

Chaos Engineering in pratica
La prima cosa da fare per iniziare ad applicare Chaos Engineering è la definizione di un esperimento, che potrà poi essere eseguito manualmente, oppure eseguito automaticamente tramite un tool.
Il passo successivo è la scelta dell’ambiente in cui eseguire l’esperimento: SandBox/Staging oppure Produzione?
Se si considera di eseguire l’esperimento in produzione, è buona norma limitare il più possibile il suo effetto, il cosiddetto Blast Radius, in modo da evitare di causare un vero e proprio incidente di produzione.
L’alternativa è quella di iniziare con un piccolo esperimento e con un piccolo Blast Radius in un luogo più sicuro, ad esempio in Staging, e poi far crescere il suo Blast Radius fino a quando non si è certi che l’esperimento non abbia trovato punti deboli in quell’ambiente.
Ovviamente, eseguendo l’esperimento — che si tratti di Game Day oppure di esperimento automatico — in un ambiente protetto si ha il vantaggio di non interrompere la funzionalità del nostro sistema in produzione, e quindi non rischiamo di lasciare i nostri utenti nella situazione spiacevole di non poterlo utilizzare; ma si ha lo svantaggio di non scoprire prove reali delle eventuali debolezze presenti in produzione.
Osservabilità
L’osservabilità è la capacità di un sistema in esecuzione di essere debuggato. La capacità di comprendere, interrogare, sondare e porre domande a un sistema mentre è in esecuzione è il cuore di questa debuggability.
Chaos Engineering incoraggia e si affida all’osservabilità del sistema in modo da poter rilevare le prove delle reazioni del sistema alle condizioni turbolente dei nostri esperimenti. Anche se non si dispone di una buona osservabilità del sistema quando si inizia ad adottare Chaos Engineering, si vedrà rapidamente il valore e la necessità di “debuggabilità” del sistema in produzione.
Quindi l’ingegneria del caos e l’osservabilità vanno spesso di pari passo, essendo l’ingegnere del caos uno dei fattori che costringono a migliorare l’osservabilità del sistema. La domanda cruciale che ci dobbiamo porre è “Cosa vogliamo imparare?”
L’obiettivo di Chaos Engineering è quello di aiutarvi a costruire la fiducia e la sicurezza nel modo in cui l’intero sistema sociotecnico si comporterà in condizioni di turbolenza. Quindi, prima di scatenare Chaos Monkey in produzione, ricordiamoci che l’obiettivo è imparare dal nostro esperimento di chaos, il che significa che abbiamo bisogno di molto più di un semplice “Facciamo qualcosa di strano” o “Blocchiamo qualche servizio”.
Per un vero esperimento è fondamentale seguire il metodo scientifico. La domanda giusta da porci dovrebbe essere “Dove sarebbe più utile creare un esperimento che ci aiuti a costruire fiducia e sicurezza nel nostro sistema in condizioni di turbolenza?”.
Chaos Engineering Loop
Se osserviamo il ciclo del Chaos Engineering ci accorgiamo di quanto sia simile al metodo scientifico, a dimostrazione, come già detto, che non si tratta semplicemente di lasciare libera la scimmia nella nostra sala server e vedere cosa succede al nostro sistema, ma piuttosto di un metodo rigoroso.
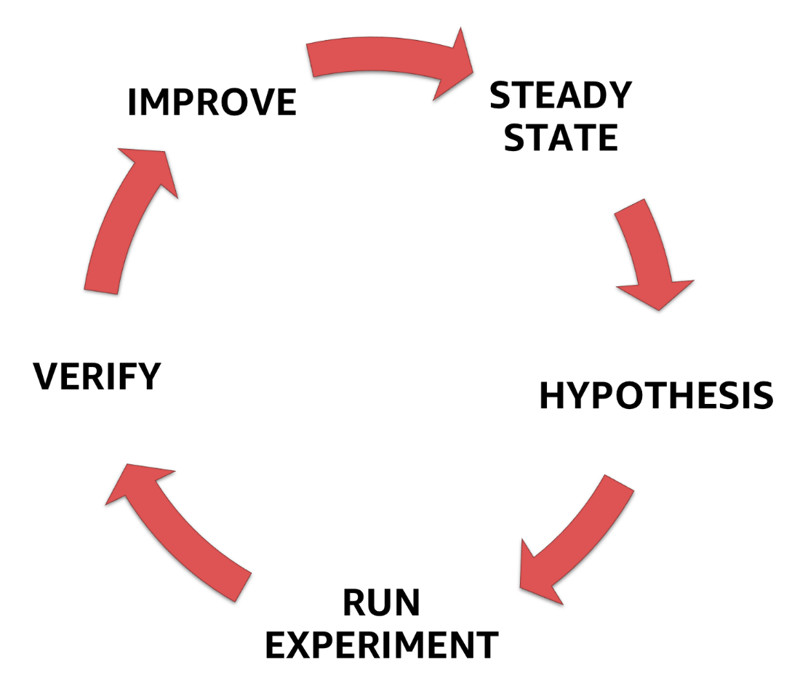
Proviamo ad analizzare i passi di questo ciclo.
Steady State
Secondo la definizione, è il modello che caratterizza lo stato stazionario del sistema basato sui valori attesi dalle metriche di business. Va precisato che questa definizione dev’essere limitata alla porzione di sistema che sarà oggetto del Chaos Engineering. Un po’ come se stessimo facendo Unit Test su una porzione di codice… non su tutta la solution.
Hypothesis
Affinché il processo sia rigoroso, è fondamentale avere delle ipotesi da verificare. L’obiettivo dell’esperimento di Chaos Engineering è quello di confutare i nostri sospetti e fornirci nuove conoscenze sulle debolezze del nostro sistema.
Run Experiment
Lo ripeto un’altra volta: affinché sia efficace, e non distruttivo, l’esperimento deve avere un raggio d’esplosione (Blast Radius) contenuto. Lo allargheremo ad ogni ciclo, se sarà necessario e soprattutto dopo aver verificato che il sistema regge alle prime turbolenze.
Verify
Come ogni esperimento che si rispetti, al termine dello stesso verifichiamo se le ipotesi iniziali sono dimostrate; a tal proposito, avremo avuto successo se l’esperimento troverà dei malfunzionamenti dovuti alle turbolenze iniettate. In caso contrario, al prossimo giro, non faremo altro che allargare il Blast Radius.
Improve
Quando una nuova debolezza emerge da un esperimento di Chaos Engineering, spesso comporta una buona dose di carico di lavoro per tutto il team. La priorità ora infatti sarà quella di colmare le debolezze del sistema affinché possa resistere alle turbolenze iniettate che, ricordo, erano parte delle ipotesi iniziali.
E poi… e poi si ricomincia, come in ogni loop che si rispetti.
A supporto del fatto che si tratta di un metodo rigoroso, è fondamentale capire che l’unica possibilità che abbiamo per preparare delle ipotesi sensate, è quella di osservare attentamente il nostro sistema all’opera in ambiente di produzione. Solo dall’osservazione, che possiamo fare con i soliti metodi a disposizione, per esempio loggando quanto necessario, potremmo partire con i nostri esperimenti.
Ma come si eseguono realmente gli esperimenti? Manualmente, oppure esistono tool per automatizzarli?
Game Day
Nel 2000, Jesse Robbins, “Master of Disaster” in Amazon, ha creato e condotto Game Day, un programma ispirato alla sua esperienza di vigile del fuoco. Il Game Day è stato progettato per testare, addestrare e preparare i sistemi, le applicazioni e le persone di Amazon, a rispondere a un disastro.
Inizialmente il Game Day è iniziato con una serie di annunci a livello aziendale: si comunicava che si sarebbe svolta un’esercitazione, a volte grande quanto la distruzione di un centro dati in scala reale. Sono stati forniti pochi dettagli sull’esercitazione e il team ha avuto solo pochi mesi per prepararsi. Il punto focale era di assicurarsi che i singoli punti di fallimento regionali venissero affrontati ed eliminati.
Durante queste esercitazioni sono stati utilizzati strumenti e processi come il monitoraggio, gli allarmi e le chiamate di emergenza per testare ed esporre i flussi nelle capacità standard di risposta agli incidenti. Il Game Day è diventato davvero un ottimo metodo per esporre i classici difetti architetturali, ma a volte esponeva anche i cosiddetti “difetti latenti”, problemi che appaiono solo a causa del guasto che si è innescato. Ad esempio, i sistemi di gestione degli incidenti critici per il processo di recupero falliscono a causa delle dipendenze sconosciute del guasto iniettato.
Con la crescita dell’azienda è cresciuto anche il raggio di esplosione del Game Day, e queste esercitazioni sono state alla fine interrotte poiché l’impatto potenziale sui clienti dei siti web di vendita al dettaglio è diventato troppo grande. Queste esercitazioni si sono poi evolute in diversi esperimenti “a compartimenti stagni”, con l’intento di esercitare le modalità di guasto senza causare alcun impatto sui clienti.
Esperimenti automatizzati
È possibile automatizzare un esperimento utilizzando ad esempio il Chaos Toolkit [1]. Ma perché dovremmo automatizzare un esperimento di Chaos Engineering? Automatizzare gli esperimenti ci consente di esplorare il nostro sistema alla ricerca di debolezze in ogni istante. Oltre a Chaos Toolkit esistono ovviamente altri tool di automazione, a partire a Chaos Monkey for Spring Boot [2].
Chaos Toolkit è open source, ha un largo “ecosistema” di estensioni ed è free… il che non guasta mai. È facile da configurare, grazie all’utilizzo di file YAML o JSON.
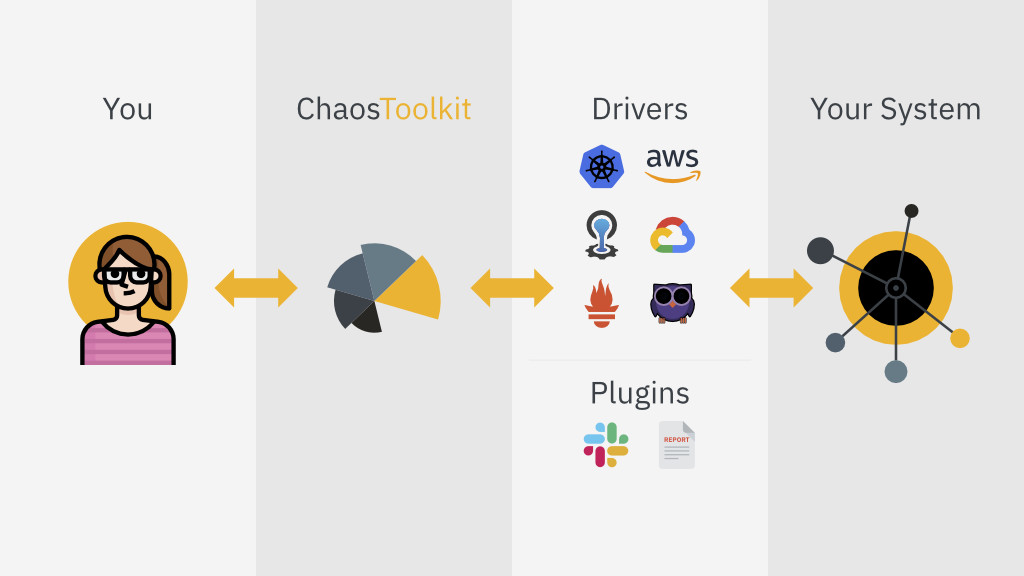
Utilizzare Chaos Toolkit
Sul sito di riferimento trovate una documentazione dettagliata di come utilizzarlo e, soprattutto, un semplice esperimento di test per cominciare a “sporcarsi le mani”.
Vi consiglio di prepararei una macchina Linux based: personalmente, mi sono creato una macchina virtuale Ubuntu. Il passo successivo è l’installazione di Python 3: purtroppo o per fortuna, Python è il linguaggio di riferimento per questo tool. Infine, installate la CLI di Chaos Toolkit. Al termine dell’installazione avrete a disposizione una nuova serie di comandi con cui giocare e sperimentare.
Il file di configurazione JSON
Proviamo ad analizzare il file di configurazione, in formato JSON, necessario al tool per funzionare.
{
"title": "What are you looking for?",
"description": "How works our system, and what could be a weakness of his?",
"tags": [
"tutorial",
"filesystem"
],
"steady-state-hypothesis": {
"title": "The exchange file must exist",
"probes": [
{
"type": "probe",
"name": "service-is-unavailable",
"tolerance": [200, 503],
"provider": {
"type": "http",
"url": "http://localhost:8080/"
}
}
]
},
"method": [
{
"name": "move-exchange-file",
"type": "action",
"provider": {
"type": "python",
"module": "os",
"func": "rename",
"arguments": {
"src": "./exchange.dat",
"dst": "./exchange.dat.old"
}
}
}
]
}
Vediamolo in dettaglio:
{
"title": "What are you looking for?",
"description": "How works our system, and what could be a weakness of his?",
"tags": [
"tutorial",
"filesystem"
],
È fondamentale, per un esperimento che si rispetti, il titolo che ci indica lo scopo dello stesso, ossia “Cosa vogliamo indagare del nostro sistema?”.
"steady-state-hypothesis": {
"title": "The exchange file must exist",
"probes": [
{
"type": "probe",
"name": "service-is-unavailable",
"tolerance": [200, 503],
"provider": {
"type": "http",
"url": "http://localhost:8080/"
}
}
]
},
In questa sezione sono indicate le condizioni di business per cui il nostro sistema è ritenuto stabile. Come già anticipato in precedenza queste ipotesi si riferiscono alla porzione di sistema che stiamo processando, non a tutto il sistema. Dobbiamo limitare il raggio d’azione dell’esperimento per due ragioni: imparare il più possibile, isolando il resto del mondo, e limitare eventuali danni al processo in produzione.
Se il processo passa questa sezione, e ritiene dunque il sistema stabile, è possibile passare oltre, altrimenti verrà interrotto l’esperimento.
"method": [
{
"name": "move-exchange-file",
"type": "action",
"provider": {
"type": "python",
"module": "os",
"func": "rename",
"arguments": {
"src": "./exchange.dat",
"dst": "./exchange.dat.old"
}
}
}
]
Nell’ultima sezione del file troviamo le parti attive dell’esperimento, ossia le azioni che vogliamo compiere, le turbolenze che intendiamo iniettare, per testare la stabilità del nostro sistema, o per imparare qualcosa di nuovo, ossia scoprire che c’è una debolezza.
Lo svolgimento del processo
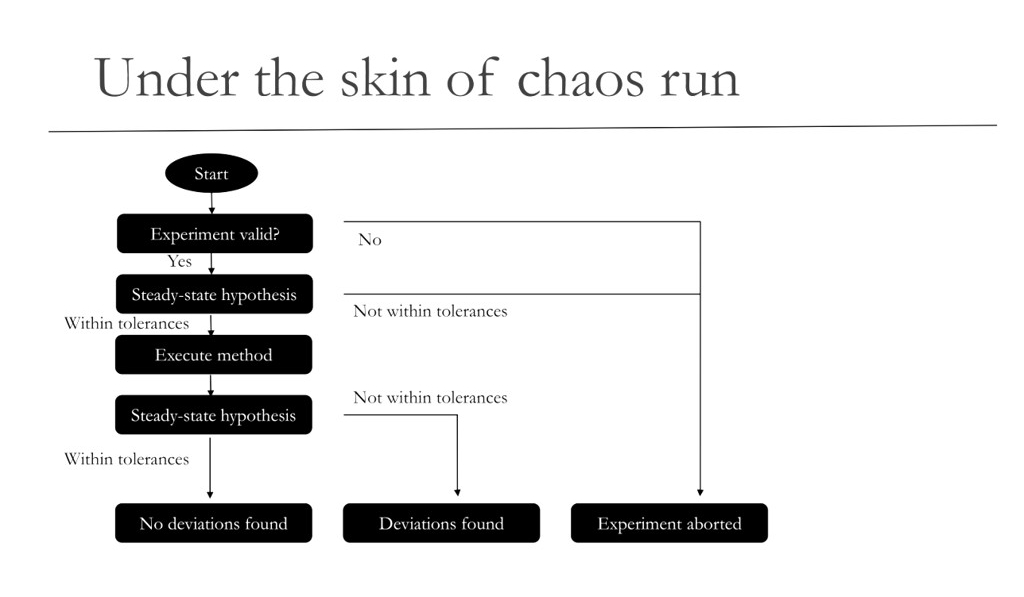
Una volta preparato il file JSON del nostro esperimento è possibile avviare il tutto da linea di comando grazie ai nuovi comandi messi a disposizione dal tool:
run experiment.json
Il processo inizia verificando che il file sia valido, e solo se lo è ovviamente procede.
- Il primo vero step è la verifica delle ipotesi steady-state; se sono confermate, si procede; altrimenti, non ha alcun senso condurre un esperimento su un sistema già di per sé instabile.
- Vengono eseguiti i metodi indicati, ossia vengono iniettate le turbolenze nel nostro sistema.
- A questo punto è necessario verificare nuovamente se il sistema è ancora in uno stato stabile, oppure no.
- Se il sistema è ancora stabile possiamo allargare il raggio d’azione dell’esperimento e osare un po’ di più. In caso contrario possiamo esultare: siamo contenti di aver trovato un punto debole del nostro sistema, che dovrà essere colmato il prima possibile, e poi potremo ripetere l’esperimento e verificare l’efficacia del nostro intervento, il che ci permetterà di allargare il raggio d’azione alla scoperta di altre debolezze.
Conclusioni
Dopo questa breve introduzione al mondo di Chaos Engineering quali conclusioni possiamo trarre? Possiamo affermare con relativa certezza che Chaos Engineering offre alcuni benefici.
Anzitutto, ci aiuta a scoprire le debolezze nascoste del nostro sistema, in gergo Dark Debt, e ci permette quindi di apportare le necessarie modifiche prima che siano i nostri utenti a scoprirle e il nostro capo ci svegli alle 3 del mattino chiedendoci di risolvere il prima possibile… e questo è già di per sé un gran risultato.
Poi, un esperimento di Chaos Engineering genera sempre più cambiamenti del previsto, soprattutto culturali. Probabilmente il più importante è una naturale evoluzione verso la trasformazione da “Perché lo hai fatto?” a “Come possiamo evitare di ripeterlo in futuro?”. Il risultato di questa trasformazione è un team più felice, e tutti gli agilisti sanno bene che un team felice è un team più potente, più efficiente che genera maggior successo… Se questo è poco!
Infine, come ha sottolineato recentemente Casey Rosenthal un pionere del Chaos Engineering, i tool sono importanti, e ci aiutano a lavorare meglio, ma non dimentichiamoci che sono le persone il vero valore del nostro sistema.
Sono fondamentalmente un eterno curioso. Mi definisco da sempre uno sviluppatore backend, ma non disdegno curiosare anche dall'altro lato del codice. Mi piace pensare che "scrivere" software sia principalmente risolvere problemi di business e fornire valore al cliente, e in questo trovo che i pattern del DDD siano un grande aiuto. Lavoro come Software Engineer presso intré, un'azienda che sposa questa ideologia; da buon introverso trovo difficoltoso uscire allo scoperto, ma mi piace uscire dalla mia comfort-zone per condividere con gli altri le cose che ho imparato, per poter trovare ogni volta i giusti stimoli a continuare a migliorare.
Mi piace frequentare il mondo delle community, contribuendo, quando posso, con proposte attive. Sono co-founder della community DDD Open e Polenta e Deploy, e membro attivo di altre community come Blazor Developer Italiani.