

Introduzione
Questo e il successivo articolo sono un adattamento dell’articolo originale in lingua inglese pubblicato anch’esso su MokaByte.
I container [1] rappresentano una nuova modalità per creare degli ambienti operativi isolati: sono più leggeri delle macchine virtuali e probabilmente anche più facili da gestire.
Per quanto la tecnologia basata sui container non sia ancora sufficientemente matura per un’ampia adozione a livello enterprise, molte aziende tra le più grandi e ricche già la tengono strettamente d’occhio con una prospettiva d’adozione a pochi anni dalla sua prima apparizione. Per fare un confronto, c’erano invece voluti svariati anni affinché le tecnologie di virtualizzazione ottenessero lo stesso livello di attenzione da parte delle grandi aziende enterprise.
Ritengo che la tecnologia basata sui container sia destinata a durare: vivrà accanto alla virtualizzazione e magari finirà con il tempo per sostituirla. La stessa considerazione si applica ai provider cloud: presto appariranno sul mercato dei fornitori di servizi cloud basati su container e coesisteranno con quelli basati sulla virtualizzazione.
In questo e nel prossimo articolo tenterò di spiegare l’evoluzione delle tecnologie, che cosa sono I container, quali funzionalità siano in grado di fornire, quali sono i “problemi” ancora irrisolti e, infine, quali sono I principali attori del mercato per quanto riguarda questa tecnologia.
Ma cominciamo questa panoramica dando uno sguardo all’evoluzione delle tecnologie nel campo della IT Operations (quella che, con termine italiano, viene a volte definita “esercibilità” del software…).
L’evoluzione tecnologica nel ramo IT Operations
Per meglio comprendere l’impatto dei container, può essere utile dare uno sguardo al modo in cui le pratiche IT Operations si sono sviluppate negli annni: l’immagine di figura 1 mostra una breve storia di questa evoluzione.
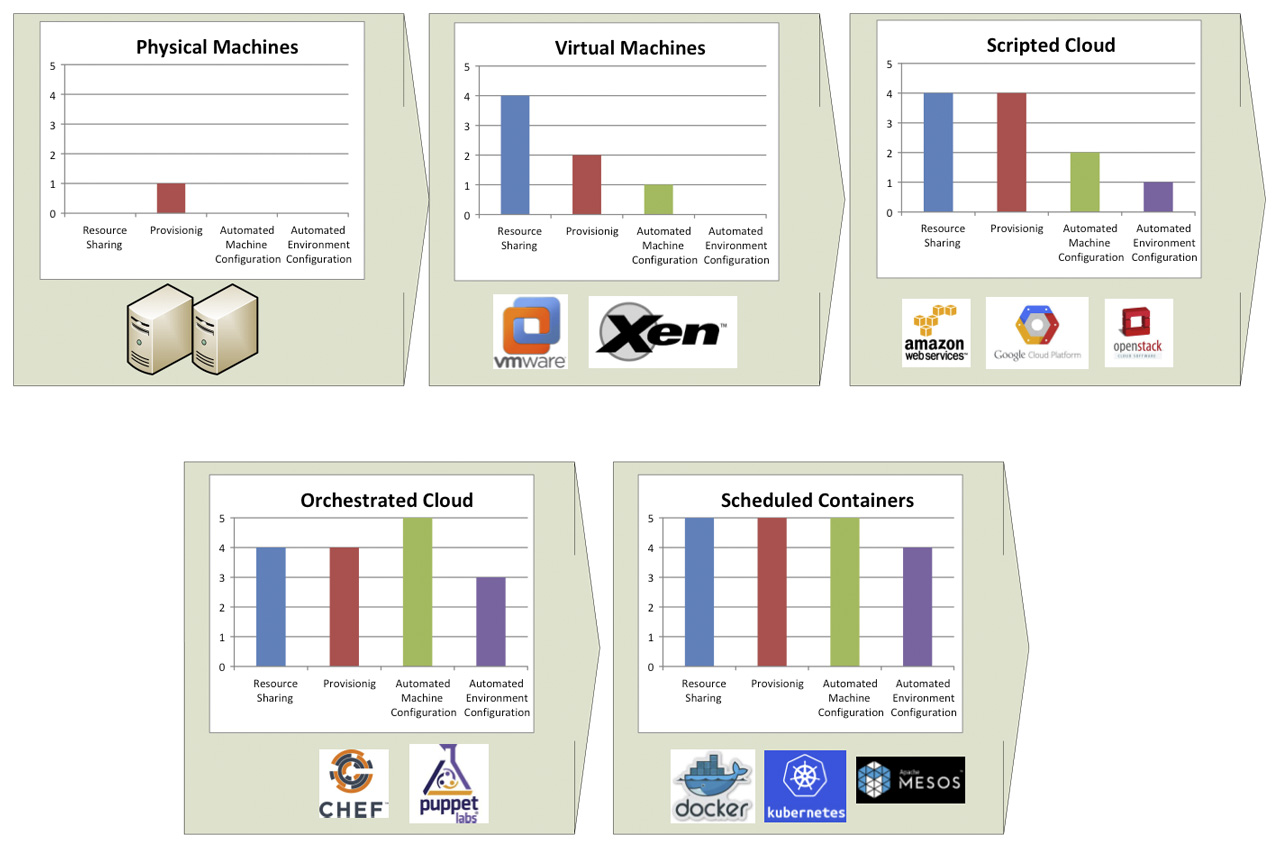
Dalle macchine hardware alla virtualizzazione
Inzialmente, tutto era basato su macchine “fisiche”. Il problema con questo modello è che l’approvvigionamento di macchine è in genere lento poiché si tratta, in sostanza, di acquistare hardware. Oltre a questo, con le macchine fisiche non c’è condivisione di risorse e, fatto da non sottovalutare, installazione e configurazione sono operazioni manuali.
La virtualizzazione andava a risolvere alcuni di questi problemi: in cambio di un leggero calo di prestazioni, diventava possibile ottenere una condivisione delle risorse nettamente migliore, con svariate macchine virtuali (VM) in esecuzione sullo stesso hardware. Il procurement (approvvigionamento delle risorse) e la configurazione, però, restavano passaggi da effettuare manualmente.
Cloud computing
Il passo successico è stato il cloud computing. Il cloud computing — in particolare nella sua versione IaaS [2] (Infrastructure as a Service) — è un sistema in cui le risorse IT (computazionali, di rete, di memoria e di immagazzinamento) sono disponibili “su richiesta”. E non solo queste ricorse sono disponibil on demand ma sono anche fruibili tramite API.
Diventa quindi possibile utilizzare queste API per procurarsi e configurare le macchine, lo spazio di storage in cui salvare i dati, e i collegamenti di rete che vanno tutti a costituire la soluzione che dobbiamo costruirci: definisco questo approccio scripted cloud. Generalmente, l’insieme di componenti e configurazioni che vanno a costituire la soluzione scelta viene chiamato ambiente.
Pertanto, con il cloud “a script” è possibile creare script che fanno partire degli ambienti on demand. L’infrastruttura è quindi adesso descritta come codice (Infrastructure as Code, IaC) [3].
Però, gli script basati su linguaggi imperativi tendono a essere difficili da manutenere e a fornire una limitata possibilità di riuso: in altre parole, non scalano facilmente verso ambienti ampi e complessi. Questa limitazione ha favorito la creazione di strumenti maggiormente dichiarativi.
Cloud “orchestrato”
Il cosiddetto orchestrated cloud ha introdotto un approccio dichiarativo per la creazione e la configurazione di risorse computazionali, di storage e di rete: vale a dire, un vero e proprio provisioning di ambienti. Nuovi strumenti hanno fornito un solido approccio all’applicazione di configurazioni a macchine appena create.
Il modo in cui funziona la maggior parte di tool è la seguente: quando la macchina si avvia, un agente contatta un server centralizzato di configurazione e scarica da esso le istruzioni di configurazione per la macchina in questione.
Questi strumenti hanno capacità limitate per l’approvvigionamento delle macchine — il procurement dipende ancora in larga parte dalla sottostante tecnologia cloud — e di monitoraggio dello stato della macchina con conseguente correzione se lo stato non coincide con quello desiderato, vale a dire numero errato di elementi cluster attivi, file di configurazione modificati in maniera inappropriata etc.
Chef [4] e Puppets [5] sono due esempi di questa tecnologia. Anche provider di IaaS pura hanno aggiunto capacità simili come funzionalità native delle loro piattaforme (p.e.: CloudFormation [6] per Amazon Web Services [7] oppure CloudDeploymentManager [8] per Google Cloud Platform [9]).
Scheduled containers
Gli scheduled containers sono l’ultima aggiunta a questa serie di miglioramenti tecnologici e metodologici. I container rappresentano un modo migliore rispetto alle macchine virtuali per fornire risorse computazionali. Infatti, i container forniscono prestazioni migliori e una maggiore condivisione di risorse, mantenendo al contempo più o meno lo stesso livello di isolamento. È principalmente dei container che ci occuperemo in questi due articoli.
I container promuovono l’idea di Immutable Infrastructure [10] poiché rendono molto semplice implementare una configurazione “basata su immagine” (image-based). Le “immagini” dei container, inoltre, sono estremamente portabili, a differenza delle immagini di VM. Docker [11] l’implementazione di container più diffusa, ma esistono anche altre implementazioni di container, come LXC [1] e Rocket [13].
Gli orchestrator, nel mondo dei container, vengono di solito chiamati scheduler ed è per questo che parlo di scheduled container in relazione a queste tecnologie. Sebbene lo scenario sia in rapida evoluzione, vale comunque la pena di mettere in luce l’idea di base verso cui questi prodotti si orientano. Gli scheduler dei container tentano di costruire un livello di astrazione sopra alcune risorse fisiche, potenzialmente collocate su uno o più data center, in modo tale che gli utenti possano “calendarizzare” i loro lavori senza la necessità di sapere dove essi verranno eseguiti. Esempi di scheduler per container sono rappresentati da Kubernetes [13], Mesos [14] e Docker Compose [15].
Qualche informazione ulteriore sulla gestione della configurazione
La gestione della configurazione è una delle pratiche più difficili nell’ambito Operations. Ci sono molte ragioni per cui le configurazioni dei sistemi devono cambiare: patch di sistema, “toppe” per la sicurezza, aggiornamenti del middleware, deployment di applicazioni e così via.
Ciascuna di queste modifiche ha una maniera differente di essere messa in produzione: questo significa processi differenti, tool diversi, e persone differenti che lavorano a esse. Tutto ciò crea complessità e soluzioni soggette all’errore.
Le cose sono diverse in un ambiente cloud. Seguendo la buona pratica della “struttura immutabile”, il modo migliore di applicare cambiamenti di configurazione in un ambiente cloud consiste semplicemente nel riciclare la risorsa, che si tratti della macchina virtuale o del container.
Con il termine riciclare intendo di spegnere la risorsa computazionale in funzione e sostituirla con una analoga risorsa che ha già la nuova configurazione. Questo semplifica le attività Ops poiché a questo punto c’è un solo modo per applicare i cambiamenti, che quindi può essere ottimizzato al massimo. Non c’è altro modo di modificare una risorsa computazionale dopo che è stata avviata; questo fa aumentare la stabilità evitando che la sua configurazione possa seguire una pericolosa deriva rispetto allo stato desiderato.
Affinché questo approccio funzioni, ci sono due aspetti da tenere ben presenti. Il primo è il modo in cui creiamo e aggiorniamo le definizioni di configurazione. Il secondo è il modo in cui applichiamo tali definizioni di configurazione in maniera tale che questa operazione non interrompa il servizio: oggigiorno è spesso richiesto come requisito che non ci siano più le classiche interruzioni di servizio a orari prestabiliti cui ci eravamo abituati per anni in ambito sistemistico. Vediamo di seguito questi due aspetti in maggiore dettaglio.
Gestione della configurazione: agent-based vs. image-based
Esistono due scuole di pensiero sul modo in cui creare e manutenere le configurazioni: image-based e agent-based.

Si tratta in effetti dei due estremi di un’unica linea continua; dovendo definire il loro processo di gestione del cambiamento, la maggior parte delle aziende si collocherà in una delle innumerevoli posizioni lungo questa scala.
La gestione della configurazione image-based prevede un’immagine per ciascun tipo di server che si abbia necessità di istanziare. Quando si avvia l’immagine, il server è pronto a operare, e nessuna ulteriore configurazione è necessaria. A volte il comportamento del server può essere modificato passando delle variabili d’ambiente all’avvio o allegando ulteriori file di configurazione. Un vantaggio di questo approccio sta nel fatto che generalmente i tempi di avvio sono più brevi rispetto alla gestione della configurazione agent-based. Un inconveniente, invece, è rappresentato dal numero di immagini da gestire, che può crescere velocemente fino a finire fuori controllo. La strategia image-based è di solito quella seguita dai container.
Nella gestione della configurazione agent-based, ci sono solo pochissime immagini, che devono essere gestite opportunamente. Attraverso un agente che è preinstallato in tutte le immagini, un server centralizzato applica la configurazione alle Virtual Machine quando esse vengono avviate. Puppet e Chef sono due tra i più conosciuti prodotti in questo campo.
Strategie di deployment per il cloud
Il secondo elemento di cui abbiamo bisogno per riciclare efficacemente le risorse computazionali è una strategia di deployment che non crei interruzioni di servizio. Nella maggior parte dei casi, i servizi vengono forniti da cluster di macchine identiche, per cui la nostra strategia di deployment dovrà consentirci di riciclare l’intero cluster.
Questo campo è relativamente maturo per servizi stateless. I servizi stateless sono quelli che non fanno affidamento su uno stato locale: i data store — che si tratti dei tradizionali RDBMS o degli ormai affermati NoSQL — sono invece servizi stateful. Gli strati di servizio e l’applicazione web possono essere considerati servizi stateless anche quando possiedano una sessione, a patto che la sessione sia ragionevolmente breve nel tempo o che il cluster abbia una capacità di gestione del failover di sessione.
Con i servizi stateless esistono due pratiche ben stabilite per eseguire il riciclo di un cluster: il rolling deployment e il blue–green deployment [16].
Rolling deployment
Con i rolling deployment ciascun elemento del cluster viene riciclato separatamente. il load balancer della richiesta deve partecipare attivamente a questo deployment reindirizzando la richiesta al server appropriato. La sequenza è la seguente:
- Viene creato un nuovo server con la nuova configurazione e il load balancer comincia a inviare una condivisione del carico a questo server.
- Viene rimosso un vecchio server dal cluster. Se questo server utilizza le sessioni, e non è disponibile un meccanismo di gestione del failover, il vecchio server viene mantenuto vivo fin quando tutte le sessioni non saranno state concluse.
- Questo ciclo verrà ripetuto finché tutti i server saranno stati riciclati.
Un approccio come questo presenta alcuni inconvenienti quando il numero di server che compongono il cluster è molto elevato. In questo caso, l’operazione di riciclo di tutti i server potrebbe prendere molto tempo, il che non è certo desiderabile. Kubernetes è un prodotto che è in grado di svolgere questo tipo di riciclo.
Blue-green deployment
L’approccio di tipo blue-green risolve il problema appena visto relativo al grande numero di server e ai tempi lunghi necessari a riciclarli tutti, uno alla volta.
Con il deployment blue-green, viene creato un nuovo cluster di risorse computazionali accanto a quello vecchio. Tutte le nuove richieste vengono reindirizzate dal load balancer verso il nuovo cluster. Se il server utilizza le sessioni, e non è disponibile un meccanismo di gestione del failover, il vecchio cluster viene mantenuto vivo fin quando tutte le sessioni non saranno state concluse.
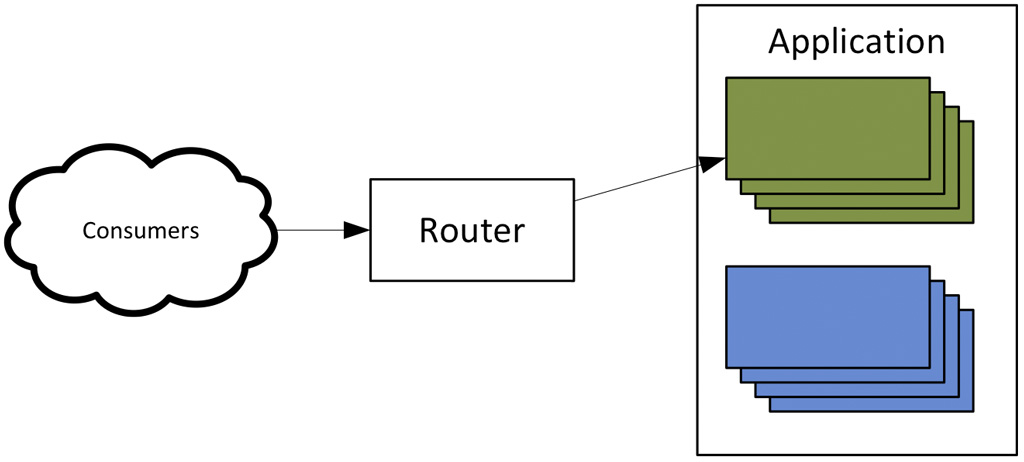
Il vantaggio di questa tecnica è rappresentato non solo da deployment più veloci, ma anche da rollback più veloci nel caso fallisse un deployment. Infatti, il vecchio cluster non deve necessariamente essere rimosso subito dopo il completamento del deployment, e può essere mantenuto “in panchina” fin quando non saranno state effettuate tutte le convalide necessarie per la nuova release.
Il deployment blue-green appare come la strada migliore da seguire quando sia disponibile una “riserva” di capacità computazionale non utilizzata e sia possibile istanziare con sicurezza due cluster paralleli per il servizio che deve essere aggiornato.
Conclusioni
Abbiamo visto in questo primo articolo una panoramica sulle tecnologie che consentono l’esercibilità del software in ambito IT Operations, analizzando la situazione e passando in rassegna alcuni principi alla base del funzionamento dei container.
Nel prossimo numero concluderemo la discussione analizzando più a fondo i container, esaminando Docker, uno dei prodotti più diffusi e conosciuti, e dando uno sguardo anche ad altre soluzioni.
Raffaele Spazzoli ha lavorato per piu di 10 anni a Imola Informatica come consulente con il ruolo di architetto delle applicazioni e delle integrazioni.
Attualmente lavora in KeyBank, una banca statunitense, come architetto dei canali fisici (filiali e contact center) e digitali (web e mobile).