

Introduzione
Negli scorsi articoli abbiamo parlato di come i comuni approcci alle stime (per esempio, story point) spesso falliscono nel darci la prevedibilità che cerchiamo, e abbiamo poi visto come utilizzare la metrica Lead Time per fare previsioni e per migliorare le nostre conversazioni.
In questo articolo spieghiamo come rispondere a un’altra serie di domande utilizzando le metriche Throughput e Story Health, con molti esempi pratici di conversazioni che la maggior parte dei team si trova spesso ad affrontare.
Metrica: Throughput
Dopo essere andati nel dettaglio di come utilizzare il Lead Time nello scorso articolo, ci concentriamo ora su una nuova metrica: Throughput. Come nel caso del Lead Time, ne abbiamo già parlato su queste pagine [1] qualche anno fa, ma ne scriviamo qui un riassunto per poi vedere come questa metrica ci aiuti a fare previsioni e rispondere a numerose domande di business. Per cominciare, chiariamo cosa si intende con “throughput”.
Throughput: definizione
Il Throughput — spesso chiamato anche “Delivery Rate” o “Story Count” — rappresenta il numero di storie completate in un particolare periodo di tempo. Nella maggior parte dei team, il periodo di tempo coincide con lo Sprint, o riguarda un periodo di una/due settimane.
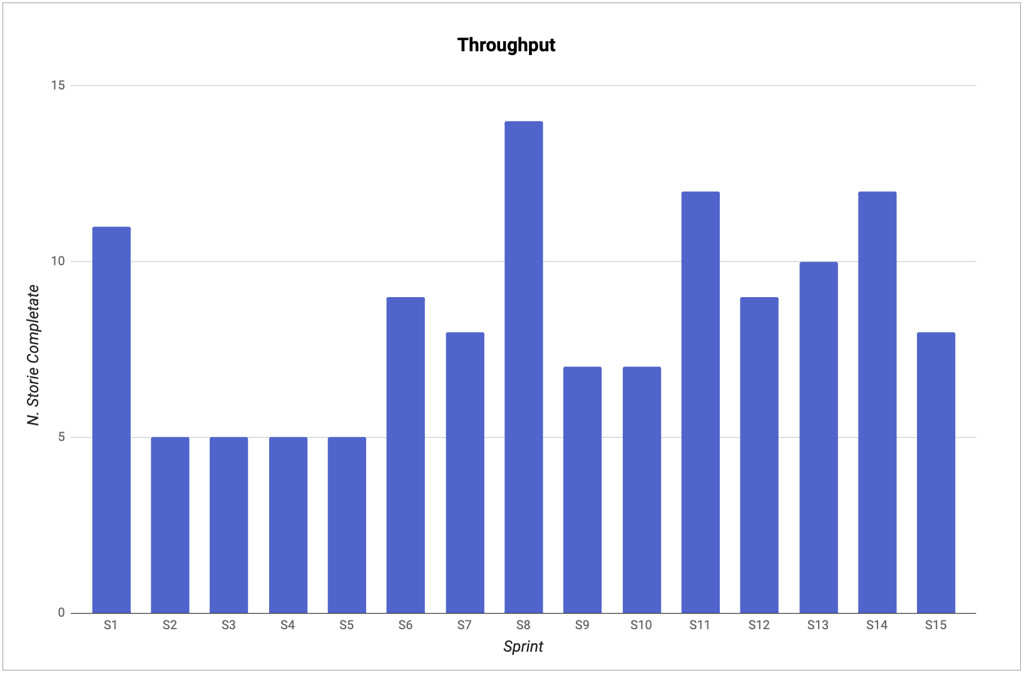
Nella figura in esempio, il team ha completato 11 storie nello Sprint 1, 5 storie negli Sprint 2–5, 9 storie nello Sprint 6, e così via. È una metrica semplicissima da calcolare ma, come vedremo, è estremamente utile per rispondere a numerose domande di business.
Usando i dati del Throughput possiamo calcolare alcune statistiche che ci aiutano a fare previsioni: media, mediana, minimo, massimo, e alcuni percentili.
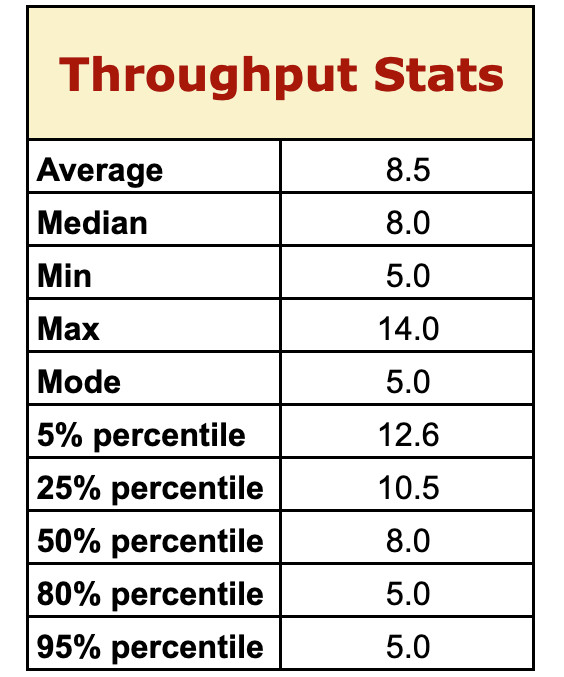
Senza perderci nei dettagli matematici, vediamo come utilizzare queste statistiche in esempi pratici di conversazioni. Per aiutarvi a mettere in pratica quanto stiamo descrivendo, potete usare come esempio gli spreadsheet disponibili al link [3].
“Quante storie possiamo completare nel prossimo Sprint?”
È una domanda tipica che i team si trovano spesso ad affrontare. Per i team che fanno Scrum, è una discussione che avviene ad ogni Sprint Planning, quando stiamo pianificando il prossimo Sprint. Per chi invece fa Kanban, durante il Queue Replenishment ci viene comunque chiesto “Quante storie possiamo completare nel prossimo periodo, p.e. nella prossima settimana? Di quante storie dobbiamo fare pull?”.
Interrogare i dati
Per rispondere, andiamo a vedere cosa ci dicono i nostri dati, osservando in particolare le due righe evidenziate in rosso in figura 3.
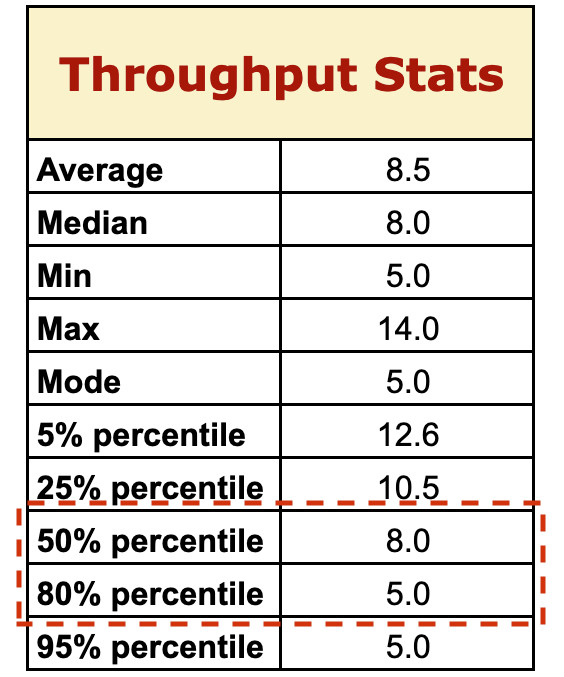
La riga dell’80esimo percentile ci dice che, in passato, nell’80% degli Sprint il team ha completato almeno 5 storie. Il 50esimo percentile invece ci dice che, nel 50% degli Sprint, il team è arrivato a completare fino a 8 storie.
La conversazione che ne deriva
Usiamo questi dati per rispondere nel modo seguente: “Abbiamo l’80% di sicurezza che possiamo completare almeno 5 storie. Potremmo arrivare fino a 8 storie, ma c’è solo il 50% di possibilità. Possiamo quindi esprimere un forte commitment per le prime 5 storie e metterle nello Sprint, ma vogliamo assumerci il rischio di aggiungere 3 ulteriori storie? Se le mettiamo in Sprint e poi non le completiamo, qual è l’impatto? Possiamo decidere di metterle nello Sprint, ma non farei alcuna promessa su queste 3 storie in più”.

In questa situazione, personalmente preferirei selezionare solo 5 storie. Quando poi il team le completa e ha bisogno di altro lavoro, possiamo facilmente tirare dentro altre storie (che nel frattempo potrebbero aver cambiato priorità). In questo modo aiutiamo il team a mantenere un basso WIP limit, lavorare in “small batches”.
Ricordiamo che, come descritto nel primo articolo di questa serie, non occorre che ogni storia abbia la stessa dimensione. Fintanto che il team fa slicing delle storie per renderle il più piccolo possibile e resta uniforme e coerente nei criteri con cui spezza il lavoro, ci sarà una naturale variazione nella dimensione delle storie, ma questa variazione viene automaticamente tenuta in considerazione dal fatto che utilizziamo dati storici per fare previsioni.
“Quali storie possiamo completare nelle prossime 2 settimane?”
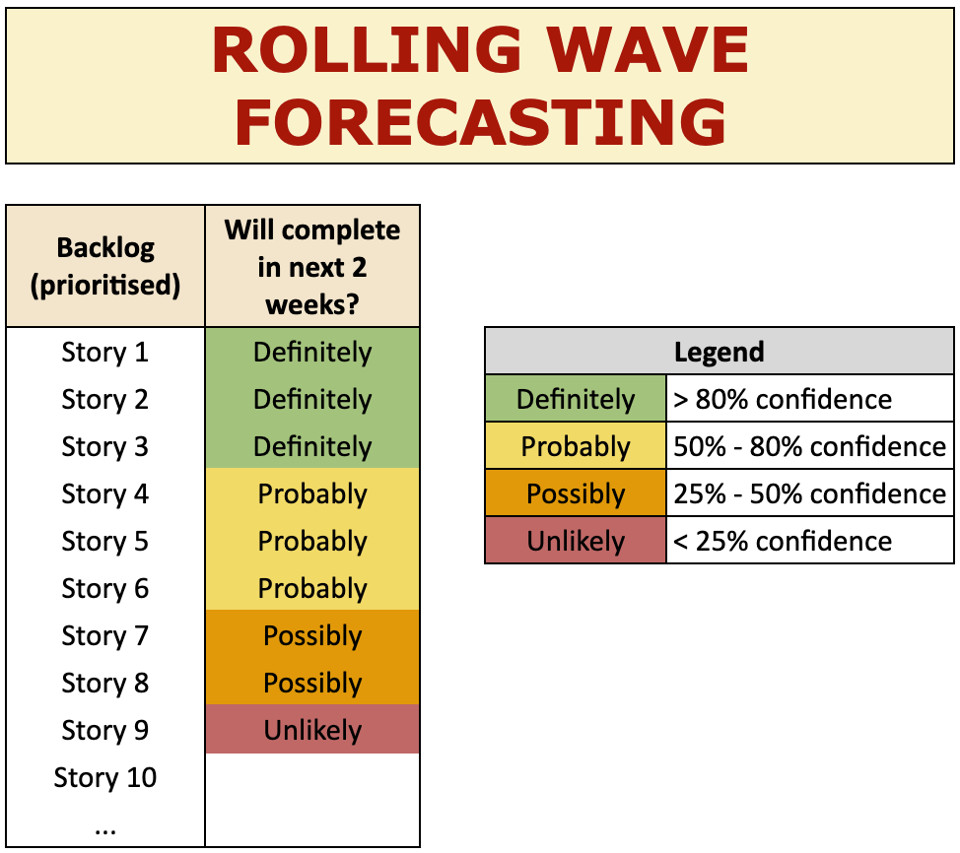
Una volta che abbiamo risposto alla domanda “Quante storie” possiamo completare, sorge spontaneo continuare con “Quali storie” possiamo completare? Rispondiamo usando una tecnica chiamata Rolling Wave Forecasting [4], estremamente utile per visualizzare questo tipo di previsione.
Livelli di sicurezza
Assumendo che abbiamo un backlog con storie in ordine di priorità, visualizziamo al fianco di ogni storia il livello di sicurezza che tale storia sia completata entro le prossime due settimane. Nella figura 5, stiamo dicendo che entro le prossime due settimane:
- Quasi certamente completeremo le prime 3 storie in verde (sicurezza >80%). Ci sentiamo molto sicuri, possiamo esprimere un forte commitment per queste storie.
- Probabilmente completeremo qualcuna delle storie 4, 5, e 6 in giallo (sicurezza tra 50% e 80%). Non farei promesse su queste.
- Possibilmente completeremo le storie 7 e 8 in arancione (sicurezza tra 25% e 50%). Contare sul loro completamento comporta un alto rischio.
- È improbabile che arriveremo a completare la storia 9, in rosso (sicurezza tra 25%).
Questi livelli di sicurezza sono presi dai percentili che abbiamo calcolato nelle nostre statistiche sul throughput, e sono quindi basati su quante storie abbiamo completato in un singolo Sprint in passato.
Un quadro più chiaro
Questo tipo di visualizzazione è estremamente utile per i nostri stakeholder, o i nostri Product Owner: in qualunque momento possono vedere cosa si possono aspettare di ricevere nelle prossime due settimane, e possono riordinare il backlog in base a quanto vogliono sentirsi sicuri che una particolare storia sia completata o meno.
“Possiamo completare N storie nel prossimo Sprint?”
Altro caso piuttosto comune: qualcuno — un Product Owner, un manager, o una figura simile — vuole che il team completi una certa quantità di lavoro, e per esempio chiede: “Queste 10 storie sono molto importanti; possiamo completarle nel prossimo Sprint?”.
I dati raccontano
Ancora una volta, prendiamo in mano i nostri dati per rispondere:
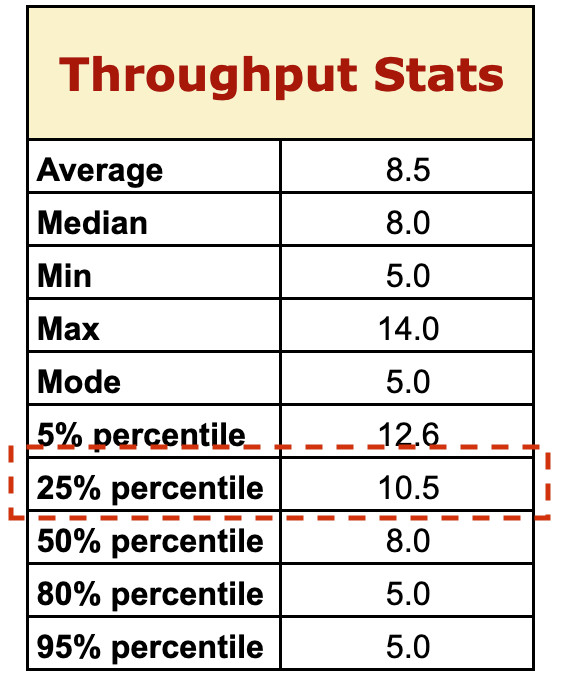
I nostri dati storici ci dicono che, in passato, il team ha completato 10 storie solo nel 25% degli Sprint. Rispondiamo quindi come segue: “Se accettiamo le 10 storie, abbiamo solo una possibilità su quattro di completarle in tempo. Vogliamo assumerci questo rischio? Qual è l’impatto se diciamo di sì e poi non le finiamo? Stiamo facendo qualche promessa a qualcuno, o è solo un commitment interno?”.

Voglio sottolineare come, in situazioni di questo tipo, è comune per il team di sentirsi sotto pressione e dire di sì, finendo poi a fare straordinari o prendere scorciatoie pericolose per finire in tempo. Purtroppo in molte aziende vige ancora una cultura dove, quando il capo vuole qualcosa, bisogna dire di sì. Avendo dati a disposizione, invece, è molto più facile resistere alla pressione e parlare dei possibili scenari, creando aspettative realistiche.
“Quanto tempo impiegherà questo progetto?” (risposta breve)
Quando analizziamo un progetto o un gruppo di storie, molto presto arriva la domanda “Quanto tempo ci vuole?”. Se abbiamo bisogno di precisione, e soprattutto se vogliamo gestire i rischi del progetto, allora per rispondere dovremmo usare Probabilistic Forecasting, di cui abbiamo parlato in un vecchio articolo [5] e che approfondiremo nel prossimo numero.
Tuttavia, ci sono scenari in cui una risposta approssimativa è sufficiente. In queste situazioni, possiamo usare la media del Throughput per tracciare un veloce burn-up chart e darci un’idea di quanto potrebbe volerci:
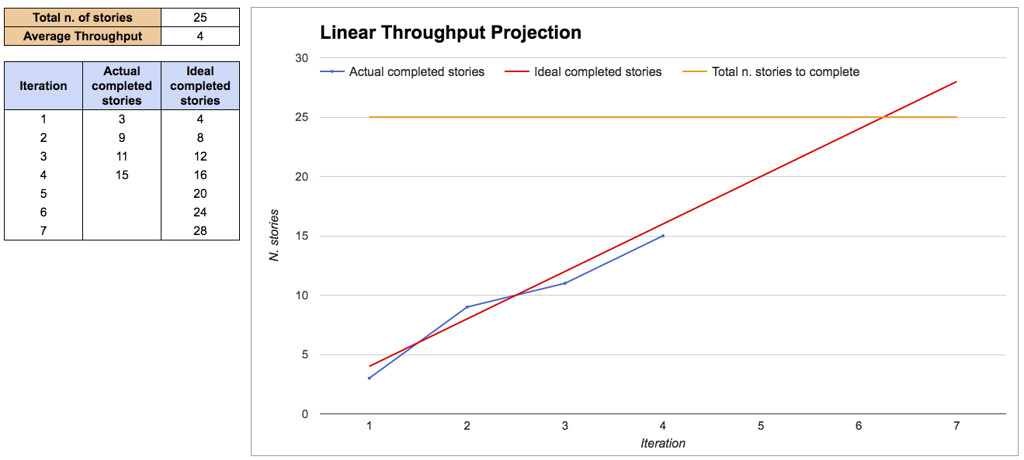
Attenzione al fatto che usare la media per fare previsioni è molto pericoloso: come spiega la “Flaw of Averages” [6], la realtà può deviare molto dalla media, con picchi che nascondono rischi. Ma se ci accontentiamo di una risposta veloce senza troppe pretese, allora questa proiezione potrebbe bastare.
La conversazione
Ecco un esempio di conversazione reale avvenuta con uno dei miei team. Il team stava discutendo una nuova funzionalità per supportare il lancio di un nuovo prodotto. Il Product Owner aveva presentato il problema, e insieme avevamo discusso alcune possibili soluzioni, arrivando a sceglierne una che avevamo poi spezzato in storie.
A quel punto, il PO chiese la classica domanda: “OK, quanto tempo ci vuole?”. Andai a prendere i dati del team, che tenevamo stampati di fianco alla nostra Kanban board e, indicando le statistiche del Throughput risposi: “Vediamo. Abbiamo appena spezzato il lavoro in 10 storie, e in media il team completa circa 3 o 4 storie per Sprint. A occhio e croce, ci vorranno 3 o 4 Sprint. Ti basta come risposta? Altrimenti se mi dai dieci minuti creo un nuovo forecasting spreadsheet e ti faccio una previsione più accurata.”
Il PO rispose: “No non preoccuparti, è abbastanza. Volevo solo capire se saremo pronti in tempo per il lancio del nuovo prodotto tra 6 Sprint. Direi che siamo a posto”. Il meeting terminò in meno di un’ora, e il team si mise subito al lavoro sulla nuova funzionalità.
Metrica: Story Health
Oltre al Throughput, un’altra metrica che possiamo usare a nostro vantaggio è rappresentata dalla cosiddetta Story Health. Di che cosa si tratta? Si tratta di una metrica legata ai dati già utilizzati quando ci siamo occupati di Lead Time. Vediamo di seguito la questione in dettaglio.
Story Health: definizione
Torniamo per un attimo al Lead Time, che abbiamo discusso nell’articolo precedente. Possiamo utilizzare quegli stessi dati per osservare lo stato di salute delle storie attualmente in corso. Nota: alcuni tool chiamano questa metrica “Aging WIP”, o “età del work in progress”, ma si tratta dello stesso concetto.
Per ogni storia che è stata iniziata ma che non è ancora completata, osserviamo da quanti giorni è in corso. Usiamo poi alcuni percentili della nostra Lead Time Distribution per deciderne lo stato di salute, per esempio:
- 0-50%. Finché la storia è in corso da meno di 4 giorni, la consideriamo verde: è tutto OK. La metà delle storie impiega tale tempi e quindi è normale.
- 50-80%. Tra i 4 e 9 giorni la storia diventa gialla perché sta iniziando a impiegare più del solito. Ci chiediamo: “Va tutto bene? Ci sono impedimenti? Vale la pena fare swarming e avere un ulteriore paio di persone sulla storia per aiutare?”.
- 80-90%. Tra i 9 e 10 giorni la storia è rossa: non è normale che impieghi così a lungo. Forse c’è qualche problema che necessita escalation? Forse lo scope era troppo grande e va spezzata? Diamo priorità a risolvere questi problemi e a completare la storia.
- 90-100%. Oltre i 10 giorni la storia è nera: la consideriamo un’emergenza che va risolta con massima priorità.
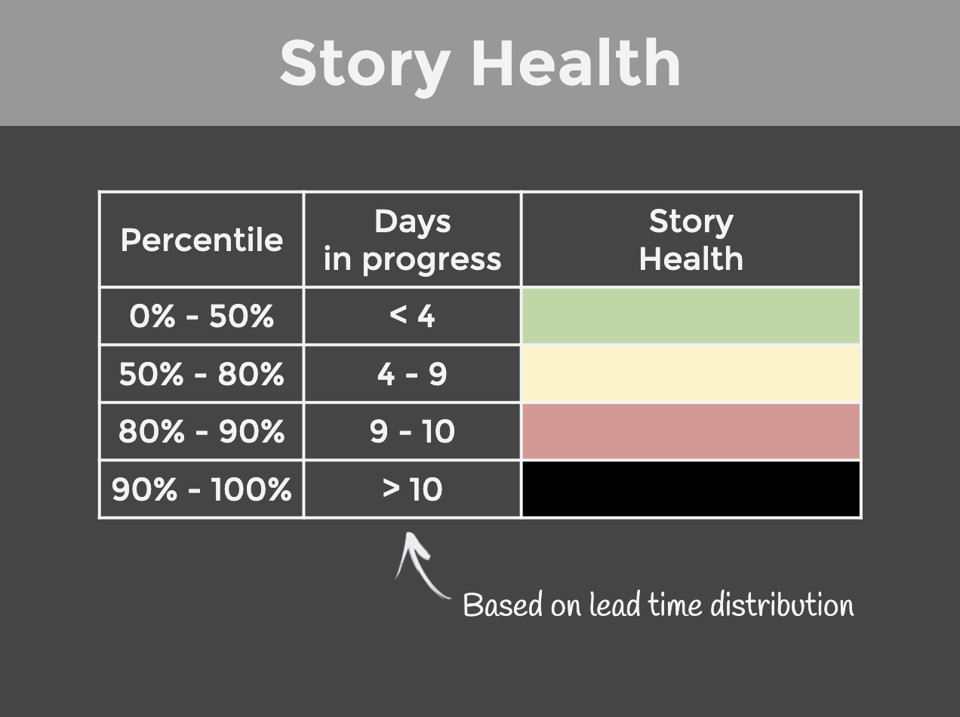
Questa informazione si può visualizzare digitalmente, usando diversi colori per le storie sulla lavagna elettronica, o fisicamente, ponendo dei segnali sulle storie come nell’esempio di figura 10.

“Su cosa è meglio lavorare oggi? A cosa diamo priorità?”
Supponiamo di essere allo Standup meeting, dove il team deve decidere su cosa lavorare oggi, e come assegnare i membri del team alle storie in corso. La Story Health è un’informazione utilissima per prendere queste decisioni: più una storia invecchia, e più diventa importante completarla. Diamo quindi priorità alle storie che sono in corso da più tempo, assegnando loro più persone per fare swarming.

Concentrarci sul completare le storie più vecchie ha un effetto molto importante: ci rende più prevedibili.
Storie più corte riducono il possibile range del nostro lead time. Inoltre, avere più storie corte ha l’effetto di abbassare i nostri percentili, permettendo al team di promettere che una storia verrà completata in meno giorni ma mantenendo un alto livello di sicurezza.
Con questo approccio, è più facile che una storia rispetti la sua previsione e SLA, visto che il team è proattivo nel notare quando c’è il rischio che una storia sfori. Di conseguenza, intraprende azioni per prevenire ulteriori ritardi.
Conclusione
In questo articolo abbiamo discusso di come utilizzare le metriche Throughput e Story Health per rispondere a domande di business. Nel prossimo numero vedremo come usare Probabilistic Forecasting per fare previsioni di progetti/feature.
Mattia Battiston è un software developer con una grande passione per il miglioramento continuo. Attualmente lavora a Londra e utilizza Kanban, Lean e Agile per aiutare diversi team a migliorare.