

Introduzione
Apache Kafka è una piattaforma di stream-processing distribuita scritta in Scala e in Java, inizialmente sviluppata da LinkedIn e divenuta open source a inizio 2011 [1].
Si occupa di elaborare grandi moli di dati in tempo reale, permettendo di creare sistemi scalabili a elevato throughput e bassa latenza. Gestisce infine anche la persistenza dei dati stessi sia sul server principale che sulle repliche, garantendo così la cosiddetta fault-tolerance.
In questo articolo ci focalizzeremo sull’utilizzo di Kafka come strumento per lo scambio di messaggi asincroni in un ecosistema di microservizi.
Concetti fondamentali
In questa sezione illustreremo il funzionamento ad alto livello di Kafka, concentrandoci in particolare sulle cosiddette Consumer e Producer API.
Di seguito vengono descritti i principali termini utilizzati nel mondo Kafka [2]:
- topic: è una sorta di categoria utilizzata per raggruppare i messaggi;
- partizione: ciascuna delle sottosezioni in cui è diviso un topic;
- record: è il messaggio vero e proprio, costituito da una chiave, un valore e un timestamp;
- offset: indice che identifica univocamente un record all’interno di una partizione;
- produttore: entità che invia i messaggi a Kafka;
- consumatore: entità che riceve i messaggi da Kafka;
- gruppo: è un’etichetta utilizzata per distinguere insiemi di consumatori sottoscritti a un topic;
- broker: è un processo che si occupa di gestire la ricezione e il salvataggio dei messaggi e i relativi offset;
- cluster: insieme di più broker utile per replicare e distribuire le partizioni.
In figura 1 è illustrato un esempio di topic con tre partizioni.
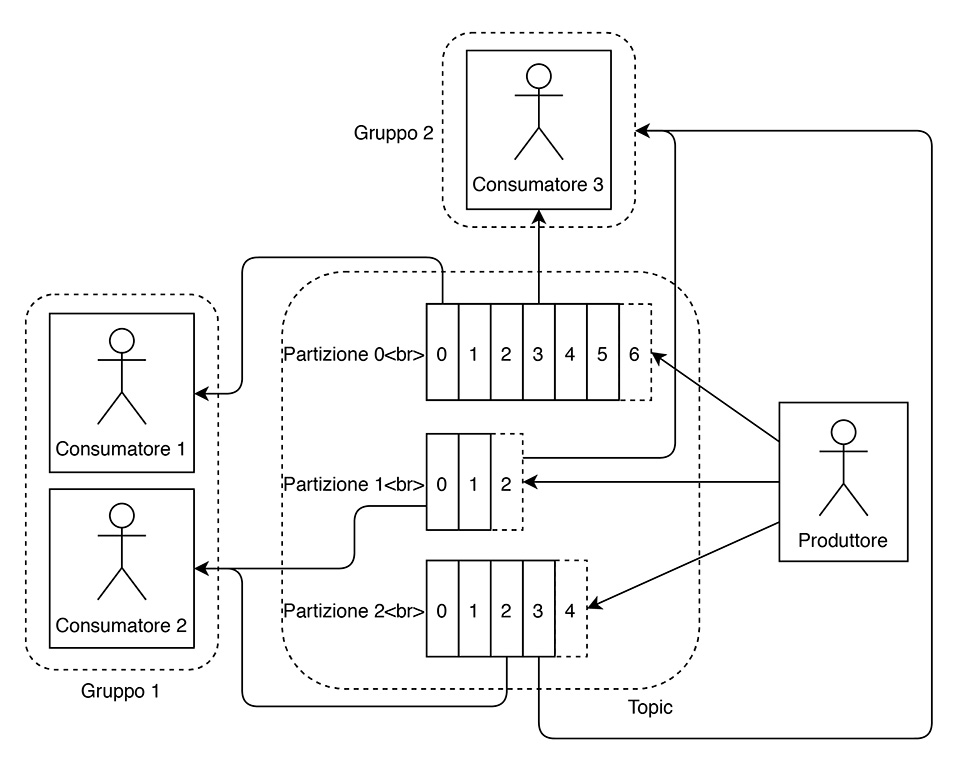
Topic e partizioni
Come si può notare, ogni partizione contiene un numero variabile di record, ciascuno con il suo offset. La partizione a cui viene assegnato un messaggio è:
- quella scelta dal produttore, se specificata al momento dell’invio;
- quella ottenuta elaborando l’hash della chiave del record, se presente;
- una qualsiasi secondo una logica di tipo round-robin, se il produttore non ha indicato né una partizione né una chiave per il messaggio.
Consumatori e partizioni
Nello schema precedente (figura 1) sono inoltre presenti due diversi gruppi di consumatori, uno costituito da due distinte istanze di consumatori, l’altro comprendente invece un solo consumatore.
Se un gruppo è formato da più consumatori, le partizioni di un topic e i relativi record vengono distribuiti tra di essi. In particolare, detto C il numero di consumatori e P il numero di partizioni:
- se C > P allora a P consumatori verrà assegnata una partizione, mentre C – P consumatori resteranno senza partizioni;
- se C = P ciascun consumatore avrà una e una sola partizione;
- se C < P le varie partizioni saranno distribuite in maniera uniforme tra i vari consumatori.
Il bilanciamento delle partizioni è dinamico, ossia esse vengono redistribuite al momento della connessione o disconnessione dei consumatori.
Come si può facilmente intuire, quindi, le partizioni e i gruppi di consumatori sono gli elementi che permettono di scalare orizzontalmente un sistema. Nel nostro esempio possiamo notare che:
- il consumatore 1 riceve messaggi solo dalla partizione 0;
- il consumatore 2 riceve messaggi dalle partizioni 1 e 2;
- il consumatore 3 riceve messaggi da tutte le partizioni essendo l’unico membro del suo gruppo.
È importante sottolineare che un consumatore non riceve mai automaticamente i messaggi, bensì deve richiederli esplicitamente quando è pronto a elaborarli.
Installazione
Per semplicità, si consiglia di eseguire Kafka utilizzando un’immagine Docker. Prima di farlo, però, deve essere attivato anche ZooKeeper, un software utile per gestire la sincronizzazione di sistemi distribuiti e necessario per il funzionamento di Kafka.
Di seguito è riportato un esempio di docker-compose.yml che permette di avviare entrambi i servizi.
version: '2' services: zookeeper: image: wurstmeister/zookeeper ports: - 2181:2181 kafka: image: wurstmeister/kafka ports: - 9092:9092 depends_on: - zookeeper environment: KAFKA_LISTENERS: PLAINTEXT://:9092 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_CREATE_TOPICS: "Stocks:2:1,Quotes:2:1,Orders:2:1"
Come si può notare, nel file è stata valorizzata anche la variabile d’ambiente KAFKA_CREATE_TOPICS, che permette di creare automaticamente un insieme di topic specificandone il nome, nonché il numero di partizioni e di repliche necessarie.
Esempio applicativo
Mostreremo ora come è possibile utilizzare Kafka in pratica. Lo schema riportato in figura 2 delinea l’architettura della nostra applicazione d’esempio, ossia un sistema di trading automatico composto da tre distinti microservizi: il QuotesDownloader, il TradingBot ed il DbService.
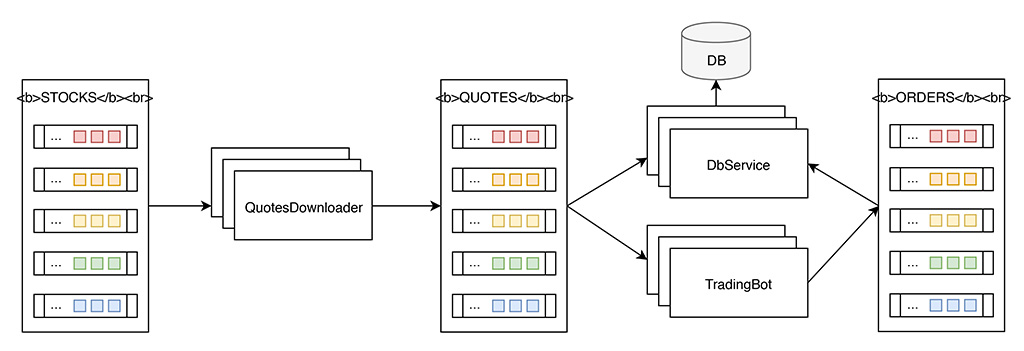
Figura 2 – Architettura dell’applicazione d’esempio.
L’obiettivo è quello di realizzare un’applicazione che riceva in input le quotazioni di quanti più possibili titoli del mercato azionario, le elabori in parallelo e produca in output degli ordini di acquisto e/o vendita dei titoli stessi.
QuotesDownloader
Il QuotesDownloader è il microservizio che si occupa di scaricare le quotazioni — interrogando ad esempio un servizio REST — e di inviarle a un topic Kafka affinché possano essere elaborate dagli altri microservizi.
Per rendere il sistema scalabile, dobbiamo far sì che ogni istanza di QuotesDownloader prenda in carico un sottoinsieme dei titoli da analizzare e che i vari sottoinsiemi siano tra loro disgiunti. Per far ciò possiamo sfruttare anche in questo caso Kafka: non dovremo far altro che creare un topic (denominato Stocks) con un numero arbitrario di partizioni a seconda del livello di parallelismo che vogliamo ottenere. Ogni partizione dovrà contenere un certo numero di record, ciascuno avente come valore il simbolo di un titolo tra quelli in esame, e ogni istanza prenderà in carico una o più partizioni.
Per realizzare il servizio possiamo creare un semplice progetto Maven, inserendo nel file pom.xml la seguente dipendenza che ci permetterà di utilizzare le API di Kafka:
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.12</artifactId> <version>2.0.0</version> </dependency>
Procediamo quindi con la creazione delle classi Consumer.java e Producer.java riportate di seguito, che non sono altro che un wrapper rispettivamente di KafkaConsumer e KafkaProducer messi a disposizione dalla libreria di Kafka.
Ecco la classe Consumer:
public class Consumer {
private final Logger logger = LogManager.getLogger(Consumer.class);
private KafkaConsumer<String, String> consumer;
private String topic;
public Consumer(String topic, int instanceNumber) {
this.topic = topic;
Properties properties = new Properties();
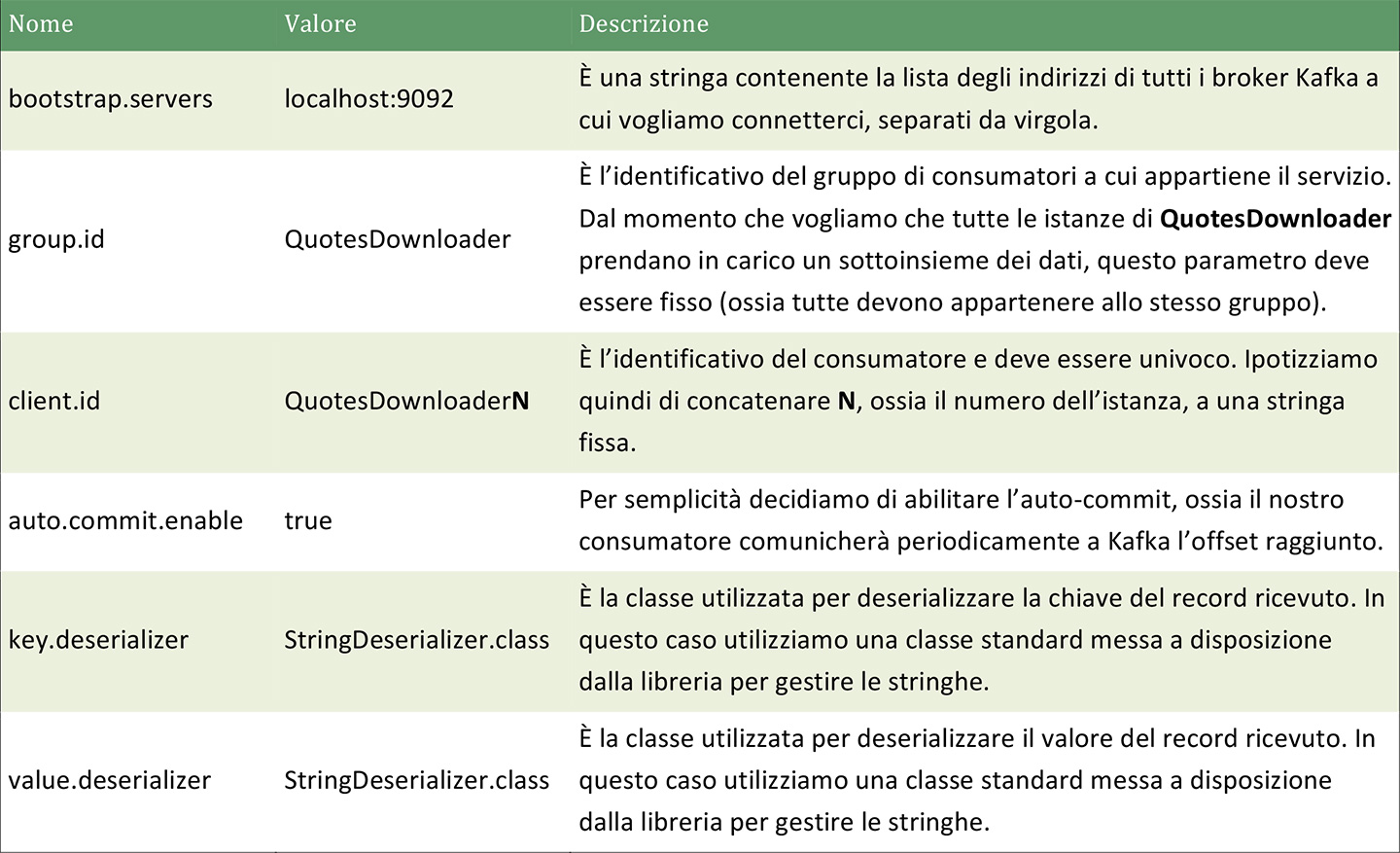
properties.put("bootstrap.servers", Constants.BOOSTRAP_SERVERS);
properties.put("group.id", "QuotesDownloader");
properties.put("client.id", "QuotesDownloader" + instanceNumber);
properties.put("auto.commit.enable", "true");
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer", StringDeserializer.class);
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(Arrays.asList(this.topic));
}
public ConsumerRecords<String, String> receive() {
ConsumerRecords<String, String> records = null;
try {
this.logger.debug("Receiving records...");
records = this.consumer.poll(Duration.ofSeconds(1));
this.logger.debug("{} records received", records.count());
} catch (Exception e) {
this.logger.error("receive exception:", e);
}
return records;
}
public void close() {
this.consumer.close();
}
}
E la classe Producer:
public class Producer {
private final Logger logger = LogManager.getLogger(Producer.class);
private KafkaProducer<String, Quote> producer;
private String topic;
public Producer(String topic, int instanceNumber) {
this.topic = topic;
Properties properties = new Properties();
properties.put("bootstrap.servers", Constants.BOOSTRAP_SERVERS);
properties.put("client.id", "QuotesDownloader" + instanceNumber);
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", QuoteSerializer.class);
this.producer = new KafkaProducer<>(properties);
}
public boolean send(String key, Quote value) {
try {
this.logger.debug("Sending record...");
this.producer.send(new ProducerRecord<>(this.topic, key, value)).get();
this.logger.debug("Record sent");
return true;
} catch (Exception e) {
this.logger.error("send exception:", e);
return false;
}
}
}
Come si può notare, il consumatore definisce una serie di proprietà specifiche di Kafka, elencate nella tabella 1.
Il metodo receive non fa altro che richiamare il metodo poll della libreria Kafka, il quale riceve come parametro il timeout dell’operazione.
Il metodo close, infine, si occupa chiudere la connessione.
In analogia con quanto fatto per il consumatore, anche il produttore definisce alcune proprietà di Kafka. In questo caso però, vengono omesse group.id e auto.commit.enable, che sono specifici del consumatore, mentre per deserializzare il valore di un record utilizzeremo una classe ad hoc, descritta nel seguito.
Infine, il produttore definisce un metodo send che riceve come parametro la chiave del record e il suo valore, e restituisce un booleano che indica se l’invio è andato a buon fine.
Analizziamo ora in dettaglio la classe QuoteSerializer.java, che si occupa appunto di serializzare un oggetto di tipo Quote. Questo oggetto dovrà contenere i dati di nostro interesse, come ad esempio prezzo e volume, nonché il simbolo del titolo e il timestamp a cui fanno riferimento. Il codice del QuoteSerializer, riportato di seguito, è comunque indipendente dall’effettiva struttura dell’oggetto.
public class QuoteSerializer implements Serializer<Quote> {
private ObjectMapper objectMapper;
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
this.objectMapper = new ObjectMapper();
}
@Override
public byte[] serialize(String topic, Quote quote) {
try {
return objectMapper.writeValueAsBytes(quote);
} catch (Exception e) {
throw new SerializationException("Error serializing object", e);
}
}
@Override
public void close() {
}
}
La classe deve implementare l’interfaccia Serializer della libreria Kafka, che definisce i seguenti metodi [3]:
- configure. È il metodo che viene eseguito all’avvio e riceve le configurazioni (servers, client.id, etc. definite in precedenza) e un flag che indica se l’oggetto da serializzare è la chiave o il valore del record. Nel nostro caso utilizziamo questo metodo per istanziare un ObjectMapper della libreria Jackson, che permette di trasformare oggetti Java in JSON.
- serialize. È il metodo che contiene la logica che permette di trasformare il dato in un array di byte.
- close. Deve essere idempotente in quanto potrebbe essere richiamato più volte al momento della chiusura.
A questo punto non resta che la classe principale del nostro servizio, ossa Main.java, riportata di seguito.
public class Main {
private static final Logger logger = LogManager.getLogger(Main.class);
public static void main(String[] args) {
final int instanceNumber = Integer.valueOf(args[0]);
Consumer consumer = new Consumer("Stocks", instanceNumber);
List<String> symbols = new ArrayList<>();
while (symbols.isEmpty()) {
ConsumerRecords<String, String> records = consumer.receive();
for (ConsumerRecord<String, String> record : records) {
String symbol = record.value();
logger.debug("Adding symbol {}", symbol);
symbols.add(symbol);
}
}
consumer.close();
Downloader downloader = new Downloader();
Producer producer = new Producer("Quotes", instanceNumber);
Map<String, Quote> oldQuotesMap = new HashMap<>();
while (true) {
for (String symbol : symbols) {
Quote newQuote = downloader.download(symbol);
Quote oldQuote = oldQuotesMap.get(symbol);
if (newQuote != null && !newQuote.equals(oldQuote)) {
boolean success = producer.send(symbol, newQuote);
if (success) {
oldQuotesMap.put(symbol, newQuote);
}
}
}
}
}
}
La logica è molto semplice e suddivisa in due blocchi distinti.
Nella prima parte viene istanziato un consumatore, che riceverà dati dal topic Stocks. A questo punto il nostro consumatore deve restare in attesa finché non riceve l’elenco dei simboli da gestire.
Nella seconda parte, dopo aver preso in carico un insieme di titoli, il servizio si occupa di istanziare un produttore e un oggetto di tipo Downloader, il quale ha il compito di recuperare la quotazione di un titolo in un dato momento a partire dal suo simbolo. La realizzazione di questa parte è demandata al lettore. Si consiglia l’utilizzo di un servizio come IEX [4], che fornisce delle API gratuite.
A questo punto si entra in un ciclo infinito, in cui il Downloader scarica di continuo le quotazioni di tutti i titoli e, se sono cambiate, le invia al topic Quotes, utilizzando come chiave del record il simbolo del titolo.
Dopo aver avviato Kafka e tutte le nostre istanze di QuotesDownloader, possiamo popolare il topic Stocks e avviare così il processo di download sfruttando lo script kafka-console-producer.sh presente all’interno della release di Kafka.
Procediamo quindi con la creazione di un file di testo che chiameremo stocks.txt e conterrà tutti i titoli di nostro interesse. Eccone un esempio:
AAPL ABBV FB JNJ JPM KO MSFT NKE T XOM
Successivamente possiamo eseguire lo script con il seguente comando, avendo cura di sostituire [KAFKA_PATH] con il path della cartella della release di Kafka:
cat stocks.txt | [KAFKA_PATH]/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Stocks
In questo modo il produttore invierà un messaggio per ogni riga contenuta nel file. Dal momento che non viene specificata alcuna partizione né alcuna chiave, la strategia di indirizzamento utilizzata sarà quella di tipo round-robin e le nostre partizioni risulteranno quindi perfettamente bilanciate.
Le istanze di QuotesDownloader si divideranno equamente le partizioni e il carico risulterà quindi perfettamente bilanciato.
TradingBot
Il TradingBot rappresenta il core del nostro sistema. È infatti il componente che contiene tutta la logica che permette di generare ordini sulla base delle quotazioni di un determinato titolo.
Come il QuotesDownloader, agisce sia da consumatore, per ricevere dati dal topic Quotes, che da produttore, per tracciare le transazioni nel topic Orders).
Il TradingBot dovrà pertanto essere in grado di deserializzare oggetti di tipo Quote. Procediamo quindi con la creazione della nuova classe QuoteDeserializer.java, riportata di seguito.
public class QuoteDeserializer implements Deserializer<Quote> {
private ObjectMapper objectMapper;
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
this.objectMapper = new ObjectMapper();
}
@Override
public Quote deserialize(String topic, byte[] objectBytes) {
try {
return objectMapper.readValue(objectBytes, Quote.class);
} catch (Exception e) {
throw new SerializationException("Error deserializing object", e);
}
}
@Override
public void close() {
}
}
Per la serializzazione degli ordini si può invece procedere in maniera analoga a quanto fatto in precedenza per le quotazioni.
Per realizzare la logica di trading vera e propria, invece, si consiglia l’utilizzo di Ta4j [5], una libreria open source per l’analisi tecnica. Di seguito sono riportate due classi di esempio, Bot.java e SmaBot.java.
La classe Bot.java definisce il metodo executeStrategy che riceve periodicamente in ingresso un oggetto di tipo Bar [6] e si occupa di emettere degli ordini di acquisto o vendita in base alla strategia di trading scelta.
Essendo una classe astratta, la specifica logica da applicare dovrà essere implementata nelle sottoclassi, nel nostro caso SmaBot.java. Qui viene utilizzato come indicatore la media mobile semplice calcolata su una finestra di 10 dati, e la strategia prevede la generazione di ordini di acquisto o vendita ogni qualvolta il prezzo di chiusura si sposti rispettivamente al di sopra o al di sotto della media mobile.
Bot.java:
public abstract class Bot {
private boolean isInitialized;
private Decimal totalAmount;
private Decimal orderLimit;
protected int timeFrame;
protected TimeSeries timeSeries;
protected Strategy strategy;
private TradingRecord tradingRecord;
protected Bot(String timeSeriesName) {
this.isInitialized = false;
this.totalAmount = Decimal.valueOf(0);
this.orderLimit = Decimal.valueOf(10000);
this.timeFrame = 10;
this.timeSeries = new BaseTimeSeries(timeSeriesName);
this.timeSeries.setMaximumBarCount(this.timeFrame);
this.tradingRecord = new BaseTradingRecord();
}
protected abstract void buildStrategy();
public void addBar(Bar bar) {
this.timeSeries.addBar(bar);
if (!this.isInitialized &&
this.timeSeries.getBarCount() == this.timeFrame) {
this.isInitialized = true;
this.buildStrategy();
}
}
public Order executeStrategy(Bar newBar) {
Order order = null;
this.addBar(newBar);
if (this.strategy != null) {
int endIndex = this.timeSeries.getEndIndex();
Decimal price = newBar.getClosePrice();
if (this.strategy.shouldEnter(endIndex)) {
boolean entered = this.tradingRecord.enter(
endIndex,
price,
this.computeAmount(price));
if (entered) {
order = this.tradingRecord.getLastEntry();
this.totalAmount = this.totalAmount.plus(order.getAmount());
}
} else if (this.strategy.shouldExit(endIndex)) {
boolean exited = this.tradingRecord.exit(
endIndex,
price,
this.totalAmount);
if (exited) {
order = this.tradingRecord.getLastExit();
this.totalAmount = this.totalAmount.minus(order.getAmount());
}
}
}
return order;
}
private Decimal computeAmount(Decimal price) {
return this.orderLimit.dividedBy(price).floor();
}
}
SmaBot.java:
public class SmaBot extends Bot {
public SmaBot() {
super("smaTimeSeries");
}
@Override
protected void buildStrategy() {
ClosePriceIndicator cpIndicator = new ClosePriceIndicator(this.timeSeries);
SMAIndicator sma = new SMAIndicator(cpIndicator, this.timeFrame);
this.strategy = new BaseStrategy(
new OverIndicatorRule(sma, cpIndicator),
new UnderIndicatorRule(sma, cpIndicator)
);
}
}
Trattandosi di un esempio, la realizzazione di logiche di business più complesse e articolate è lasciata al lettore. Quello che ci preme sottolineare qui è invece che, avendo utilizzato i simboli delle azioni come chiavi dei record nel topic Quotes, abbiamo la garanzia che tutte le quotazioni di uno stesso titolo vengano memorizzate nella stessa partizione.
Dal momento che le partizioni sono poi assegnate univocamente ai consumatori, ogni istanza di TradingBot riceverà tutte le quotazioni di uno o più titoli e potrà quindi generare ordini di acquisto o vendita basati su una finestra completa di dati.
DbService
Il DbService, infine, è il microservizio che si occupa di memorizzare in un database le principali informazioni che circolano all’interno della nostra applicazione, ossia quotazioni e ordini. Sebbene non strettamente necessario ai fini del funzionamento del sistema, può essere utile salvare questi dati per eseguire ulteriori analisi e misurare l’effettiva efficacia del nostro algoritmo di trading.
Se fino ad ora i nostri microservizi si erano occupati di ricevere in input un unico tipo di record, il DbService deve essere in grado di gestire e memorizzare sul database oggetti diversi; pertanto può essere utile modificare le classi viste in precedenza utilizzando i generics.
Riportiamo di seguito il codice della classe ObjectDeserializer.java, utilizzata per deserializzare oggetti generici.
public class ObjectDeserializer<O> implements Deserializer<O> {
private ObjectMapper objectMapper;
private Class<O> objectClass;
@Override
public void configure(Map<String, ?> config, boolean isKey) {
this.objectMapper = new ObjectMapper();
this.objectClass = (Class<O>) (
isKey ?
configs.get("keyClass") :
configs.get("valueClass")
);
}
@Override
public O deserialize(String topic, byte[] objectBytes) {
try {
return objectMapper.readValue(objectBytes, this.objectClass);
} catch (Exception e) {
throw new SerializationException("Error deserializing object", e);
}
}
@Override
public void close() {
}
}
Come si può notare, le classi da utilizzare per la chiave e il valore vengono passate all’interno delle configurazioni.
Vediamo quindi come riscrivere la classe Consumer.java per rendere anch’essa generica.
public class Consumer<K, V> {
private final Logger logger = LogManager.getLogger(Consumer.class);
private KafkaConsumer<K, V> consumer;
private String topic;
public Consumer(String topic, int instanceNumber,
Class<K> keyClass, Class<V> valueClass) {
this.topic = topic;
Properties properties = new Properties();
properties.put("bootstrap.servers", Constants.BOOSTRAP_SERVERS);
properties.put("group.id", "DbService" + topic);
properties.put("client.id", "DbService" + topic + instanceNumber);
properties.put("auto.commit.enable", "true");
properties.put("key.deserializer", ObjectDeserializer.class);
properties.put("value.deserializer", ObjectDeserializer.class);
properties.put("keyClass", keyClass);
properties.put("valueClass", valueClass);
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(Arrays.asList(this.topic));
}
public ConsumerRecords<K, V> receive() {
ConsumerRecords<K, V> records = null;
try {
this.logger.debug("Receiving records...");
records = this.consumer.poll(Duration.ofSeconds(1));
this.logger.debug("{} records received", records.count());
} catch (Exception e) {
this.logger.error("receive exception:", e);
}
return records;
}
public void close() {
this.consumer.close();
}
}
Il nuovo consumatore riceve le classi da utilizzare per chiave e valore e le aggiunge alle proprietà.
Focalizziamo ora l’attenzione sul gruppo: dal momento che l’identificativo scelto è costante, tutte le istanze di DbService si divideranno equamente le partizioni (e quindi i record da salvare nel database). Essendo inoltre diverso da quello del TradingBot, i due processi opereranno indipendentemente l’uno dall’altro.
A questo punto possiamo istanziare un nuovo consumatore che legga dal topic Quotes con questa semplice riga di codice:
Consumer quotesConsumer
= new Consumer<>("Quotes", instanceNumber, String.class, Quote.class);
Il servizio vero e proprio sarà quindi costituito da un ciclo continuo di ricezione e salvataggio dei record nel database scelto.
Conclusioni
In questo articolo abbiamo esposto i principali concetti riguardanti il funzionamento di Apache Kafka, concentrandoci in particolare sull’utilizzo delle Consumer e Producer API e delle relative potenzialità.
Abbiamo poi illustrato l’architettura di una possibile applicazione a microservizi, corredata da esempi di codice che mostrano come sia possibile suddividere e gestire in parallelo grandi moli di dati in maniera semplice e immediata, rendendo il sistema nel suo complesso scalabile orizzontalmente.
Dopo aver conseguito la laurea con lode in Ingegneria Informatica presso il Politecnico di Milano, ho lavorato per qualche anno come full-stack developer e successivamente come Project Manager in ambito Telco & Media.
Nel corso del 2017 ho iniziato ad avvicinarmi al mondo Agile, ottenendo la certificazione PSM I e arrivando infine in Intré.
La mia esperienza si concentra principalmente in ambito Java e Node.js.