

Nel precedente articolo avevamo visto un’ampia panoramica sul mondo delle IT Operations e sui diversi approcci alla gestione delle Ops, osservando come questo mondo sia stato modificato negli ultimi anni dall’avvento di nuovi strumenti tecnologici e di approcci metodologici innovativi. Ricordando che un articolo in inglese è stato già pubblicato su queste pagine, concludiamo in questo articolo le nostre considerazioni, passando in rassegna i diversi container attualmente disponibili.
Container
Linux containers [29] rappresenta una tecnologia che consente di eseguire processi LInux in un ambiente isolato. Un processo “containerizzato” va in esecuzione in modo tale che abbia un file system privato e non abbia visibilità di alcun altro processo che sia in esecuzione sullo stesso server Linux.
Questo tipo di isolamento viene ottenuto grazie ai namespace [2]. Con i namespace è possibile proteggere le seguenti risorse del kernel Linux: Inter Process Communications (IPC), configurazione di rete, il punto di mount della root, l’albero dei processi, gli utenti e i gruppi di essi, nonché la risoluzione del nome di rete. Senza addentrarsi in eccessivi tecnicismi, il vantaggio principale sta nel fatto che, con l’uso dei namespace, diventa possibile isolare i processi in modo molto efficace. L’unica cosa che il processo isolato nel container condivide con il sistema operativo ospitante è il kernel Linux.
cgroups
Al fine di gestire l’accesso alle risorse, i container utilizzano un altro modulo kernel chiamato “gruppi di controllo” (control groups, cgroups [3]). I control groups permettono di impostare le quote, impostare le priorità e misurare diversi tipi di risorse, quali la memoria, l’utilizzo della CPU, gli accessi al disco e così via.
Storicamente, i container sono stati sviluppati nell’ambito del progetto LXC [1]. Per quanto rappresenti una soluzione valida, LXC non è mai diventata popolare, principalmente per ragioni di usabilità e per la limitata portabilità dei container creati tramite questa tecnologia.
Docker
Docker parte proprio dalla tecnologia descritta sopra per costruire, spostare ed eseguire container Linux. Docker è un progetto open source con una azienda di supporto [4] che fornisce assistenza e altri servizi a pagamento. La forza di Docker, e una delle ragioni della sua diffusione, è la sua facilità d’uso.
Docker implementa una architettura client–server. Il client è un semplice strumento a linea di comando che invia comandi al server utilizzando servizi REST: questo implica che chiunque potrebbe costruire client differenti. Il server è un daemon Linux in grado di costruire immagini ed eseguire container sulla base di una immagine preesistente.
I container possono essere costruiti in maniera interattiva utilizzando un file di configurazione. La costruzione interattiva dei container dovrebbe essere usata “sperimentando” soluzioni perché consente di lanciare alcuni comandi che creano diversi cambiamenti all’interno di un container. Modifiche che poi possono essere rese definitive con un commit verso una nuova immagine di container.
I container basati su file di configurazione possono essere utilizzati nella costruzione di processi automatizzati, come è possibile vedere da un esempio relativo a una immagina Docker che esegue CentOS [5].
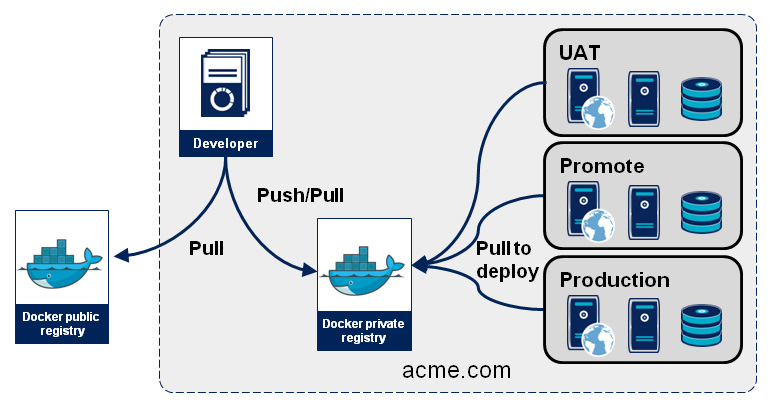
Le immagini Docker possono essere immagazzinate in un repository per facilitarne la condivisione. Docker offre un prodotto chiamato Docker Trusted Registry che può essere installato in locale e anche un repository pubblico. Sono poi disponibili altri prodotti, ad esempio Artifactory.
Artifact repository
Il concetto di artifact repository, una sorta di “deposito di manufatti”, (Nexus [6], Artifactory [7], Archivia [8], etc.) non è nuovo. Molti sistemi di build con gestione automatizzata delle dipendenze si basano su questi strumenti, ma Docker spinge ancora più avanti i limiti della questione. Infatti, l’uso tradizionale di un artifact repository sta nell’immagazzinare i risultati di una build, magari dopo l’esecuzione di una suite di test di integrazione automatizzati.
Ora, con Docker, possiamo immagazzinare nel repository un’immagine di container con un’applicazione di cui già è stato effettuato il deployment, e il tutto già pronto per andare in esecuzione su qualsiasi server. In altre parole, le impostazioni di configurazione che si solito sarebbero definite solo al momento del deployment, vengono invece anche esse incorporate nell’immagine [9]. Tutto cio finisce per accrescere ulteriormente l’affidabilità dei nostri rilasci.
Union File System
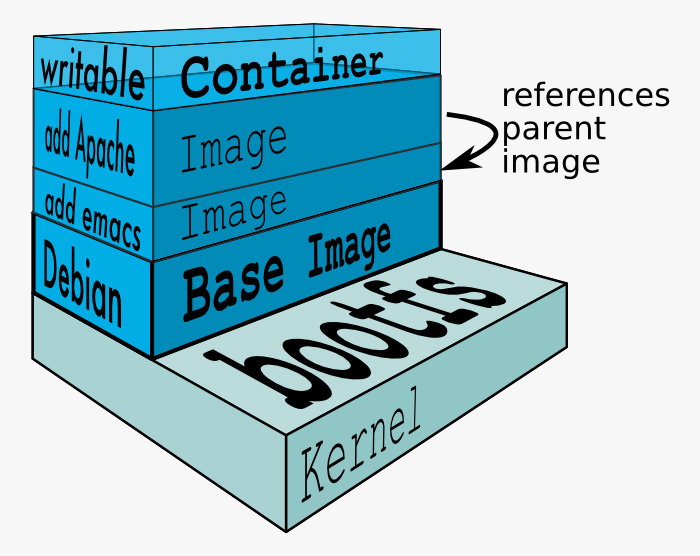
Una caratteristica davvero interessante di Docker è il modo in cui viene gestito il file system. Docker utilizza un’implementazione di Union File System [10] per comporre il file system che apparirà visibile al container. Gli Union File System (ad esempio UnionFS o aufs [11]) consentono di unire diversi file system e montarli in un unico punto di mount.
Un’immagine Docker è in realtà un insieme di file organizzati in directory: in definitiva, è un file system. Un’immagine docker può essere costruita sulla base di un’immagine già esistente semplicemente aggiungendo e/o modificando alcuni file. E questo può essere ripetuto per un numero illimitato di volte. Un’immagine può essere ad esempio costituita da 4 strati: questo concetto è conosciuto anche come “immagini stratificate” (layered) [12].
Nell’esempio precedente, quando l’immagine Docker va in esecuzione, i quattro file system vengono uniti insieme (merge) in modalità sola lettura, e ad essi viene sovrapposto un ulteriore strato in modalità lettura–scrittura.
Se due container condividono parte degli strati dell’immagine, questi layer non dovranno essere replicati nel file system host, poiché sono montati in modalità sola lettura. Questo può generare significativi risparmi specie se un’azienda si dà una certa disclipina riguardo al modo in cui possono essere create le immagini: potrebbe essere il caso, ad esempio, di stabilire che tutte le immagini debbano derivare da una base comune.
In questo caso, siccome la base comune sarà probabilmente lo strato che prende la maggior parte dello spazio disco e gli altri layer dovranno aggiungere installazioni o configurazioni minori, tale semplice linea guida potrebbe far risparmiare grandi quantità di spazio disco.
Container vs. Virtual Machine
L’immagine di figura 3 [13] mette a confronto i container con le macchine virtuali. Nella figura, si dà per assodato che tutta l’implementazione del container userà lo stesso approccio di Docker per organizzare le immagini di configurazione.

Come è possibile vedere, i vantaggi principali dei container si riassumono in un minore consumo di memoria e spazio disco. I container usano meno memoria poiché tutti i container in un ambiente ospitante condividono lo stesso kernel. I container usano meno spazio su disco poiché le immagini dei container possono essere condivise da container che sono in esecuzione sullo stesso host.
Dal punto di vista della sicurezza, il consenso generale sembra essere a favore delle macchine virtuali. Infatti le virtual machine appaiono più sicure e più isolate rispetto ai container, ma la mia opinione è che anche questo cambierà con la progressiva maturazione della tecnologia container.
Docker e il supporto per Windows
Docker supporta solo container Linux; e questo, evidentemente, è un limite significativo. Microsoft ha affermato che che Windows Server 2016 supporterà container in maniera compatibile con Docker [14]. Dalle versioni beta di Windows Server 2016 ci renderemo conto di come andranno le cose, ma il supporto per i container Windows [15] in Azure Cloud è già disponibile. Il supporto per i container Windows sarà comunque inizialmente meno maturo di quello per Linux.
Oltre Docker
Il progetto Docker è nato con l’obiettivo di semplificare la creazione e la gestione di container. Docker svolge questi compiti in modo molto efficace e va riconosciuto al team che l’ha creato la capacità di mantenere l’ambito di questo progetto chiaro e limitato. Docker è un mattone per costruire dei sistemi cloud basati su container.
Costruire un ambiente cloud basato su container implica di tenere presenti alcune aree principali:
- container scheduling
- networking avanzato
- sicurezza
- monitoraggio
- quote e misurazioni
Vediamo di seguito questi diversi aspetti.
Container scheduling
Il container scheduling (più o meno “calendarizzazione dei container”) è la possibilità di definire e attivare un ambiente potenzialmente composto di diversi container. Come già detto, è un concetto simile a quello dell’orchestrazione negli ambienti cloud basati su Virtual Machine.
Attraverso il container scheduling si dovrebbe riuscire a definire la corretta sequenza di attivazione dei container, la dimensione del cluster di container che è necessario creare e la qualità del servizio dei container: per esempio, un’app potrebbe richiedere un minimo garantito di di memoria e di accessi al disco.
Tool avanzati per l’orchestrazione devono garantire anche che un determinato ambiente rifletta lo stato desiderato dopo essere stato creato: significa che questi strumenti di orchestrazione possono anche svolgere un certo grado di monitoraggio ed effettuare, almeno in parte, una autoriparazione nel caso lo stato dell’ambiente non si allinei con quello stabilito dalla configurazione.
Un’altra importante caratteristica comune a molti scheduler per container è la capacità di definire un livello di astrazione intorno a un cluster di container identici, in maniera tale che essi siano visti come servizio, vale a dire un indirizzo IP e una porta. Questo risultato è ottenuto facendo impostare allo scheduler un load balancer davanti al cluster di container accompagnato dalle regole di indirizzamento necessarie.
In quest’ambito, alcuni degli strumenti disponibili sono Kubernetes, Mesos e Docker Compose. Li vediamo di seguito.
Kubernetes
Kubernetes è un container scheduler reso disponibile come open source da Google, che afferma di utilizzare i container da circa dieci anni. Kubernetes, in tal senso, rappresenta un modo per condividere con il resto del mondo l’esperienza accumulata in questo periodo.
Kubernetes introduce il concetto di pod. I pod sono una serie di container che devono essere collocati insieme nello stesso host. Esistono svariate situazioni o modelli ricorrenti in cui una funzione come questa può essere necessaria: per esempio, un’applicazione potrebbe aver bisogno di un’altra applicazione “di accompagnamento” che si occupi di inviare i log [16].
Kubernetes introduce inoltre il concetto di “controller di replicazione”. Il compito di replication controller consiste nel garantire che tutti i pod di un cluster siano “in salute”. Se un pod è giù o non sta fornendo le prestazioni attese, il replication controller lo rimuoverà dal cluster e creerà un nuovo pod.
Oltre a questo, Kubernetes cerca di essere portabile tra implementazioni private di Docker e implementazioni cloud pubbliche, grazie all’uso di una architettura a plugin. Per esempio, la configurazione del load balancer necessaria per la definizione di un servizio attiverà un plugin differente a seconda che il deploy del progetto sia effettuato in Google Cloud invece che in Amazon Web Service. L’intenzione è quella di aggiungere plugin per collegarsi a diversi tipi di storage, per effettuare diverse tipologie di deployment, per utilizzare fornitori di sicurezza diversi e così via.
Mesos
Mesos è un progetto open source ospitato dalla Apache Foundation. Lo scopo di Mesos sta nel fornire “un sistema kernel distribuito”. Mesos tenta di trasportare i principi del kernel Linux sul sulla temporizzazione dei processi e applicarli a un cluster o a un intero datacenter.
Il progetto Mesos è cominciato nel 2012 ed è stato recentemente sottoposto a un processo di reingegnerizzazione per renderlo in grado di gestire i container Docker. Mesos utilizza ZooKeeper [17] per implementare i concetti dei servizi.
Mesos eccelle sulla portabilità ed è possibile creare dei cluster Mesos che si estendono su diversi datacenter e su differenti fornitori di servizi cloud.
Docker Compose
Docker Compose è una aggiunta recente all’insieme delle soluzioni Docker. Compose non può essere considerato ancora pronto per la produzione e non è neanche ben integrato con Docker Swarm, lo strumento di gestione dei cluster targato Docker.
Per ora, Docker Compose è in grado di controllare il ciclo di vita di un’applicazione composta di container multipli che sono in esecuzione sullo stesso host.
Il “problema dello zaino”
Se ci prendiamo il tempo di riflettere su ciò che effettivamente fa un container scheduler, ci rendiamo conto che il problema principale che deve risovlere è massimizzare l’utilizzo delle risorse fisiche che si trova a gestire. Abbiamo già detto che in questo i container sono migliori rispetto alle VM, ma in che modo possiamo massimizzare l’utilizzo rispetto all’infrastruttura fisica, soddisfacendo al contempo i vincoli che ha ciascuna applicazione?
Esempi di tali vincoli sono:
- Necessità tecniche: quantità di RAM disponibile, tipo di CPU, necessità in termini di I/O, presenza di processori GPU, tipo di sistema operativo (in futuro saranno supportati anche i container Microsoft).
- Vincoli topologici: per ragioni di disponibilità (availability) vogliamo che i componenti di un cluster non siano collocati sullo stesso host, o rack, o addirittura proprio non siano nello stesso datacenter. D’altro canto, desideriamo che alcuni container siano collocati insieme sullo stesso host (come nel caso di pod di Kubernetes).
- Tipologia di caricamento: priorità del load, load batch vs load online.
Questi vincoli rappresentano una variante del cosiddetto “problema dello zaino” [18] nel quale occorre cercare il modo migliore per inserire oggetti di forme e pesi differenti all’interno di zaini di forma e dimensione diverse. Il problema dello zaino è di tipo NP-completo [19] ne quindi non c’è modo di avere una soluzione che sia al tempo stesso veloce e ottimale. Occorre pertanto avere un programma per risolvere questo problema specialmente in un cluster con un grande numero di nodi.
Senza tante sorprese, una ricerca fatta da Google [20] mostra che miscelare diversi tipi di carico (online vs batch, CPU-bound vs Memory-bound vs I/O-bound) aiuta a massimizzare l’utilizzo delle risorse. Invece la sorpresa sta nel fatto che un impegno delle risorse al limite (over-commitment) è una buona strategia di allocazione. I ricercatori Google aggiungono anche che seguono questa strategia di over-commitment solo nei loro carichi interni e non applicano questo approccio ai loro servizi cloud pubblici. In una recente release di Mesos, l’over-commitment è disponibile come strategia di allocazione.
Networking
Docker fornisce un “interruttore virtuale” (routing al Livello 2) per consentire comunicazione di rete dei container tra di loro e con il resto del mondo. Non c’è supporto in Docker per i firewall (routing al Livello 3), per il reverse proxy (routing al Livello 7), per il load balancing e per le reti virtuali di container, utile nelle implementazioni multi-tenant o laddove sia richiesto un’isolamento della rete.
Queste funzionalità sono necessarie quando si debbano effettuare dei deployments nella realtà produttiva, e Docker non intende affrontarli. Come abbiamo visto, i container scheduler tentano di superare questo ostacolo, concentrandosi in special modo sulle funzionalità di firewall e load balancing. Il problema non è ancora del tutto risolto, e soprattuto non lo è in maniera portabile, vale a dire in maniera diffusa tra le diverse implementazioni di cluster Docker.
Ci sono però degli strumenti che stanno tentando di colmare tale lacuna, segnatamente Flannel [21] e Weave [22], ma anche qualcun altro.
Flannel e Weave
Flannel e Weave affrontano il problema di creare delle reti virtuali tra i container. Funzionano entrambi aggiungendo un router virtuale (routing al Livello 3) a cascata con il virtual switch di Docker, e affiancando un agente per gestire la configurazione del virtual router.
In entrambi i casi, la mancanza di una piena integrazione con Docker o con un container scheduler finisce per introdurre alcuni passaggi di configurazione manuale, il che sembra essere una limitazione a questo punto della storia. Ritengo che tool come questi saranno presto “inglobati” nei container scheduler.
A quanto mi risulta, non esiste una soluzione chiara per quel che attiene alle capacità di reverse proxy, e pertanto sarà necessario che tale funzione sia svolta da un software apposito, che magari sia in esecuzione all’interno di un container.
Sicurezza
Docker si prende cura di alcuni aspetti legati alla sicurezza, quali l’isolamento del container, ma non affronta tutti i problemi. Più specificamente, è responsabilità dell’implementatore del cluster Docker quella di fornire sicurezza intorno al daemon Docker. Questo diventa di primaria importanza in un’implementazione Docker multi-tenant.
Gli scheduler per container che abbiamo passato in rassegna hanno delle implementazioni basilari di sicurezza che possono essere integrate con sistemi di sicurezza a livello enterprise. Si tratta comunque di un’area destinata a vedere grossi sviluppi, poiché i container saranno progressivamente sempre più adottati dalle grandi aziende.
Quote e misurazioni
Come abbiamo visto, i container possono stabilire come debbano essere utilizzate le risorse su un singolo container; però in Docker non c’è un buon modo per stabilire l’utilizzazione globale delle risorse di un ambiente (un insieme di container) creato da un utente. Questo controllo, invece, è cruciale per evitare che una configurazione errata fatta da un team possa far crollare un intero cluster Docker poiché ne esaurisce le risorse.
Si tratta chiaramente di un compito che dovrebbe essere eseguito dal container scheduler. Kubernetes affronta questo problema; Mesos al riguardo ha alcune funzionalità limitate.
Misurare l’utilizzo delle risorse è un altro aspetto importante: queste informazioni verranno infatti usate per produrre report dell’utilizzo delle risorse, per elaborare le politiche con cui comprendere l’utilizzo delle risorse da parte dei vari dipartimenti e/o utilizzatori (chargeback e showback), nonché per stabilire i costi da imputare nei casi di servizi a pagamento.
Docker ha un buon supporto per le metriche a livello di container, ma diventa necessario aggiungere dei tool in grado di aggregare tali informazioni a livello di cluster.
Monitoraggio
Docker e gli strumenti che funzionano con esso, come Kubernetes e Mesos, sono stati costruiti con la capacità di fornire statistiche a tool di monitoraggio. Tutti questi strumenti possono fornire informazioni molto ricche sullo stato dei nodi host e dei container in essi ospitati. Queste informazioni dovranno essere raccolte e analizzate da tool “a valle” del processo, come Graphite [23] o InfluxDB [24] e Grafana [25], prodotti open source che possono contribuire a gestire la grande mole di dati generati dai cluster Docker e trarne delle informazioni sensate.
Conclusioni
Sia Google [26] che Amazon [27] hanno recentemente esteso i loro servizi cloud affinché supportino i container. In queste release iniziali, i container sono messi in esecuzione su VM, ma ritengo che in tempi brevi vedremo svilupparsi fornitori di servizi cloud in grado di garantire un supporto nativo ai container. Tutto questo accelererà la maturazione di cloud schedulers in quelle aree che fin qui sono state più trascurate, come il networking avanzato e la sicurezza.
I container semplificano significativamente il problema di lunga data costituito dalla portabilità delle Virtual Machine e di interi ambienti tra i vari cloud. Il supporto per i deployment dei container su svariati fornitori di servizi cloud sarà una funzionalità presente in numerosi container scheduler (Mesos già la possiede). Effettuare il deployment su svariati fornitori di servizi cloud finirà ovviamente per far diminuire il lock-in nei confronti di un singolo fornitore, ma potrà oltretutto essere utilizzata come strategia per il recupero da disastri in cui, per qualsivoglia ragione, un cluster dovesse andare distrutto.
Questa portabilità tra i diversi fornitori, inoltre, potrà avere un impatto sui prezzi, poiché in futuro i costi potrebbero diventare uno dei parametri di input per lo scheduler quando dovrà decidere dove andare ad allocare il carico di un determinato lavoro. Attualmente, questo tipo di politica (cloud service broker arbitrage [28]) viene seguita solo da pochissime aziende e comporta dei passaggi manuali, spesso effettuati con l’aiuto di aziende di nicchia. Nel futuro, il cloud service brokerage sarà effettuato dinamicamente dal container scheduler per ciascun lavoro richiesto.
Raffaele Spazzoli ha lavorato per piu di 10 anni a Imola Informatica come consulente con il ruolo di architetto delle applicazioni e delle integrazioni.
Attualmente lavora in KeyBank, una banca statunitense, come architetto dei canali fisici (filiali e contact center) e digitali (web e mobile).