

Introduzione
Nello scorso articolo siamo partiti dal tema dei Big Data e abbiamo visto brevemente le motivazioni per l’affermazione dei database NoSQL, ampia categoria in cui si fanno rientrare tutti quei DBMS che non sono relazionali. Tra le varie tipologie di DB non relazionali, quelli “a grafo” hanno delle particolari caratterische, che abbiamo presentato, constatando come Neo4J [1] rappresenti ad oggi il database a grafo più conosciuto e diffuso.
Come dicevamo, il paradigma “a grafo” non è una tipologia di database buona per tutte le stagioni, anzi. Ma, per certi particolari domini, rappresenta senza dubbio la soluzione migliore. Dopo aver visto il modo in cui i dati sono rappresentati internamente a Neo4j (nodi e relazioni) e i meccanismi di ricerca all’interno del database (le API Core Java e Traversal, nonché il linguaggio di query Cypher), continuiamo in questo articolo analizzando gli indici e indicando qualche breve cenno sull’utilizzo di questo database nei deploy in produzione, quindi in un’ottica di tipo DevOps.
Indici
Quello di indice (index) dovrebbe essere un concetto chiaro a chiunque abbia avuto a che fare in maniera poco più che superficiale con i database relazionali. Ogni colonna indicizzata, come la chiave primaria, viene mantenuta in un costrutto di ricerca separata — l’indice, appunto — ogni volta che dei dati vengono inseriti, aggiornati o cancellati da una tabella.
Con una query del tipo
SELECT * FROM utente WHERE età >= 21
fatta su una colonna indicizzata (età) il vantaggio dell’indice è che consente al database di trovare velocemente tutte le righe corrispondenti. Lo svantaggio sta nel fatto che, ad ogni cambiamento nei dati per inserimento, aggiornamento o cancellazione, anche l’indice deve essere aggiornato, e questo vale per ciascuna colonna indicizzata.
Gli indici in Neo4j
Neo4j fa uso degli indici per consentirci di trovare i nodi di partenza, quelli che servono a Traversal o con le query Cypher per cominciare il loro “attraversamento” a partire da un nodo, e poi definire le regole per i risultati corrispondenti.
Diventa pertanto importante definire una strategia veloce di ricerca per le proprietà dei nodi che vengono in genere ricercate, in maniera da poter definire il nodo (o i nodi) di partenza senza dover prima esaminare tutti gli oggetti presenti nel nostro database a grafo.
In Neo4j sono disponibili tre “meccanismi” per poter indicizzare i dati:
- gestione manuale degli index
- schema indexing
- autoindicizzazione
Gestione manuale dell’indicizzazione
Neo4j si appoggia ad Apache Lucene [2] come suo “motore di ricerca” ed espone dei metodiche possono essere utilizzati per una gestione manuale degli indici, i quali sono definiti per nome in modo tale che lo sviluppatore possa associare i dati indicizzati con un indice dal nome sensato.
Per esempio, l’indice per gli utenti potrebbe essere denominato users e a quel punto sarebbe possibile un accesso tramite programmazione a partire dall’IndexManager del database a grafo.
IndexManager indexManager = graphDB.index(); Index userIndex = indexManager.forNodes( “users” );
Una volta ottenuto questo Index, lo sviluppatore non farà altro che creare un nodo, aggiungendo un record index per quel nodo:
Node person = graphDB.createNode(); person.setProperty(“nome”, “Pino”); person.setProperty(“email”, “pino@mokabyte.it”); userIndex.add(person, “email”, “pino@mokabyte.it”);
Abbiamo creato un nodo person, impostato il suo nome e la sua email, e poi abbiamo aggiunto un index per quel nodo person sul suo indirizzo email. Ora che l’indice è stato creato, trovare un nodo è molto più veloce che scansionare l’intero grafo dei dati:
IndexHits indexHits = userIndex.get(“email”, “pino@mokabyte.it”); Node user = indexHits.getSingle();
Qui richiediamo che userIndex trovi tutti i nodi la cui email corrisponde a “pino@mokabyte.it”: otteniamo così un’istanza di IndexHits attraverso la quale possiamo accedere a tutti i nodi che possiedono quell’indirizzo email specificato. In questo esempio, sappiamo già che ci ritroveremo con un risultato singolo e quindi possiamo invocare il metodo getSingle() per recuperare il nodo utente.
Dove sta il difficile con la gestione manuale degli indici? Nel fatto che lo sviluppatore ha la totale responsabilità di creare il record dell’indice, aggiornare l’indice — per esempio quando cambia l’indirizzo email dell’utente — e cancellare l’indice nel caso in cui sia necessario farlo. E questo comporta un grosso livello di responsabilità, e si capisce facilmente che questo approccio, pur avendo alcune potenzialità, non rappresenta la scelta preferibile.
Indicizzazione automatica
Se invece ci affidiamo all’indicizzazione automatica, possiamo scegliere fra i due approcci che Neo4j ci mette a disposizione, vale a dire:
- Schema Indexing
- Auto Indexing
Indicizzazione a schema
Lo schema indexing si appoggia al concetto di etichetta dei nodi e consente di creare automaticamente un indice per l’etichetta di un nodo e un insieme di proprietà. Per esempio, in presenza dell’etichetta USER, sarà possibile indicare al database di creare un indice a schema su tutti i nodi che hanno l’etichetta USER sulla proprietà email. In questa situazione, Neo4j si occuperà “autonomamente” dell’indice, in maniera simile a quanto avviene nei database relazionali.
Quindi, quando si aggiunge un nuovo nodo con l’etichetta USER, sarà aggiunto un nuovo index record per la proprietà email di questo nodo: se si aggiorna l’indirizzo email, conseguentemente Neo4j aggiornerà l’indice e, infine, se si cancella il nodo, sarà autonomamente Neo4j a farsi carico di cancellare il record dell’indice.
Autoindicizzazione “pura”
Tra gli approcci di indicizzazione automatica, Neo4j prevede anche il cosiddetto auto indexing, in grado di creare automaticamente degli indici per nodi e/o per relazioni, e per proprietà specifiche.
Per esempio, è possibile indicare a Neo4j di creare automaticamente un indice per i nodi con una proprietà nome. Il problema con questo approccio è che, al momento, non esiste un modo per specificare lo schema o l’etichetta di nodo su cui creare automaticamente l’indice. Quindi succede che l’indicizzazione automatica finirà per mischiare insieme nodi con qualsiasi label.
Facciamo un esempio per capirci meglio: mettiamo di avere dei nodi con l’etichetta MOVIE e altri la cui label è USER. Entrambi questi gruppi di nodi contengono una proprietà nome. Con questo quadro, succederà che l’autoindicizzazione competamente autonoma di Neo4j mischierà insieme i film (MOVIE) e gli utenti (USER) basandosi sulla proprietà nome. E questo comporta che se — da appassionato di boxe o fan di Sylvester Stallone — qualcuno ha chiamato il proprio bambino “Rocky”, il database restituirà come risultato della ricerca sia l’utente bambino con il nome da pugile (label: USER, proprietà nome: Rocky) che il film del 1976 con Stallone (label: MOVIE, proprietà nome: Rocky).
Strategie di indicizzazione
Adesso che abbiamo visto rapidamente quali sono le possibilità per l’indicizzazione offerte da Neo4j, cerchiamo di valutarne vantaggi e svantaggi. Chiaramente, l’indicizzazione consente una ricerca più veloce per le proprietà indicizzate. Ma occorre anche comprendere che questo ha un costo in termini computazionali tutte le volte che occorra “gestire” l’indicizzazione: ogni volta che si esegue l’inserimento, l’aggiornamento o la cancellazione di un nodo o di una relazione dotati di una qualche proprietà indicizzata, deve essere necessariamente modificato anche l’indice.
Pertanto l’approccio all’indicizzazione (manuale, a schema, automatica demandata al database) e la scelta di quali proprietà indicizzare risultano molto importanti e vanno valutate bene per ottenere una adeguata strategia di indicizzazione.
In questi casi, la scelta migliore è quella di guardare anzitutto ai criteri di ricerca che si useranno maggiormente nell’uso del database: questo ci consentirà di individuare le proprietà più adatte a essere indicizzate. Come consiglio generale, almeno in questo caso, il canonico “giusto mezzo” sembra essere la scelta migliore: lo schema indexing, infatti, rappresenta il giusto compromesso tra flessibilità nella scelta delle proprietà da indicizzare — cosa che l’auto indexing non consente — e quantità di lavoro da effettuare, che è minore — e meno prono ad errori — rispetto alla gestione totalmente programmatica della indicizzazione effettuata in maniera manuale.
Neo4j in azione
Abbiamo fin qui tratteggiato le caratteristiche principali di Neo4j, descrivendo la struttura a grafo fatta di nodi e relazioni, e i benefici che tale modello è in grado di offrire per le ricerche in grandi quantità di dati con legami di relazione. Abbiamo poi visto nei paragrafi sopra le varie strategie di indicizzazione presenti in Neo4j.
Ma cosa possiamo dire riguardo al suo uso in un contesto reale di produzione?
Vediamo anzitutto in figura 1 l’architettura ad alto livello di Neo4j [3].
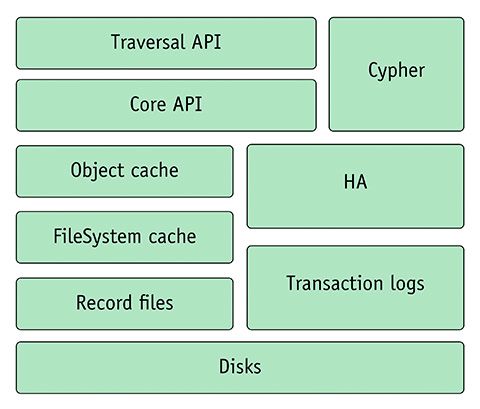
Le informazioni che ricaviamo da questo schema ci consentiranno di ipotizzare una configurazione di produzione per il nostro prodotto.
Memorizzazione dei dati
Anzitutto, alla base dell’architettura c’è la piattaforma “fisica” su cui Neo4j è in esecuzione, vale a dire il disco (o i dischi): per quanto si cerchi di mantenere tutto il possibile in memoria, per consentire una lettura e una scrittura più rapida dei dati, alla fine il “substrato” fisico è necessario, e quindi più i dischi sono veloci (nel senso di rapidità in I/O), migliore è il risultato; in tal senso, i dischi a stato solido che ormai si stanno sempre più diffondendo rappresentano la soluzione preferibile.
Nel libro Neo4j in action [3] vengono anche indicate dettagliatamente le “pezzature” di memorizzazione da allocare in base alle diverse situazioni.
Cache: filesystem
Neo4j dispone di un sistema di cache allo scopo di ridurre la latenza. Tale cache si esplica su due livelli: filesystem e object (figura 1).
La cache di filesystem è un’area di memoria libera, o di RAM del sistema operativo che però non è stata allocata ad alcun processo; ad essa si accede attraverso input/output mappati in memoria (memory-mapped I/O). Quando un processo richiede un file, o una sua parte, questo viene caricato in memoria nella cache del filesystem. In questo modo le letture successive saranno effettuate a partire dalla cache del filesystem e non direttamente dal disco, con un’evidente velocizzazione delle operazioni; analogamente, anche le scritture sono effettuate verso la memoria e poi passate dalla cache al disco.
Tutto questo, in Neo4j, è basato su Java NIO (Java Native i/O) che si occupa di “consigliare” al meglio il sistema operativo affinché carichi, legga e scriva i dati da e verso il disco fisico nella maniera più efficiente.
La cache di filesystem si configura andando a editare il file conf/neo4j.properties e impostando le seguenti proprietà:
neostore.nodestore.db.mapped_memory=22M neostore.propertystore.db.mapped_memory=66M neostore.propertystore.db.string.mapped_memory=1.4G neostore.propertystore.db.arrays.mapped_memory=0M neostore.relationshipstore.db.mapped_memory=1.0G
In particolare, nodestore ospita tutti i nodi; i propertystore ospitano le proprietà che sono state definite sui nodi e sulle relazioni, con la differenziazione che le primitive e le stringhe inline sono definitite nella prima proprietà, le stringhe nella seconda e gli array nella terza propertystore. Infine, relationshipstore ospita tutte le relazioni. In ogni caso, per approfondire questo (e tutti gli altri argomenti) si rimanda sempre al già citato Neo4j in Action [3].
Cache: object
L’altro livello di cache è quello object: in definitiva, nodi e relazioni sono oggetti Java in memoria, visto che Neo4j funziona in una JVM. In tal senso, Neo4j prevede due impostazioni di configurazione per la memoria: la configurazione dello heap della JVM tramite –Xmx??m e la scelta del tipo di cache.
Diremo molto brevemente che la configurazione dello heap permette di impostare la misura iniziale e massima dello heap, la dimensione del “survivor space” della JVM e la strategia di garbage collection per trovare l’equilibrio migliore tra frequenza e durata delle “raccolte di spazzatura”. Uno heap di maggiori dimensioni consente di mantenere più dati in memoria cache ma comporta anche una maggiore durata della garbage collection.
L’altra scelta che si può fare è quella del tipo di cache, scegliendo fra none, soft (predefinita), weak, strong e HPC.
- None (“nessuna”) rappresenta il caso in cui non c’è una cache di alto livello e nessun oggetto sarà pertanto mantenuto nella cache.
- Soft (“morbida”) è l’impostazione di default e prevede che ci sia un’ottimizzazione della memoria disponibile; in pratica, garantisce ottime prestazioni per le operazioni di “attraversamento” dei nodi, ma potrebbe dare problemi di sovraccarico e causare frequenti operazioni di garbage collection quando le parti del grafo usate spesso sono parecchio grosse e non entrano in memoria.
- Weak (“debole”) è l’impostazione che dà un ciclo di vita breve agli oggetti nella cache e quindi risulta molto adatta alle applicazioni con un notevole throughput, in cui può essere immagazzinata in memoria un’ampia porzione del grafo usato frequentemente.
- Strong (“forte”) imposta una strategia per cui tutti i dati sono caricati in memoria e lì restano, senza essere rilasciati; chiaramente funziona bene solo in presenza di piccoli insiemi di dati.
- HPC (High Performance Cache): è una strategia presente solo nella versione enterprise di Neo4j e non nella community edition. la cache ad “alte prestazioni” consente di dedicare una specifica porzione di memoria per tenere in cache i nodi e le relazioni caricati.
Rimandando gli approfondimenti alla documentazione del database [4] e al libro citato, si può però comprendere già da questi brevi accenni come sia possibile individuare una strategia di caching adeguata alle esigenze della propria applicazione, scegliendo di mantenere precaricate tutte le parti del grafo che saranno utilizzate più di frequente e tenendone in considerazione le dimensioni in relazione alle risorse di memoria disponibili.
Transazioni: integrità e log
Un aspetto da non sottovalutare in Neo4j è quello relativo al supporto ACID per le sue operazioni, proprio come avviene nei database relazionali. ACID è l’acronimo di Atomic, Consistent, Isolated, Durable (“atomico, coerente, isolato, durevole”) e sta a indicare le caratteristiche che ogni transazione deve avere, in maniera tale che i dati rimangano consistent e non perdano coerenza. È prevista, in tal senso, una funzionalità di commit/rollback sulla base del fatto che la transazione sia andata o meno a buon fine.
Le transazioni ACID vengono supportate grazie all’impementazione di un log delle transazioni di tipo write–ahead (WAL): i cambiamenti nella transazione attiva vengono registrati su un file di logging, e vengono inviati fisicamente al disco prima di essere applicati ai file sottostanti. Con il WAL, Neo4j è in grado di mantenere transazioni ACID e questo log nioneo_logical.log.* si trova nella directory del database a grafo.
Conclusioni
Neo4j non è l’unico database a grafo esistente, ma è il più popolare per una serie di buone ragioni, non ultima quella che la community edition è disponibile gratuitamente. La versione enterprise presenta svariate funzionalità in più [5] tra cui anche il modulo per l’alta disponibilità (HA) in grado di supportare il clustering e lo sharding dei dati. Con applicazioni più complesse e per esigenze particolari, potrebbe essere il caso di valutare i costi per l’adozione della enterprise edition, ma per tanti altri scenari più semplici, la versione gratuita è più che sufficiente.
I benefici dell’uso di un database a grafo in particolari domini sono tali da farlo preferire ai classici database relazionali, perché la prestazione di Neo4j in un’operazione di “attraversamento” del grafo è decisamente superiore a quanto si otterrebbe con una classica JOIN SQL. Queste considerazioni, e molte altre funzionalità del prodotto, nonché la sua grande diffusione fanno di Neo4j uno strumento che vale la pena di provare e su cui è possibile costruire applicazioni robuste e performanti.
Luigi Mandarino ha cominciato ad appassionarsi ai computer con il glorioso ZX Spectrum 48k: una bomba, per l‘epoca 🙂 Dopo gli studi di ingegneria, si è dedicato per diversi anni allo sviluppo di applicazioni Java, specie per la piattaforma Enterprise. Successivamente, ha svolto il ruolo di architetto dei sistemi interessandosi particolarmente alle architetture di integrazione. Attualmente, svolge consulenze a svariate aziende in particolare nel settore bancario, assicurativo e finanziario, principalmente su temi inerenti le architetture Java EE e le dinamiche di processo secondo un approccio Lean/Agile.