

Introduzione
Nel primo di questa serie di articoli abbiamo spiegato alcuni concetti di statistica robusta e di ricerca di outlier in una popolazione, e perché essi siano importanti nel data mining. Abbiamo anche dato una breve introduzione a FSDA, un toolbox sviluppato in MATLAB che offre un’ampia scelta di funzioni statistiche e grafiche per la ricerca di outlier. In questa seconda parte descriviamo un caso — per certi versi un po’ particolare — di applicazione di testing automatico al codice del progetto FSDA.
Il contesto
Il progetto FSDA [1] è completamente open source e, come tale, è disponibile sotto forma di un archivio scaricabile e installabile: a seconda della piattaforma, un semplice .ZIP da scompattare manualmente o un eseguibile autoinstallante. Il suddetto archivio contiene tutte le informazioni necessarie per essere subito operativi: funzioni (matematiche statistiche, grafiche, etc.) scritte in MATLAB, un help online completo, utilità e numerosi data set di esempio. Le funzioni scritte in MATLAB costituiscono il “cuore” del toolbox.
Lo schema dei nuovi rilasci di MATLAB prevede l’uscita di due release all’anno, tipicamente una in primavera e una in autunno, più patch aggiuntive quando necessarie. Le release principali sono etichettate secondo lo schema
“R” + anno + (“a” | “b”)
dove “a” indica la release primaverile e “b” quella autunnale. Ad esempio, nel 2018 sono previste la R2018a (uscita a marzo) e la R2018b. Ogni release reca in dote una discreta quantità di cambiamenti.
Dato che il progetto FSDA è portato avanti da una decina d’anni, uno dei problemi principali che gli sviluppatori del progetto si sono trovati ad affrontare è la compatibilità del codice con le varie versioni di MATLAB. Anche se le versioni più vecchie sono ormai poco utilizzate, è comunque vero che la qualità di un software si misura anche dalla consistenza dei risultati ottenibili.
Le problematiche
Quando, alcuni anni fa, mi è stato chiesto di dare un contributo alla gestione e alla qualità del progetto, per prima cosa abbiamo allestito un sistema di controllo di versione, necessario anche perché il progetto è rapidamente cresciuto in dimensione, numero di partecipanti e dislocazione geografica.
Successivamente, è scaturita l’esigenza di verificare in modo automatico la compatibilità del codice con un’ampia lista di versioni di MATLAB le quali, come abbiamo visto poc’anzi, escono regolarmente con frequenza abbastanza elevata.
Test automatizzati
Nel caso di un progetto nuovo, la best practice più consolidata consiste nell’adottare un processo di sviluppo software basato sull’uso esteso di test di unità: il codice vero e proprio evolve insieme ai test; anzi, negli approcci di test-driven development più puro, addirittura si sviluppa come conseguenza di questi ultimi.
L’esecuzione dei test è automatizzata in modo tale da avere una rapida ed efficace “retroazione” che consenta di apportare modifiche tempestive sul codice in caso di fallimento dei test stessi. Questo processo è più efficace se accompagnato all’uso di un moderno linguaggio orientato agli oggetti.
Le specificità di FSDA
Il progetto FSDA presentava alcune specifiche peculiarità:
- progetto esistente da diversi anni, con una “base di codice” già abbastanza grande e consolidata;
- progetto non composto da una o poche applicazioni complesse — tipico caso di applicazione enterprise —, ma da un gran numero di funzioni matematiche e statistiche, le quali sono usate come “mattoni” per sviluppare software più complessi;
- MATLAB ha una sua sintassi orientata agli oggetti, ma il team di sviluppo è composto prevalentemente da statistici e matematici, e non è stato possibile organizzaare un adeguato programma di formazione.
Alle particolarità di cui sopra si aggiunga anche la necessità di arrivare a un risultato in un tempo ragionevole e richiedendo il minimo sforzo possibile da parte degli sviluppatori. Nonostante MATLAB offra il suo sistema di test di unità, non c’erano le condizioni per sviluppare da zero un insieme di test necessario ad assicurare una copertura del codice ragionevolmente estesa.
La soluzione adottata
L’idea per mettere in pratica una soluzione mi è venuta guardando la documentazione delle funzioni MATLAB di FSDA. Fin dall’inizio il team di sviluppo ha profuso uno sforzo notevole nel dotare il progetto di una ricca documentazione, ben integrata nell’help online di MATLAB.
Quasi tutte le funzioni possiedono una sezione di commenti, che descrive in modo dettagliato il comportamento della funzione, tutti i suoi parametri e i valori restituiti. Per ogni funzione sono presenti uno — o, spesso, molti — esempi che l’utente può copiare ed eseguire immediatamente nell’IDE di MATLAB il quale, essendo nato come software di elaborazione numerica e matematica, a differenza di altri linguaggi possiede una console interattiva in cui è possibile effettuare calcoli, tracciare grafici ed eseguire intere porzioni di codice.
La documentazione delle funzioni
Nella sezione della documentazione, ogni esempio fruibile è circoscritto da due delimitatori: %{ e %} (il carattere % in MATLAB apre un commento, come // in Java e altri linguaggi). La figura seguente contiene un esempio di come appare la documentazione di una funzione (alcuni commenti sono stati omessi per brevità):
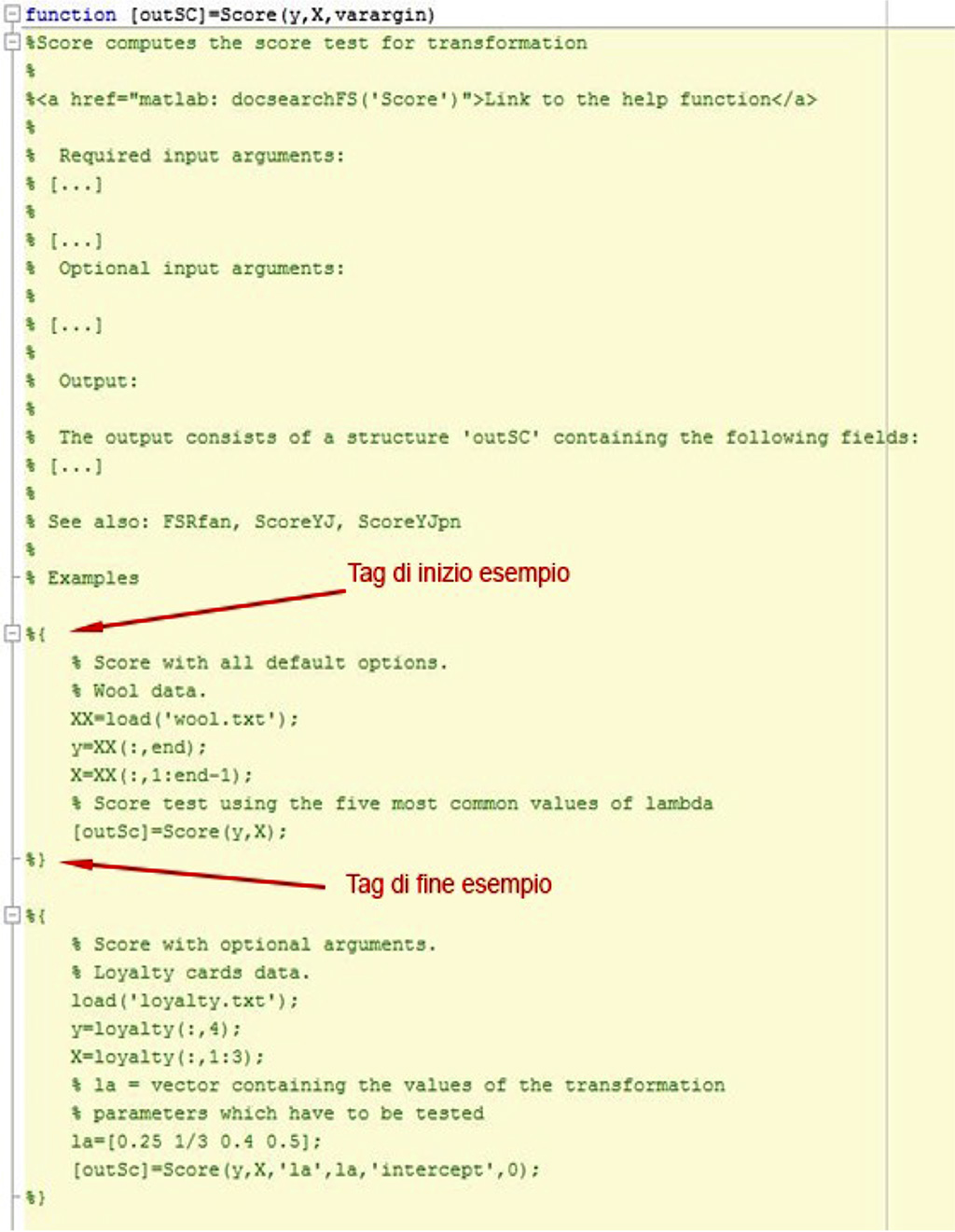
Nella metà inferiore della figura ci sono due esempi completi relativi alla funzione. Basta selezionare le righe nell’editor e premere F9: il codice selezionato verrà immediatamente eseguito nella console di MATLAB e l’utente avrà subito a disposizione i risultati. Gli esempi come questi in tutto il codice di FSDA sono diverse centinaia.
Partire dagli esempi…
Quindi mi sono domandato: perché non utilizzare gli esempi già disponibili come base per i test automatici?
Questi esempi, essendo “annegati” nel codice, richiedono un lavoro di filtraggio ed elaborazione per poter essere eseguiti in modo automatico. Con i colleghi abbiamo quindi sviluppato un insieme di script in bash e awk che estraggono questi esempi dalle funzioni MATLAB (file con estensione “.m”) usando come riferimento i tag di inizio e fine — %{ e }% — e scrivendo ciascuno di essi in un file MATLAB separato.
…e arrivare ai test
Il flusso di lavoro completo è il seguente:
- Eseguire un checkout pulito di tutto il codice sorgente MATLAB dal sistema di controllo di versione.
- Scandire ogni funzione di FSDA con estensione .m estraendo tutti gli esempi racchiusi fra {% e }% e mettendo ciascuno di essi in un file .m
- Costruire un unico file detto m contenente le chiamate a ciascun file .m di esempio estratto al punto precedente. Ogni chiamata è racchiusa in un blocco try…catch automaticamente generato, che in caso di errore scrive su file un esito (pass/fail) sempre uguale. All’esito del test sono allegati eventuali messaggi di errore contenuti nell’eccezione.
- Eseguire l’intero m con ogni versione di MATLAB scelta, in questo caso lanciata in modalità headless, cioè non interattiva.
- L’esecuzione di test_runner produce un file di log formattato in modo standard, che può quindi essere elaborato automaticamente per ricavare statistiche — p.e., il numero di test passati/falliti — e la lista dei test che falliti.
- Inviare per e-mail ai partecipanti del progetto i resoconti dei test e i file .m dei singoli esempi estratti. In questo modo gli sviluppatori possono valutare l’esito dei test e apportare eventuali azioni correttive.
Tutti gli script usati per automatizzare i passi da 1 a 6 sono compatibili con la shell Unix di Windows, Cygwin. Il workflow è stato a sua volta implementato in Jenkins [2] tramite un cosiddetto job, ed è attualmente eseguito con cinque versioni di MATLAB uscite nell’arco di oltre otto anni (R2009b, R2012a, R2014b, R2016b e R2018a). In questo modo è possibile tenere sotto controllo anche eventuali differenze di comportamento tra versioni diverse. La seguente figura contiene un estratto del test_runner con l’inizio del blocco try…catch che racchiude ciascun esempio:

Gli esempi estratti da ciascuna funzione MATLAB sono numerati sequenzialmente con suffissi opportuni (“_ex01”, “_ex02”, ecc.). Nel sorgente sono previsti tag speciali per gli esempi non adatti all’esecuzione automatica, come ad esempio quelli che richiedano l’interazione con l’utente (grafici/plot con selezione, click, etc.).
Questo sistema non permette di avere dati dettagliati sulla copertura del codice, come fa ad esempio Cobertura [3] con Java. Tuttavia esiste con poco sforzo la possibilità di tenere sotto controllo in modo visivo l’evoluzione nel tempo dei test eseguiti con successo o falliti tramite il protocollo TAP [4]. Nel nostro caso, un job di Jenkins in cascata al job principale di test.
Conclusioni
L’approccio qui descritto ha dimostrato sul campo di avere alcuni vantaggi concreti: è minimamente invasivo nei confronti del codice già esistente, ha fornito “quasi gratis” un notevole numero di test (oltre 900!) pur richiedendo uno sforzo di sviluppo abbastanza modesto, e ha permesso di trovare diversi bachi nel codice, anche di tipo prestazionale.
Allo stesso tempo, in alcuni punti c’è margine di miglioramento. In primis, è necessario fare di più per confrontare i risultati dei test con valori noti. Inoltre, i test non sono stati concepiti per essere eseguiti in breve tempo: l’intera suite richiede infatti circa due ore per ogni versione di MATLAB.
Con questi tempi una vera integrazione continua — cioè l’esecuzione di tutti i test ad ogni singolo commit nel repository dei sorgenti — non è realizzabile: di conseguenza, l’intera suite viene lanciata da Jenkins la sera a istanti programmati alcune volte alla settimana, in modo tale che i membri del team di sviluppo si trovino nella mail il resoconto completo appena arrivati al lavoro la mattina successiva. Pur non essendo la soluzione ideale, è un compromesso ragionevole dal momento che la frequenza dei commit nel repository dei sorgenti al momento non è molto elevata.
Professionista dell'informatica da oltre vent'anni, Emmanuele Sordini ha iniziato la sua carriera in una multinazionale tuttora attiva nel campo dell'automazione ferroviaria, per poi approdare a una importante realtà internazionale della ricerca.
La sua attuale attività si focalizza soprattutto sulla gestione del ciclo di vita del software e dei processi ad esso collegati: design, implementazione, progetto di architetture, testing, ecc. Oltre a ciò, si occupa anche di data mining e di implementazione software di algoritmi statistici.