

Introduzione: database non relazionali e Big Data
Il tema dei database non relazionali, i Not only SQL dell’acronimo NoSQL, è quantomai ampio e attuale. La necessità di immagazzinare e ricercare enormi quantità di dati ha messo in luce tutti i limiti del modello relazionale per quanto riguarda la scalabilità sui grossi numeri e ha favorito lo sviluppo e l’affermazione di svariati database non relazionali.
Un aspetto importante dei database che devono trattare i Big Data è che qui non siamo in presenza di soluzioni buone per tutte le situazioni, e quindi è stato necessario sviluppare database NoSQL che funzionano su principi e modelli anche molto diversi tra di loro e non solo rispetto al classico modello relazionale su cui sono stati realizzati per decenni i vari RDBMS: in pratica, problemi e necessità diverse dei vari ambiti di applicazione hanno portato a creare soluzioni specifiche per i vari domini.
I grandi attori dell’attuale scenario Internet sono coloro che hanno saputo inventare o sfruttare al meglio soluzioni di questo tipo: si pensi a Google o a Facebook per primi. In quest’ultimo decennio, quello che era un argomento innovativo e “di rottura” è diventata ordinaria amministrazione. Per chi fosse interessato a leggere un quadro completo sull’argomento, consiglio di riguardarsi gli articoli pubblicati circa cinque anni fa proprio su MokaByte [1] in cui, oltre a una panoramica sul tema, si possono trovare numerosi riferimenti, molti dei quali sempre validi a distanza di anni.
Database relazionali e programmazione orientata agli oggetti
I database relazionali funzionano su questi principi:
- tabelle (tipi);
- colonne (attributi);
- chiavi esterne (vincoli di relazione tra due o più tabelle);
- normalizzazione dei dati (eliminazione della ridondanza delle informazioni e della possibile incoerenza).
Da questo deriva che gli sviluppatori dovranno lavorare con oggetti che non si mappano perfettamente alle tabelle del database. Occorre pertanto uno strato di “traduzione” che semplifichi questa situazione.
Tale necessità di mettere in connessione il paradigma Object Oriented e il modello relazionale ha fatto sì che negli anni si siano dovute sviluppare le soluzioni di mappatura tra OO e RDBMS (Object Relational Mapping, ORM) con tool di persistenza come iBatis o il ben conosciuto Hibernate.
Tipologie di database NoSQL
I database non relazionali possono essere raggruppati in quattro grandi categorie:
- i cosiddetti key/value store, ad esempio Memcached o Redis;
- orientati alle colonne (column-oriented), come Cassandra o HBase;
- orientati ai documenti (document-oriented), ad esempio CouchDB o MongoDB;
- basati sul modello a grafo, come OrientDB e, appunto, Neo4j.
Pur rientrando nell’ambito dei non relazionali, i database a grafo sono abbastanza differenti da quelli delle altre categorie appena riportate. In questi due articoli, daremo quindi un’occhiata a Neo4j [2] un database basato sul modello a grafo e probabilmente il più conosciuto e diffuso della sua “categoria”.
Dal RDBMS al modello a grafo
Quando parliamo di modello a grafo per un database non facciamo altro che riprodurre, a livello alto di astrazione, il modo in cui già pensano gli sviluppatori che adottano paradigmi Object Oriented. Un grafo, infatti non è altro che un insieme di nodi (gli oggetti) e di connessioni (le relazioni).
L’esempio della rete sociale
Uno degli esempi più chiari e concreti che consente di comprendere la filosofia e il funzionamento dei database a grafo è quello relativo ai social network, riportato in varie pubblicazioni tra cui un buon manuale piuttosto recente [3]. Lo riproponiamo qui per spiegare differenze tra database relazionali e a grafo e comprendere le motivazioni che spingono all’adozione di questi ultimi.
Tutti siamo in grado di capire le relazioni sui social media: il concetto di relazione è denominato, in genere, “amicizia” che lega due utenti tra loro.
In un DB relazionale, definiremmo due tabelle:
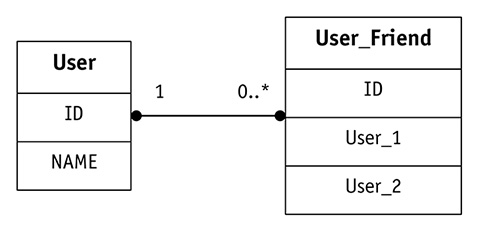
- User, cioè l’utente, e
- User_Friend vale a dire la relazione di amicizia tra due User.
In figura 1 è possibile vedere la relazione fra queste due entità.
Se andassimo a guardare dentro le tabelle, si tratterebbe di qualcosa di simile a quanto illustrato in figura 2.

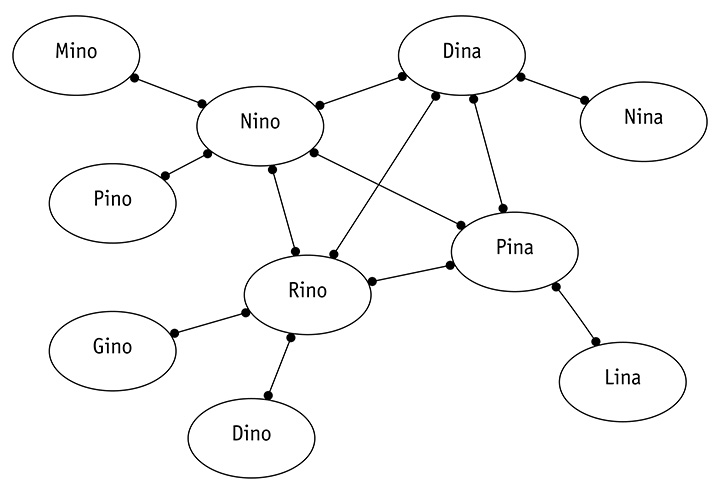
Questi dati indicano che esistono diversi utenti e che fra questi utenti ci sono delle relazioni di amicizia. Se volessimo rappresentare in maniera grafica questi dati, potremmo usare un grafo come quello di figura 3.
Interrogazioni
Bene, ora che abbiamo visto come sono strutturati questi dati, pensiamo a fare alcune interrogazioni. Se, ad esempio, volessimo scoprire il numero degli amici di Dina, nel nostro dominio relazionale potremmo effettuare una query come la seguente:
SELECT COUNT(distinct uf.*) FROM User_Friend uf WHERE uf.user_1 = 2;
Se, facendo un passo in avanti, volessimo scoprire gli amici degli amici di Dina, sarbbe necessaria la query riportata di seguito, un po’ più complicata, ma comunque gestibile.
SELECT COUNT(distinct uf2.*) FROM User_Friend uf1 INNER JOIN User_Friend uf2 on uf1.user_1 = uf2.user_2 WHERE uf1.user_id = 2
E se volessimo cercare gli amici degli amici degli amici di un utente? Basta scrivere una query leggermente più articolata.
SELECT COUNT(distinct uf3.*) FROM User_Friend uf1 INNER JOIN User_Friend uf2 on uf1.user_1 = uf2.user_2 INNER JOIN User_Friend uf3 on uf2.user_1 = uf3.user_2 WHERE uf1.user_id = 2
Bene: si può fare. Nulla di trascendentale. Venti anni fa ci si sarebbe anche interrogati sul perché sia necessario fare ricerche di questo tipo, ma oggi sappiamo che, in un mondo “social”, questo tipo di strutture consente, ad esempio, di creare un sistema di suggerimenti riguardo a “prodotti” (libri, musica, film, etc.) che sono piaciuti agli amici presenti nella propria rete sociale: il vecchio “passaparola”, riveduto e corretto in termini social e di Big Data.
“Big Data killed the SQL stars”
Il linguaggio SQL e i database relazionali risultano non troppo complicati, offrono garanzie sulla coerenza dei dati e sono diffusi e conosciuti a molti livelli. Allora perché bisognerebbe abbandonare questo paradigma a favore di un modello a grafo? La risposta la sapete già e, se non la sapete, la trovate nel libro citato [3] o la leggete di seguito…
Prendete l’esempio che abbiamo appena visto, e realizzatelo con 1000 utenti e 50 relazioni per ciascun utente (che non sono neanche tante…). Otterrete 50000 (leggasi cinquantamila) record User_Friend. Scrivere e archiviare questi rercord non è un problema: i database relazionali lo fanno perfettamente e sono stati inventati proprio per unire i dati.
Il problema arriva quando si iniziano a fare le ricerche. Entrano infatti in gioco alcuni elementi importati, quali la profondità e la velocità di elaborazione. La profondità della ricerca è il numero di nodi che bisogna attraversare per effettuare la query. Cercare l’amico dell’utente equivale a profondità 1, cercare l’amico dell’amico dell’utente rappresenta profondità 2 e così via. E qui bastano dei dati empirici per cominciare a capire come stanno le cose.
Prendendo come macchina per l’elaborazione un computer laptop con processore Intel i7 e 8GB di RAM, i risultati sono più o meno questi: con profondità di ricerca 2, occorrono circa 0,03 secondi (tre centesimi…) per completare lo “spoglio” dei record; con profondità di ricerca 3, il tempo sale a 0,2 secondi (venti centesimi…) con un aumento quasi imperecettibile, almeno a livello di sensazione per un utente umano. Quindi tutto bene? No. Perché se la profondità diventa 4, il tempo necessario all’elaborazone sale a 10 secondi per superare addirittura il minuto e mezzo quando si tratti di effettuare query a profondità 5…
Attraversamento del grafo
Se quindi il database relazionale si presta bene a gestire ricerche con profondità limitate (diciamo fino a 3), esso diviene assolutamente inadeguato quando si tratti di fare ricerche tra le relazioni che abbiano una profondità superiore: è una questione di prestazioni dovuta al tipo di computo che è necessario.
Con il modello a grafo, quello che accade è invece una sorta di “esplorazione geografica”: si individua un luogo e si percorrono le strade che partono da lì per andare a vedere a cosa sono collegate e dove portano. Tornando a un livello appena meno astratto, si individua un nodo di partenza e si effettua la cosiddetta graph traversal, vale a dire l’interrogazione attraverso le relazioni.
Torniamo al grafo di figura 3: ogni relazione (il connettore nella figura) sarà denominata IS_FRIEND_OF per poterla usare con la API Traversal [4] di Neo4j. A questo punto, ecco cosa occorre fare per ottenere gil stessi risultati per cui avevamo utilizzato le query SQL:
TraversalDescription traversalDescription = TraversalDescription() .relationships( “IS_FRIEND_OF”, Direction.OUTGOING ) .evaluator( Evaluators.atDepth( 2 ) ) .uniqueness(Uniqueness.NODE_GLOBAL ); Interable nodes = traversalDescription.traverse(nodeById).nodes();
La sintassi non è difficile, almeno nelle sue linee essenziali: essa significa che si parte dal nodo scelto, si compie l’attraversamento attraverso tutte le relazioni di tipo IS_FRIEND_OF verso ciascun altro nodo collegato, e questo attraversamento deve arrivare a una profondità di 2. Oltre a questo, si specifica che i risultati debbano essere unici, ossia che non devono esserci duplicati riguardo al grafo in esame.
Risultati e tempi di elaborazione
Con questo nuovo tipo di database, otteniamo risultati pari a 0,04 secondi per ricerche su profondità 2 e di 0,06 secondi su profondità 3, che sono sovrapponibili a quelli ottenuti con le query SQL. La differenza si nota laddove si passi a profondità di 4 o 5, quando i tempi si attestano sugli 0,07 secondi, paragonabili a quelli ottenuti per gli altri attraversamenti e, soprattutto, nettamente inferiori ai “tempi biblici” necessari per queste query con il database relazionale.
Portando alle estreme conseguenze questi “esperimenti”, si può prendere una tabella con 1 mlione di utenti, ciascuno sempre con 50 relazioni, il che porta il conto totale dei record a 50 mlioni di righe User_Friend… Con questi dati, e senza esagerare nella profondità delle ricerche, che stabiliremo solo a 4, la ricerca SQL necessiterebbe di 25 minuti abbondanti, mentre la ricerca con Neo4j restituirebbe i risultati in 1,5 secondi scarsi… e se la portassimo a profondità 5, si concluderebbe comunque entro i due secondi e mezzo!
Con le query SQL, i tempi di esecuzione dipendono dalla dimensione del prodotto cartesiano dei risultati possibili che devono essere analizzati. Con i database a grafo, i tempi di esecuzione dell’attraversamento del grafo sono direttamente proporzionali alla dimensione dell’insieme dei risultati effettivi.
Neo4j: definire i dati
Cominciamo a dare un quadro introduttivo di Neo4j, ricordando però con onestà che i database a grafo non sono la soluzione per tutte le situazioni. Ci sono però ambiti in cui il modello a grafo rappresenta sicuramente la scelta migliore: oltre alla modellazione delle relazioni su una rete sociale, si potrebbe pensare a una lista di controllo degli accessi e, in definitiva, a tutti quei casi in cui il modello di dominio possa essere descritto in termini di nodi e relazioni, e in cui le proprie ricerche debbano fondamentalmente attraversare le relazioni.
Definizione di nodi e relazioni
Ma in quale modo vengono definiti nodi e relazioni per organizzare i dati in Neo4j?
I nodi definiscono le entità nel nostro modello, e rappresentano cose del tipo utenti, indirizzi, libri, film, gruppi, permessi, ruoli. In Neo4j, ogni nodo contiene una raccolta di chiavi e valori che ospitano i nostri dati, ad esempio una chiave “name” e un valore “Dina”. I nodi possono anche avere una o più etichette.
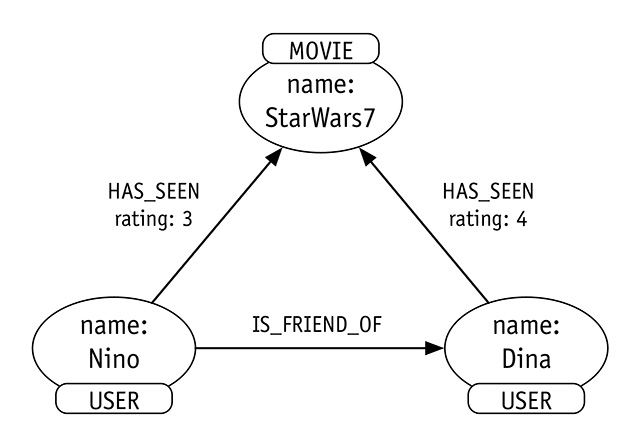
Le relazioni definiscono le connessioni fra i nodi, hanno una direzione e un nome. Inoltre, tali relazioni possono essere associate a dati chiave/valore. Per capirci meglio, vediamo un semplice esempio (figura 4). Ci sono due nodi USER e un nodo MOVIE: la relazione tra l’utente e il film, che definisce il fatto che l’utente ha visto il film, si chiama HAS_SEEN. A questa relazione possiamo aggiungere una chiave rating che indica la valutazione sul gradimento del film, la quale può prendere un valore da 1 a 5.
Direzione delle relazioni
Nel nostro esempio abbiamo due nodi utenti, Nino e Dina, entrambi con etichetta USER, e un nodo film StarWars7 con l’etichetta MOVIE. Nino definisce una relazione IS_FRIEND_OF con Dina: va notato che la relazione ha una direzione, che va da Nino verso Dina, perché in Neo4j tutte le relazioni hanno una direzione. Sia chiaro che è possibile creare un’altra relazione direzionata da Dina verso Nino e, inoltre, che la direzione di una relazione non impedisce la possibilità di attraversarla in senso contrario. Per capirsi, la relazione IS_FRIEND_OF parte da Nino e va verso Dina ma è comunque possibile partire dal nodo Dina e trovare tutte le relazioni IS_FRIEND_OF sia verso che da Dina.
Entrambi i nostri utenti hanno visto il film StarWars7 (relazione HAS_SEEN): Nino lo ha valutato con 3 stelle, mentre Dina ha dato rating: 4.
Neo4j: ricercare i dati
Una volta definiti i dati in termini di nodi e relazioni, arriva il momento di effettuare le ricerche su di essi. In Neo4j esistono diverse strategie per poterlo fare: le API Core Java e Traversal e le query con Cypher. Vediamole brevemente di seguito.
API Core Java
L’API Core Java a basso livello consente di attraversare le relazioni grazie alla programmazione “manuale”. Con questa API, un programma Java potrebbe partire da un nodo, percorrere tutte le sue relazioni, esaminarne il tipo e poi recuperare i nodi all’altro capo di tali relazioni. Si tratta di una modalità molto adatta alla mentalità dei programmatori Java, al loro modo di interpretare i nodi e le relazioni. Il problema sta nel fatto che è richiesto di implementare ciascun passaggio dell’attraveramento dei nodi e ciò porta a dover scrivere metodi di ricerca piuttosto corposi.
API Traversal
Traversal è una API programmatica a livello più alto, che i programmatori Java possono impiegare per la ricerca sui dati. Facendo riferimento all’esempio di ricerca di cui parlavamo sopra, con la API Traversal, la si scriverebbe così:
TraversalDescription traversalDescription = TraversalDescription() .relationships(“IS_FRIEND_OF”, Direction.OUTGOING) .evaluator(Evaluators.atDepth(2)) .uniqueness(Uniqueness.NODE_GLOBAL); Iterable nodes = traversalDescription.traverse(nodeById).nodes();
Il programma definisce un oggetto TraversalDescription che dice a Neo4j il modo in cui costruire il suo insieme di risultati e poi gli passa il nodo da cui partire e gli richiede un’interfaccia iterable che legga i suoi nodi.
Query con Cypher
La terza possibilità per ricercare dati con Neo4j è l’uso di un linguaggio di query che si chiama Cypher e che, nella sua incarnazione openCypher [5], si propone come query language standard per tutti i database a grafo.
Cypher consente di specificare criteri di corrispondenza per i nodi da cui si parte, le regole per l’attraversamento del grafo, e quali dati devono essere estratti nel percorso. Facendo riferimento all’esempio di figura 4, immaginiamo di voler ricercare tutti i file (movie) che un utente (user) ha visto (HAS_SEEN):
start user=node(1) match (user)-[:HAS_SEEN]->(movie) return movie;
Si parte con il nodo identificato da 1 e poi si effettuano gli attraversamenti “passando” lungo tutte le sue relazioni HAS_SEEN. La sintassi richiede che le relazioni siano inserite tra parentesi quadre ([ ]) e siano precedute dal segno dei “due punti” (:); e prima di questo segno “:” è possibile anche mettere un identificatore in maniera che sia possibile fare riferimenti a questa relazione successivamente nella query. Va notato anche il segno di “freccia” (->) che indica la direzione della relazione, la quale parte da user e va verso movie. Questa freccia può essere “ribaltata” (<-) per ottenere una ricerca sulle relazioni in entrata:
(user)<-[:IS_FRIEND_OF]-(friend)
oppure si potrebbero ricercare le relazioni sia in entrata che in uscita, semplicemente omettendo la punta della freccia (–):
(user)-[:IS_FRIEND_OF]-(friend)
Al nodo risultante viene dato un nome nella query Cypher, che in questo caso è movie, in maniera che ad esso si possa fare riferimento più avanti. Otteniamo quindi la possibilità di aggiungere questo nodo all’insieme dei risultati, che contiene la raccolta dei film che l’utente ha visto.
Conclusione
Abbiamo passato brevemente in rassegna le ragioni per cui si sono affermati i database a grafo, parlando delle ottime prestazioni che essi hanno nelle ricerche a profondità più elevata rispetto ai database relazionali.
Chiaramente questo tipo di database non è adatto a ogni soluzione implementativa, ma si presta bene a quei domini in cui le entità e le relazioni tra esse possano essere bene espresse in termini di nodi e connessioni.
Abbiamo poi dato uno sguardo alle caratteristiche basilari di Neo4j, basato su nodi e relazioni, passando velocemente in rassegna anche le diverse opzioni possibili per effettuare le query.
Nel prossimo articolo parleremo degli indici, che servono a trovare il nodo di partenza, continueremo ad approfondire le ricerche con Cypher e, cosa che più ci interessa, esamineremo alcune strategie di deployment in produzione.
Luigi Mandarino ha cominciato ad appassionarsi ai computer con il glorioso ZX Spectrum 48k: una bomba, per l‘epoca 🙂 Dopo gli studi di ingegneria, si è dedicato per diversi anni allo sviluppo di applicazioni Java, specie per la piattaforma Enterprise. Successivamente, ha svolto il ruolo di architetto dei sistemi interessandosi particolarmente alle architetture di integrazione. Attualmente, svolge consulenze a svariate aziende in particolare nel settore bancario, assicurativo e finanziario, principalmente su temi inerenti le architetture Java EE e le dinamiche di processo secondo un approccio Lean/Agile.