


Introduction
Large Language Models (LLMs) like ChatGPT, Gemini, DeepSeek, and Claude have become integral tools for a number of individuals and businesses. A significant number of readers are familiar with these models, having utilized them for various applications in their personal and professional lives. However, while users may engage with these technologies regularly, few have a comprehensive understanding of their underlying structure and functioning.
The objective of this series of articles is to provide readers with an informal, jargon-free, yet detailed explanation of how LLM models operate. By avoiding excessive technical language and complex mathematics, we strive to ensure that even those without a background in mathematics or computer science can grasp the fundamental concepts behind LLMs. To achieve this goal, we will introduce certain simplifications and carefully consider the use of inaccuracies that, while not technically precise, will aid in elucidating core ideas. We aspire to provide a clearer understanding of LLMs and inspire curiosity and further exploration in this rapidly evolving field. This first article focuses on the inner structure of LLMs: the Artificial Neural Networks (ANN). It was written with the precise support of ChatGTP and Gemini.
Traditional SW and AI
We are all familiar with “conventional” software, which, at the moment, in the vast majority of cases is still created by human programmers who instruct computers on what to do, step by step. In such cases, when the computer or software appears intelligent, it is actually a reflection of well-designed and well-coded algorithms. This type of software still holds its own key place. In contrast, LLMs, take a different approach. They are built on artificial neural networks (ANN) trained using vast amounts of natural language data. This design allows the model to learn, organize data, and apply its “knowledge” without being instructed to execute a specific task. LLMs, a key part of AI, aim to mimic human intelligence. They use statistical models to analyse large datasets, learning patterns and connections between words and phrases. This forms the basis of their internal knowledge, enabling them to answer questions and generate new texts such as papers, essays, articles, and even books. LLMs can create content that mimics the style of specific authors or genres.
LLM
Every day, we see LLMs perform various tasks. Typically, we use “pre-trained” models, which have been trained by analysing immense amounts of unstructured data: encyclopaedias, papers, books, and more. Processing this massive data allows the model to extract and learn patterns and connections between words and data more generically. It is clear that the more (high quality) data the model is trained on, the better it becomes at generating new content. However, this also means that the model requires more memory and develops more complex internal data representations which can become obscure to human.
We have learned that these models use their knowledge base to predict the next word in a sentence. For instance, given the English text “Chicago is very different from”, many models will correctly predict “Boston”. Similarly, given the Latin phrase “Beati monoculi in terra”, the model might predict “Caecorum”. Through a large number of such predictions, the model learns to build extensive graphs that help it handle grammar, facts about the world, reasoning abilities, and more.
Biological neural networks (BNN) in a Nutshell
Note: the author of this paper is by no means an expert in biological neural networks. The information included in this paper has been sourced from other studies that have investigated this topic extensively (see [McCulloch, Pitts, 1943], [Byrne, 2016], [Hanani, M., 2005], [Nicholls et al., 2001], [Reece et al., 2011], [Solomon, 2016], [Khan Academy, 2012], [Rye et al, 2016]). Additionally, the functioning of several parts of the human brain is still the subject of detailed study by scientists.
ANNs are inspired by the BNNs and are a foundational component of LLM. Their objective is to mimic the way the human brain operates. They do not replicate the brain’s functions, but they attempt to capture some of its structural and functional aspects. For decades, researchers were truly convinced they could succeed in replicating human neural networks. Many experiments have been conducted in this regard. Now we understand that there are still many mechanisms of the brain that we cannot yet explain in detail. Therefore, even artificial intelligence researchers currently settle for the goal of simulating, mimic a few neural processes.
![Figure 1 – Simplified structure of a neuron (from [Rye et al, 2016])](https://www.mokabyte.it/wp-content/uploads/2025/06/AILLM-1_fig01.jpg)
Neurons, among other brain cells, are unique cells for several reasons, including their distinct shape, length and functioning (see figure 1). Many neurons contain extension called Axon that can reach up to a meter long, extending from the hips down to the toes, which is unusual since most cells are only about 20 micrometres (2 10-5 m) in diameter. In comparison, a single hair ranges from about 70 to 100 micrometres in diameter (7 10-5 m – 10-4 m).
Dendrites, branches of the neuron body, touch the other neurons to receive messages, which then travel through the axon to the synapse, the place where neurons communicate. Here, the message can move to the next neuron. Neurons communicate using specialized electrical signals. Some signals convey information from the external environment, such as sights, sounds, and smells, while others send instructions to organs, glands, and muscles. Signals are received by neighbouring neurons through their dendrites, travel to the main cell body called the soma, and then move down the axon to the synapse.
Our brains contain millions of synapses, and each neuron can communicate with several others creating a many to many relationships (see Figure 2). For example, dendrites from a single neuron may receive synaptic contact from many other neurons. This complexity, at the moment, is not partially implemented in the vast majority of ANNs.
Based on their roles, neurons can be divided into the following three categories:
- Sensory Neurons
- Motor Neurons
- Interneurons
Sensory Neurons
Sensory neurons receive information about the internal and external environment of the body and deliver this information to the Central Nervous System (CNS) for processing. For example, if a person places a finger in a pan filled with boiling water, sensory neurons with endings in the fingertip will transmit information to the CNS, indicating that the water is extremely hot.
Motor Neurons
Motor neurons receive information from other neurons and transmit commands to muscles, organs, and glands. They act at the end of the communication chain. In the example above, if a person places a finger in boiling water, motor neurons innervating the muscles in the person’s fingers will cause the person to immediately withdraw the finger from the boiling water.
Interneurons
Interneurons, found only within the CNS, connect neurons to each other. They receive information from sensory neurons or other interneurons and transmit it to motor neurons or other interneurons.
In our example, when a person puts a finger in a pan of boiling water, the signal from the sensory neurons in the fingertips travels to interneurons in the spinal cord. Some of these interneurons signal the motor neurons controlling the finger muscles, causing the person to withdraw the finger, while others transmit the signal up the spinal cord to neurons in the brain, where it is perceived as pain.
Artificial Neural Networks (ANN)
In both biological neural networks (BNNs) and artificial neural networks (ANNs), neurons are the fundamental units. The core functioning of neurons, from the perspective of LLMs, can be summarized in the following three steps:
- Receiving Signals
- Processing the signals
- Communicating the signals
Receiving Signals
Sensory neurons receive stimuli from the external world or from within the body. This can be likened to what is referred to in IT as an input event.
Interneurons and motor neurons receive signals from other neurons.
Processing the Signals
The received signals are processed to determine whether the information needs to be transmitted further.
Communicating the Signals
Interneurons can communicate signals to other neurons, including other interneurons or motor neurons.
Motor neurons transmit signals to effectors—such as muscles, organs, and glands—acting as the output layer.
Layers
ANNs are organized into the following layers (see Figure 2):
- Input Layer: This is the entry point of the LLM network, where it receives input data. Each node in this layer corresponds to a feature from the input dataset. A feature is a specific input attribute of the model.
- Hidden Layers: These consist of one or more layers where computations occur. Each neuron in these layers applies a transformation to the inputs, enabling the network to learn complex features.
- Output Layer: This final layer provides the network’s output, which could be a classification label, a predicted value, etc.
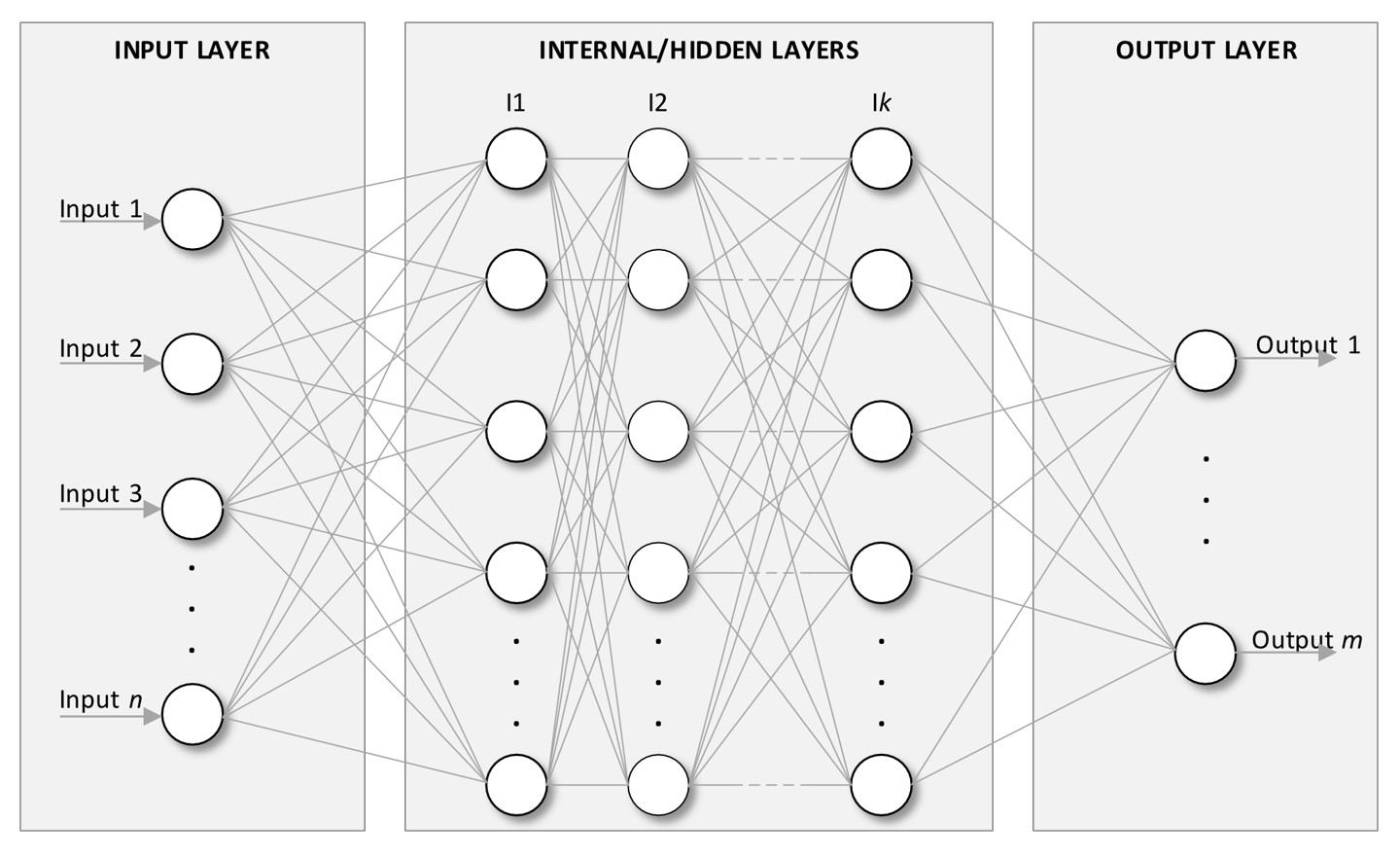
Let’s imagine implementing an AI model capable of predicting the likelihood of a river overflowing. In this scenario, the model would include features such as the amount of rainfall in the past 24 hours, amount of rainfall forecasted for the next few days, current and forecasted temperatures, humidity, and the current river level. Each of this feature will require an input neuron. The outputs might include predictions for the water level and the likelihood of overflow.
It is assumed that the model has been trained with historical data, where the set of features has been linked to the corresponding output variable(s).
Weight and Bias
Each connection between neurons (synapses in biological neural networks) has an associated weight that LLMs adjust as learning progresses. Biases are added to the weighted sum of inputs (making it an attribute of the neurons) to improve model fit (see Figure 3).
Weights
Weights are numerical parameters that adjust the strength of the input signals to the neuron, determining how much influence each input has on the neuron’s output. Each input is multiplied by its corresponding weight; thus, weights can amplify or diminish the value of the inputs. By adjusting these weights during training, the network learns which features of the input data are more important for making predictions. For example, the model could assign higher value to the amount of rainfall in the past 24 hours, and a lower weight to the humidity factor. During the training process, gradients are computed to update the weights using optimization algorithms, with the aim of minimizing the loss function, which quantifies the difference between predicted and actual outputs.
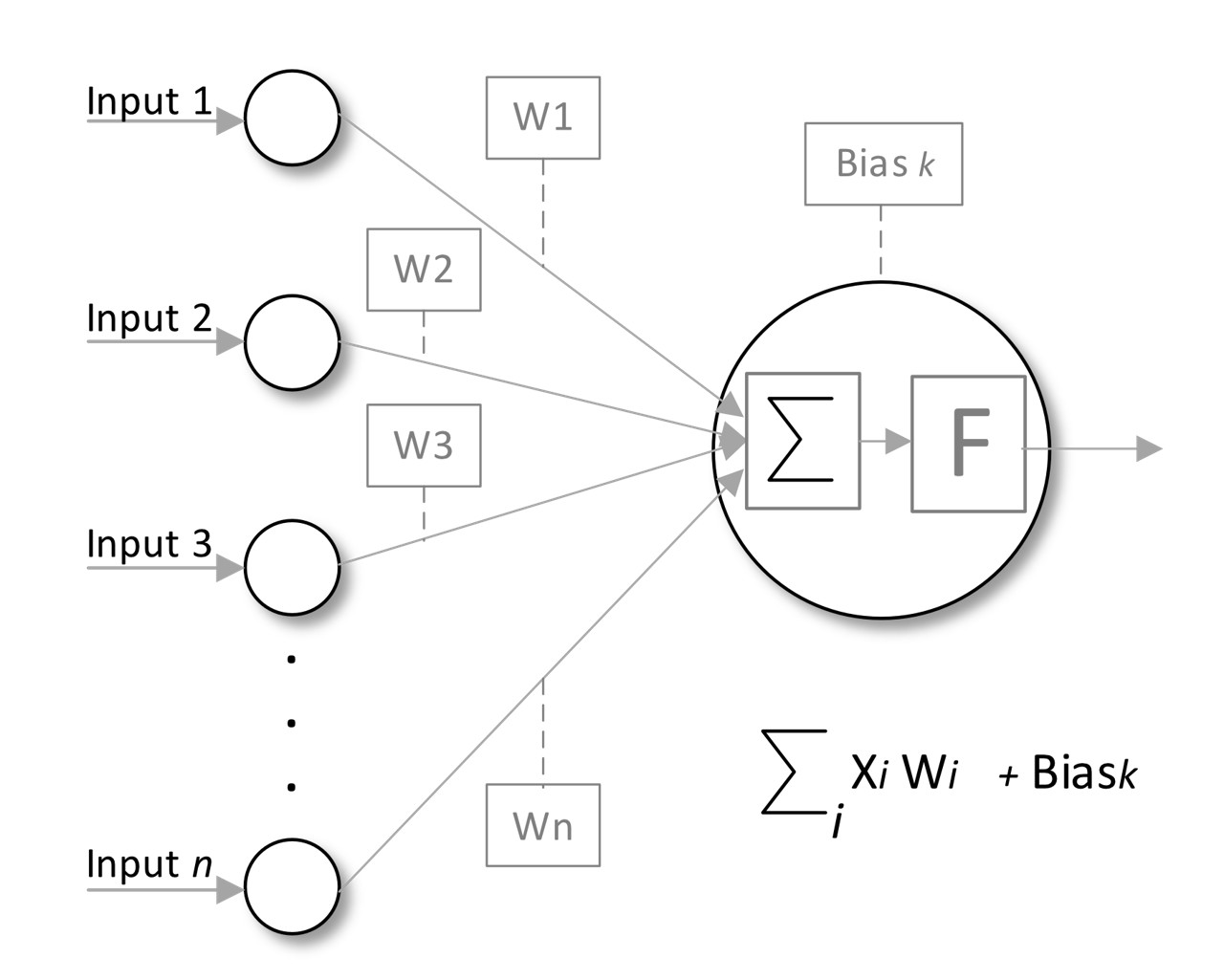
Biases
A bias is a separate trainable parameter added to the weighted sum of inputs before applying the activation function. The purpose of the bias is to allow the model to fit the data better by providing a means to shift the activation function left or right (it is a parameter outside the sum). This is especially useful when the data does not pass through the origin (0,0), as it gives the neuron greater flexibility in adjusting its output. Like weights, biases are also adjusted during the training phase based on gradients computed during backpropagation. Each bias is updated individually to help minimize the overall loss.
The combination of weights and biases enables neural networks to learn complex functions and patterns in data, facilitating hierarchical feature extraction. By incorporating biases and utilizing activation functions, neural networks can model non-linear relationships, making them powerful tools for tasks such as image recognition, natural language processing, and more. In summary, weights and biases are essential for neural networks, as they govern how inputs are transformed and processed to produce outputs. Their proper initialization and adjustment during training significantly impact the model’s performance.
Activation function
An activation function is a mathematical operation applied to the “potential” output of a neuron, determining whether it should be activated or not. It introduces non-linearity into the model, allowing the network to learn complex relationships and patterns in the data. It can be viewed as a decision-maker, similar to a light switch: when the input signal reaches a certain level, the switch turns on, permitting the neuron to send its signal to the next layer in the network. For example, with the ReLU (Rectified Linear Unit) activation function, if the input to a neuron is a number, ReLU will output that number if it’s greater than zero; otherwise, it outputs zero. This means for example that:
- If the input is 3, ReLU outputs 3 (the neuron “fires”).
- If the input is -2, ReLU outputs 0 (the neuron does not “fire”).
By shaping the output of neurons in this manner, activation functions play a crucial role in how information flows through the network, enabling it to make accurate predictions.
The most popular activation functions are:
- Sigmoid: Best suited for binary classifications; it maps outputs to the range (0, 1) but suffers from the vanishing gradient problem at extreme input values.
- ReLU (Rectified Linear Unit): Widely used for hidden layers; it is efficient and effective but may encounter issues with inactive neurons, leading to the “dying ReLU” problem.
- Softmax: Ideal for multiclass outputs; it transforms logits into a probability distribution but requires careful handling of input scale to avoid numerical instability.
Sigmoid Activation Function
The sigmoid function maps any input value to a range between 0 and 1 and exhibits an S-shaped (sigmoidal) curve. Its output is valuable in the context of binary classification tasks, as it provides a straightforward interpretation in terms of probabilities. Additionally, the sigmoid function smooths gradient (the gradient indicates how sensitive the output is to changes in the input), making optimization easier. However, one notable disadvantage of the sigmoid function is that it tends to saturate for very high or very low input values. This saturation can cause gradients to become negligible, leading to the vanishing gradient problem where updates to the weights become ineffective.
ReLU (Rectified Linear Unit)
The ReLU activation function outputs the given input if it is positive; otherwise, it outputs zero. As a result, it outputs values in the range between 0 and positive infinity. ReLU is widely employed in the hidden layers of deep neural networks due to its significant performance benefits. The advantages of ReLU include its computational efficiency, as it involves only a simple thresholding at zero. Moreover, it effectively mitigates the vanishing gradient problem since it does not saturate for positive inputs. However, a specific disadvantage is the potential for the “dying ReLU” problem, where neurons can become inactive and stop learning if they consistently produce zero outputs for negative inputs.
Softmax Activation Function
The Softmax function normalizes a vector of raw scores (also known as logits) into a probability distribution over multiple classes. This normalization helps produce clearer and more interpretable probabilities, making it easier to determine which class is the best prediction. The Softmax function outputs values within the range (0, 1) for each component, with the sum of all components equalling 1. Softmax is commonly used in the output layer of multiclass classification problems. Its advantages include providing a probabilistic interpretation of outputs, indicating the likelihood of each class, and it works well in conjunction with categorical cross-entropy loss during training. However, one key disadvantage is its sensitivity to outliers due to the exponentiation step, which can lead to numerical instability if the logits are very large or very small.
These activation functions are among the most popular ones and also the easiest to understand. Therefore, they have been introduced here to provide readers with an easier-to-understand explanation.
A simple example
Let’s consider the AI model capable of predicting the likelihood of a river overflowing. This model could be structured as following:
Input Layer
The input layer will consist of seven nodes corresponding to the following chosen features:
- Amount of rainfall in the past 24 hours
- Amount of rainfall forecasted for the next few days
- Current temperature
- Forecasted temperature
- Current humidity
- Current river level
- River margin
Hidden Layers
The model will include several hidden layers in your ANN, the number of hidden layers and nodes in those layers vary based on the complexity of the problem and the size of your dataset. A common starting point is to consider two hidden layers with a number of nodes that might range from 5 to 20. Then via a proper experimentation with these parameters may be necessary to optimize performance.
Output Layer
The model requires two types of outputs and therefore a total of 2 nodes:
- A continuous value which predicts the water level
- a binary output: overflow or no overflow
It is possible to consider only the first output and to derive the second. If the water level exceeds the river margins, then there’s an overflow, otherwise not.
Let’s show the example with real numbers.
Assuming the following input values:

Assume we have a hidden layer with 3 nodes. The weights and biases for these nodes (for simplicity, we will use small values) might be as follows:

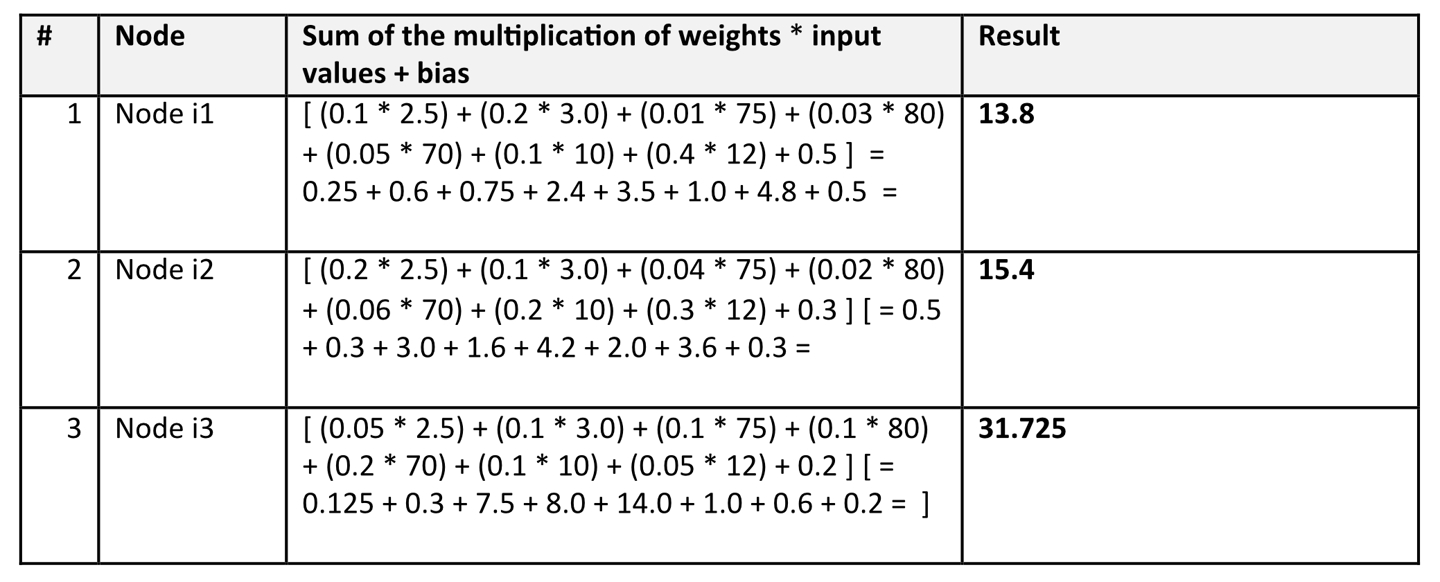
Let’s assume for simplicity that the activation function is ReLU, therefore these outputs will then be forwarded to the output layer for final predictions. Let’s consider only the following output node:


So, the output of the Node o1: Continuous Water Level Prediction, is 21.6575 m which is a clear overflow!
Now, the model was extremely simple for explanation purposes, however, it is clear that a key part of the models is given by the weights and the bias. These are fundamental outputs of the learning process.
ANN: origin and evolution
In the 1940s, Warren McCulloch, a neurophysiologist, and Walter Pitts, a logician, proposed a groundbreaking model of the biological neuron (see [McCulloch, Pitts, 1943]). At that time, a lot of what we know about neurons had not yet been understood, and still they pioneered a method to represent neuronal activity and communication within logical structures, influencing both artificial intelligence and the understanding of brain function. They proposed a simplified model of neurons based on binary logic. Each neuron has a threshold and can be activated by simultaneous excitatory inputs, with inhibition capable of preventing activation. They suggested that neurons operate within a fixed time frame, making decisions about firing in discrete moments. They employed other assumptions regarding neuron behaviour, including fixed synaptic delays and integration times, which were based on the limited biological knowledge of their time. Neurons were described as logical elements, where their firing states represent logical propositions about the inputs from preceding time intervals.
Initially, the model omitted feedback, focusing on feedforward neural networks. However, they recognized the potential for future work to incorporate feedback mechanisms, which complicate the analysis of network behaviour.
McCulloch and Pitts laid the groundwork for understanding neural networks and computing systems. Their conceptualization of logical devices influenced initial computer architecture, particularly in the design of digital computers like the EDVAC. Advancements have shown that the assumptions made by McCulloch and Pitts were overly simplistic. Modern neuroscience indicates neurons operate in more complex and asynchronous ways, often functioning in a continuum rather than strictly binary. Despite inaccuracies in their model, the fundamental ideas derived from McCulloch and Pitts’ work persist in contemporary neuroscience discussions regarding neuronal communication and ensemble coding.
They key Components of their model included:
- Inputs: Binary signals (0 or 1) representing synaptic inputs from other neurons.
- Weights: fixed values representing the strength of connections (excitatory or inhibitory).
- Threshold: A predefined value that determines whether the neuron “fires” (outputs 1) or not (outputs 0).
- Output: Binary (0 or 1) calculated as 1 if the weighted sum of inputs meets or exceeds the threshold, otherwise 0.
After the foundational work of McCulloch and Pitts, several significant developments in ANNs emerged, marking important advancements in the field.
Frank Rosenblatt in the late 1950s Developed the perceptron (see [Rosenblatt, 1958]). This is often considered the first true neural network algorithm, laying the groundwork for supervised learning in ANNs. It operates as a single-layer network that makes binary decisions based on input features. Despite its limitations, for example the inability to solve non-linear problems, the perceptron sparked interest and research that led to the development of multi-layer networks.
David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams in the late 1980s, proposed the backpropagation (see [Rumelhart, et al. 1986]) based on multi-layer networks (multi-layer perceptrons) to train effectively by adjusting weights across multiple layers in response to errors. This technique enabled the minimization of the loss function (it measures the difference between the predicted and actual outputs). The introduction of backpropagation was pivotal in making neural networks practical for complex tasks, leading to later advancements in deep learning.
LeCun, Y., Bottou, L., Bengio, Y., & Haffner Introduced in the 1990s and popularized in the 2010s the Convolutional Neural Networks (CNNs, see [LeCun et al., 1998]). CNNs revolutionized image processing tasks by detecting spatial hierarchies through convolutional layers. These networks use filters to capture local patterns, which makes them particularly effective for visual data. CNNs have since become essential in various applications, including facial recognition, object detection, and medical image analysis, significantly outperforming previous methods.
Sepp Hochreiter and Jürgen Schmidhuber designed the Recurrent Neural Networks (RNNs) to handle sequential data, including Long Short-Term Memory (LSTM) networks (see [Hochreiter et al., 1997]), advanced natural language processing and time series prediction. RNNs maintain an internal state that can capture information from previous inputs, facilitating tasks that depend on context, such as language modelling and translation. LSTMs, an evolution of standard RNNs, addressed issues of vanishing gradients, making them suitable for longer sequences.
Yann LeCun, Yoshua Bengio & Geoffrey Hinton made a significant contribution to the rise of deep learning in the early 2010s (see [LeCun et al., 2015]), characterized by large networks with many layers, led to breakthroughs in speech recognition, image classification, and game playing. Deep learning models leverage vast amounts of data and computational power to learn complex representations hierarchically. This shift has spurred innovation across industries, from autonomous vehicles to healthcare diagnostics.
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville and Yoshua Bengio proposed the Generative Adversarial Networks (GANs) which allow the generation of new data through competing networks (a generator and a discriminator). The generator creates synthetic data, while the discriminator assesses the authenticity relative to real data. This adversarial training approach has led to impressive results in image synthesis, enabling applications such as deepfakes and art generation, showcasing the creative potential of AI.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin, introduced in 2017, the transformer architecture (see [Vaswani et al., 2017]). This has become the foundation for state-of-the-art models in natural language processing, leveraging self-attention mechanisms. Transformers allow for parallel processing of input sequences, significantly improving efficiency and scalability compared to recurrent architectures. This innovation has also led to advancements in language understanding and generation, with models like BERT and GPT achieving remarkable performance on various NLP benchmarks. Chat GTP, Generative Pre-Trained Transformer, includes the Transformer in its name to highlight the importance of the underlying transformer architecture.
Conclusion
In this paper, we began our journey to explain how AI models are structured and how they function. The objective of this series of papers is to provide readers with an informal, jargon-free, yet detailed explanation of AI models. By avoiding excessive technical language and complex mathematics, we aim to ensure that those without a strong background in mathematics and computer science can grasp the fundamental concepts of AI models. This approach seeks to alleviate concerns about this critically important technology and enable users to utilize it more effectively.
The focus of this paper is the structure of AI models, particularly Artificial Neural Networks (ANNs), which constitute the internal components of these models.
We started by describing biological neural networks (BNNs). Although we only scratched the surface, this discussion was essential for understanding their roots and foundational concepts. ANNs are inspired by BNNs and serve as a foundational component of large language models (LLMs). Their objective is to mimic the operational processes of the human brain. While BNNs, at the moment, do not replicate the brain’s functions, they attempt to capture some of its structural and functional aspects. For decades, researchers were convinced they could successfully replicate human neural networks. This goal does not seem possible in the near future.
According to their roles, biological neurons can be divided into three categories: sensory neurons, motor neurons, and interneurons. Sensory neurons receive information about the internal and external environments of the body and convey this information to the Central Nervous System (CNS) for processing. Motor neurons receive information from other neurons and transmit commands to muscles, organs, and glands. Interneurons, found only within the CNS, connect neurons to one another, receiving information from sensory neurons or other interneurons and transmitting it to motor neurons or additional interneurons. This explains why ANNs are organized into three layers: the Input Layer, which is the network’s entry point for input data; the Hidden Layers, which consist of one or more layers where computations occur and where each neuron applies transformations to the inputs, enabling the network to learn complex features; and the Output Layer, which provides the network’s final output.
Each connection between neurons (analogous to synapses in biological neural networks) has an associated weight that adjusts as learning progresses. Biases are added to the weighted sum of inputs, enhancing model fit. These factors are determined during the training phase. By adjusting the weights throughout training, the network learns which features of the input data are more important for making predictions.
An activation function is a mathematical operation applied to the potential output of a neuron, determining whether it should be activated. It introduces non-linearity into the model, allowing the network to learn complex relationships and patterns in the data. The activation function can be viewed as a decision-maker, akin to a light switch: when the input signal reaches a certain threshold, the switch turns on, enabling the neuron to send its signal to the next layer in the network.
In upcoming papers, we will explain how more complex LLMs work, shifting the focus from the internal structure to functionality.
References
[McCulloch, Pitts, 1943] McCulloch, W.S., Pitts, W. “A logical calculus of the ideas immanent in nervous activity”. Bulletin of Mathematical Biophysics 5, 115–133 (1943).
https://doi.org/10.1007/BF02478259
[Rosenblatt, 1958] Frank Rosenblatt, “The perceptron: A probabilistic model for information storage and organization in the brain”
https://psycnet.apa.org/record/1959-09865-001
[Gamma et al., 1995] E. Gamma, R. Helm, R. Johnson, and J. Vlissides, Design Patterns : Elements of Reusable Object-Oriented Software. Reading, Mass. :Addison-Wesley, 1995.
[Rumelhart, et al. 1986] David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams, “Learning representations by back-propagating errors”. Nature 323, 533–536 (1986).
https://doi.org/10.1038/323533a0
[Hochreiter et al., 1997] Sepp Hochreiter, Jürgen Schmidhuber; Long Short-Term Memory. Neural Comput 1997; 9 (8): 1735–1780.
doi: https://doi.org/10.1162/neco.1997.9.8.1735
[LeCun et al., 1998] LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). “Gradient-Based Learning Applied to Document Recognition.” Proceedings of the IEEE
https://ieeexplore.ieee.org/document/726791
[Nicholls et al., 2001] Principles of signaling and organization. In From neuron to brain. Sunderland, MA: Sinauer Associates.
[Reece et al., 2011] Neuron structure and organization reflect function in information transfer. Campbell biology. San Francisco, CA: Pearson.
[Hanani, M., 2005] “Satellite glial cells in sensory ganglia: From form to function”. Brain Research Reviews, 48, 457-476.
https://www.sciencedirect.com/science/article/abs/pii/S0165017304001274
[Khan Academy, 2012] The neuron and nervous system. Overview of neuron structure and function. Introduction to neurons and glia. How the structure of a neuron allows it to receive and transmit information.
https://www.khanacademy.org/science/biology/human-biology/neuron-nervous-system/a/overview-of-neuron-structure-and-function
[Goodfellow et al. 2014] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville and Yoshua Bengio (2014). “Generative Adversarial Networks.”
https://arxiv.org/abs/1406.2661
[LeCun et al., 2015] Yann LeCun, Yoshua Bengio & Geoffrey Hinton. (2015). “Deep Learning.” Nature.
https://www.nature.com/articles/nature14539
[Solomon, 2016] Sensory receptors. In Introduction to human anatomy and physiology. Maryland Heights, MO: Saunders.
[Rye et al, 2016] Connie Rye, Robert Wise, Vladimir Jurukovski, Jean DeSaix, Jung Choi, Yael Avissar, Biology, OpenStax, 2016
https://openstax.org/books/biology/pages/1-introduction
https://openstax.org/books/biology/pages/35-1-neurons-and-glial-cells#fig-ch35_01_04
[Byrne, 2016] “Introduction to Neurons and Neuronal Networks”. Neuroscience.
https://nba.uth.tmc.edu/neuroscience/s1/introduction.html.
[Vaswani et al., 2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin, 2017, “Attention is All You Need.” Advances in Neural Information Processing Systems (NeurIPS)”
https://arxiv.org/abs/1706.03762
[Drug Target R., 2019] Scientists discover unique imaging technique to view synapse proteins, Drug Target Review, 27 September 2019
https://www.drugtargetreview.com/news/50185/scientists-discover-unique-imaging-technique-to-view-synapse-proteins/
Acknowledgements
Dr Prof. Grigory Dianov
Reviewed and corrected the paragraphs related to neurons. Accepting that this is an IT paper and not a biochemistry study.
Gianluca Zoppo
For reviewing the article from an AI perspective.
Antonio Rotondi
For reviewing the article from a computer science perspective.
Francesco Saliola
For his patient corrections.