EJB
o POJO?
Questo tipo di persistenza trasparente somiglia da vicino
a quella promessa dai bean di entità CMP, dove
è il component container ad svolgere una funzione
che corrisponde alla descrizione data sopra. La tecnologia
EJB, però, richiede dei descrittori più
complessi, ed impone l'utilizzo di interfacce e superclassi
presenti nel framework EJB, come javax.ejb.EntityBean
e javax.ejb.SessionBean.
I motori di persistenza come Hibernate lavorano invece
con semplici POJO, acronimo che sta per Plain Old Java
Object, termine coniato da Martin Fowler (http://www.martinfowler.com,
di refactoriana memoria [fowler]) - e da altri. Un POJO
indica un semplice oggetto Java, privo degli orpelli che
solitamente vengono imposti dai framework per questa o
quella funzione, come le sopracitate interfacce EJB. Un
esempio di POJO è:
package
com.mokabyte.samples.Prodotto;
public
class Prodotto {
String id;
String descrizione;
public
String getId() {
return id;
}
public
void setId( String id ) {
this.id = id;
}
public
String getDescrizione() {
return descrizione;
}
public
void setDescrizione( String descrizione ) {
this.descrizione = descrizione;
}
}
Quante
volte avete implementato una classe come questa, aderendo
alle convenzioni sui nomi della specifica Javabean?
Questo stile di programmazione è ormai divenuto
uno standard, ed è sufficiente alla persistenza
con Hibernate, se accompagnato da un file XML che definisce
alcune informazioni basilari, come il nome della tabella
su cui andare a leggere e scrivere ed il tipo dei dati
coinvolti:
<hibernate-mapping>
<class
name="com.mokabyte.samples.Prodotto" table="T_PRODOTTI">
<property name="id" type="string"/>
<property name="descrizione" type="string"/>
</class>
</hibernate-mapping>
Arriva
MokaTrack
Per esemplificare un motore di persistenza è
necessario fare riferimento ad un modello di entità
non troppo banale, che consenta di affrontare i diversi
problemi che si riscontrano in un modello applicativo
reale. Per questo scopo utilizziamo il modello di un
ipotetico software di usse tracking, MokaTrack, il cui
modello (per la verità abbastanza basilare) è
osservabile in figura 1.
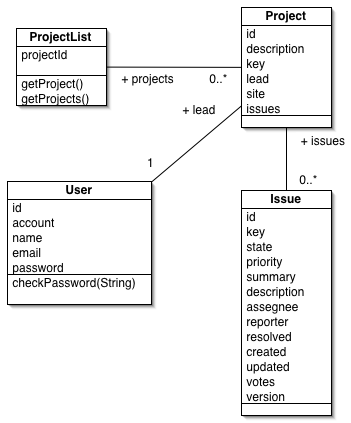
Figura 1 - Le entità coinvolte nel modello
di MokaTrack
Elenco
dei progetti
Mokatrack raccoglie le segnalazioni sulla base del singolo
progetto; l'elenco dei progetti disponibili è
presentato dalla pagina index.jsp, che utilizza direttamente
l'oggetto ProjectList per ottenerne l'elenco (ovviamente
un approccio migliore sarebbe stato quello di utilizzare
un oggetto helper). Questa pagina JSP 2.0 utilizza JSTL
per produrre la tabella dei progetti e gli URL:
<%@
taglib prefix="c" uri="http://java.sun.com/jstl/core"
%>
<html>
<body>
<h1>Elenco dei progetti</h1>
<jsp:useBean
id="projectList" class="com.mokabyte.tracking.model.ProjectList"/>
<table
cellspacing="10">
<tr>
<td>Chiave</td>
<td>Descrizione</td>
<td>Sito</td>
<td>Team leader</td>
</tr>
<c:forEach var="project" items="${projectList.projects}">
<c:url var="projectLink" value="project.jsp">
<c:param name="projectId" value="${project.id}"
/>
<c:param name="projectKey" value="${project.key}"
/>
</c:url>
<c:url var="extLink" value="${project.site}"/>
<tr>
<td>
<a href="${projectLink}">${project.key}</a>
</td>
<td>${project.description}</td>
<td>
<a href="${extLink}">${project.site}</a>
</td>
<td>${project.lead.name}</td>
</tr>
</c:forEach>
</table>
</body>
</html>
Come
si osserva dal listato, l'elenco dei progetti avviene
invocando il metodo getProjects(). Si noti che ProjectList
non è un oggetto persistito con Hibernate, ma
che le informazioni necessarie vengono ottenute con
le opportune chiamate alle API dello stesso. In particolare,
l'elenco dei progetti avviene eseguendo una find() con
una espressione molto simile ad SQL:
public
List getProjects() throws HibernateException, SQLException
{
createSession();
return session.find("from projects
in class com.mokabyte.tracking.model.Project");
}
Il
linguaggio HSQL (Hibernate SQL) implementa molte delle
funzionalità presenti in SQL, mantenendo però
l'approccio ad oggetti.
L'oggetto session è una sessione Hibernate, ottenuta
come segue:
Datastore
ds = Hibernate.createDatastore()
.storeClass( com.mokabyte.tracking.model.Project.class
)
.storeClass( com.mokabyte.tracking.model.Issue.class
)
.storeClass( com.mokabyte.tracking.model.User.class
);
SessionFactory
sessions = ds.buildSessionFactory();
return sessions.openSession();
L'oggetto
DataStore viene configurato con le classi che saranno
persistite, attraverso il metodo storeClass(). Per ciascuna
di queste classi sarà necessario un descrittore
XML, oppure un solo descrittore cumulativo. Questi file
XML vengono ricercati come risorse e quindi dovrebbero
essere presenti nel CLASSPATH nello stesso package delle
classi che definiscono.
Persistenza
della classe Project
Il file XML che definisce la persistenza dell'oggetto
Project contiene tre elementi principali: le proprietà
dell'oggetto, il legame alla tabella delle segnalazioni
e la relazionalità con la tabella degli utenti;
un attributo di Project è infatti leader, che
è di tipo User ed identifica il team leader del
progetto. Nel dettaglio, troviamo:
-
class name. Nome completo di package della classe
da persistere;
- table.
Nome della tabella SQL su cui scrivere le informazioni;
- id.
Chiave univoca della tabella;
- property.
Proprietà dell'oggetto, che viene mappata su
una colonna della tabella;
- many-to-one.
Relazionalità con l'oggetto User
- list.
Mappatura dell'oggetto List presente in Project e
che mantiene l'elenco delle segnalazioni.
<?xml
version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-1.1.dtd">
<hibernate-mapping>
<class
name="com.mokabyte.tracking.model.Project"
table="projects">
<id name="id" column="id" type="long">
<generator class="native"/>
</id>
<property name="key" column="ukey"
type="string" not-null="true"/>
<property name="description" type="string"/>
<property name="site" type="string"/>
<many-to-one
name="lead"
column="id_lead"
class="com.mokabyte.tracking.model.User"
/>
<list
role="issues" table="issues" cascade="all">
<key column="id_project"/>
<index column="id"/>
<one-to-many class="com.mokabyte.tracking.model.Issue"/>
</list>
</class>
</hibernate-mapping>
La
gestione dell'identificativo univoco è particolarmente
interessante, perchè Hibernate dispone di una
serie di meccanismi che permettono una ampia varietà
di algoritmi predefiniti, quando nella tecnologia EJB
non esiste un supporto similare. In particolare si trovano:
-
uuid.hex algoritmo UUID a 128 bit che risulta in una
stringa di cifre esadecimali lunga 32. Utilizza l'IP
della macchina per rendere la chiave univoc a livello
di network.
- uuid.string
lo stesso di uuid.hex ma utilizza tutti i caratteri
ASCII (non supportato su PostgreSQL)
- vm.long
long univoco all'interno della stessa VM. Non funziona
in cluster
- vm.hex
come il precedente ma codifica in esadecimale
- assigned
fornito dall'applicazione
- native
consente di supportare le tipologie native presenti
in MySQL, DB2, Sybase, Hypersonic SQL e MS SQL Server.
- sequence
consente di utilizzare i sequence su database quali
DB2, PostgreSQL, Oracle, SAP DB, McKoi o un generatore
su Interbase.
- hilo.long
utilizza l'algoritmo hi/lo per generare una chiave
univoca di tipo long
- hilo.hex
come il precedente ma ritorna una stringa lunga 16
con cifre esadecimali
- seqhilo.long
utilizza l'algoritmo hi/lo a fronte di un sequence
Nel caso di MokaTrack sono stati utilizzati per tutte
le tabelle identificativi ottenuti in modo nativo, visto
che il database utilizzato è stato MySQL.
Configurazione
del database
Per indicare ad Hibernate quale database utilizzare
è necessario posizionare nelle classi di sistema
un file di proprietà chiamato hibernate.properties,
che dovrà contenere le informazioni di configurazione
specifiche del database scelto. Ad esempio:
hibernate.dialect
cirrus.hibernate.sql.MySQLDialect
hibernate.connection.driver_class com.mysql.jdbc.Driver
hibernate.connection.url jdbc:mysql://127.0.0.1/mokatrack
hibernate.connection.username root
hibernate.connection.password ***
E'
particolarmente importante la proprietà hibernate.dialect,
perchè identifica la classe che eseguirà
la mappatura tra il dialetto SQL generico utilizzato
da Hibernate con quello reale dello specifico database
utilizzato. E' noto infatti che, se da una parte JDBC
è una API standard per l'accesso a database di
tipo diverso, è anche vero che il dialetto SQL
utilizzato nei comandi dell'applicazione deve essere
diverso in funzione del database. Questo strato di indirezione
presente in Hibernate consente al motore di persistenza
principale di utilizzare un dialetto unico che poi viene
tradotto in quello specifico impiegato dal database
utilizzato.
Aggiunta
di una segnalazione
All'interno di MokaTrack è la pagina addIssue.jsp
ad occuparsi di raccogliere le informazioni per la memorizzazione
nel database di una nuova segnalazione:
<%@
taglib prefix="c" uri="http://java.sun.com/jstl/core"
%>
<html>
<body>
<h2>Aggiunta di una segnalazione ${param.projectKey}</h2>
<jsp:useBean
id="projectList" class="com.mokabyte.tracking.model.ProjectList"/>
<jsp:setProperty name="projectList" property="projectId"
value="${param.projectId}"/>
<c:set var="issueList" value="${projectList.project}"/>
<form
action="Project.jsp" method="post">
<!--
Campi nascosti necessari alla pagina destinataria -->
<input type="hidden" name="projectId"
value="${param.projectId}"/>
<input type="hidden" name="projectKey"
value="${param.projectKey}"/>
<table
cellspacing="10">
<tr>
<td>Sommario</td>
<td><textarea name="summary" rows="10"
cols="80"></textarea></td>
</tr>
<tr>
<td>Priorità</td>
<td>
<select name="priority">
<option value="1">Triviale</option>
<option value="2">Minore</option>
<option value="3">Maggiore</option>
<option value="4">Critico</option>
<option value="5">Bloccante</option>
</select>
</td>
</tr>
<tr>
<td>Descrizione</td>
<td><textarea name="description"
rows="25" cols="80"></textarea></td>
</tr>
</table>
<input
name="submit" type="submit" value="addIssue"/>
</form>
</body>
</html>
Le
informazioni raccolte vengono, in modo poco elegante,
invate alla pagina Project.jsp per la memorizzazione,
che avviene attraverso l'helper IssueAdder.java. La
pagina Project.jsp contiene infatti le seguenti azioni
che individuano l'eventuale arrivo dalla pagina addIssue.jsp;
in tal caso viene creato un oggetto IssueAdder ed impostate
le proprietà:
<c:if
test="${!empty param.submit}">
<jsp:useBean id="issueAdder" class="com.mokabyte.tracking.process.IssueAdder"/>
<jsp:setProperty name="issueAdder" property="*"/>
<jsp:setProperty name="issueAdder" property="add"
value="${param.projectId}"/>
</c:if>
La
classe IssueAdder si limita a memorizzare le informazioni
passate:
package
com.mokabyte.tracking.process;
import
java.sql.SQLException;
import cirrus.hibernate.*;
import
com.mokabyte.tracking.model.*;
import com.mokabyte.tracking.util.*;
public
class IssueAdder {
String
summary;
int priority;
String description;
//Getter e setter
public void setSummary(String summary) {
this.summary = summary;
}
public
void setPriority(int priority) {
this.priority = priority;
}
public
void setDescription(String description) {
this.description = description;
}
public
String getSummary() {
return summary;
}
public
int getPriority() {
return priority;
}
public
String getDescription() {
return description;
}
}
L'interazione
con Hibernate avviene alla chiamata di setAdd(), a cui
viene passato l'id del progetto a cui aggiungere la
segnalazione. In una applicazione reale, avremmo già
avuto l'oggetto Project corretto in sessione, ma in
questo caso abbiamo solo l'ID, quindi è necessario
rivolgersi alla classe ProjectList per ottenere l'oggetto
Project corretto. Il codice carica anche un oggetto
User per essere passato come utente che ha inviato la
segnalazione; anche in questo caso l'utente sarebbe
dovuto essere in sessione:
public
void setAdd( String projectId ) throws HibernateException,
SQLException {
Session session = HibernateUtils.getSession();
//L'utente
andrebbe preso dalla sessione
User currentUser = (User)session.load( User.class, new
Long( 1 ) );
ProjectList
list = new ProjectList();
Project currentProject = list.getProject( projectId
);
currentProject.addIssue( currentUser, summary, description,
priority );
}
Come
si nota osservando il listato, il caricamento di una
specifica istanza di oggetto avviene tramite il metodo
load() esposto dall'oggetto Session, che si aspetta
come primo parametro la classe dell'oggetto da caricare
e come secondo parametro la chiave relativa all'istanza
desiderata.
A sua volta, il metodo Project.addIssue() aggiunge la
segnalazione all'elenco aggiungendo semplicemente un
nuovo oggetto Issue alla List.
public
void addIssue( User user, String summary, String description,
int priority) throws HibernateException, SQLException
{
Issue
issue = new Issue( this, user, summary, description,
priority );
issues.add( issue );
System.out.println("------------------------");
session.saveOrUpdate(this);
session.flush();
}
Per
persistere questa modifica dell'oggetto è necessario
chiamare il metodo saveOrUpdate(): questo verifica se
l'oggetto è già presente in tabella e
se lo è ne aggiorna gli eventuali dati cambiati.
Si noti che Hibernate utilizza la chiave della tabella
per come identità di un oggetto e con questo
dato riesce a capire se una istanza è già
presente sul database o meno. In questo caso la scrittura
delle informazioni percorre tutta la gerarchia degli
oggetti contenuti (quindi anche delle Collection come
issues) fino ad arrivare agli oggetti finali (le entità).
Comunque, la scrittura effettiva avviene solo all'esecuzione
del metodo flush().
Conclusioni
Che dire di una possibile convergenza tra EJB CMP e
framework di persistenza? Pendiamo dalle labbra di SUN
che, con in mano anche JDO (Java Data Objects, una API
standard per la persistenza di POJO) ha ampia scelta
di movimento.
JBoss Group, dalla sua, ha già assunto il responsabile
del progetto Hibernate, con il preciso scopo di integrare
il suo prodotto nel noto application server open source
e costruire appunto la persistenza CMP di JBoss con
Hibernate. JBoss Group rassicura: il famoso motore di
persistenza vivrà anche come entità a
se stante, e non saremo obbligati ad utilizzare JBoss
per poter sfruttare le potenzialità di Hibernate.
Sarà vero? Noi speriamo di si, come speriamo
che la logica "Embrace & Extend" rimanga
una pratica lontana dal mondo open source. Anzi, che
scompaia proprio, anche da Redmond.
Bibliografia
[gof] Gamma, altri -"Design Patterns", Addison-Wesley
1995
[grand98] Grand - "Java Design Patterns vol 1",
Wiley 1998
[fowler] Martin Fowler - "Refactoring", Addison-Wesley
1999
Esempi
Scarica
gli esempi
allegati all'articolo
|


