

Introduzione
In questo articolo racconteremo un caso reale che ha interessato KeyBank, una banca di dimensione regionale media, e che ha comportato, come uno degli esiti, il passaggio da un rilascio in produzione del software su base trimestrale a un deployment con cadenza settimanale. Ciò che è riportato qui è l’adattamento di quanto già scritto dall’autore sul blog di RedHat [1], in un post pubblicato recentemente.
Il processo ha visto l’utilizzo completo di software open source con una migrazione da WebSphere [2] a Tomcat [3] e con l’adozione della piattaforma per applicazioni cloud OpenShift [4] come nostro container Linux privato.
Il contesto
Il lavoro è stato condotto per modernizzare il canale digitale della banca, e si è trattato del progetto tecnologico più importante nel periodo in cui è stato svolto. In pratica, occorreva effettuare la migrazione di una applicazione web Java — vecchia di 15 anni, basata su servlet, sviluppata su un framework MVC “fatto in casa”, e funzionante con Java 1.6 e WebSphere 7.x — verso un’esperienza Web più moderna, compresa la creazione di una nuova app mobile.
I costi dell’invecchiamento tecnologico
L’applicazione da cui siamo partiti era diventata molto costosa da mantenere; oltre a ciò il suo livello di disponibilità tendeva lentamente a declinare al punto che diventava difficile mantenere i livelli di servizio previsti. Si trattava della classica applicazione monolitica e il nostro obiettivo architetturale consisteva nel creare uno strato di API in grado di separare la logica di presentazione (Web o mobile) dalla logica applicativa.
Tempi di rilascio
Il calendario per il rilascio era impostato su base trimestrale: il processo di deployment delle nuove versioni di software in produzione era costoso e faticoso. Si trattava di un processo di rilascio complicato basato su un foglio di calcolo Excel e che comportava una settantina di passaggi manuali: veniva svolto durante il finesettimana nella speranza che il sistema fosse di nuovo perfettamente on-line e operativo per la mattina del lunedì. Non è difficile capire anche il tipo di sensazioni che tutto questo ci causava: non ci faceva sentire tranquilli e non ci rendeva certo orgogliosi come architetti/sviluppatori.
La lezione dei “big”
Ma in che modo si comportano i grossi calibri del panorama tecnologico internazionale (Google, Amazon, Facebook etc.) per gestire il loro ciclo di rilascio? Durante una conferenza a cui prendevo parte mi colpì particolarmente una presentazione in cui veniva illustrato l’approccio di Netflix: era chiaro che questo tipo di organizzazioni erano due o tre ordini di grandezza più avanti di noi su tutte le metriche relative al rilascio, vale a dire frequenza, costi, rapporto tra codice completato e codice in produzione così via.
La giusta velocità
Da quel momento, maturò in me la decisione di “sfidare” la nostra organizzazione di delivery, affinché passasse da rilasci ogni tre mesi a rilasci ogni settimana: lì per lì questa sfida non fu presa troppo sul serio, ma quell’obiettivo si era ormai fissato nella mia mente.
Oltretutto ritenevo che rilasci settimanali rappresentassero una velocità ragionevole per il canale digitale di una banca, senza dover raggiungere la velocità estrema del ciclo di rilascio tipica delle start-up della Silicon Valley, ma al contempo sufficientemente veloce da non lasciare spazio per riunioni, testo manuali, passaggi manuali per il rilascio. In altre parole, un ciclo abbastanza veloce da favorire il cambiamento.
Architettura e tecnologia
Il mio ruolo nel progetto era quello di architetto della soluzione e il mio primo passo fu di spingere in direzione di una nuova architettura con uno strato di servizi REST completamente stateless e due front-end: un’applicazione web basata su AngularJS [5] e un’app mobile basata su framework Iconic [6] che riutilizzasse in gran parte lo stesso codice dell’applicazione web.
JDK7
In questa fase l’idea era comunque quella di far girare questa nuova applicazione su WebSphere, e quindi cominciai a chiedere al nostro team Ops di approntare una serie di cambiamenti. Anzitutto occorreva aggiornare il JDK passando dalla versione 6 alla 7, perché ci voleva un JDK più recente che fosse in grado di scrivere servizi REST appoggiandosi su JAX-RS. Sulle prime, dal reparto Ops fu risposto che la cosa non era possibile; poi quando il team si rese conto che il JDK in uso era prossimo alla fine del suo ciclo di vita, cominciò a lavorare per far funzionare il nuovo JDK: il processo durò circa sei mesi.
Application server
Un’ulteriore richiesta da parte mia fu di utilizzare Liberty [7] come application server. WebSphere aveva tempi di avvio molto lenti sui laptop degli sviluppatori, che oscillavano tra i 5 e i 10 minuti: ci serviva sicuramente qualcosa di più agile e veloce vista la grande impresa che ci accingevamo ad affrontare. La risposta che ci fu data fu più o meno questa: “Usate pure Liberty sui vostri computer di sviluppo, ma l’unico application server supportato in produzione continuerà a essere WebSphere”.
Di fatto, fu quello che facemmo seppur con una sensazione di “ insicurezza”, poiché sapevamo bene a livello intuitivo quanto fosse importante una uniformità tra sviluppo e produzione al fine di andare più veloce. In mancanza di tale uniformità infatti, quando si cambino elementi fondamentali dello stack tecnologico, negli ambienti al livello più elevato (IT, QA, produzione) saltano sempre fuori troppi bug.
Cache distribuita
Alle precedenti, si aggiungeva la richiesta di un tool di cache distribuita. Questo strumento serviva poiché il nostro service layer doveva essere completamente stateless e sessionless, e quindi occorreva una cache per ragioni di efficienza.
La risposta fu che non c’era a disposizione alcuna piattaforma di cache distribuita che fosse ufficialmente supportata, anche se, magari, un giorno… ce ne sarebbe stata qualcuna.
Un cambiamento di prospettiva
Questi episodi, gli altri che non perdo tempo a raccontare, mi fecero pensare che, evidentemente, ci stavamo muovendo nel modo sbagliato. Da un lato, il team Dev non era in grado di esprimere le proprie necessità nel modo più opportuno; dall’altro, il team Ops era probabilmente troppo preoccupato di continuare a far funzionare le cose e tendeva pertanto al mantenimento dello status quo. Nel mezzo c’ero io che, come solution architect, probabilmente non ero in grado di moderare la conversazione e di spingerla in una direzione produttiva.
Mi rendevo conto che era necessario modificare completamente questo modello e sbarazzarsi del labirinto di richieste di servizio che veniva usato dal team di delivery per richiedere al team di operations che l’infrastruttura fosse messa in funzione. Addirittura a un certo punto un altro team che doveva mettere in piedi un’infrastruttura completamente nuova fece uno studio dal quale emergeva che avrebbero dovuto riempire 400 richieste per poter portare a termine il compito!
Mi convinsi che il team di delivery avrebbe dovuto avere la possibilità di costruirsi la propria infrastruttura e ne serviva una in particolare: un cloud privato. Per quello cominciai a fare delle ricerche per capire quale fosse il miglior strumento a disposizione. Proprio nello stesso periodo, un piccolo team di operations aveva appena risolto una serie di seri problemi di rete che si protraevano da tempo ed era stato coinvolto nel nuovo compito di costruire un cloud privato in KeyBank.
Verso il private cloud
In breve, unimmo le forze e, sulla base delle nostre ricerche, decidemmo che Kubernetes [8] era la miglior piattaforma disponibile per il cloud privato basato su container. Non ci sembrava il caso di affidarci a una piattaforma cloud basata su macchine virtuali, perché ci rendevamo conto che i container erano tecnologicamente migliori delle VM.
Nella nostra riceca di supporto professionale per Kubernetes ci rendemmo conto che Red Hat e la sua piattaforma OpenShift rappresentavano una proposta molto credibile. Gli eventi che seguirono questo incontro si svolsero a velocità piuttosto sostenuta: dopo esserci impegnati con Red Hat. in 4 mesi eravamo già in production preview, e in produzione col la prima mandata di clienti in 7 mesi.
Stack tecnologico
A questo punto, l’applicazione viene migrata da WebSphere a Tomcat; il motore REST passa da Wink [9] al più popolare Jersey [10] che non avrebbe funzionato con WebSphere; come parte della strategia per la availability, viene aggiunta la libreria Hystrix [11], implementando il patter Circuit Breaker [12]; viene usato Redis [13] come implementazione per la cache distribuita.
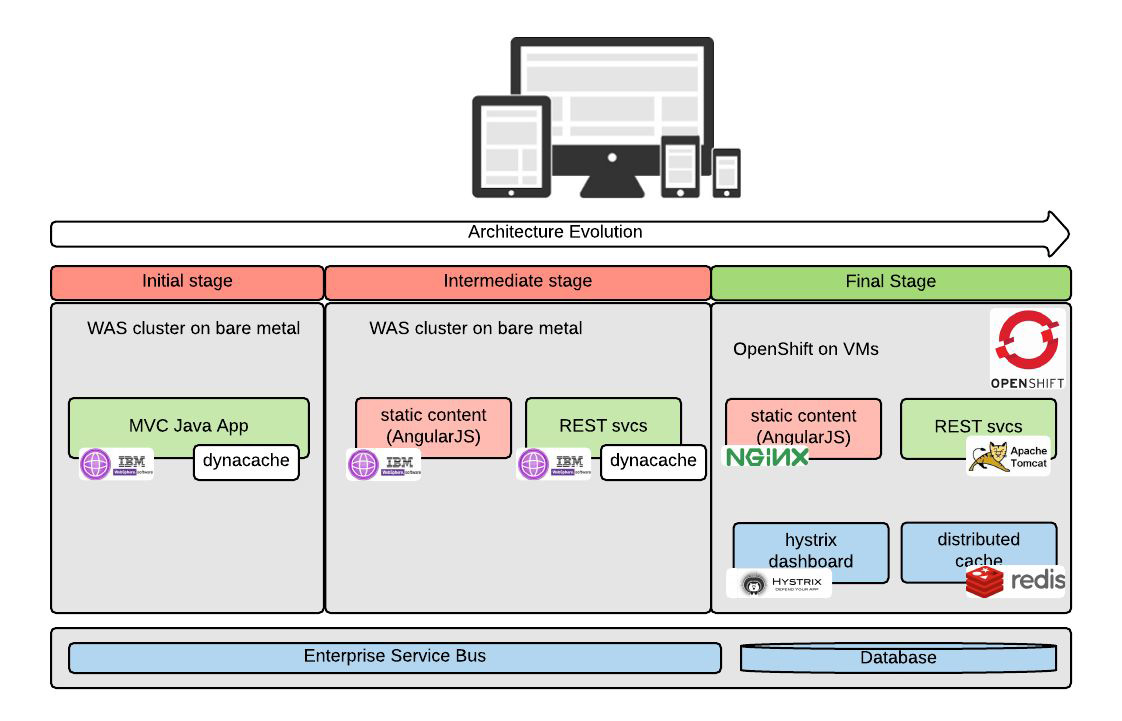
Infrastruttura immutabile
Di fatto, la parte tecnologica è sempre la più facile da gestire. Ma il nostro obiettivo finale rimaneva quello di arrivare a rilasci settimanali; i principi che intendevamo seguire per raggiungerlo erano il self provisioning dell’infrastruttura e il concetto di infrastruttura immutabile [14].
Ownership e modelli di supporto
Per raggiungere i nostri obiettivi, dovevamo definire la ownership e i modelli di supporto per le applicazioni di cui si effettuava il deployment in OpenShift. Preso atto del fatto che il team di sviluppo può “autofornirsi” la propria infrastruttura, resta aperta la domanda: “A chi spetta il suo supporto?”.
Guardando a quello che fanno Google, Netflix e Spotify, la soluzione è un modello per cui il team Dev è responsabile dell’infrastruttura di cui ha bisogno — sostanzialmente, tutto quello che mette nei suoi container — e il team Ops svolge il compito di mantenere OpenShift disponibile, visto che ovviamente OpenShift deve essere più disponibile di qualsiasi cosa ci giri sopra, il che per una banca significa una cifra davvero prossima al 100%
Per assicurarci che la ownership fosse chiara, si è deciso pertanto di collocare i file di configurazione di OpenShift per un determinato progetto insieme al resto del codice sorgente del progetto.
Continuous delivery
Tutte le operazioni dovevano essere automatizzate attraverso un flusso di continuous delivery, e abbiamo quindi costruito una pipeline con Jenkins [15].
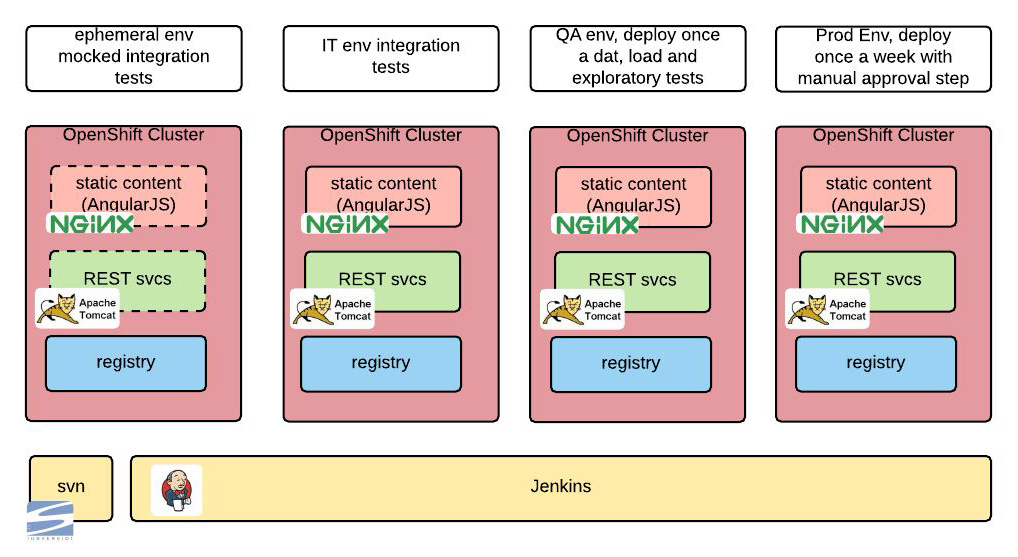
La logica con cui funziona questo flusso di continuous delivery in Jenkins è riassunta nei punti seguenti:
- Ogni 10 minuti, il repository del codice sorgente viene “scansionato”; se c’è un qualche cambiamento nel codice, si fa partire una nuova build.
- La build passa attraverso test di unità e tutto ciò che è necessario per creare l’immagine Docker del nostro progetto. Tale immagine Docker non viene più cambiata da adesso in poi: questo è uno dei punti in cui emerge il nostro approccio alla “infrastruttura immutabile”.
- Poi si fa una serie di test di integrazione su ciascuno strato della soluzione in isolamento, dove per “isolamento” si intende il fatto che le dipendenze esterne vengono simulate. Questo ci consente di condurre una serie di test indipendentemente dalla disponibilità delle dipendenze sottostanti e dalla qualità dei dati per i test. Questi test vengono condotti in un ambiente che poi si distrugge, qualcosa di piuttosto semplice con OpenShift.
Il passo successivo consiste nel condurre una serie di test di integrazione nell’ambiente IT.
Una volta al giorno si effettua nell’ambiente di QA il deployment dell’ultima build che ha completato con successo tutti i passaggi previsti. L’ambiente di Quality Assurance viene utilizzato per condurre test manuali “esplorativi” e test di carico (per ora) manuali.
L’ultimo passaggio consiste nell’effettuare il deploy una volta a settimana nell’ambiente di production preview. Questo passaggio richiede una approvazione manuale.
Passaggi di approvazione
Precedentemente, in KeyBank la messa in produzione di nuovo software prevedeva una serie di passaggi di approvazione. Si facevano delle riunioni, nelle quali le persone presentavano ciò che sarebbe stato rilasciato e i senior leader davano la loro approvazione, “firmando” la release.
Un tale processo non avrebbe funzionato con il nostro nuovo workflow su base settimanale, semplicemente perché non c’era tempo sufficiente per fare tre riunioni ogni settimana: sì, tre riunioni perché c’erano tre diverse “commissioni” che dovevano convincersi della bontà del rilascio.
Invece l’accordo finale che ha cambiato tale processo fu di considerare che, se una release aveva impatto solo su componenti all’interno di OpenShift, il rilascio era automaticamente approvato.
Test di regressione automatizzati
L’ultimo tassello che occorreva per comporre il quadro finale del nostro progetto era una copertura completa della nostra suite per i test di regressione automatici. Ci accorgemmo presto, a prezzo di alcuni errori, che non potevamo completare la nostra accelerazione verso un rilascio settimanale se non avevamo una copertura completa di test di regressione: molto semplicemente, il team dei test manuali non poteva andare così veloce da essere in grado di rieffettuare nuovi test su tutto ogni settimana.
Pertanto, l’infrastruttura per i test è stata costruita sulla base di alcuni principi del Behavioral Driven Development (BDD) [16], scegliendo Cucumber [17] come strumento per il BDD. L’aspetto davvero notevole di Cucumber è che consente di scrivere casi di test usando linguaggio naturale (inglese e non solo): abbiamo sfruttato questa possibilità chiedendo di scrivere i casi di test al team di business analysis, in modo da poter mettere in parallelo lo sviluppo del codice di business e quello dei test. Si è trattato di un netto cambiamento rispetto a prima, quando lo sviluppo delle due diverse tipologie di codice era sequenziale e quindi i test, manuali o automatici, finivano sempre per collaudare una versione vecchia del codice.
Per verificare il funzionamento della applicazione web, è stato usato Selenium [18] in modo da testare diverse combinazioni di browser e sistemi operativi. Per verificare il funzionamento della app mobile, si è fatto ricorso ad Appium [19] che ha consentito di fare test su diverse combinazioni di dispositivi e sistemi operativi mobile.
Conclusioni
Alla fine, in KeyBank la confidenza con il nostro processo di rilascio è aumentata al punto che adesso effettuiamo il deploy delle nuove versioni ogni giovedì mattina.
Utilizzando la funzionalità di rolling deployment presente in OpenShift, siamo in grado di effettuare rilasci in cui il tempo di non disponibilità del servizio è pari a zero: il downtime 0 era una delle richieste che erano sempre state fatte e che non avevano fin qui trovato una soluzione soddisfacente.
Abbiamo inoltre abilitato l’autoscaling: dopo aver testato approfonditamente questa funzionalità durante i test di carico, adesso sappiamo che il nostro sistema — o perlomeno i vari livelli del sistema contenuti in OpenShift — reagirà a picchi di carico scalando orizzontalmente al numero di istante adeguate per gestire il carico corrente.
Quello che abbiamo raccontato qui è considerato all’interno della banca come un significativo caso di successo. Il prossimo passo sarà quello di replicare lo stesso processo su altri progetti, spostando sempre più carico di lavoro all’interno di OpenShift.
Raffaele Spazzoli ha lavorato per piu di 10 anni a Imola Informatica come consulente con il ruolo di architetto delle applicazioni e delle integrazioni.
Attualmente lavora in KeyBank, una banca statunitense, come architetto dei canali fisici (filiali e contact center) e digitali (web e mobile).