

Introduzione
Cominciamo con questo articolo una serie che affronterà aspetti vari della Continuous Integration (CI): l’integrazione continua è ormai entrata a far parte delle pratiche seguite dagli sviluppatori in contesti diversi e ha ormai alle spalle una serie di esperienze, trattazioni, riflessioni che ne fanno uno degli argomenti più conosciuti.
Ciò di cui parlerò in questo e nei successivi articoli vuol rappresentare uno sguardo ad alcuni temi peculiari di queste pratiche, con l’intenzione di riuscire magari ad affrontare alcuni argomenti più specifici o che presentano elementi non sempre trattati nell’applicazione della CI.
La nascita della CI
La Continuous Integration è una delle numerose pratiche “figlie” dell’eXtreme Programming (XP) che, è indubbio, ha segnato una delle più decise “rivoluzioni” nel mondo dello sviluppo software nel passaggio tra gli anni Novanta e il nuovo secolo [1].
Come molte altre pratiche XP, ad esempio il pair programming [2] — la Continuous integration nasce, estremizzando la soluzione a problemi comuni. Il problema a cui si risponde con la CI è il la divergenza delle versioni del codice e quindi le conseguenti integrazioni bibliche che a volte portano addirittura a dover rinunciare a pezzi di software sviluppato. Se ancora non avete letto il libro Extreme Programming Explained: Embrace Change [3], consiglio di farlo, perché questo testo potrebbe essere davvero utile a darvi diversi spunti.
Che cos’è la Continuous Integration
Per quanto oggi possa sembrarci “assurdo”, per molti anni la prassi dello sviluppo è stata quella di creare “indipendentemente” dei componenti software che poi andavano integrati in un secondo tempo. E quando arrivava questa seconda fase, spesso erano dolori. Ci si ritrovava con porzioni di software a volte decisamente divergenti perché sviluppate per lunghi periodi di tempo senza “agganciarle” alle altre: il termine coniato per definire tale situazione fu integration hell, un vero “inferno dell’integrazione”.

La soluzione proposta in ambito XP fu l’integrazione continua che, almeno a livello concettuale, è piuttosto semplice: ogni piccolo commit di codice che facciamo nel nostro sistema di versionamento (Version Control Systems, VCS) preferito (git, Subversion, Mercurial, etc.) deve essere integrato il prima possibile e automaticamente da una macchina appositamente configurata che eseguirà la compilazione del codice e lancerà la suite di test, il che significa: “compila tutto senza rompere niente”.
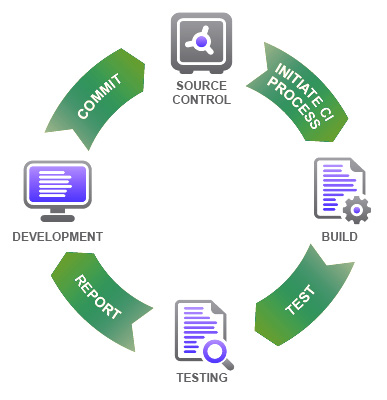
Il peso delle dipendenze
I concetti e le tecnologie che concorrono alla creazione della Continuous Integration possono contribuire a gestire l’annoso problema derivante dall’aggiornamento delle dipendenze.
Aggiornare frequentemente le librerie, badando bene di prendere sempre le versioni più stabili, è senz’altro un modo per affrontare poco alla volta la necessità di fare un aggiornamento obbligato per software oramai datato.
L’integrazione continua ci aiuta in tal senso ad affrontare i rischi dovuti all’incompatibilità prima che essi si evidenzino in modo “drammatico”. E magari ci aiuta a capire che forse è il caso di cambiare dipendenza: nulla è per sempre e ciò che solo qualche anno fa poteva apparire come la libreria di riferimento, adesso potrebbe non essere più il meglio, almeno per il nostro software.
Così fan tutti
Sappiamo bene che a volte non si seguono alla lettera i dettami della buona architettura, nonostante li si conosca bene e li si metta generalmente in pratica. Però accade anche che, quando si gettano le fondamenta di un progetto, si scelgano le tecnologie e i framework che faranno parte del core accoppiando fortemente la business logic ai framework: sappiamo bene che non è consigliabile, ma si fa. Alcuni esempi? Rails con active record, Spring nel suo modulo core etc…
Si iniziano poi a sviluppare le diverse funzionalità, con il risultato che il nostro sistema cresce. Questo comporta che talvolta si inseriscano ulteriori dipendenze, andando a pescare tra ciò che in quel momento ci sembra più interessante e funzionale: la complessità del sistema cresce esponenzialmente.
Nel breve, tutto a posto, specie per chi lavora a un progetto, lo consegna e poi va in mantenimento: dovrà fornire qualche patch, preoccuparsi di risolvere qualche bug… ma niente di più complesso.
La sostenibilità tecnica delle dipendenze
Ma c’è anche chi lavora su prodotti che crescono nel tempo e lo fa in un contesto di sviluppo iterativo incrementale: personalmente è quello che mi succede in questi ultimi anni e che mi ha fatto capire come accumulare un crescente debito tecnico sia un male da evitare. E non curarsi delle dipendenze è sicuramente una forma importante di debito tecnico.
Il team Agile, nei vari framework organizzativi, è responsabile della qualità interna del prodotto: questo significa che, mentre si occupa di rilasciare funzionalità, deve anche garantire una “sostenibilità” a lungo termine e idealmente l’assenza di bug, vale a dire che deve procedere in maniera che il sistema stia in piedi continuamente.
Come dice Uncle Bob [4], “non cedete al lato oscuro!”. Chiaramente il business spingerà il team di sviluppatori a fare sempre di più e sempre più in fretta. Ma è un errore cedere al di più a scapito del bene: è vostra esclusiva responsabilità fare le cose fatte bene.
E fare le cose bene significa anche approntare all’interno del ciclo di sviluppo pratiche ingegneristiche che contemplino l’integrazione dell’aggiornamento delle dipendenze: è senz’altro un modo per rendere più robusto il vostro software. Farlo vi aiuterà anche a risolvere problemi di performance e security.
Gestire le dipendenze in pratica
Come stavamo dicendo prima, la Continuous Integration è nata per combattere il problema della divergenza del codice. Senza questa pratica probabilmente saremmo spinti a toccare il meno possibile il codice e ad affrontare lo sviluppo in maniera molto difensiva. In realtà, anche se ci sembra di fare il contrario, agendo in questo modo si finisce per complicare la codebase. Ma la Continuous Integration da sola non basta, se non è accompagnata da uno sviluppo supportato dai test; in ogni caso, però, ci aiuta a gestire molti noiosi fastidi.
Che cosa è la versione di una libreria, se non un’etichetta che fissa un determinato commit? E cosa succede quando si decide di legare le fondamenta del nostro progetto a quella versione? Accade che da quel momento in poi iniziamo a divergere con la versione; più il tempo passa e più noi non ci preoccuperemo di raccordare la divergenza, più sarà difficile gestire la riconciliazione.
Dato che la versione della libreria è la nostra dipendenza, l’aggiornamento della stessa può andare in diverse direzioni, che vedremo qui di seguito, alcune delle quali rappresentano dei cambiamenti più drastici nella nostra dipendenza rispetto ad altri.
Esistono delle precise convenzioni di versioning, come quella della Apache Software Foundation [5], a cui facciamo riferimento. Basandosi su questo schema, i casi possibili sono i seguenti:
- la versione è salita di una patch version;
- la versione è salita di una minor version;
- la versione è salita di una major version.
Vediamoli nel dettaglio
Patch version
Se la versione è salita di una patch version, possiamo ritenere che si tratti di un commit atomico o una serie molto breve che risolve un piccolo bug. In questo caso, il comportamento è piuttosto semplice: integrate, vedete se tutto compila e se i test girano tutti. Nel caso ci sia qualche problema, non sarà difficile sistemarlo, poiché si tratterà nella maggior parte dei casi di piccole modifiche.
Minor version
Se la versione è salita di una minor version, metaforicamente consideriamo come se fosse un commit non troppo grande (o una serie corposa): tipicamente è stata aggiunta qualche nuova funzionalità che non “rompe” le precedenti, oppure ci possono essere migliorie di performance o di sicurezza. In tale scenario, occorre anzitutto leggere con attenzione il changelog, ma poi si può procedere con passi analoghi a quelli visti per il caso precedente.
Nelle minor spesso capita che alcune chiamate che facciamo potrebbero essere segnate come deprecate: questo accade più frequentemente nei linguaggi tipati o con le API di un servizio. Tipicamente si fa riferimento a un nuovo modo di utilizzare lo strumento. Ascoltiamo il feedback e modifichiamo le parti di codice interessate, anche perché questi cambiamenti potrebbero essere “propedeutici” a quanto avverrà con la successiva major release: fare bene ora questo lavoro potrebbe risolvere un po’ di problemi in futuro.
Major version
Nei primi due casi non dovrebbero sussistere enormi difficoltà: in breve tempo vi sarete portati a casa fix di bug e piccoli miglioramenti che renderanno il vostro sistema più stabile e che… consentiranno ai vostri capelli di aspettare un altro po’ prima di cadere.
Il caso più difficoltoso, come avrete intuito, è l’aumento di una major version. Ricordate quando, all’insegna del motto “se non è rotto, non lo toccare”, dicevo che l’approccio “conservativo” è quello di mettere il meno possibile le mani nel software? La ragione per cui questo modulo troppo “difensivista” non funziona a lungo termine è che tipicamente le software house offrono un supporto limitato alle versioni precedenti e nel tempo tendono ad abbandonarlo; pertanto è conveniente passare il prima possibile alla nuova versione, e saltare sulla nuova barca prima che quella da cui veniamo affondi.
Il passaggio però potrebbe essere comunque impegnativo: è necessario leggere attentamente il changelog e munirsi di guide alla migrazione, qualora esistano.
Nel caso di framework che fanno un setup iniziale, potrebbe essere utile ad esempio creare un nuovo progetto base e confrontare le configurazioni per individuare così più rapidamente i punti di frizione.
In alcuni casi invece sarà necessario fare un lavoro più impegnativo in quanto si toccano troppi punti del vostro software. Si deve cogliere l’occasione per applicare i principi della clean architecture di Uncle Bob e provare a disaccoppaire la business logic dalla dipendenza.
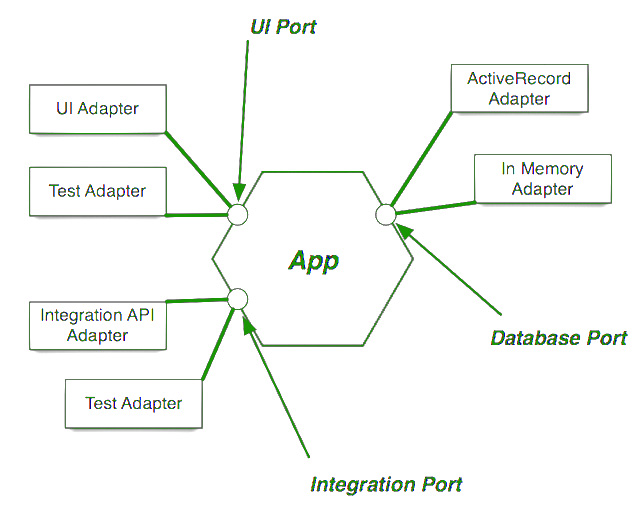
Implementate un adapter che sarà il vostro punto di frizione fra la versione vecchia e la vostra business logic, dopodiché iniziate a implementare incrementalmente il nuovo adapter che utilizzerà la nuova versione. Quando tutte le chiamate saranno sostituite — ad aiutarvi potrebbe esserci un log appositamente configurato — potrete mandare in pensione la vecchia dipendenza e così avrete portato a casa due risultati: un aggiornamento importante e un’architettura più pulita.
Le dipendenze: poche e aggiornate
Talvolta il lavoro di integrazione è veramente grande e a quel punto potrebbe aver senso procedere incrementalmente. Se avete costruito una buona architettura esagonale, potreste iniziare a implementare un nuovo adapter al quale incrementalmente passerete responsabilità; ma questa non deve essere una scusa per tirarla troppo per le lunghe! In ogni caso cercate di non demordere e di trovare una strategia per risolvere l’aggiornamento.
Se da un lato le dipendenze vanno aggiornate, dall’altro il consiglio spassionato è di cercare di usarne meno possibile, per evitare che questo lavoro di integrazione diventi eccessivo. Per quanto possa essere guidato da una buona pratica che ci suggerisce di spalmare nel tempo il costo, rimane comunque un lavoro considerevole, che oltretutto, come abbiamo visto, non va procrastinato più di tanto.
Diffidate della lussureggiante facilità con la quale framework e librerie vi seducono: un accoppiamento eccessivo con un determinato prodotto è sempre un rischio ed è sempre meglio disaccoppiare a sufficienza. Se proprio dovete affidarvi fortemente a una dipendenza, fatelo nei confronti dei prodotti forniti da aziende “robuste” pronte a fornire tutte le informazioni a corredo del loro prodotto.
Conclusioni
In questo articolo abbiamo cominciato a parlare di Continuous Integration con una panoramica sul tema delle dipendenze del nostro prodotto sofwtare da librerie e componenti di terze parti. All’insegna del “prevenire è meglio che curare”, abbiamo visto come la strategia da seguire sia quella di disaccoppiare per quanto possibile, scegliere poche e sicure dipendenze, e aggiornarle il prima possibile.
Nei prossimi articoli, continueremo a trattare questi argomenti, analizzandone aspetti ulteriori.
Fabrizio Machella è uno sviluppatore software, laureato in Ingegneria Informatica. È fortemente interessato ai temi legati all’Agilità, al Lean e alle Startup. Ha fatto parte di team XP, ma le sue esperienze lavorative più recenti sono andate tutte nella direzione Agile. Attualmente lavora in una multinazionale italiana che adotta le pratiche di sviluppo software agili nei propri progetti.