
Tip and Tricks
Dopo il primo articolo dedicato ai princìpi fondamentali della geolocalizzazione e quello dello scorso mese in cui abbiamo parlato delle API e dei paradigmi messi a disposizione per implementarla, è arrivato il momento in cui vedere come risolvere certi problemi tecnici che vengono sollevati dal mettere in pratica quanto esposto fin qui. Appare infatti chiaro come un progettista che si deve cimentare nello sviluppo di una applicazione che sfrutta i servizi di geolocalizzazione debba fare i conti con diversi aspetti.
Approssimazione della posizione
Il primo elemento da considerare è senz’altro l’approssimazione con cui la posizione viene determinata. Una buona costante da tenere a mente sono almeno i 5-6 metri derivanti dall’utilizzo del GNSS.
Accesso ai servizi di geolocalizzazione
Un altro aspetto è il paradigma di accesso ai servizi di geolocalizzazione: in base a quello scelto, è necessario governare il processo di acquisizione della posizione in modo che questo sia reso disponibile in tempo e modo utile all’applicazione, giocando sulla parametrizzazione dei tempi e/o delle distanze.
Consumo della batteria
Infine, ma non ultimo in termini di importanza, c’è il discorso della durata della batteria che alimenta il funzionamento del dispositivo mobile. Occorre attuare ogni forma di ottimizzazione dell’utilizzo dei sensori in modo da non scaricare la batteria dopo poche ore di attività. “Sì, ma le batterie dei dispositivi più moderni durano più a lungo!”. Vero, ma di fatto un utilizzo continuo dei sensori è in grado di abbassare il livello di carica in tempi relativamente brevi.
Poi, se il tipo di applicazione da sviluppare è sostanzialmente un navigatore, non ci sono molte scappatoie. Un navigatore nasce con lo scopo di presentare la posizione su una mappa che rappresenta lo stradario; per cui, quando il veicolo è in movimento, deve di continuo aggiornare la posizione.
Questo implica che la frequenza con cui l’applicazione richiederà gli aggiornamenti sarà alta: una volta al secondo o anche più; e a questo va aggiunta la richiesta di una precisione massima: già i classici 5-6 metri di errore diventano eccessivi.
Quindi un navigatore è necessariamente un consumatore cronico di batterie e non si può fare molto al riguardo. Fortunatamente sono applicazioni che si usano solo per il tempo strettamente necessario a raggiungere una destinazione, e magari si tratta di brevi tragitti; ma ci possono essere applicazioni che invece, in modo silente, devono rimanere sempre attive.
Paradigmi
Le applicazioni di cui ci occupiamo utilizzano tipicamente il tracking o il geofencing per attivare delle funzioni quando un veicolo è in prossimità di un obiettivo. Ad esempio, possono informare sulla situazione del traffico, del meteo o su incidenti ancora non risolti quando si percorrono determinate strade.
Si pensi per esempio a Waze che, sulla base di queste necessità, ha anche depositato un brevetto nel 2012 relativamente a “Condition-based activation, shut-down and management of applications of mobile devices”.
In questo tipo di applicazioni una eccessiva approssimazioni nel rilevamento della posizione, o una scorretta modalità nell’uso delle API, può comportare una cattiva interpretazione dei vincoli geometrici, comportano il rischio di mancare l’obiettivo e rendendo quindi l’applicazione funzionalmente inutilizzabile.
Non ci sono best practice che forniscano delle linee guida valide per ogni contesto e ogni implementazione; si può solo cercare di crearsi una piccola knowledge base che sia il risultato delle sperimentazioni fatte e della comprensione degli errori verificatisi.
Di seguito, quindi, riportiamo alcune considerazioni che, sulla base di esperienze, sono risultate le più importanti.
Tempo o distanza?
Quando si tratta di tracking, dal punto di vista geometrico, per un progettista è senz’altro più semplice ragionare per distanze percorse invece che per tempi di percorrenza.
La ragione è ovvia: le distanze danno la sicurezza di come saranno disposti i campioni lungo il tracciato, indipendentemente dalla velocità — e meglio ancora dalla variazione della velocità — del veicolo. Seguire un tracciato curvo o verificare se si passa in prossimità di un punto, diventa più semplice se si può ragionare solo per spostamenti limitati.
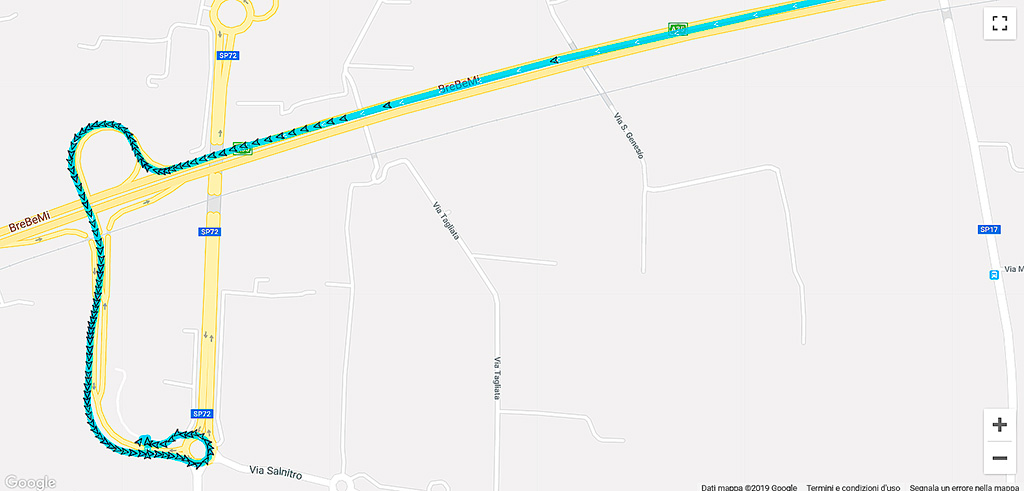
Un esempio pratico generato con un’applicazione di prova è riportato in figura 1. L’obiettivo è un casello autostradale, per cui si modula il tracking in modo che, in prossimità del casello, si aumenti il numero dei campioni cercando di mantenerli a una distanza di 10 m l’uno dall’altro.
Limiti al campionamento per sola distanza
Queste considerazioni però devono fare i conti con le API che non garantiscono una notificazione delle letture esattamente corrispondente alla distanza indicata: spesso in realtà i dati vengono registrati con un leggero ritardo rispetto alla distanza preimpostata, e certamente non prima che tale intervallo sia stato percorso. Un eccessivo ritardo o una distanza troppo grande potrebbe influire sulla funzionalità dell’applicazione, per cui si è costretti a scegliere tra le due modalità quella che garantisce un errore minore.
In figura 2 sono riportati i campioni misurati di alcuni punti consecutivi relativi al tracking in esame. Come si può vedere dall’odometro, tra due campioni successivi non otteniamo un valore di circa 10 m — sovrapponibile a quello impostato — ma invece un intervallo di 15–18 metri!
L’utilità degli intervalli di tempo
Sulla base di altre prove, si è constatato come imporre i tempi, fissando la cadenza con cui vengono registrati i dati, comporti l’acquisizione di campioni con una deriva percentuale molto minore rispetto ai risultati attesi.
Ciò comporta che, nello sviluppo di applicazioni di questo genere, la via più sicura è che il progettista si faccia carico di ragionare per tempi anziché su distanze come potrebbe invece sembrare più naturale e “logico”.
Guardando alla realtà, occorre tenere in considerazione anche la velocità con cui un veicolo potrebbe attraversare un tracciato. La velocità non è costante per tutti gli utenti ma è direttamente proporzionale alla loro incoscienza: in autostrada ci possono essere i casi limite di chi viaggia alla velocità di 80 km/h nella corsia di sorpasso e quello di chi, nonostante il limite, viaggia a 250 km/h anche sulle rampe di decelerazione agli svincoli… Poi c’è la massa che più o meno rispetta il limite dei 130 km/h.
Facendo riferimento a questi esempi, per campionare uno spazio di 10 m bisognerebbe impostare un intervallo di 450 ms nel primo caso e di 180 ms nel secondo, e di 280 ms per coloro che rispettano i limiti.
Per non scontentare gli utenti che viaggiano come missili, è necessario imporre un campionamento con il periodo più basso a discapito degli utenti medi che vedranno un consumo di batteria pari a quasi il doppio del necessario.
Alternativamente, bisognerebbe sviluppare un algoritmo che si adatti alla velocità, per cui ad ogni campione si decide l’intervallo di campionamento prima che venga effettuato il campionamento successivo. Ma questo complicherebbe ulteriormente la vita agli sviluppatori nella progettazione del codice…
Tracking: API native o Fused Location API?
Gli algoritmi di tracking applicano per lo più una modulazione nel rilevamento, a seconda delle zone in esame. La discriminante è quindi capire se siamo vicini o lontano dall’obiettivo e, sulla base di questa considerazione, tarare la frequenza dei campionamenti e la precisione della misura.
Sotto questo profilo l’uso delle API native sembra molto più semplice e diretto rispetto alle Fused Location API, per cui si sarebbe tentati di andare a più “basso livello” con l’idea di avere un maggior controllo del dispositivo.
Se tralasciamo per un momento le strategie utilizzate dalle Fusion Location API che cercano di ottimizzare in autonomia l’uso dei provider, non vi è una sostanziale differenza quando si usano le API native con provider GPS e NETWORK rispetto alle strategie HIGH_ACCURACY e LOW_POWER.
Però, a differenza delle API native, le Fused Location API sono in grado di sfruttare il fatto che possono condividere i rilevamenti eseguiti quando anche altre applicazioni usano i sensori di geolocalizzazione, diminuendo il complessivo consumo di batteria.
Certamente questo tipo di vantaggio non porta a un beneficio diretto per la singola applicazione ma, nell’economia complessiva del dispositivo, si può trarre qualcosa di utile. L’uso delle Fused Location API è quindi da preferire anche se sembrano “meno dirette” delle API native.
Fused Location API: soglie di precisione e scelta del provider
Uno degli aspetti più importanti delle Fused Location API è la capacità di determinare il miglior provider in base alla strategia scelta per il rilevamento della posizione. Consultando però la documentazione si nota come di fatto ci sia un solo profilo per cui questa scelta viene effettuata dalle librerie; tale profilo si attiva impostando il parametro priority a BALANCED_POWER_ACCURACY.
L’assunzione implementata nelle librerie è che una sorgente WiFi non può distare mai oltre 100 m. Il rilevamento della posizione viene fatto prendendo, se presenti, le informazioni trasmesse sulla posizione fisica dell’access point; pertanto, sulla base dell’assunzione precedente, la precisione del rilevamento è al più la distanza massima di copertura del segnale.
La reale precisione del WiFi e delle celle telefoniche
Il limite dei 100 m è valutato considerando antenne e potenze indicate negli standard IEEE 802.11; tuttavia l’uso di antenne direzionali invece che omnidirezionali già potrebbe allungare la portata del segnale: per questo motivo non è opportuno affidarsi alle letture di posizione da WiFi e un utile consiglio sarebbe che gli utenti disabilitassero questa opzione dal pannello di controllo di Android.
Anche nel caso di rilevamento da celle telefoniche si opera lo stesso tipo di assunzione e modalità di determinazione della posizione. La differenza sta nel fatto che le librerie assumono che la precisione sia dell’ordine dei 10 km.
In questo caso si può dire che la distanza è da considerarsi parecchio in eccesso in quanto il numero di antenne installate è tale che non distano mai così tanto l’una dall’altra e i dispositivi mobili cercano sempre di agganciare la cella più vicina. Queste informazioni sono accessibili da siti che mappano il posizionamento delle antenne in base all’operatore. In figura 3 si può vedere che tra centri urbani (p.e. Venezia Mestre-Padova-Vicenza) la distanza a volte non supera i 5-6 km, mentre nelle aree urbane 1 km o poco più.
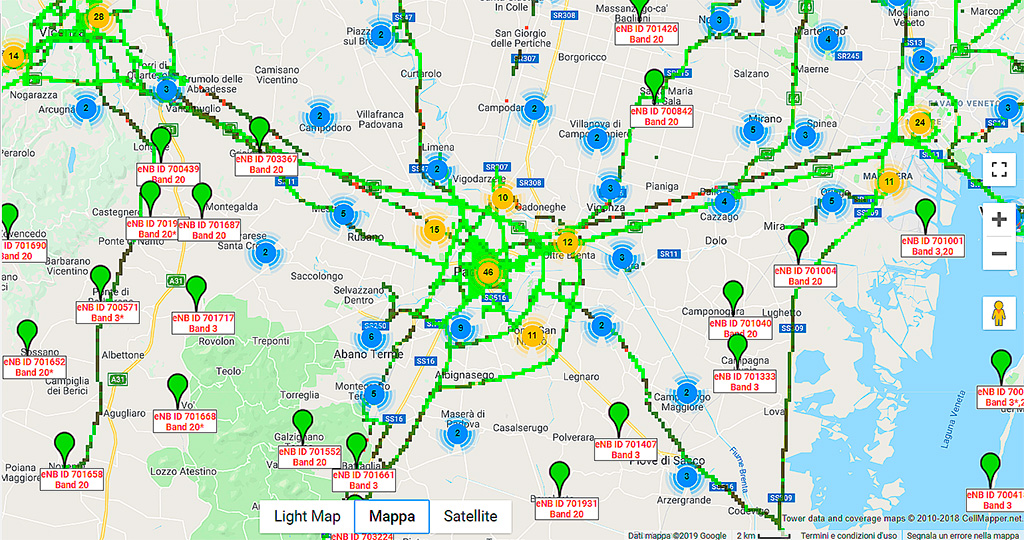
Se si potessero mettere in atto queste considerazioni — avendo di ogni cella l’informazione se urbana o meno — le Fused Location API potrebbero dare una migliore precisione nella lettura della posizione anche da rete.
Il risparmio energetico messo in atto dalle Fused Location API
La modalità di risparmio energetico messo in atto dalle Fused Location API per le funzioni di rilevamento della posizione si basa sul fatto di minimizzare il numero di letture necessarie cercando di condividerle il più possibile tra tutte le applicazioni che stanno usando i servizi di geolocalizzazione.
La speranza è, che in questo modo, più applicazioni che utilizzino i servizi di geolocalizzazione contemporaneamente, possano operare consumando poco più che una singola applicazione.
Gli effetti di questo tipo di economia si vedono però se un utente comincia ad avere parecchie applicazioni in background; ma, che mi risulti, al momento non ce ne sono poi così tante.
Per questo motivo, un progettista software deve comunque considerare di implementare dei processi ottimizzati nell’uso di tali servizi a prescindere dalle tecniche di ottimizzazione messe in atto dalle librerie: basta una singola applicazione mal progettata affinché ogni sforzo per risparmiare batteria risulti vano.
Questo va un po’ contro la consuetudine dei progettisti di dare per assunto che una infrastruttura risolva i problemi di complessità dell’applicazione nell’accesso a un servizio e quindi non sia un compito fondamentale dello sviluppatore progettarlo già ottimizzato…
Geofence: bene ma non benissimo
L’uso dei geofence sembra la panacea di ogni male per le applicazioni in cui bisogna attivare un evento in prossimità di un luogo: basta posizionare i geofence come se fossero delle “fotorappole” e, senza avere più necessità di consumare un elettrone, aspettare che scattino. Peccato che le Fused Location API consentano di gestire solo fino a 100 geofence.
Questo è un limite importante perché richiede che ogni applicazione utilizzi i geofence con particolare parsimonia e si preoccupi di inserirli fintantoché che n’è bisogno e rimuoverli subito dopo. Un’applicazione quindi, non può semplicemente registrare tutti i geofence che intende monitorare se questi sono in numero considerevole, ma deve implementare delle strategie di aggiornamento mantenendo attivi solo quelli strettamente necessari.
Ovviamente i geofence strettamente necessari sono quelli che, in un determinato momento, sono i più vicini, quindi l’applicazione, per mantenerli aggiornati, ha bisogno comunque di determinare la posizione tramite i servizi di localizzazione e di conseguenza rimanere attiva in background.
L’impiego dei geofence nelle applicazioni di tracking veicolare
Nelle applicazioni di tracking veicolare c’è un fattore importante che può aiutare un progettista a migliorare il software: i veicoli corrono su strade e non si muovono a caso su qualsiasi punto della superficie del geoide terrestre.
Per individuare il passaggio di un veicolo su un tratto di strada utilizzando un geofence è sufficiente quindi posizionarne il centro a metà della corsia e imporre un raggio abbastanza ampio per consentire di catturare i veicoli che transitano su di essa tenendo in considerazione l’approssimazione del GPS. Sapendo che una corsia di marcia di una strada in genere è larga dai 2,75 m ai 3,75 m, e considerando la precisione del GPS pari a 5 m, il raggio da imporre sarà non meno di 7-10 m.
Ciò può creare non pochi problemi perché comincia a trattarsi di un raggio considerevole rispetto alla dimensione della corsia e delle distanze in gioco tra strade. Ad esempio, già così si è sicuri che verranno rilevati anche eventi dei veicoli che viaggiano sulla corsia di marcia opposta e quindi si dovrà considerare la direzione di moto valutando i punti degli eventi ENTER e EXIT.
Nella documentazione di Android, si indica che le migliori performance si ottengono con raggi di 100-150 m. Chiaramente se fosse così non sarebbe possibile usare i geofence nell’ambito veicolare perché in un raggio di 100 m passano parecchie strade e quindi non sarebbe più comprensibile su quale strada sta viaggiano il veicolo!
In realtà si fa riferimento alle migliori performance per il risparmio della batteria per cui, se ci fosse la presenza del WiFi, si potrebbe applicare il geofence con ugual successo, senza consumare risorse per il GPS. Nel caso veicolare, invece, le dimensioni delle strade impongono che il GPS sia necessariamente attivo.
Ottimizzazione estrema: caso di un epic fail
Nel corso di un test è capitato di osservare un comportamento anomalo spiegabile solamente con un’ottimizzazione nell’uso del GPS che ha però causato di fatto un malfunzionamento dell’applicazione.
Il test in questione era quello di rilevare il passaggio per un tratto autostradale da casello a casello. Il tester percorreva un tratto di autostrada uscendo ad un casello per controllare le applicazioni e poi rientrava per percorrere il tratto successivo. È stato notato che se il tempo di sosta all’uscita dei caselli superava il tempo di 5 minuti, al rientro era più che probabile che il GPS non fosse in funzione in quanto le letture riprendevano con un notevole ritardo.
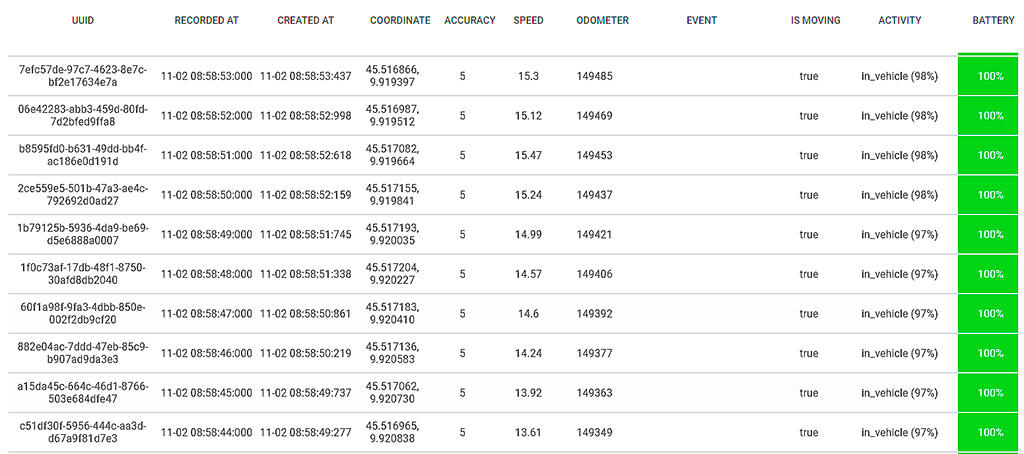
In figura 4 si riporta uno di questi casi. All’uscita del primo casello, sulla destra della figura, il tester opera una sosta che viene rappresentata da un cerchio rosso. La lettura successiva riprende quando il tester si trova già sulla rampa di uscita del casello seguente, vale a dire 10 minuti dopo!
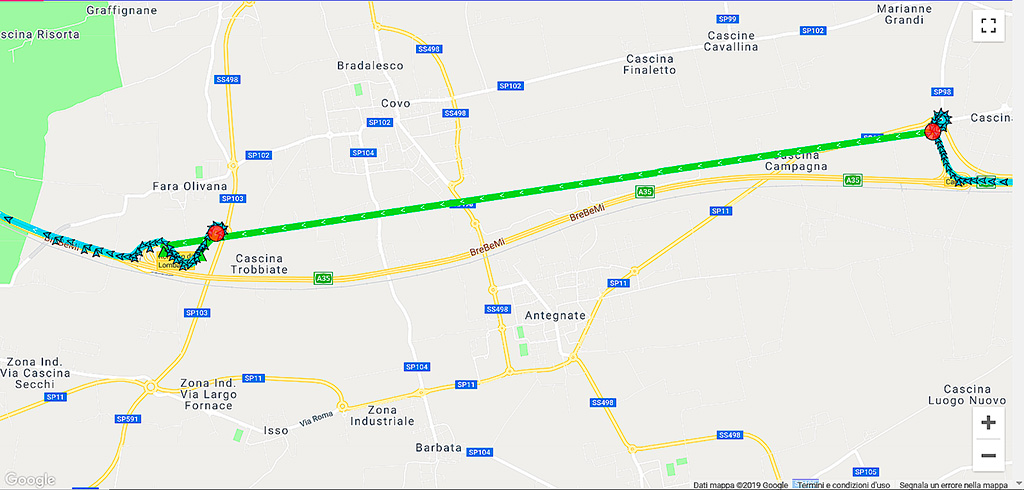
Dai dati puntuali mostrati in figura 5 si nota che viene evidenziata l’informazione motionchange proprio in corrispondenza dell’evento. Ma cosa vuol dire? In pratica, viene fatto uso di altri sensori per determinare lo stato di moto del dispositivo in modo da applicare delle ottimizzazioni. In questo caso, da una condizione still (fermo) si passa a una condizione in_vehicle (movimento tramite veicolo) che vengono determinati non dal rilevamento di posizione, ma dall’accelerometro e dalla bussola.
Si suppone quindi che, fintantoché questi sensori non hanno aggiornato lo stato di moto, il GPS sia rimasto “spento” per ragioni di ottimizzazione. Il guaio che si è venuto a creare è che l’aggiornamento dello stato di moto è avvenuto con notevole ritardo rispetto alla realtà, facendo perdere all’applicazione la rilevazione del passaggio di un obiettivo.
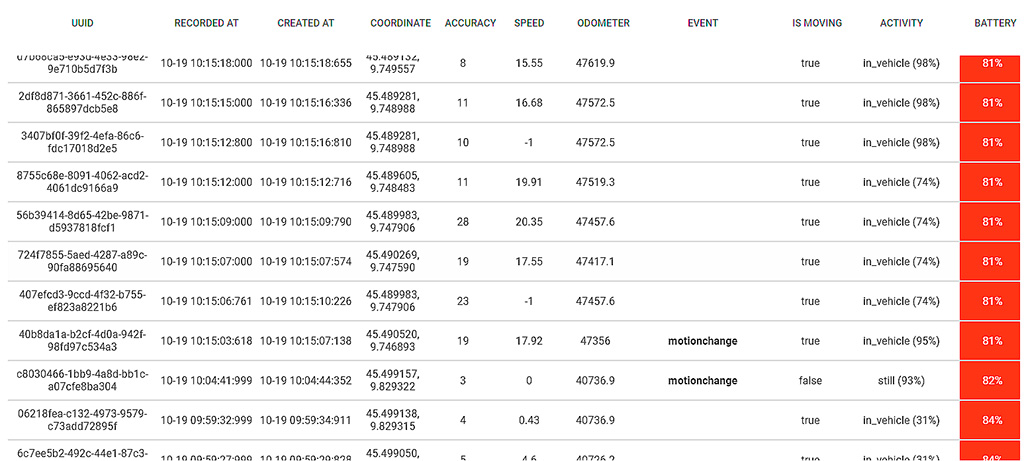
Dai dati si nota inoltre che, dopo che le misure sono riprese, per un certo periodo di tempo il GPS ha fornito letture poco precise; si notino i valori di accuracy molto alti e speed negativi. Tutto questo fa pensare che il tempo di inattività del GPS gli abbia fatto perdere la sincronizzazione con i satelliti.
Politiche repressive di Android verso le applicazioni in background
Dalle ultime versioni, Android sta applicando sempre di più delle politiche di gestione delle applicazioni in background notevolmente repressive. Di fatto quello che accade è che il sistema operativo può decidere, senza nessuna notifica o avviso all’utente, di terminare un’applicazione in background.
Questa operazione viene svolta sempre per risparmiare batteria a favore dell’utente che può impiegarla per applicazioni più importanti. Tuttavia, così facendo, si rischia che una applicazione altrettanto importante venga chiusa solo perché in background.
A complicare le cose si aggiunge il fatto che le politiche di gestione delle applicazioni in background sono spesso reimplementate dai produttori di dispositivi, per cui una stessa applicazione potrebbe essere trattata in maniera diversa in base alla marca del dispositivo.
E gli sviluppatori non possono farci nulla, perché non è prevista nessuna funzionalità applicativa che faccia capire ad Android il tipo di importanza dell’applicazione stessa. Direi che questo è anche logico, perché una applicazione sviluppata con cattive intenzioni “mentirebbe” pur di non venire terminata.
L’unica possibilità è che l’utente operi manualmente una configurazione da pannello di controllo inserendo esplicitamente l’applicazione tra quelle che non devono risentire delle strategie di ottimizzazione della batteria.
Poiché ci sono molti produttori che reimplementano questa funzionalità, la configurazione da applicare sarà diversa in base alla versione di Android e alla marca del dispositivo. Questo diventa motivo di fastidio per l’utente ma anche per i progettisti che debbono poi trovare un modo a prova di “utonto” di spiegare come eseguire l’eventuale configurazione con tutte queste varianti in gioco.
Conclusioni
In questo ultimo articolo della serie abbiamo presentato un insieme di suggerimenti e trucchi comprovati per il migliore utilizzo dei paradigmi e delle API di cui si era parlano nell’articolo precedente. Abbiamo mostrato delle possibilità assodate per raggiungere l’obiettivo senza spendere tantissime risorse andando per “tentativi”.
Gli esempi e i casi riportati nell’articolo non possono e non vogliono essere esaustivi, tuttavia sono risultati essere casi notevoli alla base delle considerazioni per lo sviluppo di un’applicazione utilizzata ormai da migliaia di utenti.
Ivano Tagliapietra è un professionista nel mondo dell'IT da oltre 20 anni. Ha lavorato prima come dipendente per grandi compagnie per dedicarsi poi alla libera professione.
L'interesse per la tecnologia e l'evoluzione dell'informatica lo ha sempre spinto a cercare soluzioni innovative nella progettazione dei sistemi informativi, mantenendo però sempre salda la modalità di operare con concretezza per raggiungere con efficienza il risultato desiderato.
Per questo motivo di continuo sperimenta, collabora e cerca di fare network con diverse altre realtà del mondo dell'IT e non solo (professionisti, piccole e grandi imprese) per incubare nuove idee da realizzare e portare innovazione nei settori ormai tradizionali dell'informatica (dal web alle app).
Ultimamente si è interessato particolarmente alle evoluzioni nel mondo della smart mobility e collabora con importanti gruppi (in particolare Fincons Group), enti e startup.
Per passione, sulla base di tali esperienze, si è dedicato anche all'attività di articolista e recensore fin dagli anni Duemila.