|
Gerarchia
di DTO: base light ed estensioni pesanti
Spesso capita che al termine della stesura e test della
versione alfa della applicazione multistrato, scritta
seguendo tutti i canoni della progettazione per pattern
e delle indicazioni Sun su JavaEE, sorgano alcune importanti
discrepanze e stranezze nel comportamento di una applicazione
fra quanto ottenuto e quanto ipotizzato. Oppure che
vi sia un degrado elevato delle prestazioni nella gestione
di determinati set di dati.
Alcune di queste problematiche possono essere imputate
sia ad un cattivo design sia ad una non ottimale messa
a punto del sistema server (sia il database sia il container
EJB).
Spesso mi sono confrontato con clienti che chiedevano
aiuto perché l'applicazione "gira piano"
o "il server si pianta" cercando la soluzione
di tutti i mali nella giusta configurazione dei parametri
Xmm o Xms di Tomcat.
L'esperienza insegna che prima di andare a cercare nell'application
server la manopola magica (come appunto i paramentri
di configurazione della gestione della memoria) che
risolva problemi di prestazione e di memoria in modo
rapido e indolore, è necessaria una indagine
attenta del codice scritto dato che nel 99% dei casi
il problema risiede nella applicazione e non nel container.
Nel proseguo di questa serie parleremo adeguatamente
degli aspetti relativi alla ottimizzazione sia dell'application
server sia della parte di persistenza CMP: per il momento
concentreremo quindi l'attenzione su come un DTO possa
impattare su prestazioni complessive. Affrontare il
tema della ottimizzazione delle prestazioni di una applicazione
JavaEE è un compito arduo per certi versi senza
fine: cercheremo nel corso di questo e dei prossimi
articoli, di affrontarne ogni singolo punto, sicuri
che trovare una soluzione definitiva e completa è
concettualmente una contraddizione in termini vista
la molteplicità dei fattori in gioco.
Dato che si sta parlando di DTO la prima cosa che salta
in mente anche ad un neofita di Java EE, teoria dei
pattern e simili è che un trasfer object sposta
informazioni fra strati e moduli applicativi e che quindi
più informazioni sono inserite nel DTO, maggiore
sarà il tempo necessario per tale trasferimento.
Inoltre un tipico errore che si commette in questi casi
è concentrare l'attenzione esclusivamente nella
parte di lettura dei dati e popolamento del DTO (ovvero
nello strato di persistenza-mapping): una cosa di cui
spesso non si tiene conto è che trasferire informazioni
da uno strato A (es il container EJB) ad uno strato
B (es il container web) implica dare allo strato destinatario
l'onere di caricare in memoria dei dati. Non è
infrequente per questo motivo che se A invia dati in
modo sconsiderato, B dopo un certo lasso di tempo non
disponga di sufficienti di risorse per poter gestire
tali informazioni.
Il concetto fondamentale è quindi quello di pensare
in maniera estremamente oculata a cosa debba essere
trasferito: è importante quindi per ogni use
case (indispensabile qui una saggia analisi degli use
case in gioco tramite un ben consolidato approccio metodologico)
definire il set minimo di informazioni necessarie da
trasferire.
In tale ambito potrebbero prendere in esame moltissimi
di esempi per capire l'importanza di tale argomento.
Se ne farà uno solo: si pensi alla classica ricerca
di un articolo (si prende al solito l'esempio del MokaCMS)
pubblicato da un CMS tramite interfaccia web.
A fronte della immissione di un criterio di ricerca
e dei parametri relativi, si otterrà una lista
di massima di articoli dalla quale poi l'utente selezionerà
quello interessato per la visualizzazione completa delle
informazioni.
Per lista di massima si intende un elenco di dati contenenti
per ogni articolo uno stretto numero di informazioni
prese fra le n proprietà dell'articolo stesso;
importante notare che n potrebbe essere molto grande
o alcune di queste proprietà potrebbero particolarmente
ingombranti (si pensi al campo blob dell'articolo contenente
il codice XML del corpo dell'articolo).
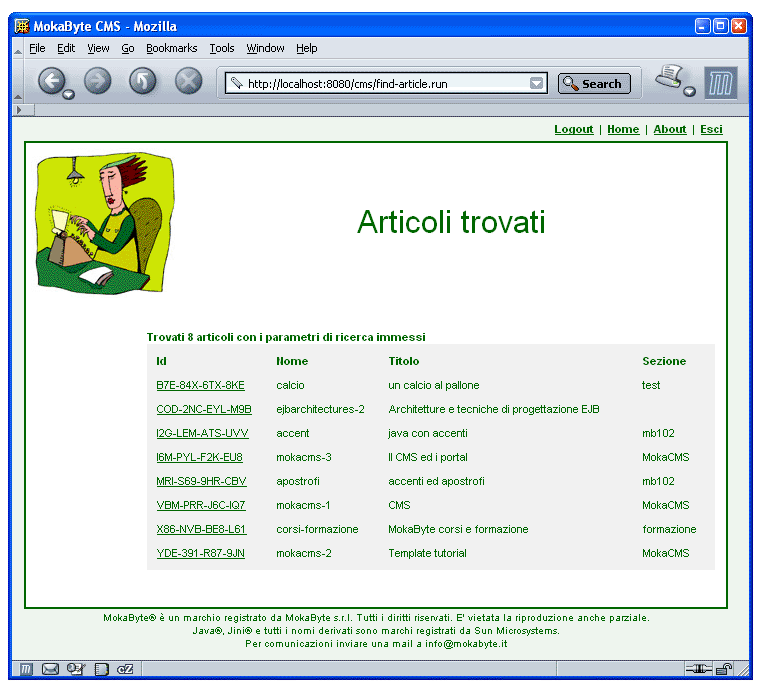
Figura 1 - Ricerca di un articolo: dopo la prima
ricerca viene proposta una lista di sintesi degli articoli
trovati
Da
un punto di vista applicativo la ricerca avviene tramite
una invocazione da parte dello strato client di un qualche
metodo di business logic il quale restituirà
un elenco di DTO.
Appare ovvio che se per comporre la lista di massima
siano necessarie solamente id, titolo, data di pubblicazione
dell'articolo stesso, allora non ha senso popolare ogni
DTO con tutte le informazioni relative ad ogni singolo
articolo.
Equivalentemente se l'entità articolo risulta
legata ad altre entità (esempio autore, sezione,
immagini etc…) per una completa rappresentazione
di tale manuscritto sarà necessario anche trasferire
le varie entità dipendenti, ovvero sarà
necessario inserire nel DTO dell'articolo anche tutti
i DTO dipendenti.
Per comprendere questo aspetto si consideri la figura
2 in cui si riporta nuovamente lo schema delle entità
che partecipano all'applicazione:
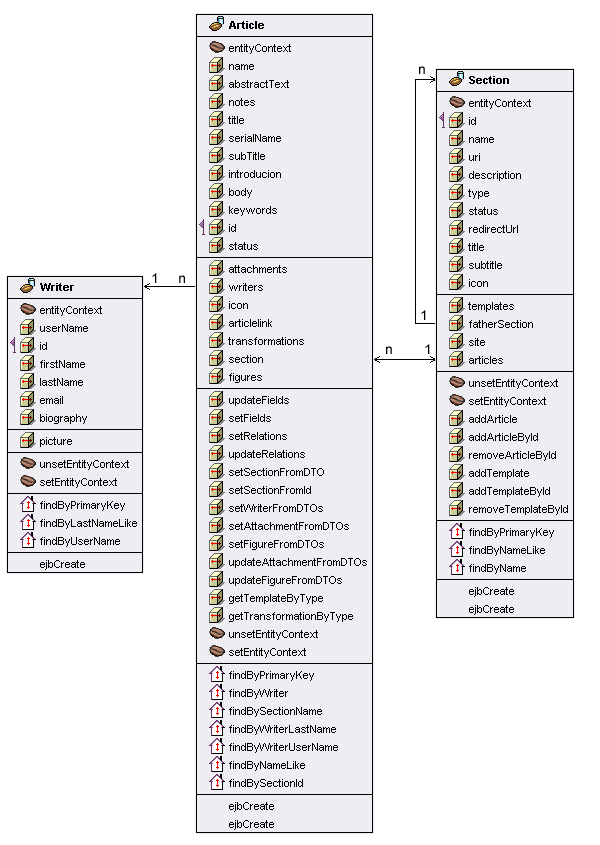
Figura 2 - Porzione del modello di dati relativo
alle entità Article-Session-Writer
Per
risolvere queste problematiche si possono adottare diverse
soluzioni progettuali ed implementative. Concentrando
l'attenzione sul DTO, una delle possibili vie per ridurre
inutili trasferimenti di informazioni è diversificare
la tipologia dei DTO in funzione di quello che realmente
serve caso per caso. Di seguito sono riportate alcune
tecniche e soluzioni: il lettore è esortato a
considerare tale elenco volutamente incompleto, ma sia
di spunto per eventuali possibili alternative.
Diversificare
i DTO in light, normal, fullfat
Per ogni entità del business model, la cosa più
semplice che si possa pensare di fare è dar vita
non ad un solo DTO ma a più versioni diversificando
in ognuno la quantità di informazioni contenute.
Si immagini una entità che abbia n proprietà
di cui solo una parte sia sempre necessaria per ogni
operazione da parte dello strato di presentation (es.
id e titolo dell'articolo come nel caso precedente).
Delle n proprietà di cui prima, alcune (in genere
le più pesanti in bytes e tempo di elaborazione)
saranno utilizzate di rado: esempio la foto di un autore
dovrà essere ricavata solamente al momento della
visualizzazione della scheda autore ma potrebbe essere
del tutto inutile al momento della visualizzazione di
un articolo dove deve comparire solamente nome cognome
ed email dell'autore (in realtà questo non è
il caso degli articoli di MokaByte).
Da questa prima analisi si potrebbero creare tre tipologie
di DTO: uno mimale (detto light) con solo i dati strettamente
necessari, uno di media dimensione (con tutti i dati
dell'articolo esclusi quelli veramente molto ingombranti
come blob o allegati) ed uno "fullfat" contenente
tutto quello che riguarda l'articolo.
Nella applicazione MokaCMS ([cms]) per gestire gli articoli
si sono utilizzati solo due livelli di diversificazione,
unitamente all'uso di assembler personalizzati in modo
da avere più varianti senza aumentare a dismisura
il numero di classi (si veda il punto successivo).
Di seguito la parte iniziale della classe LightArticleDTO
public
class LightArticleDTO implements java.io.Serializable
{
public final static String STATUS_READY="READY";
public final static String STATUS_NOT_READY="NOTREADY";
protected
String name;
protected String abstractText;
protected String notes;
protected String title;
protected String status;
protected String subTitle;
protected String introducion;
protected String body;
protected String id;
private String serialName;
private String keywords;
private String linkStatus;
private String columnName;
private String htmlTemplateId;
public LightArticleDTO() {
super();
}
...
}
Mentre
a seguire il DTO fat della classe ArticleDTO
public
class ArticleDTO extends LightArticleDTO {
private SectionDTO sectionDTO;
private AttachmentDTO[] attachmentDTOs;
private WriterDTO[] writerDTOs;
private ArticlelinkDTO articlelinkDTO;
private FigureDTO[] figureDTOs;
private IconDTO iconDTO;
public ArticleDTO(){
super();
}
public ArticleDTO(String name, String abstractText,
String notes, String title,
String
subTitle, String introducion, String body, String id,
String
status, String serial, String columnName, String keywords,
String
linkStatus, SectionDTO sectionDTO, IconDTO iconDTO){
super(name, abstractText, notes,
title, subTitle, introducion, body, id, status, serial,
columnName, keywords, linkStatus);
this.sectionDTO = sectionDTO;
this.iconDTO = iconDTO;
}
...
}
In
questo caso la differenza fra le due risiede negli oggetti
dipendenti (si riconsideri la figura 2): il DTO base
o light contiene infatti solamente i dati relativi ad
un articolo mentre la versione completa include al suo
interno tutti i riferimenti ai DTO delle entità
dipendenti.
Questa seconda versione è ovvio che debba essere
utilizzata con estrema attenzione dato che il suo trasferimento
potrebbe risultare estremamente costoso.
Come
si avrà modo di vedere in uno degli articoli
successivi di questa serie, non è il trasferimento
del DTO ad essere costoso, ma piuttosto la relativa
creazione e popolazione all'interno dello strato di
persistenza.
Ad esempio le tecniche di lazy loading comunemente utilizzate
da un container EJB CMP 2.0, rimandano il caricamento
dal db al container di tutti i campi di un entity all'effettivo
momento del bisogno.
Durante la fase di implementazione della applicazione
che sul sito di MokaByte permette il download dei libri
in formato PDF, una errata valutazione della diversa
necessità fra DTO light e fullfat introdusse
un fattore 1 nell'elencazione dei capitoli appartenenti
ad un libro: dopo la messa a punto, dai 30 secondi necessari
per visualizzare l'elenco 10 capitoli di un libro con
l'utilizzo di due DTO (light e fullfat) si è
passati a poco più di un 1".
Creazione
di gerarchie di DTO
I due DTO presentati poco prima sono legati da un legame
padre figlio: questa sceltà è indicata
nel caso in cui non sia necessario assemblare i dati
in maniera eterogenea (vedi oltre) secondo viste o parzializzazioni
di dati. Ogni elemento della gerarchia fa riferimento
in questo caso solamente ad una ed una sola entità,
selezionando eventualmente quei campi che interessano.
Il vantaggio di centralizzare le proprietà base,
comuni e le più semplici in un padre comune,
certamente semplifica lo sviluppo di tutti gli eventuali
DTO figli.
Diversificare
la creazione/popolamento del DTO con diversi Assembler
Una variante dello schema precedente (che può
essere utilizzata in abbinamento o congiuntamente) è
quella che demanda al DTOAssembler (vedi articolo precedente
[DTO-1]) il popolamento delle proprietà del DTO
che pero' in questo caso è e rimane sempre uno
solo.
Ad esempio la classe ArticleDTOAssembler che si occupa
della creazione dei vari DTO relativi a un articolo
offre tre metodi di assemblaggio: un per il DTO leggero,
uno per il fullfat, e uno finalizzato alla generazione
di un DTO specifico per la visualizzazione in HTML
/**
* Crea un DTO completo con tutti i DTO dipendenti opportunamente
creati e popolati
*/
public static ArticleDTO createDto(ArticleLocal articleLocal)
{
ArticleDTO
articleDTO = new ArticleDTO();
if
(articleLocal != null) {
articleDTO.setName(articleLocal.getName());
articleDTO.setAbstractText(articleLocal.getAbstractText());
articleDTO.setBody(articleLocal.getBody());
articleDTO.setColumnName(articleLocal.getColumnName());
articleDTO.setId(articleLocal.getId());
articleDTO.setIntroducion(articleLocal.getIntroducion());
articleDTO.setKeywords(articleLocal.getKeywords());
articleDTO.setNotes(articleLocal.getNotes());
articleDTO.setSerialName(articleLocal.getSerialName());
articleDTO.setStatus(articleLocal.getStatus());
articleDTO.setSubTitle(articleLocal.getSubTitle());
articleDTO.setTitle(articleLocal.getTitle());
// crea i DTO dipendenti e li
lega al DTO da restituire come risposta del metodo
articleDTO.setFigureDTOs(FigureDTOAssembler.createDtos(articleLocal.getFigures()));
articleDTO.setIconDTO(IconDTOAssembler.createDto(articleLocal.getIcon()));
articleDTO.setSectionDTO(SectionDTOAssembler.createDto(articleLocal.getSection()));
articleDTO.setWriterDTOs(WriterDTOAssembler.createDTOs(articleLocal.getWriters()));
articleDTO.setAttachmentDTOs(AttachmentDTOAssembler.createDtos(articleLocal.getAttachments()));
}
return articleDTO;
}
/**
* crea un DTO leggero senza i DTO degli oggetti dipendenti
*/
public static LightArticleDTO createLightDTO(ArticleLocal
articleLocal) {
logger.debug("--- Enter - Parameters:
articleLocal= " + articleLocal);
LightArticleDTO lightArticleDTO = new LightArticleDTO();
if (articleLocal != null) {
logger.debug("si assembla
il lightArticleDTO");
lightArticleDTO.setName(articleLocal.getName());
lightArticleDTO.setAbstractText(articleLocal.getAbstractText());
lightArticleDTO.setNotes(articleLocal.getNotes());
lightArticleDTO.setTitle(articleLocal.getTitle());
lightArticleDTO.setSubTitle(articleLocal.getSubTitle());
lightArticleDTO.setIntroducion(articleLocal.getIntroducion());
lightArticleDTO.setBody(articleLocal.getBody());
lightArticleDTO.setId(articleLocal.getId());
lightArticleDTO.setStatus(articleLocal.getStatus());
lightArticleDTO.setLinkStatus(articleLocal.getArticlelink().getStatus());
}
logger.debug("--- Exit - return
lightArticleDTO="+lightArticleDTO);
return lightArticleDTO;
}
/**
* crea un DTO leggero per la visualizzazione in HTML.
il corpo viene preso
* dalla trasformazione HTML. Fra i DTO dipendenti sono
lasciati solo quelli
* strettamente necessari alla visualizzazione dell'articolo
in HTML: SectionDTO,
* SerialDTO. i WriterDTO sono messi per poter visualizzare
nome, cognome ed id (serve
* per poter ricavare la foto e visualizzarla nella pagina
JSP)
*/
public static HTMLArticleDTO createHTMLDTO(ArticleLocal
articleLocal) {
ArticleDTO articleDTO = new ArticleDTO();
if (articleLocal != null) {
articleDTO.setName(articleLocal.getName());
articleDTO.setAbstractText(articleLocal.getAbstractText());
articleDTO.setNotes(articleLocal.getNotes());
articleDTO.setTitle(articleLocal.getTitle());
articleDTO.setSubTitle(articleLocal.getSubTitle());
articleDTO.setIntroducion(articleLocal.getIntroducion());
TransformationLocal transformationLocal
= articleLocal.getTransformationByType("XSLT");
logger.debug("si assegna
il body dell'articolo = " + transformationLocal.getBody());
articleDTO.setBody(transformationLocal.getBody());
articleDTO.setId(articleLocal.getId());
articleDTO.setKeywords(articleLocal.getKeywords());
articleDTO.setWriterDTOs(WriterDTOAssembler.createLightDTOs(articleLocal.getWriters()));
articleDTO.setSerialName(articleLocal.getSerialName());
articleDTO.setColumnName(articleLocal.getColumnName());
}
return articleDTO;
}
Ognuno dei tre metodi restituisce un oggetto differente,
per una scelta progettuale ben precisa infatti non si
vuole utilizzare nessun mascheramento dietro una classe
base che permetterebbe un utilizzo polimorfico del tipo
restituito.
Usare un solo DTO o comunque un numero limitato, e di
variarne il contenuto ovvero le dimenzioni tramite differenti
tipologie di assembler è una scelta saggia al
fine di ridurre la complessità dall'esterno,
anche se riduce il type checking e la possibilità
di fare controlli in fase di scrittura del codice. Ad
esempio utilizzando un solo DTO per tutte le situazioni,
variandone il contenuto tramite diversi DTO assembler,
impedisce al client di sapere cosa vi sia effettivamente
dentro un oggetto di trasportp che arriva dallo strato
di business logic, reintroducendo le problematiche tipiche
dei DTO standard viste nell'articolo precedente ([DTO-1]).
Al solito il buon senso dovrebbe far mediare fra le
varie opportunità e soluzioni: personalmente
cerco sempre di ridurre al massimo l'utilizzo parzializzato
dei DTO; se servono solo metà delle informazioni
della entità Writer, è preferibile creare
un HalfWriterDTO, piuttosto che riempire a metà
il WriterDTO standard.
Assemblare
le viste eterogenee in DTO compositi
Infine una ulteriore soluzione che potrebbe rivelarsi
utile è quella di creare DTO in maniera non isomorfa
con il modello di dati. Per questo se si considera la
figura 2 in cui sono raffigurate tre entità si
potrebbe pensare di creare un DTO che contenga una raccolta
solo di alcune proprietà contenute nei vari entity.
In questo modo il DTO risultante non risulterebbe espressione
diretta di nessuna entità del business model,
ma piuttosto l'accorpamento di dati eterogenei utili
solo in determinati casi particolari.
Questo approccio certamente non complesso da un punto
di vista implementativo può risultare impraticabile
se prima non sia stata completata in maniera accurata
una scrupolosa analisi degli use case coinvolti e soprattutto
delle strutture dati associate ad ogni use case.
Le
collezioni di DTO: liste e array
Un aspetto particolarmente importante è legato
alla modalità secondo la quale gruppi di DTO
devono essere trasferiti da uno strato all'altro. Il
caso più evidente è quello della ricerca:
si consideri il business delegate che permetta di ricavare
un elenco di articoli ricercati per autore
public
LightArticleDTO[] lightArticleFindByWriterLastName(String
lastName)
throws
FacadeInvocationException {
logger.debug("--- Enter - Parameters:
lastName= " + lastName);
try {
return articleManagerSFRemote.lightArticleFindByWriterLastName(lastName);
}
catch (RemoteException re) {
String msg = "Errore di
invocazione remota sul metodo di façade articleFindByWriter()
\n"+re;
logger.error(msg);
throw new FacadeInvocationException(msg);
}
}
In
perfetto accordo con la filosofia base del pattern Business
Delegate all'esterno del metodo di ricerca sono nascoste
le complessità legate alla interrogazione remota
del session façade che lavora congiuntamente
con il BD.
La cosa interessante che si può notare in questo
caso è il tipo di parametro restituito dal metodo
lightArticleFindByWriterLastName(). Essendo una ricerca
con valori multipli si poteva optare per un oggetto
di tipo lista (es. LinkedList molto comodo da usare
nelle applicazioni web) che certamente risulta più
comoda di un oggetto a dimensionamento fisso come è
un array.
Il motivo di tale scelta si può dedurre in modo
piuttosto semplice osservando la firma del metodo alternativo
public
LinkedList lightArticleFindByWriterLastName(String lastName)
throws
FacadeInvocationException;
In
questo caso appare evidente come sia impossibile ricavare
il tipo del valore ritornato dal metodo: potrebbe essere
un DTO fullfat o un light, oppure potrebbe essere tutt'altra
cosa.
L'utilizzo degli array nelle risposte con valori multipli
ed in generale in tutti quei casi in cui sia necessario
passare collezioni di DTO è quindi una scelta
che per quanto risulti scomoda offre maggiore chiarezza
e definizione.
DTO
e VO
In alcuni testi è riportata una organizzazione
più articolata degli oggetti che popolano i vari
strati applicativi: in tali contesti il DTO viene affiancato
ad un altro pattern importante, il Value Object. Un
VO è un oggetto il cui scopo è quello
di rappresentare una struttura dati ad uso e consumo
del client.
Un VO è quindi una specie di DTO ma con il preciso
compito di offrire una rappresentazione "spot"
dei dati per il client. Il senso di tale oggetto è
infatti non tanto quello di offrire una rappresentazione
coerente e aggiornata in tempo reale del model sottostante
allo strato server, ma piuttosto di contenere una istantanea
dello stato, "scattata" nel momento in cui
il client ha effettuato una qualche interrogazione sul
server.
Per questo motivo DTO e VO sono due pattern che lavorano
in stretto contatto.
Quando un client (o più precisamente il Business
Delegate come dovrebbe ormai essere chiaro a chi ha
seguito questa serie di articoli) effettua una interrogazione
riceve un DTO provvederà immediatamente a spostare
i dati dal DTO al VO e usare quest'ultimo per esempio
per completare una scheda dati di una pagina JSP.
Viceversa ogni modifica che si vuole effettuare su tale
assemblaggio di dati dovrà poi essere re-inviato
allo strato di logica business ricreando nuovamente
un DTO e reinviandolo al server.
Il
flusso tipico è quindi quello rappresentato in
figura 3
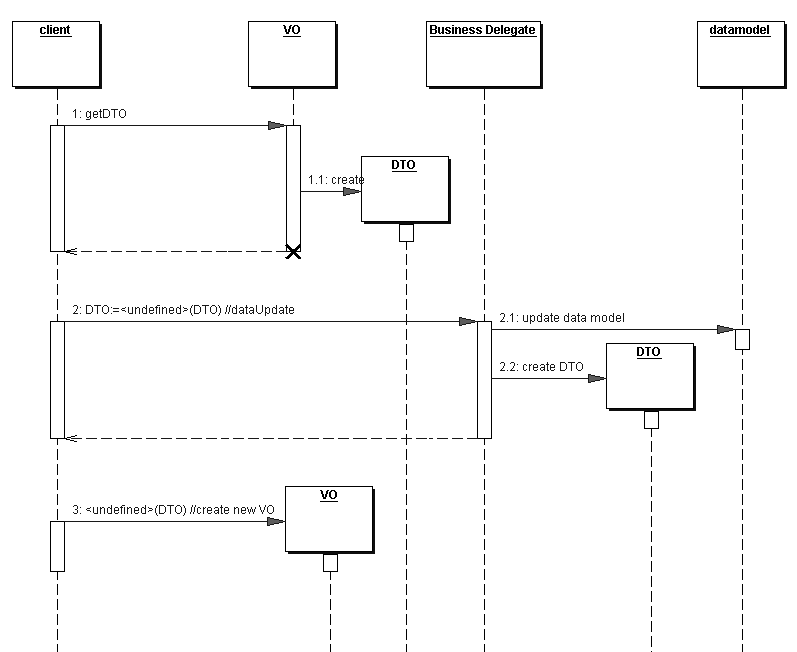
Figura 3 - Il flusso dati fra gli strati client
e busines logic avviene per mezzo di DTO che migrano
fra i vari strati e di VO che vengono creati sul client.
Da
questa figura appaiono chiare alcune osservazioni: la
prima è che il VO è il corrispondente
client side del data business model (nel caso in questione
un entity bean o un aggregato di entity). Come un entity
bean un VO rappresenta una astrazione di un modello
dati con la importante differenza che il VO ha il solo
scopo di rappresentare una struttura dati in modo molto
semplice. Non vi è nessuna logica di gestione
della transazionalità ne della persistenza.
In passato, prima dell'avvento di strumenti di mapping
OO-RDB come Hibernate, CMP, JDO, i VO erano utilizzati
come rappresentazione dei dati e mascheravano le operazioni
di persistenza in unione con un altro pattern (il Data
Access Object o DAO).
L'altra osservazione importante è relativa alla
natura di un DTO che sempre di più assume il
ruolo di oggetto di trasporto a vita breve: un DTO viene
creato su uno dei due strati applicativi inviato verso
l'altro strato e qui immediatamente ritrasformato in
un oggetto usato come rappresentazione dei dati (un
VO o un CMP).
In tale ottica si giustifica la teoria secondo la quale
un DTO dovrebbe essere valorizzato esclusivamente tramite
il costruttore e non dovrebbe avere metodi di setXXX
ma solamente getXXX dato che dopo la creazione deve
rimanere immutabile.
Il condizionale è d'obbligo dato che spesso per
motivi di praticità o di semplicità (progetti
piccoli, team di sviluppo piccoli o molto ben preparati,
un sistema di documentazione molto ben rodato) si tende
a ridurre i vincoli progettuali. Per lo stesso motivo
in alcuni casi si tende a semplificare ulteriormente
ed eliminare la separazione fra DTO e VO creando un
unico oggetto che svolga entrambe le funzioni in maniera
unificata.
Personalmente non mi trovo in accordo con tale organizzazione
(i vantaggi sono minimi) che può portare in alcuni
casi ad una eccessiva dipendenza fra i vari strati applicativi.
L'utilizzo di oggetti separati per i vari contesti applicativi
semplifica enormemente il lavoro del deployer al momento
della organizzazione dei vari pacchetti da distribuire
ai vari application server, applicazioni client e così
via.
In ogni caso non si grida allo scandalo se in un progetto
si è fatta la scelta di riunire DTO e VO in un
solo oggetto.
Volendo utilizzare DTO e VO è importante capire
come i due oggetti possano convivere fra loro e quali
siano i punti di contatto. Al solito il codice che si
andrà ad analizzare è stato estrapolato
dal CMS di MokaByte ([CMS]) ma in tal senso ogni altro
progetto scritto in maniera canonica potrebbe essere
preso ad esempio.
Partendo dal VO si prenderà in esame il value
object che rappresenta un autore di articoli, ovvero
l'oggetto WriterVO di cui di seguito è riportata
la prima parte della classe
package
com.mokabyte.cms.web;
public class WriterVO implements Serializable{
static Logger logger = Logger.getLogger(WriterVO.class.getName());
private String biography;
private String userName;
private String firstName;
private String lastName;
private String email;
private String id;
La
prima cosa da notare è l'inserimento della classe
nel package com.mokabyte.cms.client.vo che è
concettualmente e strutturalmente separato da quello
che contient il DTO (che in questo caso sta in com.mokabyte.cms.util).
La seconda cosa importante è la presenza di due
costruttori del VO: uno che permette la creazione del
value object tramite i singoli parametri:
public
WriterVO(){
super();
this.userName="";
this.firstName="";
this.lastName="";
this.email="";
this.biography="";
logger.debug("--- Exit VO creato con
i seguenti valori: "+this.toString());
}
Mentre
il secondo prende in input direttamente un DTO:
public
WriterVO(WriterDTO writerDTO) {
logger.debug("--- Enter - Parameters:
writerDTO=" + writerDTO);
this.firstName=writerDTO.getFirstName();
this.lastName=writerDTO.getLastName();
this.email=writerDTO.getEmail();
this.userName=writerDTO.getUserName();
this.id=writerDTO.getId();
this.biography=writerDTO.getBiography();
logger.debug("--- Exit");
}
Il
significato di quest'ultimo è molto importante:
non appena arrivano i dati dallo strato server tramite
un DTO si trasformano in un VO che verrà usato
per ogni operazione di visualizzazione o manipolazione.
Viceversa se si devono inviare i dati contenuti nel
VO per un aggiornamento del modello dei dati (ad esempio
dopo una modifica del value object tramite form HTML/JSP)
è comodo poter disporre del metodo del VO
public
WriterDTO getDTO(){
logger.debug("--- Enter");
WriterDTO writerDTO = new WriterDTO (this.getFirstName(),
this.getLastName(),
this.getEmail(), this.getUserName(), this.getId(),
this.getBiography(), null);
logger.debug("--- Exit - return WriterDTO="+writerDTO);
return writerDTO;
}
In
questo modo dal VO si passa al DTO in modo trasparente
e l'eventuale operazione di aggiornamento risulta molto
compatta
Ecco
ad esempio cosa accade dentro una classe del model dell'MVC
dello strato web (esempio una action di Struts)
public
Routing perform(HttpServlet servlet, HttpServletRequest
httpServletRequest,
HttpServletResponse
httpServletResponse) throws ActionException {
logger.debug("--- Enter");
HttpSession httpSession = httpServletRequest.getSession();
WriterManagerBD writerManagerBD = (WriterManagerBD)
httpSession.getAttribute("writerManagerBD");
logger.debug("si adopera il writerManagerBD="
+ writerManagerBD);
WriterVO writerVO = (WriterVO)httpSession.getAttribute("writerVO");
logger.debug("si adopera il writerVO="
+ writerVO);
try {
writerManagerBD.updateWriter(writerVO.getDTO());
}
catch (FacadeInvocationException ex) {
String msg = "Problema
di comunicazione con lo strato server - Non è
possibile proseguire";
this.addMessage(httpSession,
"invocationFacadeError", msg);
logger.error("--- Error:
FacadeInvocationException" + ex);
throw new ActionException(msg);
}
httpSession.setAttribute("writerVO",
writerVO);
logger.debug("--- Exit");
return this.getExecutedRouting();
}
Nella
classe DTO non è presente nessun legame con il
VO per ovvi motivi: il DTO non deve legarsi allo strato
client: la sua funzione è quella di traghettare
i dati da uno strato all'altro indipendentemente dalla
collocazione progettuale di tali strati. Il DTO non
ha quindi un costruttore che riceve in input un VO ne
tantomeno dispone di un metodo getVO() sebbene questo
rappresenterebbe un vincolo meno grave ma una utility
inseribile opzionalmente nel DTO.
Slegare
il DTO: il problema del log
Una nota di contorno relativa all gestione dei log dice
che, per motivi analoghi a quanto appena visto, un DTO
non dovrebbe avere nessuna inclusione di classi esterne
appartenenti a framework esterni o simili. Se questa
considerazione appare ovvia in assoluto, può
essere facilmente violata da un programmatore ligio
al dovere e a cui sia stato detto di inserire il log
in tutte le classe della applicazione. L'utilizzo del
framework log4j da questo punto di vista appare la soluzione
ideale e fortemente consigliata per tutte le classi
della applicazione.
Ma in MokaCMS appare subito un problema: una parte del
progetto fa uso di una applet per la scrittura e formattazione
in modalità avanzata del testo dell'articolo.
Appare ovvio che nella applet sia sconveniente inserire
log4j data la pesantezza della libreria nel suo complesso
(sebbene ne esistano delle versioni light appositamente
pensate per questo scopo). Il problema del log4j nel
DTO si è presentato in tutta la sua gravità
nel momento in cui nel CMS si sono dovute implementare
alcune funzionalità di comunicazione applet-servlet
le quali per ovvi motivi di praticità ed eleganza
sono state implementate tramite il classico meccanismo
business delegate - session façade presentato
negli articoli precedenti.
Tale comunicazione fa uso di oggetti di trasporto DTO
per cui l'inserimento di log nel DTO obbliga la applet
a scaricarsi tali librerie.
La soluzione potrebbe essere quella di creare un DTO
apposito log4j-free oppure più semplicemente
creare un DTO sufficientemente testato in modo che non
sia necessario l'utilizzo di un log in fasi successive
di test della applicazione (anche se spesso il log dentro
il DTO è utile per capire quello che accade fuori
dal DTO).
Eventuali messaggi potrebbero in ogni momento essere
prodotti in modo brutale con l'invocazione della System.out.println().
Conclusione
Al termine di questa miniserie dedicata ai DTO iniziata
il mese scorso si dovrebbe avere una visione piuttosto
completa di cosa sia un oggetto di trasporto, di come
possa essere utilizzato e come creare i vari DTO in
funzione delle esigenze applicative.
Come ormai accade sempre più spesso è
impossibile concludere un argomento fornendo la formula
magica per creare il DTO ottimale per ogni situazione.
Molte possono essere le soluzioni e le variabili in
gioco. Dalla complessità della applicazione alle
conoscenze del gruppo di lavoro.
Il consiglio più utile che si possa dare in questi
casi è di seguire un approccio graduale alla
complessità: partendo dall'avere solamente un
DTO che contenga sempre tutte le informazioni della
entità presente nel data model (scelta certamente
non performante), si potrebbero iniziare a creare con
il supporto dell'esperienza DTO specializzati, light
e fullfat, assemblando solo le informazioni necessarie
per ogni use case.
Sicuramente è indicato adottare la filosofia
secondo la quale non si potranno mai avere nel contempo
le tre cose: Buono (ovvero ben fatto e progettato),
Veloce (performante ma anche parsimonioso in termini
di risorse), Economico (che si scrive in poco tempo
e che chiede pochissima manutenzione).
Delle tre in genere si cerca di sacrificare le prestazioni
perché un oggetto ben progettato e implementato
e orientato alla semplicità (quindi anche economico)
è presumibile che poi con poco lavoro possa diventare
anche veloce. Il contraio è ben più difficile
che possa accadere.
Bibliografia
[DTO-1] - Architetture e tecniche di progettazione EJB
- III parte: la trasmissione dei dati fra gli strati
tramite il pattern DTO (introduzione)
http://www.mokabyte.it/2005/12/ejbarchitectures-3.htm
[CMS] - MokaByte CMS pubblicato in modalità Open
Source nell'ambito del progetto MokaLAB - www.mokabyte.it/mokalab
|

