

Introduction
Containers [1] are a new way of creating insulated computing environments. They are more lightweight than VMS and arguably easier to manage.
Even though the container technology is not yet mature enough for wide enterprise adoption, it is already on the radar of many Fortune 500 companies, just after a few years of this technology becoming available. It took several years to virtualization technologies to gain the same level of attention from large enterprises.
I believe that the container technology is here to stay; it is going to live alongside the virtualization technology and potentially even supersede it in time. The same consideration applies to cloud providers: container-based cloud providers will soon appear on the market and will coexist with virtualization-based cloud providers.
In the rest of this article I’ll try to explain what containers are, what they provide, what the gaps are still open and finally which the main players in this technology are.
IT Operations Technology Evolution
To better understand the impact of containers it is useful to take a look at how IT Operations practices have evolved: the picture below shows a brief history of this evolution.
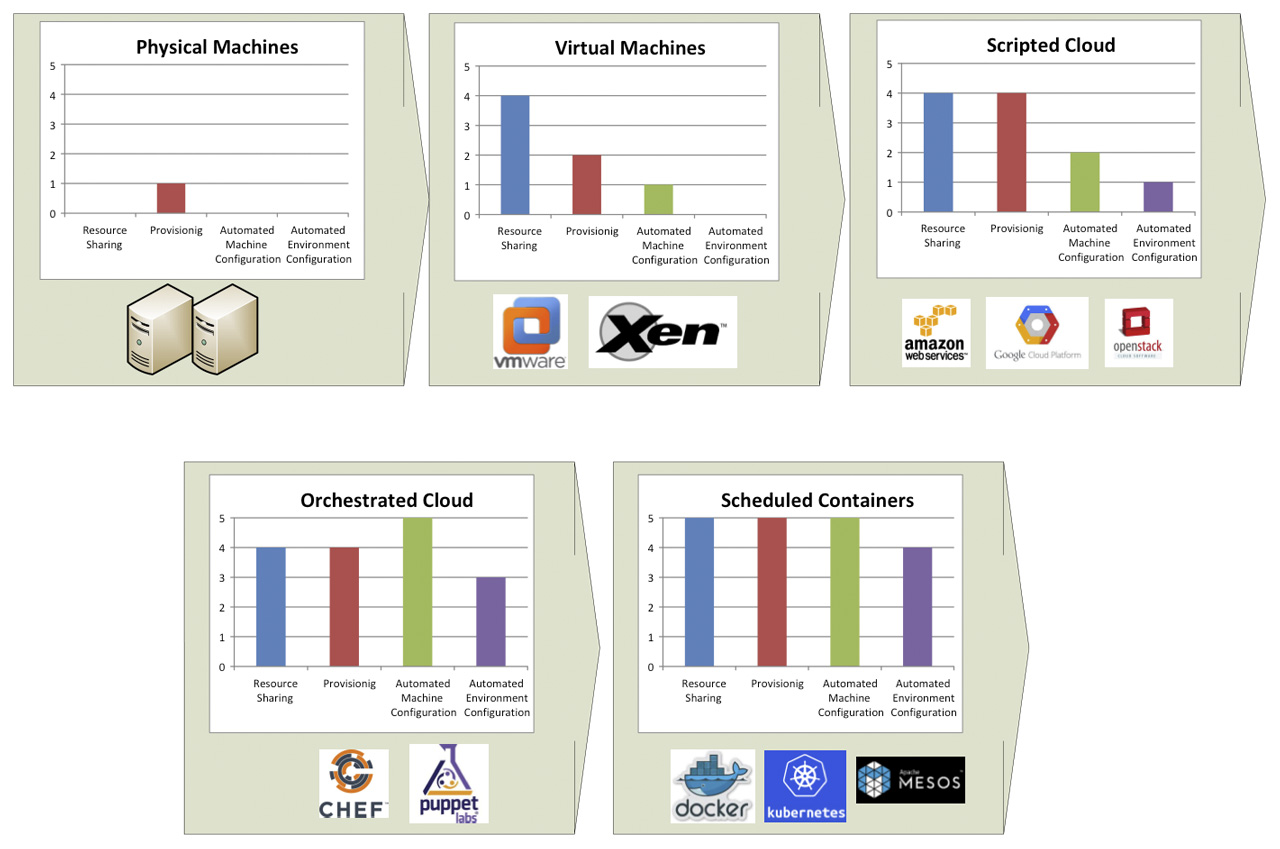
From physical machines to virtualization
Initially there were physical machines. The main problem with physical machines is that procurement is slow because it usually involves a purchase of hardware, there is no resource sharing and configuration and set-ups are manual.
Virtualization addressed some of these problems: for a little performance tax, it was possible to get much better resource sharing by having multiple virtual machines running in the same hardware. Procurement and configuration still involved manual steps.
Cloud computing
The next step was cloud computing. Cloud computing (and in particular the Infrastructure as a Service [2] type of cloud) is a system in which IT resources (compute, networking and storage) are available on demand. Resources not only are available on demand, but they also are available via an API.
It is possible to use these APIs to procure and configure the machines, storage and networking that comprise the solution we need to build; I call this approach scripted cloud. Usually the set of components and configurations that comprise a solution is also called environment. Therefore with scripted cloud it is possible to create scripts that spin up environments on demand. Infrastructure is now described by code (Infrastructure as Code) [3].
Imperative language-based scripts, though, tend to be difficult to maintain and to provide limited reusability; in other words they do not scale easily to large and complex environments. This limitation fostered the creation of more declarative tools.
Orchestrated Cloud
Orchestrated cloud introduced a declarative approach to the creation and configuration of compute, storage and network resources (i.e. environment provisioning). New tools provided a solid approach to applying configurations to newly created machines.
The way most of the tools work is that when the machine starts up, an agent contacts a central configuration management server and downloads from it configuration instructions for the current machine.
These tools have limited capabilities to procure the machines (but procurement is still largely dependent on the underlying cloud technology) and to monitor the machine status and correct it if divergent from the desired state (e.g.: wrong number of active cluster elements, configuration files changed inappropriately).
Chef [4] and Puppets [5] are two examples of this technology. Pure IaaS providers have also added similar capabilities as native functionalities for their platform (e.g.: CloudFormation [6] for Amazon Web Services [7] or CloudDeploymentManager [8] for Google Cloud Platform [9]).
Scheduled Containers
Scheduled containers are the latest addition to this series of technology and methodology improvements. Containers are a better way to provide computing resources than Virtual Machines because they provide better performance and greater resource sharing while retaining approximately the same level of insulation. We’ll spend the rest of this articles talking about containers.
Containers foster the idea of Immutable Infrastructure [10], because they make very easy implementing image-based configuration. Container images are also extremely portable as opposed to VM images. Docker [11] is the most popular container implementation; LXC [1] and Rocket [13] are other existing container implementations.
Orchestrators, in the container world, are customarily called schedulers (hence the name I gave to this technology wave: scheduled containers). Things in this space are changing very rapidly, yet it is worth highlighting the general idea towards which these products are marching. Container schedulers try to create a level of abstraction on top of some physical resources, potentially located on one or more data centers, so that users can schedule their jobs without needing to know where they will be executed. Examples of container schedulers are Kubernetes [13], Mesos [14] and Docker Compose [15].
More on Configuration Management
Configuration management is one of the hardest practices in IT operations. There are many reasons why systems configurations have to change: system patches, security patches, middleware upgrades, application deployments, etc.
Each of the above changes has a different way of being put into production; this means different processes, different tools, and different people working on it. This creates complexity and error prone situations.
Things are different in a cloud environment. Following the immutable infrastructure best practice, the way to apply configuration changes in a cloud environment is simply to recycle the compute resource (either VM or container). By recycling here I mean to shut down the running compute resource and replace it with one with the new configuration. This simplifies operations because there is only one way to apply changes which can be highly optimized. There is no other way to change a computer resource after it has been started; this increases stability by preventing compute resource configuration from drifting away from the desired state.
There are two things to keep in mind to make this approach work. One is how we create and update configuration definitions and the second is how we apply configuration definitions in a way that does not interrupt a service (no planned outages is these days is a common requirement).
Agent-Based vs. Image-Based Configuration Management
There are two schools of thought on how to create and maintain configurations: image-based configuration management and agent-based configuration management.

These are actually two extremes of a continuum and most companies will land somewhere in between, when they define their change management process.
In image-based configuration management there is an image for each server type that we need to instantiate. When the image starts, the server is ready to operate and no additional configuration is needed. Sometimes the server behavior can be tweaked by passing environment variables at start-up or attaching storage with additional configuration files. An advantage of this approach is that generally start-up times are lower than in agent-based configuration management. A drawback of this approach is that the number of images to manage will grow fast and can easily get out of control. This is the strategy generally adopted by containers.
In agent-based configuration management, only very few images exist and have to be managed. A central configuration server applies configuration to VMs when they start-up via an agent that is pre-installed in all images. Puppet and Chef are some of the most popular players in this space.
Cloud Deployment Strategies
The second piece we need to effectively recycle compute resources is a deployment strategy that does not create service outages. In most cases services are provided by clusters of identical machines, so our deployment strategy will need to allow us to recycle the entire cluster.
This field is relatively mature for stateless services. Stateless services are services that don’t rely on a local state. Data stores (either traditional RDBMS or NoSQL) are stateful services. Service layers and web application can be considered stateless services even when they have a session as long as the session is reasonably short in time or the cluster has a session failover capability.
For stateless services there are two well established practices to perform a cluster recycle: rolling deployments and blue-green deployments [16].
Rolling deployments
With rolling deployments each element of the cluster is recycled separately. The request load balancer must actively participate in this deployment by redirecting the request to the appropriate server. The sequence is the following:
- A new server is created with the new configuration and the load balancer starts sending one share of the load to this server.
- An old server is removed from the cluster. If this server uses sessions and a session failover mechanisms is not available, the old server is kept alive until all the sessions are over.
This cycle is repeated until all servers are recycled. This approach has some shortcomings when the number of servers comprising the cluster is very high. In this instance the cluster recycling operation can take very long and that is undesirable. Kubernetes features this capability.
Blue-green deployments
The blue-green deployment approach solves this problem. With blue-green deployments a cluster of compute resources with the new configuration is created alongside the old one. All new requests are directed by the load balances to the new cluster. If the server uses sessions and a session failover mechanism is not available the old cluster is kept online until all the sessions are completed.
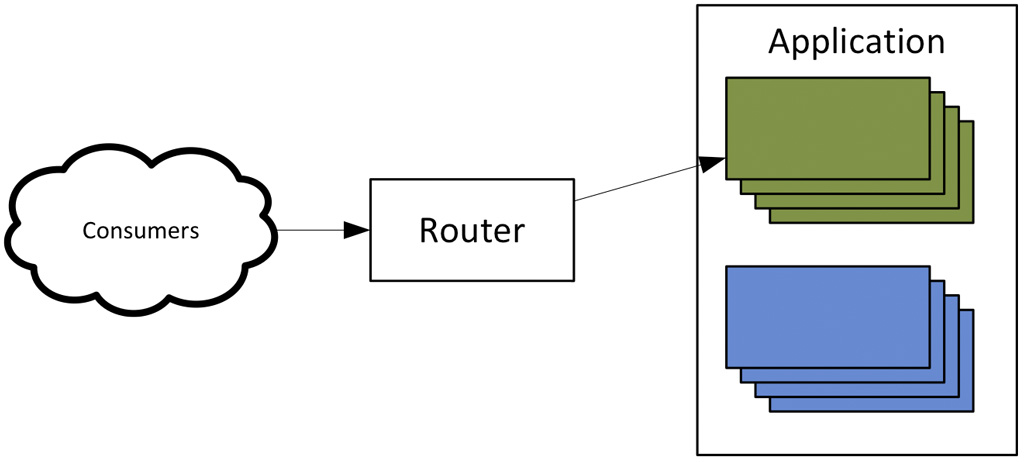
The advantage of this technique is not only faster deployments, but also faster rollbacks in the case a deployment fails. In fact the old cluster does not have to be wiped out right away after the deployment completes and can be kept around as long as the necessary release validations are completed.
Blue-green deployment seems to be the best route when unused capacity is available to and it is possible to safely instantiate two parallel clusters for the service that needs to be updated.
Containers
Linux containers [17] are a technology that allows running Linux processes in an isolated environment. A containerized process runs in such a way that it has a private file system and it doesn’t have visibility of any other processes that is running on the same Linux server.
This type of isolation is achieved using namespaces [18]. With namespaces the following Linux kernel resources can be protected: Inter Process Communications (IPC), networking configuration, root mount point, Process tree, user and groups, and network name resolution. Without getting too technical here, the key take-away is that by using namespaces it is possible to isolate processes in a very effective way. The only thing that a containerized process shares with the hosting OS is the Linux kernel.
In order to manage access to resources, containers use another kernel module called control groups (cgroups [19]). Control groups allows to set quotas, set priorities and meter several types of resources such as memory, CPU utilization, disk I/O, etc.
Historically containers were developed under the LXC project [1]. LXC, although a viable solution, never really became popular, mainly because of usability reasons and limited portability of the containers created with it.
Docker
Docker builds on the above described technology to “build, ship (move), and run Linux containers”. Docker is an open source project and a backing company [20] that provides paid support and services. The strength of Docker and one of the reasons for its popularity is its ease of use.
Docker implements a client-server architecture. The client is a simple shell command line tool that sends commands to the server using REST services (this obviously implies that anyone could build different clients). The server is a Linux daemon that can build images and run containers based on a preexisting image.
Containers can be build interactively and using a configuration file. Interactive build of containers should be used when experimenting and allows one to run some commands that create some changes from within a running container and then commit these changes as a new container image.
Configuration-file based containers can be used when building automated processes. Here [21] is an example of a configuration for a Docker image running CentOS.
Docker images can be stored in a repository to facilitate sharing. Docker offers a product called Docker Trusted Registry that can be installed on premise and also a public repository. Other products are available, for example Artifactory.
Artifact repository
The concept of artifact repository (Nexus [22], Artifactory [23], Archivia [24], etc.) is not new and many automatic dependency management build systems rely on these tools, but Docker pushes the envelope further. In fact the traditional use of an artifact repository is to store the result of builds, maybe after a successful run of an automated integration test suite. Now with Docker, we can store in the repository a container image with a deployed application, ready to run on any server. In other words, configuration settings that usually would be defined at deploy time are also embedded in the image. This increases the reliably of our releases.
![Figure 4 – Docker registries [25].](https://www.mokabyte.it/wp-content/uploads/2021/08/ContainersITOps_EN_04.jpg)
Union file system
A very interesting feature of Docker is the way the file system is managed. Docker uses a union file system [26] implementation to compose the file system that will be visible to the container. Union file systems (such as UnionFS or aufs [27]) allow merging several file systems and mounting them in a single mount point. A Docker image is really a set of files organized in directories (a file system, in essence). A Docker image can be built on an existing image by adding/changing some files. This can be repeated an unlimited number of times. An image can for example be constituted by four layers (this concept is also known as layering images).
In the previous example, when the Docker image is run, the 4 files systems are merged together in read only way and an additional layer is added on top of them in read-write mode.
![Figure 5 – Layered file system [28]](https://www.mokabyte.it/wp-content/uploads/2021/08/ContainersITOps_EN_05.jpg)
If two containers share some of the image layers, these layers don’t have to be replicated in the host files system because they are mounted in read-only mode. This can generate significant savings especially if a company employs some discipline in prescribing how images can be created, by for example saying that all images have to derive from a common base. Because the common base image is very likely going to be the layer that takes the most disk space and all the other layers are going to add minor installations or configurations, this simple guideline could save a large amount of disk space.
Containers vs. VMs
The following picture compares and contrasts Container and VMs, assuming that all container implementation will use the same approach as Docker for organizing images.
![Figure 6 – Containers vs. VMs [29]](https://www.mokabyte.it/wp-content/uploads/2021/08/ContainersITOps_EN_06.jpg)
As we can see, the main advantages of containers are: less consumption of memory and disk storage. Containers use less memory because all containers in a host share the same kernel. Containers use less disk storage because container images can be shared by containers running on the same host.
From a security perspective the general consensus seems to be that VMs are more secure and more insulated than containers. I believe that this will change as the container technology matures.
Docker Support for Windows
Docker supports only Linux containers. This is obviously a significant limitation. Microsoft has stated that Windows Server 2016 will support containers in a Docker compatible way [30]. By the time this article is published some beta releases of Windows Server 2016 should be out, while support for Windows containers [31] in Azure Cloud is available today. Support for Windows containers is coming, but it will be initially less mature than for Linux.
Beyond Docker
Docker as a project was born with the objective of simplifying the creation and management of containers. Docker is very good at that and I believe the Docker team has been very good at keeping the scope of this project clear and limited. Docker is a building block for container-based clouds.
With respect to building a container-based cloud environment the main areas to keep in mind are:
- Container scheduling
- Advanced Networking
- Monitoring
- Quotas and metering.
Let’s examine each of these separately.
Container Scheduling
Container scheduling is the ability to define and spin up an environment potentially comprised of several containers. As we said, this concept is similar to orchestration in VM-based cloud environments.
Through container scheduling we should be able to define the right sequence of activation of containers, the size of the cluster of containers that we need to create and the Quality of Service of the containers that we need (for example an app may require a minimum amount of memory or of disk I/O).
Advanced orchestration tools also guarantee that a given environment reflects the desired state after it has been created. This implies that these orchestration tools can also do some type of monitoring and perform some type of self-healing if the current state of the environment does not align with the environment definition. Another important feature, common to many container schedulers, is the ability to define an abstraction around a cluster of identical containers so that they are seen as a service (i.e. one IP address and one port). This is achieved by having the scheduler set up a load balancer in front of the cluster of containers and the necessary routing rules.
Some of the tools available in this space are the following: Kubernetes, Mesos, and Docker Compose.
Kubernetes
Kubernetes is a container scheduler open sourced by Google. Google claims they have been using containers for the last ten years and Kubernetes is a way to share some of the experience they have accumulated with the rest of the world.
Kubernetes introduces the concept of pods. Pods are sets of containers that need to be co-located in the same host. There are several situations or patterns in which this feature is required; for example, an application may require a log forwarding companion app [32].
Kubernetes also introduces the concept of replication controller. The replication controller’s task is to make sure that all the pods of a cluster are healthy. If a pod is down or not performing as expected the replication controller will remove it from the cluster and spawn up a new pod.
Also, Kubernetes tries to be portable across private Docker implementations and public cloud Docker implementations. This is achieved through a plugin-based architecture. For example the load balancer configuration necessary for the definition of a service will activate a different plugin if the Kubernetes project is deployed in Google Cloud as opposed to Amazon Web Service. There are plans to add plugins for attaching different types of storage and performing different types of deployment, attaching different security providers, etc.
Mesos
Mesos is an open source project hosted by the apache foundation. The objective of the Mesos project is to provide “a distributed kernel system”. Mesos tries to take the principles on the Linux kernel on process scheduling and apply them to a cluster or an entire datacenter.
Mesos was started in 2012 and has been recently refactored to manage Docker containers. Mesos uses ZooKeeper [33] to bring the concepts of services to life.
Mesos excels on portability and it is possible to create Mesos clusters that span different data centers and different cloud providers.
Docker Compose
Docker compose is a recent addition to the Docker toolset. Compose is not to be considered production ready yet and is not well integrated with Docker swarm (which is the Docker cluster management tool).
At the time of the writing Docker Compose support the ability to control the life cycle of an application comprised of multiple containers running on the same host.
The Knapsack Problem
If we spend some time thinking about what a container scheduler really does, we realize that the main problem it needs to solve is maximizing the utilization of the physical resources that they manage. We have already said that containers are better at that than VMs, but how do we maximize the utilizations on out physical infrastructure while also meeting the constraints that each application has?
Examples of constraints are:
- Technical needs: amount of ram available, type of CPU, I/O needs, presence of GPU processors, type of OS (in the future Microsoft containers will also be supported).
- Topological constraints: for availability reasons we want the members of a cluster to not be deployed on the same host or rack or even datacenter. On the other hand we may want some containers to be co-located in the same host (see Kubernetes pods below).
- Load type: load priority, batch vs online types of load.
This problem is a variant of the knapsack problem [34] in which one has to find the best way to put objects of different shape and weighs in knapsack of different shape and size. The knapsack problem in a NP-Complete [35] problem so there is no way to have solution that it both fast and optimal. Therefore it is best to have a program solving this problem especially in a cluster with a large number of nodes.
Unsurprisingly research [36] from Google shows that mixing different types of load (online vs batch, cpu-bound vs memory-bound vs I/O bound) helps maximizing resource utilization. Surprisingly the same research also shows that over-commitment of resources is a good load allocation strategy (Google researchers add that they overcommit only their internal load and they don’t use this strategy for their public cloud service). In a recent release of Mesos over-commitment is available as an allocation strategy.
Networking
Docker provides a virtual switch (Layer 2 routing) to allow network communication between containers among themselves and container and the rest of the world. There is no support in Docker for firewall (Layer 3 routing), reverse proxy (Layer 7 routing), load balancing and virtual networks of containers (useful in multitenant implementations or wherever network insulation is required).
These features are necessary in real world deployments and Docker does not try to address them. As we have seen container schedulers are trying to fill this gap especially focusing on providing firewall and load balancing capabilities. The problem is not fully solved and definitely not solved in portable way (across different Docker cluster implementations).
Some tools are trying to help filling these gaps: Flannel [37], Weave [38] and other.
Flannel and Weave address the problem of creating virtual networks among containers. They both work by adding a virtual router (Layer 3 routing) in cascade of Docker virtual switch and an agent to manage the virtual router configuration. In both cases the lack of full integration with Docker or a container scheduler introduces some often manual configuration steps, which seems to be a limitation at this point in time. I believe these tools or similar will soon be part of container schedulers.
There are no clear solutions that I’m aware of for reverse proxy capability, so this function will need to be addressed by some dedicated software (potentially running in a container).
Security
Docker covers some aspects of security, such as container insolation, but it does not address everything. More specifically it is a responsibility of the Docker cluster implementer to provide security around the Docker daemon. This becomes of paramount importance in a multitenant Docker implementation.
The container schedulers that we have analyzed have some initial implementation of security hooks so that they can be integrated with enterprise-level security systems.
This is an area that will see a lot of development, as containers will be more and more adopted by large enterprises.
Quotas and metering
As we saw, containers can enforce resource utilizations of a single container. But there is no good way in Docker to enforce the overall resource utilization of an environment (a set of containers) spun off by a user. This control is crucial to prevent an erroneous configuration introduced by a team taking down the entire Docker cluster by exhausting its resources.
This is clearly a task that should be performed by the container scheduler. Kubernetes addresses this concern. Mesos has some limited feature in this space.
Metering of resource usage is another important aspect. This information will be used to produce resource utilization reports, show-back or chargeback processing and billing for paid services. Docker has a good support for container-level metering. Tools to aggregate information at a cluster level need to be added to the solution.
Monitoring
Docker and the tools around it such as Kubernetes and Mesos have been built with the ability to feed statistics to monitoring tools. All these tools can provide very rich information on the status of the host nodes and the containers housed in them. It is expected that all this information will be gathered and analyzed by downstream tools. Open source tools that can help manage the large amount of data generated by Docker cluster and make sense of it are Graphite [39] or InfluxDB [40] and Grafana [41].
Conclusions
Both Google [42] and Amazon [43] have recently extended their cloud services to support containers. In these initial releases, containers are run on VMs. I believe we will soon see the rise of native container-based cloud providers. This will accelerate the maturing of cloud schedulers in those areas that have been neglected so far such as advanced networking and security.
Containers simplify significantly the long lasting problem of portability of VMs and entire environments across clouds. Support for deployments of container on multiple cloud providers will be a feature that many container schedulers will have (Mesos already does). Deploying across cloud providers obviously decreases the lock-in to the cloud vendor and it can also be used as a disaster recovery strategy.
Portability across cloud providers can also be used to negotiate better prices. I believe in the future cost will be used as one of the input parameter to the scheduler when deciding where to allocate the load of a given job. Today cloud service broker arbitrage [44] is done by very few enterprises and it involves manual steps often with the help of niche companies. In the future, cloud service brokerage will be performed by the container scheduler dynamically for each job request.
Raffaele Spazzoli ha lavorato per piu di 10 anni a Imola Informatica come consulente con il ruolo di architetto delle applicazioni e delle integrazioni.
Attualmente lavora in KeyBank, una banca statunitense, come architetto dei canali fisici (filiali e contact center) e digitali (web e mobile).