| Dopo
le prime spiegazioni e i primi elementi di design definiti nello scorso
articolo, questo mese scopriamo altri due importanti punti di adattabilità
nell'architettura di un framework per macchine a stati finiti.
Introduzione
Nell'articolo
precedente sulla realizzazione di frameworks abbiamo introdotto una prima
astrazione utile per la realizzazione di un'architettura capace di mettere
a disposizione un design riutilizzabile. Il design serve per l'implementazione
di macchine a stati finiti.
La
prima astrazione utilizzava il pattern interface/implementation per generalizzare
gli arcs, elementi di transizione da uno stato all'altro della macchina
a stati finiti.
Stati
Il
tema centrale di questo articolo è l'adattabilità del framework.
Ciò non significa che tutto sia adattabile. Anzi, per garantire
l'utilizzo di un'architettura stabile è necessario che il framework
presenti anche parti "fisse", in cui non esiste nessuna flessibilità.
Queste rappresentano in un certo senso la spina dorsale del sistema.
L'implementazione
degli stati è una di queste parti fisse. Per la sola adattabilità
del sistema (utile al programmatore di applicazioni, concetto introdotto
in [1]) non serve conoscere questi elementi. A noi interessa però
l'intera architettura, perciò proponiamo almeno una breve spiegazione.
La
classe State viene usata per rappresentare ogni singolo stato del sistema.
Uno stato consiste in un riferimento ad un oggetto chiamato Flag (adattabile),
contenente un certo numero di informazioni riguardanti lo stato, e ad un
insieme di transizioni che permettono di passare dallo stato in questione
ad un altro stato. La struttura e i collegamenti incrociati tra stati viene
costruita direttamente a partire dal documento di input, contenente le
informazioni specifiche per una singola macchina a stati finiti (FSM).
Ecco
la rappresentazione grafica di questa mini architettura.
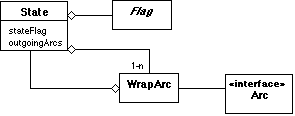
Figura
1
Da
notare la presenza della classe WrapArc che fa da tramite tra State e Arc.
Serve a gestire il collegamento allo State successivo, in modo che questa
informazione non debba essere inclusa direttamente in Arc. Questo wrapper
(pattern Proxy, [3]) serve ad evitare che il programmatore di applicazioni
abbia a che fare con un riferimento di cui non dovrebbe preoccuparsi.
Ulteriori
spiegazioni su State si possono trovare in [2].
Attraversamento
L'
attraversamento di una FSM consiste nel passare da uno stato iniziale a
tutta una serie di stati che possono eventualmente portare a uno stato
finale.
L'idea
che sta alla base dell'attraversamento "adattabile" consiste nel mettere
a disposizione una serie di algoritmi che permettano l'attraversamento
della struttura in modo differenziato, seguendo diverse strategie.
Vogliamo
con questo realizzare nel framework una funzionalità di tipo plug-in,
che ci permetta di sostituire a piacimento, anche in modo dinamico, in
run-time, l'algoritmo di attraversamento.
Per
questo tipo di realizzazione usiamo il pattern Strategy, già visto
in [4], che con l'utilizzo del polimorfismo ci permette di racchiudere
i diversi algoritmi sotto un'unica interfaccia.
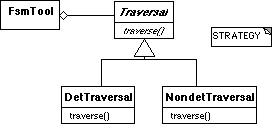
Figura
2
Il
livello più alto è la Traversal. Lo sviluppatore di applicazioni
ha a disposizione due classi concrete, oltre alla possibilità di
implementarsene una sua particolare, ereditando da Traversal.
Ecco
la classe astratta Traversal:
public
abstract class Traversal {
protected Extractor extract;
public Traversal(Extractor e){
extract = e;
}
public Extractor getExtractor(){
return extract;
}
public abstract Extractor traverse
(State state, Sequence sequence,
int traverse, Object byPassInfo);
}
Da
notare l'utilizzo di Extractor, spiegato nel prossimo capitolo.
Estrazione di
informazioni
Durante
l'attraversamento si passa da uno stato all'altro della FSM secondo le
informazioni contenute negli elementi di tipo Arc.
Da
questi elementi dobbiamo anche estrarre informazioni di output (almeno
per macchine di tipo transducer). La cosa più importante a questo
punto è poter separare bene il processo di estrazione di informazione
dall'algoritmo di attraversamento. Vogliamo mantenere questa separazione
per poter riutilizzare stessi algoritmi di attraversamento con diversi
tipi di dati e modi di interpretare le informazioni.
Non
si tratta di creare un'indipendenza assoluta (l'estrazione dell'informazione
dipende comunque dal tipo di attraversamento), ma di offrire l'opportunità
di modificare il tipo di estrazione dei dati, senza "intaccare" il resto
dell'applicazione, algoritmo di attraversamento compreso.
Abbiamo
bisogno di un meccanismo di callback che abbia nel contempo la possibilità
di mantenere uno stato. In altre parole abbiamo bisogno di un oggetto che
sia in grado di accumulare le informazioni di output incontrate durante
l'attraversamento.
Per
questo tipo di architettura utilizziamo il pattern Command ([3]), la cui
astrazione di base è rappresentata dall'interfaccia Extractor, che
ingloba il processo di estrazione di informazione. La struttura di stati
e transizioni che verrà letta dall'oggetto rimarrà read-only.
Ereditare
da Extractor significa implementare un nuovo modo di leggere informazioni
durante l'attraversamento. La separazione della lettura di informazioni
dall'algoritmo di attraversamento permette il riutilizzo indipendente di
entrambi, in contesti diversi.
Ecco
l'interfaccia Extractor:
public
interface Extractor {
public void visit(int keyHash, Arc arc, int traverse,
int level);
public void addInfo(Flag finalFlag, int level);
public boolean hasResults();
public String iterateResults(Object filter,
Object matchCriteria);
}
Come
si vede l'interfaccia definisce più di un metodo, per permettere
una comoda interazione con il resto del framework. Quelli chiamati durante
l'attraversamento sono però unicamente i metodi visit(), responsabile
dell'accumulo di informazione ad ogni singola transizione, e addInfo(),
responsabile, al termine dell'attraversamento, dell'accettazione della
sequenza in input.
Figura
3
Consideriamo
questa architettura un'astrazione "chiave" del framework (analogamente
ad Arc, mostrato in [1]), perché, diversamente da Traversal, l'implementazione
della classe concreta è molto specifica. Per questo il pattern Command
è stato implementato con i tre livelli, seguendo il pattern interface/implementation.
In
questo caso, visto che il livello astratto non deve contenere niente di
particolare, possiamo utilizzarlo per inserire codice di debugging.
Il
codice di debugging nella classe astratta di un framework è molto
utile per capire il flusso del programma, prima di implementare le classi
concrete.
Così,
ancor prima di implementare codice specifico, con una semplice dichiarazione
di eredità è possibile utilizzare il framework e capire il
funzionamento di una singola componente.
class
TransExtractor extends AbstractExtractor {}
Con
le informazioni di debugging ottenute in esecuzione lo sviluppatore di
applicazioni è in grado di seguire l'andamento previsto dal framework.
Conclusione
In
questo articolo abbiamo compiuto un ulteriore passo nel processo di design
del framework per l'implementazione di macchine a stati finiti.
Dopo
aver visto in [1] l'architettura degli elementi di transizione, abbiamo
mostrato una parte fissa del framework (State) e due importanti parti adattabili:
attraversamento (Traversal) e estrazione di informazioni (Extractor).
Bibliografia
[1]
Pedrazzini Sandro: Realizzazione di un Framework: Primi Elementi di Design,
Moka Byte, http://www.mokabyte.com, Aprile 2001.
[2]
Pedrazzini Sandro: The Jacaranda Framework, http://a.die.supsi.ch/~pedrazz/jacaranda
[3]
Gamma E., Helm R.Johnson R., Vlissides J.: Design Patterns, Elements of
Reusable Object-Oriented Software, Addison Wesley, 1995.
[4]
Pedrazzini Sandro: Framework e Patterns: Documentare con Pattern, Moka
Byte, http://www.mokabyte.com, Febbraio 2001.
Sandro
Pedrazzini ha studiato ingegneria informatica al politecnico di Zurigo
e ha ottenuto il Ph.D. all'università di Basilea. Da anni si occupa
di progettazione e sviluppo object-oriented. Attualmente collabora con
l'università di Basilea in progetti di trasferimento tecnologico
e tiene corsi di design e sviluppo software presso la SUPSI, Scuola Universitaria
Professionale della Svizzera Italiana, a Lugano. |



