


Introduzione
I Large Language Models (LLM, che potremmo tradurre in italiano come modelli linguistici di grandi dimensioni) come ChatGPT, Gemini, DeepSeek e Claude sono da tempo diventati strumenti integrali del lavoro quotidiani di numerosi individui e aziende. Un numero significativo di lettori è sicuramente familiare con questi modelli, e li utilizza per varie applicazioni nella loro vita personale e professionale. Tuttavia, mentre gli utenti interagiscono regolarmente con queste tecnologie, non tutti hanno una comprensione sufficiente della loro struttura e funzionamento. L’obiettivo di questa serie di articoli è fornire ai lettori una spiegazione informale, priva di gergo tecnico, ma dettagliata su come operano i modelli LLM, evitando un linguaggio eccessivamente tecnico e un ricorso a complesse strutture matematiche. L’obiettivo è assicuraci che anche coloro che non posseggono un background in matematica, statistica o informatica possano comprendere i concetti fondamentali alla base degli LLM. Per raggiungere questo obiettivo, verranno introdotte semplificazioni e si introdurranno minori imprecisioni che, pur essendo tecnicamente non precise, aiuteranno a chiarire le i concetti principali. L’aspirazione è fornire una comprensione più chiara possibile degli LLM e ispirare curiosità e ulteriori esplorazioni in questo campo in rapida evoluzione.
In questo primo articolo l’attenzione è concentra sulla struttura interna degli LLM: le Reti Neurali Artificiali (ANN, Artificial Neural Network). Questo articolo è stato redatto con il supporto preciso di ChatGTP e Gemini.
Software tradizionali e modelli LLM
Il cosiddetto software “convenzionale”, che, almeno per il momento, nella stragrande maggioranza dei casi è scritto da programmatori umani, istruisce i computer su cosa fare, passo dopo passo. In questi casi, quando il computer o il software appare intelligente, ciò in realtà è un riflesso di algoritmi ben progettati e ben codificati. Questo tipo di software ha ancora un posto fondamentale. Come vedremo, I modelli LLM si discostano da questo paradigma. Sono costruiti su reti neurali artificiali (ANN) addestrate utilizzando enormi quantità di dati disponibili in vari formati incluso il linguaggio naturale. Ciò permette al modello di apprendere. Quindi l’intelligenza esibita di modelli LLM presenta una forte dipendenza dai dati usati per l’apprendimento e dall’organizzazione interna di questa “conoscenza”. Gli LLM, parte fondamentale dell’IA, mirano a imitare l’intelligenza umana. Utilizzano modelli statistici per analizzare ampi insiemi di dati, apprendendo schemi e connessioni tra parole e frasi e dati più in generale. Questo costituisce la base della loro conoscenza interna, permettendo loro di rispondere a domande e generare nuovi testi come saggi, articoli e persino libri. Gli LLM possono creare contenuti che imitano lo stile di specifici autori o generi. Nessuno insegna ai modelli LLM un compito specifico. Sono loro stessi che imparano a risolvere problemi, generate contenuti senza essere guidati da un algoritmo specifico.
LLM
Ogni giorno, vediamo gli LLM svolgere vari compiti. Tipicamente, si utilizzano modelli “pre-allenati”, che sono stati addestrati analizzando enormi quantità di dati strutturati e non: enciclopedie, documenti, paper, libri e altro. Processare quantità massicce di dati permette ai modelli di estrarre e apprendere schemi e connessioni tra dati e parole. È chiaro che maggiori quantità di dati ad elevata qualità vengono usati per addestrare il modello, migliore sarà la qualità dei contenuti generati. Tuttavia, questo significa anche che il modello richiederà sempre più memoria e svilupperà rappresentazioni interne di dati sempre più complesse e di difficile comprensione per gli esseri umani.
Questi modelli, una volta organizzata la propria base di conoscenza, utilizzano modelli statistici per svolgere i lavori richiesti. Per esempio, possiamo chiedere ad un modello di completare una frase prevedendo la parola successiva. Data la frase latina “Beati monoculi in terra”, il modello sarebbe portato a prevedere “Caecorum”. Attraverso un gran numero di previsioni, il modello impara a costruire grafi estesi che lo aiutano a gestire la grammatica, i fatti sul mondo, le capacità di simulazione del ragionamento e altro ancora.
Breve introduzione alle reti neurali biologiche (BNN)
Nota: l’autore di questo articolo non è un esperto in reti neurali biologiche e della biologia in generale. Le informazioni incluse in questo articolo sono state ricavate da altri studi che hanno indagato approfonditamente questo argomento (vedi [McCulloch, Pitts, 1943], [Byrne, 2016], [Hanani, M., 2005], [Nicholls et al., 2001], [Reece et al., 2011], [Solomon, 2016], [Khan Academy, 2012], [Rye et al, 2016]). Inoltre, è importante ricordare che lo stesso funzionamento di diverse regioni del cervello umano è ancora oggetto di studi dettagliati da parte degli scienziati.
Le reti neurali artificiali (ANN) sono ispirate alle reti neurali biologiche (BNN) e sono una componente fondamentale dei modelli LLM. Il loro obiettivo è imitare il modo in cui il cervello umano opera. Non replicano le funzioni del cervello ma tentano di catturarne alcuni aspetti strutturali e funzionali. Per decenni, i ricercatori sono stati veramente convinti di poter riuscire a replicare le reti neurali umane. Molti esperimenti sono stati condotti in questa direzione. Ora comprendiamo che ci sono ancora molti meccanismi del cervello che non siamo ancora in grado di spiegare in dettaglio. Pertanto, anche molti ricercatori attivi nel mondo dell’intelligenza artificiale, attualmente si accontentano dell’obiettivo di simulare alcuni processi neurali.
![Figura 1 – Struttura semplificata dei neuroni (fonte: [Rye et al, 2016]).](https://www.mokabyte.it/wp-content/uploads/2025/06/AILLM-1_fig01-1.jpg)
Le cellule del sistema nervoso (neuroni) sono uniche per diversi motivi, tra cui la loro forma distinta, la lunghezza e il funzionamento (vedi figura 1). Molti neuroni contengono prolungamenti chiamati Assoni (Axon), che possono raggiungere anche oltre un metro di lunghezza, come per esempio quelli che si estendono dai fianchi fino alle dita dei piedi, cosa insolita poiché la maggior parte delle cellule misura solo circa 20 micrometri (2 × 10-5 m) di diametro. In confronto, basti pensare che un singolo capello ha un diametro che varia da circa 70 a 100 micrometri (7 × 10-5 m – 10-4 m).
I Dendriti, rami del corpo cellulare del neurone, vengono in contatto con altri neuroni per ricevere messaggi, che poi viaggiano lungo l’assone fino alla sinapsi, il punto in cui i neuroni comunicano. Qui, il messaggio può passare al neurone successivo. I neuroni comunicano utilizzando segnali elettrici specializzati. Alcuni segnali trasmettono informazioni dall’ambiente esterno, come viste, suoni e odori, mentre altri inviano istruzioni a organi, ghiandole e muscoli. I segnali sono ricevuti da neuroni vicini tramite i loro dendriti, viaggiano verso il corpo cellulare principale chiamato Soma, e poi scendono lungo l’assone fino alla sinapsi.
I nostri cervelli contengono milioni di sinapsi, e ogni neurone può comunicare con molti altri, creando relazioni molti-a-molti (vedi Figura 2). Ad esempio, i dendriti di un singolo neurone possono ricevere contatti sinaptici da molti altri neuroni. Questa complessità, al momento, non è ancora completamente implementata nella stragrande maggioranza delle reti neurali artificiali (ANN).
In funzione ai rispettivi ruoli, i neuroni possono essere suddivisi nelle seguenti tre categorie:
- Neuroni sensitivi o afferenti
- Neuroni motori
- Interneuroni o neuroni intercalari
Neuroni sensitivi
I neuroni sensitivi (nome derivante dai sensi, tattili, visivi, gustativi ecc.) ricevono informazioni dall’ambiente interno ed esterno del corpo e trasmettono questa informazione al Sistema Nervoso Centrale (SNC) per l’elaborazione. Ad esempio, se una persona immerge un dito in una pentola piena d’acqua bollente, i neuroni sensitivi con terminazioni nel polpastrello del dito trasmetteranno informazioni al SNC, indicando che l’acqua è bollente. I neuroni sensitivi sono collegati alla sorgente della “catena” di comunicazione.
Neuroni motori
I neuroni motori ricevono informazioni da altri neuroni e trasmettono comandi ai muscoli, organi e ghiandole. Agiscono alla fine della catena di comunicazione. Nell’esempio precedente dell’immersione del dito nell’acqua bollente, i neuroni motori che innervano i muscoli delle dita provocheranno un immediato ritiro del dito dall’acqua bollente.
Interneuroni
Gli interneuroni, presenti solo all’interno del SNC (comprende il cervello e il midollo spinale), collegano tra loro i neuroni. Gli Interneuroni ricevono informazioni dai neuroni sensitivi o da altri interneuroni e le trasmettono ai neuroni motori o ad altri interneuroni.
Sempre nell’esempio precedente, quando una persona immerge un dito in una pentola di acqua bollente, il segnale proveniente dai neuroni sensoriali delle punte delle dita viaggia verso gli interneuroni nel midollo spinale. Alcuni di questi interneuroni segnalano ai neuroni motori che controllano i muscoli del dito, causando il ritiro immediato del dito, mentre altri trasmettono il segnale lungo il midollo spinale ai neuroni nel cervello, dove viene percepito come dolore.
Reti neurali artificiali (Artificial Neural Networks, ANN)
Sia nelle reti neurali biologiche (BNN), sia nelle reti neurali artificiali (ANN), i neuroni sono le unità fondamentali. Il funzionamento principale dei neuroni, dal punto di vista degli LLM, può essere riassunto nei seguenti tre punti:
- Ricezione dei segnali
- Elaborazione dei segnali
- Comunicazione dei segnali
Ricezione dei segnali
I neuroni sensoriali ricevono stimoli dal mondo esterno o dall’interno del corpo. Ciò può essere paragonato a quello che in informatica si definisce evento di input.
Gli interneuroni e i neuroni motori ricevono segnali da altri neuroni.
Elaborazione dei segnali
I segnali ricevuti vengono elaborati per determinare se le informazioni devono essere propagate ulteriormente lungo la catena di neuroni.
Comunicazione dei segnali
Gli interneuroni possono comunicare segnali ad altri neuroni, compresi altri interneuroni o neuroni motori.
I neuroni motori trasmettono segnali agli effettori – come muscoli, organi e ghiandole – agendo come il livello di output.
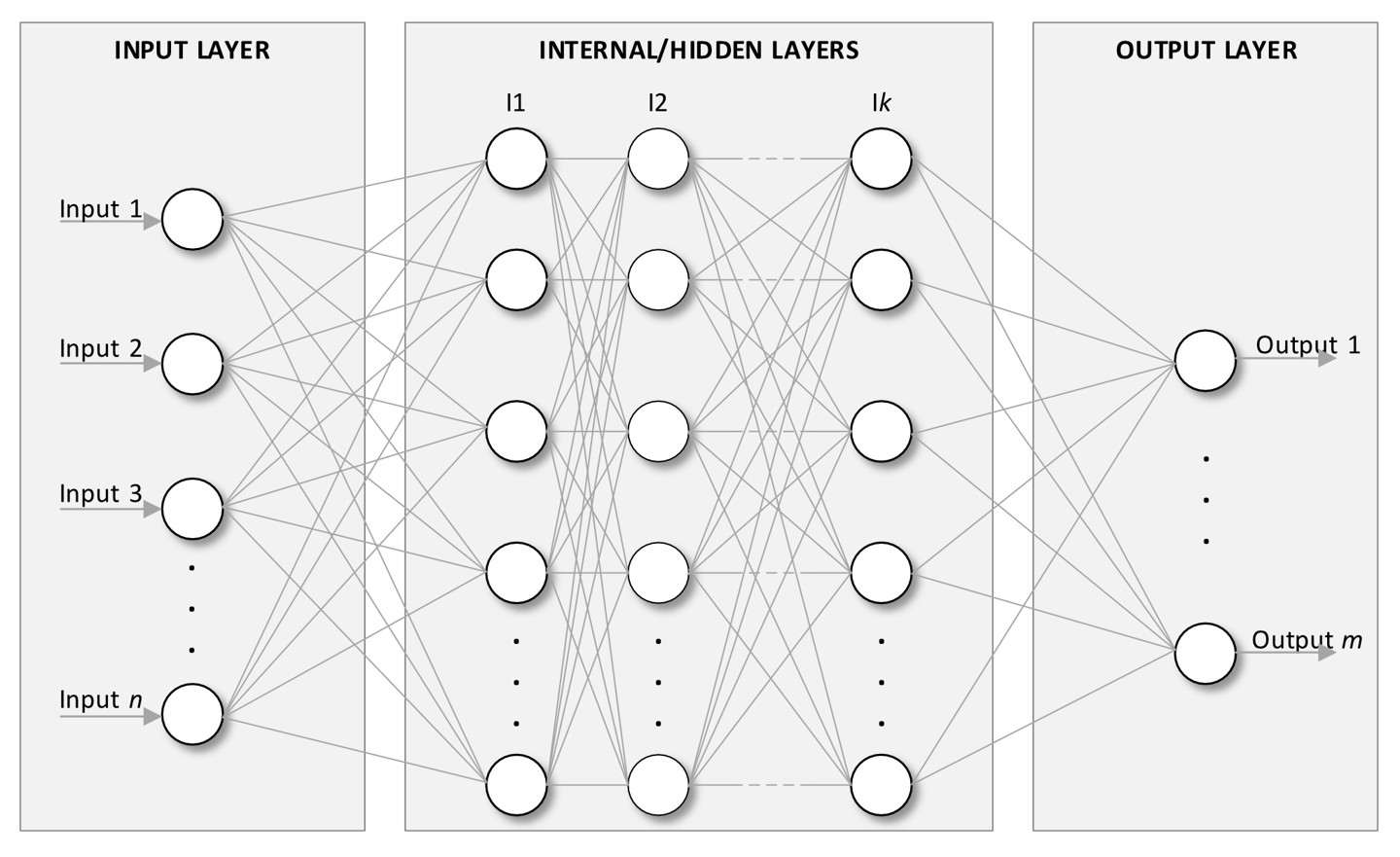
Strati
Le ANN sono organizzate nei seguenti strati (vedi Figura 2):
- Strato di input: questo è il punto di ingresso della rete LLM, dove riceve i dati di input. Ogni nodo in questo strato corrisponde a una caratteristica (feature) dell’insieme dei dati di input. Una caratteristica è un attributo specifico di input del modello.
- Strati Interni o nascosti: questi consistono in uno o più strati in cui avvengono i calcoli. Ogni neurone in questi strati applica una trasformazione agli input, permettendo alla rete di apprendere caratteristiche complesse.
- Strato di output: questo strato finale fornisce l’output della rete, che potrebbe essere un’etichetta di classificazione, un valore predetto, ecc.
Si immagini di implementare un modello di intelligenza artificiale in grado di prevedere la probabilità di un’esondazione di un fiume. In questo contesto, il modello includerebbe caratteristiche (feature, variabili di input) come la quantità di pioggia nelle ultime 24 ore, la quantità di pioggia prevista nei giorni seguenti, le temperature attuali e quelle previste, l’umidità e il livello attuale del fiume. Ciascuna di queste caratteristiche richiederà un neurone di input. Gli output potrebbero includere previsioni per il livello dell’acqua e la probabilità di esondazione. Si presume che il modello sia stato addestrato con dati storici, dove il set di caratteristiche è stato associato alle variabili di output corrispondenti.
Pesi e bias
Ogni connessione tra neuroni (sinapsi nelle reti neurali biologiche) ha un peso (weight) associato che gli LLM aggiustano con il progredire dell’apprendimento progredisce. Questi bias vengono aggiunti alla somma ponderata degli input, si tratta quindi di un attributo dei neuroni, al fine di migliorare l’adattamento del modello (vedi Figura 4). I pesi sono parametri numerici che regolano l’intensità dei segnali di input al neurone, determinando quanto ogni input influisce sull’output del neurone. Ogni input xi viene moltiplicato per il suo peso corrispondente (xi * wi); quindi, i pesi possono amplificare o ridurre il valore degli input. Modificando questi pesi durante l’addestramento, la rete impara quali caratteristiche dei dati di input sono più importanti per calcolare le previsioni. Ad esempio, il modello potrebbe assegnare un valore più alto alla quantità di pioggia caduta nelle ultime 24 ore e un peso inferiore al fattore umidità. Durante il processo di addestramento, vengono calcolati i gradienti per aggiornare i pesi utilizzando algoritmi di ottimizzazione, con l’obiettivo di minimizzare la loss funzione (funzione di perdita), che quantifica la differenza tra gli output previsti e quelli effettivi.
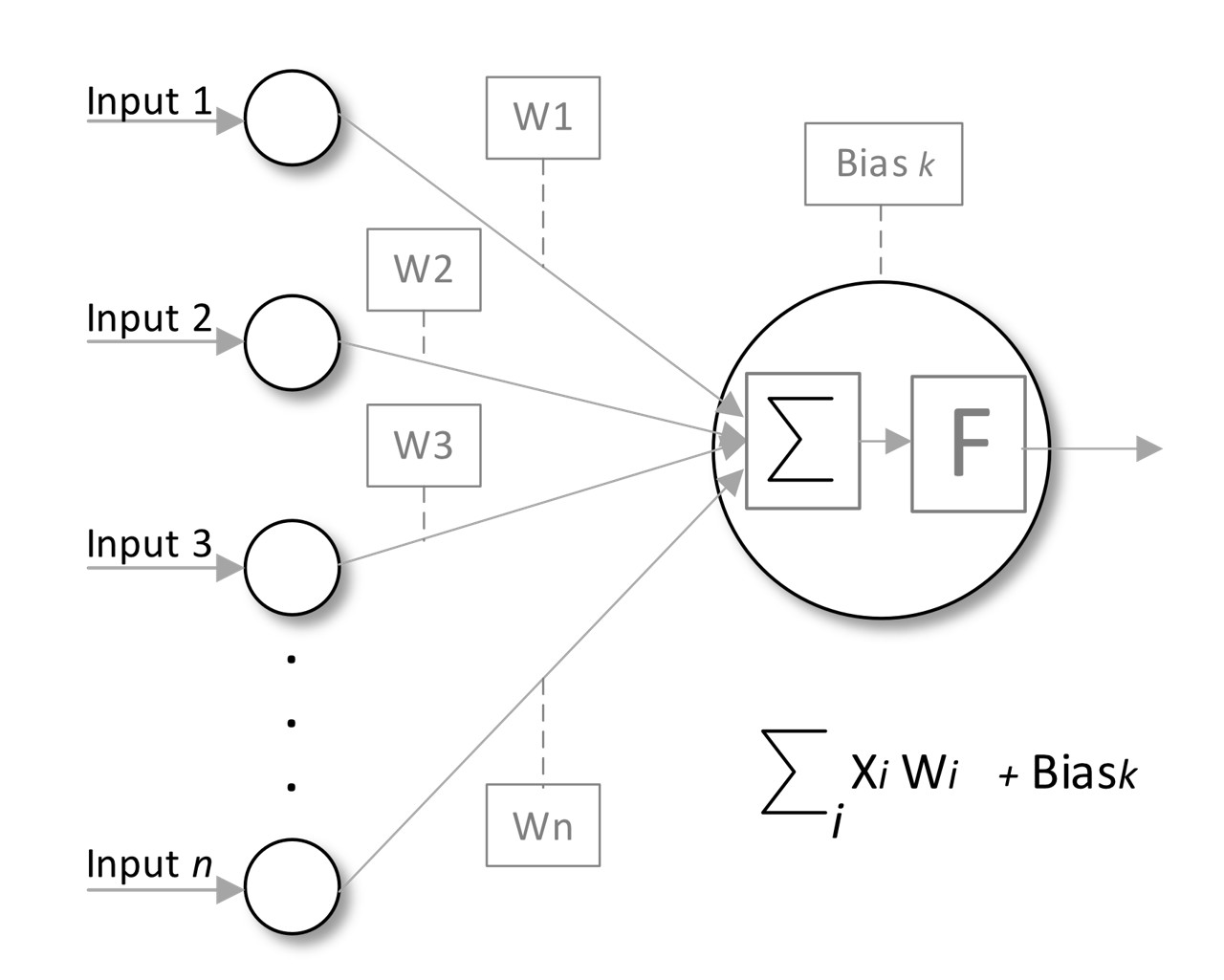
Un bias è un parametro separato, anch’esso regolabile, aggiunto alla somma ponderata degli input prima di applicare la funzione di attivazione (bias k). Lo scopo del bias è permettere al modello di adattarsi meglio ai dati, fornendo un mezzo per spostare la funzione di attivazione a sinistra o a destra (è un parametro esterno alla sommatoria). Questo è particolarmente utile quando i dati non passano per l’origine (0,0), poiché dà al nodo neurone una maggiore flessibilità nel regolare il suo output. Come i pesi, anche i bias vengono regolati durante la fase di addestramento in base ai gradienti calcolati tramite la retropropagazione (back propagation). Ogni bias viene aggiornato singolarmente per contribuire a minimizzare l’errore complessivo (si parla di retropropagazione dell’errore).
La combinazione di pesi e bias permette alle reti neurali di apprendere funzioni e pattern complessi nei dati, facilitando l’estrazione gerarchica delle caratteristiche. Incorporando i bias e utilizzando funzioni di attivazione, le reti neurali possono modellare relazioni non lineari, rendendole strumenti potenti per compiti come il riconoscimento delle immagini, l’elaborazione del linguaggio naturale e altro ancora. In sintesi, pesi e bias sono essenziali per le reti neurali, in quanto governano come gli input vengono trasformati e elaborati per produrre gli output. La loro corretta inizializzazione e regolazione durante l’addestramento influenzano significativamente le prestazioni del modello.
Funzione di attivazione
Una funzione di attivazione è un’operazione matematica applicata all’output “potenziale” di un neurone, determinando se deve essere attivato (propagato) o meno. Introduce non-linearità nel modello, consentendo alla rete di apprendere relazioni e pattern complessi nei dati. Può essere vista come un elemento di decisione, simile a un interruttore della luce: quando il segnale di input raggiunge un certo livello, l’interruttore si attiva, permettendo al neurone di inviare il suo segnale allo strato successivo nella rete. Ad esempio, con la funzione di attivazione ReLU (Rectified Linear Unit, Unità Lineare Rettificata), se l’input a un neurone è un numero, ReLU ne restituisce lo stesso se è maggiore di zero; altrimenti, restituisce zero. Questo significa, ad esempio, che:
- Se l’input è 3, ReLU restituisce 3 (il neurone “si attiva”).
- Se l’input è -2, ReLU restituisce 0 (il neurone “non si attiva”).
Modellando l’output dei neuroni in questo modo, le funzioni di attivazione giocano un ruolo cruciale nel modo in cui le informazioni fluiscono attraverso la rete, permettendo di fare previsioni accurate.
Le funzioni di attivazione considerate più popolari sono:
- Sigmoide: è più adatta per classificazioni binarie; si occupa di mappare gli output nell’intervallo (0, 1) e quindi soffre del problema del gradiente che scompare con valori estremi di input.
- ReLU (Unità Lineare Rettificata): ampiamente usata negli strati interni o nascosti; è efficiente ed efficace, ma può incontrare problemi con neuroni inattivi, portando al problema del “ReLU moribondo”.
- Softmax: utilizzata comunemente nello strato di uscita delle BNN, in particolare per i modelli di classificazione multiclasse. Si occupa di convertire un vettore di punteggi grezzi (logit) generati dagli strati interni in una distribuzione di probabilità su più classi potenziali. Ogni valore in uscita rappresenta la probabilità che l’input appartenga a una classe specifica. Richiede una gestione accurata della scala degli input per evitare instabilità numeriche.
Nota: Nei paragrafi successivi, si entrerà un po’ in dettaglio nelle funzioni di attivazione. L’obiettivo non è di fornire una descrizione dettagliata di tali funzioni, ma di illustrare i meccanismi presenti all’interno delle ANN. L’obiettivo permane di comprendere il funzionamento dei modelli, e quindi non è richiesta la comprensione approfondita di queste funzioni per poter procedere nella lettura dell’articolo.
Funzione di attivazione Sigmoide
La funzione Sigmoide si occupa di mappare ogni valore di input in un intervallo tra 0 e 1 e mostra una curva a forma di S (da cui il nome). Il suo output è utile nel contesto di compiti di classificazione binaria, poiché fornisce un’interpretazione diretta in termini di probabilità. Inoltre, la funzione Sigmoide smussa il gradiente (il gradiente indica quanto l’output è sensibile alle variazioni dell’input), rendendo più semplice l’ottimizzazione. Tuttavia, uno svantaggio importante della funzione Sigmoide è che tende a saturarsi per valori di input molto alti o molto bassi. Questa saturazione può causare che i gradienti diventino trascurabili, portando al problema del gradiente che scompare, e quindi gli aggiornamenti dei pesi diventano inefficaci.
ReLU (Unità Lineare Rettificata)
La funzione di attivazione ReLU restituisce l’input dato se è positivo; altrimenti, restituisce zero. Di conseguenza, i valori in output sono compresi tra 0 e infinito positivo. ReLU è ampiamente utilizzata negli strati interni delle reti neurali profonde grazie ai suoi notevoli vantaggi prestazionali. I principali vantaggi della ReLU includono l’efficienza computazionale, in quanto richiede solo una soglia semplice a zero. Inoltre, mitiga efficacemente il problema del gradiente che scompare, poiché non si saturano per gli input positivi. Tuttavia, uno svantaggio specifico è il rischio del problema del “ReLU moribondo”, in cui i neuroni possono diventare inattivi e smettere di apprendere se continuano a produrre output zero dovuti a input negativi.
Funzione di attivazione Softmax
La funzione Softmax normalizza un vettore di punteggi grezzi, noti anche come logit, in una distribuzione di probabilità su più classi. Questa normalizzazione aiuta a produrre probabilità più chiare e interpretabili, rendendo più semplice determinare quale classe sia la previsione migliore. La funzione Softmax restituisce valori nell’intervallo (0, 1) per ogni componente, con la somma di tutte le componenti pari a 1. Softmax è comunemente usata nell’output di problemi di classificazione multiclasse. I suoi vantaggi includono la fornitura di un’interpretazione probabilistica degli output, indicando la probabilità di ciascuna classe, ed è efficace in combinazione con la perdita di entropia incrociata categoriale durante l’addestramento. Tuttavia, uno svantaggio importante riguarda la sensibilità a valori anomali (outlier) a causa del passaggio dell’esponenziazione, che può portare ad instabilità numerica se i logit sono molto grandi o molto piccoli.
Queste tre funzioni di attivazione sono tra le più popolari e anche le più facili (o meno complicate) da comprendere. Per questo motivo sono state introdotte qui per fornire ai lettori una spiegazione più semplice.
Semplice esempio
Consideriamo un modello di AI in grado di prevedere la probabilità di un’esondazione di un fiume. Si tratta di una notevole semplificazione, presentata a fini divulgativi. Modelli utilizzabili in contesti reali presenterebbero una complessità decisamente superiore.
Questo modello potrebbe essere strutturato come segue:
Strato di input
Lo strato di input è composto da sette nodi corrispondenti alle seguenti caratteristiche scelte:
- Quantità di pioggia caduta nelle ultime 24 ore
- Quantità di pioggia prevista per i giorni successivi
- Temperatura attuale
- Temperatura prevista
- Umidità attuale
- Livello attuale del fiume
- Margine del fiume
Strati interni
Il modello include diversi strati interni nella rete neurale artificiale; il numero di strati interni e di nodi in questi strati varia in base alla complessità del problema e alla dimensione del dataset. Un punto di partenza comune è considerare due strati interni con un numero di nodi che può variare da 5 a 20. Successivamente, potrebbe essere necessario sperimentare con questi parametri per ottimizzare le performance.
Strato di output
Il modello richiede due tipi di output e, quindi, un totale di 2 nodi:
- Un valore continuo che predice il livello dell’acqua
- Un output binario: esondazione o no esondazione
È possibile considerare solo il primo output e derivare il secondo da esso. Se il livello dell’acqua supera il margine del fiume, allora si verifica un’esondazione; altrimenti, no.
Mostriamo l’esempio con numeri reali.
Si considerino i seguenti valori di input:

Si assuma di disporre di un solo livello interno con 3 nodi e che i pesi e bias per questi nodi siano quelli riportati in tabella (questioni di semplicità consideriamo valori piccoli):

A questo punto, quando gli input arrivano ai nodi interni si innescano i calcoli riportati nella seguente tabella:
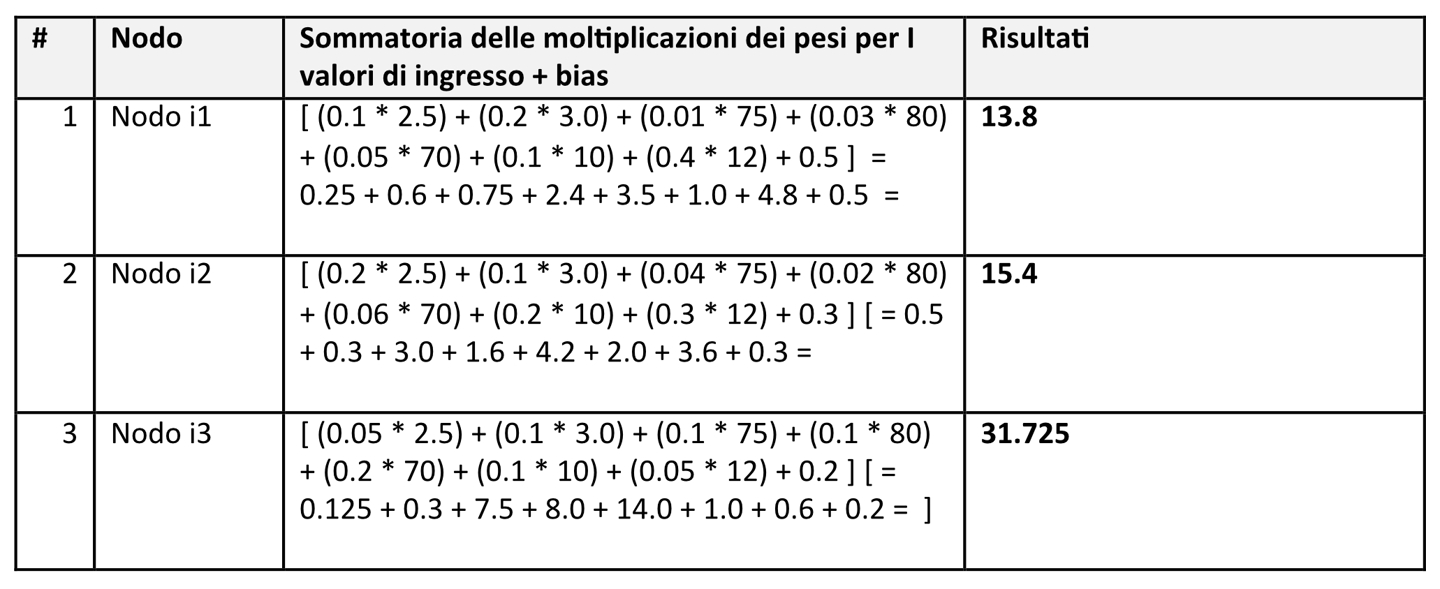
Si assuma, sempre per questioni di semplicità, che la funzione di attivazione sia ReLU, e quindi i corrispondenti valori, in quanto positivi, sono inviati allo strato di output per le predizioni finali.
Si consideri il seguente nodo di output con i suoi pesi e bias:


Quindi, il valore calcolato dal nodo di Output o1: Previsione continua del livello del fiume, è 21.6575 m che quindi ahimè si traduce in un’esondazione.
Ora, il modello presentato è estremamente semplice ed è stato introdotto unicamente per scopi illustrativi, tuttavia, è chiaro che una parte fondamentale dei modelli è costituita dai pesi e dal bias: output fondamentali del processo di apprendimento.
ANN: origine e evoluzione
Negli anni ‘40, Warren McCulloch, un neurofisiologo, e Walter Pitts, un logico, proposero un modello rivoluzionario dei neuroni biologici (vedi [McCulloch, Pitts, 1943]). All’epoca, molte delle conoscenze sui neuroni non erano ancora state comprese, eppure riuscirono a proporre modelli pionieristici per rappresentare l’attività e la comunicazione neuronale all’interno di strutture logiche, influenzando sia l’intelligenza artificiale, sia la comprensione del funzionamento del cervello. Proposero un modello semplificato dei neuroni basato sulla logica binaria. Secondo il loro modello, ogni neurone possiede una soglia e può essere attivato da input eccitatori simultanei, mentre l’inibizione può prevenire l’attivazione. Suggerirono inoltre che i neuroni operassero entro un intervallo di tempo fisso, prendendo decisioni sulla loro attivazione (firing) in momenti discreti. Utilizzarono anche altre ipotesi sul comportamento dei neuroni, tra cui ritardi sinaptici fissi e tempi di integrazione, basati sulle conoscenze biologiche limitate del loro tempo. I neuroni erano descritti come elementi logici, dove gli stati di attivazione rappresentano proposizioni logiche sugli input provenienti dai periodi temporali precedenti.
Inizialmente, il modello non prendeva in considerazione il feedback, concentrandosi sulle reti neurali in un’unica direzione (feed forward). Tuttavia, anche con le varie limitazioni, crearono il potenziale per futuri sviluppi di modelli che incorporavano anche meccanismi di feedback, complicando notevolmente l’analisi del comportamento della rete.
McCulloch e Pitts posero le basi per la comprensione delle reti neurali e dei sistemi di calcolo. La loro concezione di dispositivi logici influenzò anche le prime architetture di computer, in particolare la progettazione di calcolatori digitali come l’EDVAC. Gli avanzamenti successivi dimostrarono che le ipotesi avanzate da McCulloch e Pitts erano eccessivamente semplificate. La neuroscienza moderna indica che i neuroni funzionano in modi più complessi e asincroni, spesso in un continuo piuttosto che in modalità strettamente binarie. Nonostante le imprecisioni del loro modello, le idee fondamentali derivate dal lavoro di McCulloch e Pitts persistono nelle discussioni neuroscientifiche contemporanee riguardo alla comunicazione neuronale e al coding di insieme.
I componenti chiave del loro modello includevano:
- Input: segnali binari (0 o 1) rappresentanti gli input sinaptici da altri neuroni.
- Pesi: valori fissi che rappresentano la forza delle connessioni (eccitatorie o inibitorie).
- Soglia un valore predefinito che determina se il neurone “si attiva” (outputs 1) oppure no (outputs 0).
- Output: binario (0 o 1), calcolato come 1 se la somma pesata degli input supera o raggiunge la soglia, altrimenti 0.
Dopo il lavoro fondamentale di McCulloch e Pitts, emersero numerosi progressi significativi nelle reti neurali artificiali, segnando importanti avanzamenti nel campo.
Frank Rosenblatt alla fine degli anni ‘50 sviluppò il perceptron (vedi [Rosenblatt, 1958]), spesso considerato il primo algoritmo di rete neurale reale, che pose le basi per l’apprendimento supervisionato nelle reti neurali. Funziona come una rete a uno strato che prende decisioni binarie basate sulle caratteristiche di input. Nonostante i limiti, come l’incapacità di risolvere problemi non lineari, il perceptron suscitò interesse e ricerche che portarono allo sviluppo di reti multistrato.
David E. Rumelhart, Geoffrey E. Hinton e Ronald J. Williams alla fine degli anni ‘80 proposero la retropropagazione (vedi [Rumelhart, et al. 1986]) basata su reti multi strato (multilayer perceptrons) per addestrare efficacemente le reti regolando i pesi tra diversi strati in risposta agli errori. Questa tecnica permise di minimizzare la funzione di perdita (che misura la differenza tra gli output previsti e quelli reali). L’introduzione della retropropagazione fu fondamentale per rendere pratiche le reti neurali per compiti complessi, portando a successivi progressi nel deep learning.
Yann LeCun, Yoshua Bengio e Geoffrey Hinton dietero un contributo significativo alla crescita del deep learning all’inizio degli anni 2010 (vedi [LeCun et al., 2015]), caratterizzato da reti di grandi dimensioni con molti strati, che portarono a progressi nel riconoscimento vocale, nella classificazione delle immagini e nel gioco strategico. I modelli di deep learning sfruttano enormi quantità di dati e potenza computazionale per apprendere rappresentazioni complesse in modo gerarchico. Questo cambio di paradigma ha stimolato l’innovazione in vari settori, dalle vetture autonome alla diagnostica sanitaria.
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville e Yoshua Bengio hanno proposto le Generative Adversarial Networks (GANs), che consentono di generare nuovi dati attraverso reti competenti (un generatore e un discriminatore). Il generatore crea dati sintetici, mentre il discriminatore valuta l’autenticità rispetto ai dati reali. Questo approccio di addestramento avversiale ha portato a risultati impressionanti nella sintesi di immagini, aprendo la strada a applicazioni come deepfake e generazione artistica, mettendo in mostra il potenziale creativo dell’AI.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser e Illia Polosukhin, nel 2017, introdussero l’architettura Transformer (vedi [Vaswani et al., 2017]). Questa si è affermata come fondamento per modelli all’avanguardia nel campo del processing del linguaggio naturale, sfruttando meccanismi di auto-attenzione. I Transformer permettono l’elaborazione in parallelo delle sequenze di input, migliorando significativamente efficienza e scalabilità rispetto alle architetture ricorrenti. Questa innovazione ha portato anche a progressi nella comprensione e generazione del linguaggio, con modelli come BERT e GPT che hanno raggiunto risultati notevoli in vari benchmark NLP. ChatGPT, Generative Pre-Trained Transformer, include nel suo nome il Transformer per sottolineare l’importanza dell’architettura di base.
Conclusioni
In questo documento, abbiamo iniziato il nostro percorso per spiegare la struttura ed il funzionamento di modelli di intelligenza artificiale ed in particolare degli LLMs, che potremmo tradurre in italiano come modelli linguistici di grandi dimensioni. L’obiettivo di questa serie di articoli è fornire ai lettori una spiegazione informale, priva di gergo tecnico, ma dettagliata dei modelli, evitando un linguaggio eccessivamente tecnico e matematica complessa. Ciò al fine di permettere anche a chi non possiede una solida preparazione matematica e informatica di comprendere i concetti fondamentali dei modelli di IA. Questo approccio mira a ridurre le preoccupazioni riguardo a questa tecnologia di importanza cruciale e a consentire agli utenti di sfruttarla in modo più efficace.
Il focus di questo documento è la struttura dei modelli di IA, in particolare le Reti Neurali Artificiali (ANN), che costituiscono i componenti interni di questi modelli.
Abbiamo iniziato descrivendo le reti neurali biologiche (BNN). Sebbene abbiamo solo accennato l’argomento, questa discussione è stata essenziale per comprendere le loro origini e i concetti di base. Le ANN sono ispirate dalle BNN e rappresentano un componente fondamentale dei LLM. Il loro obiettivo è imitare i processi operativi del cervello umano. Sebbene le BNN, al momento, non riproducano le funzioni cerebrali a pieno titolo, tentano di catturare alcuni aspetti strutturali e funzionali dello stesso. Per decenni, i ricercatori erano convinti di poter replicare con successo le reti neurali umane. Quel traguardo, però, sembra irraggiungibile nel prossimo futuro.
Secondo i loro ruoli, i neuroni biologici possono essere divisi in tre categorie: neuroni sensoriali, neuroni motori e interneuroni. I neuroni sensoriali ricevono informazioni sull’ambiente interno ed esterno del corpo e le trasmettono al Sistema Nervoso Centrale (SNC) per l’elaborazione. I neuroni motori ricevono informazioni da altri neuroni e trasmettono comandi a muscoli, organi e ghiandole. Gli interneuroni, presenti solo all’interno del SNC (cervello e midollo), collegano tra loro i neuroni, ricevendo informazioni dai neuroni sensoriali o da altri interneuroni e trasmettendole ai neuroni motori o ad altri interneuroni. Questo spiega perché le BNN sono organizzate in tre strati: lo Strato di Input, che rappresenta il punto di ingresso dei dati nella rete; gli Strati Interni o Nascosti, costituiti da uno o più strati in cui avvengono i calcoli e in cui ogni neurone applica trasformazioni agli input, permettendo alla rete di apprendere caratteristiche complesse; e lo Strato di Output, che fornisce l’output finale della rete.
Ogni connessione tra neuroni (simile alle sinapsi nelle reti biologiche) ha un peso, weight, associato che viene aggiustato dal modello durante il processo di apprendimento. I bias vengono aggiunti alla somma pesata degli input per migliorare l’adattamento del modello. Questi fattori vengono determinati durante la fase di training. Regolando i pesi nel corso dell’addestramento, la rete impara quali caratteristiche dei dati di input sono più importanti per fare previsioni.
Una funzione di attivazione è un’operazione matematica applicata al potenziale output di un neurone, che ne determina se deve essere attivato o meno. Introduce non-linearità nel modello, permettendo alla rete di apprendere relazioni e pattern complessi nei dati. La funzione di attivazione può essere vista come un decision-maker, simile a un interruttore: quando il segnale di input raggiunge una certa soglia, l’interruttore si attiva, consentendo al neurone di inviare il suo segnale allo strato successivo della rete.
Nei prossimi articoli, spiegheremo come funzionano i modelli di LLM più complessi, passando dalla struttura interna alla loro funzionalità.
Riferimenti
[McCulloch, Pitts, 1943] McCulloch, W.S., Pitts, W. “A logical calculus of the ideas immanent in nervous activity”. Bulletin of Mathematical Biophysics 5, 115–133 (1943).
https://doi.org/10.1007/BF02478259
[Rosenblatt, 1958] Frank Rosenblatt, “The perceptron: A probabilistic model for information storage and organization in the brain”
https://psycnet.apa.org/record/1959-09865-001
[Gamma et al., 1995] E. Gamma, R. Helm, R. Johnson, and J. Vlissides, Design Patterns : Elements of Reusable Object-Oriented Software. Reading, Mass. :Addison-Wesley, 1995.
[Rumelhart, et al. 1986] David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams, “Learning representations by back-propagating errors”. Nature 323, 533–536 (1986).
https://doi.org/10.1038/323533a0
[Hochreiter et al., 1997] Sepp Hochreiter, Jürgen Schmidhuber; Long Short-Term Memory. Neural Comput 1997; 9 (8): 1735–1780.
doi: https://doi.org/10.1162/neco.1997.9.8.1735
[LeCun et al., 1998] LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). “Gradient-Based Learning Applied to Document Recognition.” Proceedings of the IEEE
https://ieeexplore.ieee.org/document/726791
[Nicholls et al., 2001] Principles of signaling and organization. In From neuron to brain. Sunderland, MA: Sinauer Associates.
[Reece et al., 2011] Neuron structure and organization reflect function in information transfer. Campbell biology. San Francisco, CA: Pearson.
[Hanani, M., 2005] “Satellite glial cells in sensory ganglia: From form to function”. Brain Research Reviews, 48, 457-476.
https://www.sciencedirect.com/science/article/abs/pii/S0165017304001274
[Khan Academy, 2012] The neuron and nervous system. Overview of neuron structure and function. Introduction to neurons and glia. How the structure of a neuron allows it to receive and transmit information.
https://www.khanacademy.org/science/biology/human-biology/neuron-nervous-system/a/overview-of-neuron-structure-and-function
[Goodfellow et al. 2014] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville and Yoshua Bengio (2014). “Generative Adversarial Networks.”
https://arxiv.org/abs/1406.2661
[LeCun et al., 2015] Yann LeCun, Yoshua Bengio & Geoffrey Hinton. (2015). “Deep Learning.” Nature.
https://www.nature.com/articles/nature14539
[Solomon, 2016] Sensory receptors. In Introduction to human anatomy and physiology. Maryland Heights, MO: Saunders.
[Rye et al, 2016] Connie Rye, Robert Wise, Vladimir Jurukovski, Jean DeSaix, Jung Choi, Yael Avissar, Biology, OpenStax, 2016
https://openstax.org/books/biology/pages/1-introduction
https://openstax.org/books/biology/pages/35-1-neurons-and-glial-cells#fig-ch35_01_04
[Byrne, 2016] “Introduction to Neurons and Neuronal Networks”. Neuroscience.
https://nba.uth.tmc.edu/neuroscience/s1/introduction.html.
[Vaswani et al., 2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin, 2017, “Attention is All You Need.” Advances in Neural Information Processing Systems (NeurIPS)”
https://arxiv.org/abs/1706.03762
[Drug Target R., 2019] Scientists discover unique imaging technique to view synapse proteins, Drug Target Review, 27 September 2019
https://www.drugtargetreview.com/news/50185/scientists-discover-unique-imaging-technique-to-view-synapse-proteins/