

Introduzione
Nella prima parte di questa serie di articoli sono stati illustrati i potenziali campi di applicazione dei processi di analisi in tempo reale dei dati generati dai veicoli connessi a Internet. In questa parte, e nella successiva, verrà descritto il funzionamento dei framework che saranno poi integrati per realizzare il sistema digitale di monitoraggio.
Tecnologie di analisi in tempo reale di dati IOT
La capacità di analizzare gli eventi in tempo reale rappresenta una straordinaria opportunità per poter prendere decisioni proattive, per poter minimizzare alcuni rischi o per proporre offerte commerciali competitive. La percezione di questi vantaggi ha determinato un significativo aumento dell’attenzione sulle analisi dei dati in tempo reale, che di fatto è diventata la fase successiva nel percorso di evoluzione dell’industria dei Big Data.
Uno degli esempi è rappresentato dalle grandi istituzioni finanziarie che hanno investito in modo importante nell’implementazione di sistemi di elaborazione degli eventi, per l’analisi in tempo reale dei rischi e per l’individuazione di potenziali frodi.
Framework per l’analisi in tempo reale dei dati
Questo spostamento di interesse e di mentalità, dall’analisi tradizionale dei dati, comprese le elaborazioni batch distribuite di Hadoop [5], ha determinato una crescente domanda di framework capaci di implementare pipeline di analisi in tempo reale. Nella comunità degli sviluppatori questa domanda ha avuto come effetto una forte accelerazione nella realizzazione di questi strumenti.
Con un approccio real time, il modello di analisi basato su dati resi persistenti a seguito di un evento viene superato da un modello di analisi di flussi di dati continui. Questo rende necessaria la realizzazione di sistemi capaci di raccogliere queste sequenze di informazioni, di processarle rapidamente, di attuare eventuali azioni immediate e di conservare i dati per eventuali analisi successive.
Un sistema di questo tipo deve quindi soddisfare i seguenti requisiti:
- acquisire e pubblicare velocemente flussi di dati generici, caratterizzati da volumi e dimensioni significative;
- elaborare questi flussi in modo scalabile, al fine di massimizzare l’efficienza dei modelli di trasformazione e/o aggregazione;
- eseguire modelli di trasformazione integrabili con flussi di dati provenienti da altre fonti.
Qualche strumento di riferimento
In questo contesto si è progressivamente diffusa l’integrazione tra Spark Streaming, Kafka e Cassandra, strumenti che soddisfano requisiti fondamentali come la bassa latenza e la capacità di processare significative quantità di dati trasmessi in una unità di tempo, offrendo anche funzionalità di stream-processing scalabili al crescere delle richieste.
Questi strumenti hanno raggiunto un livello di maturità tale da qualificarsi tra le soluzioni di riferimento per l’implementazione di pipeline di analisi di dati in tempo reale. Ciò è testimoniato dall’ ampia diffusione di soluzioni di streaming analytics implementate proprio attraverso l’integrazione di questi strumenti.
Kafka è un sistemadistribuito di messaggistica publish-subscribe.
Spark Streaming è un’estensione dell’API core di Spark [2], attraverso la quale è possibile importare ed elaborare in tempo reale i dati prodotti da flussi di eventi diversi.
Infine Cassandra è un database specifico per analisi in tempo reale.
La scalabilità delle istanze di Kafka viene garantita dall’integrazione con ZooKeeper, un servizio centralizzato di naming e di gestione sincronizzata delle informazioni di configurazione ed erogazione di servizi simultanei verso i nodi appartenenti ad un cluster.
In questa seconda parte verranno descritte le principali caratteristiche di funzionamento di Zookeeper, Kafka e Cassandra, necessarie alla comprensione dei dettagli di implementazione e integrazione.
A Spark verrà invece dedicata maggiore attenzione nel prossimo articolo della serie. Chiaramente, per una più ampia ed esaustiva trattazione dei dettagli di funzionamento e di integrazione, si rimanda alle fonti di documentazione ufficiale di questi framework.
ZooKeeper
Zookeeper consente di gestire in modo centralizzato e senza interazione utente la configurazione di bootstrap di nodi appartenenti a un cluster di Kafka. A Zookeeper viene inoltre delegata la gestione stessa del cluster attuando la sottoscrizione e l’esclusione di nodi e la gestione del loro stato in tempo reale. Fornisce servizi di naming (DNS) e di sincronizzazione distribuita attraverso un data registry centralizzato, il cui corrispondente servizio viene erogato in alta affidabilità.
L’architettura di Zookeeper prevede la replica del servizio in un cluster di elaboratori dove ciascuno conserva in memoria una copia dei dati di configurazione. Allo start up del servizio, viene eletto il leader del cluster, quindi ciascun client si collega a una qualsiasi delle istanze del cluster di ZooKeeper e mantiene solo con questa una connessione TCP attraverso la quale effettuare le letture.
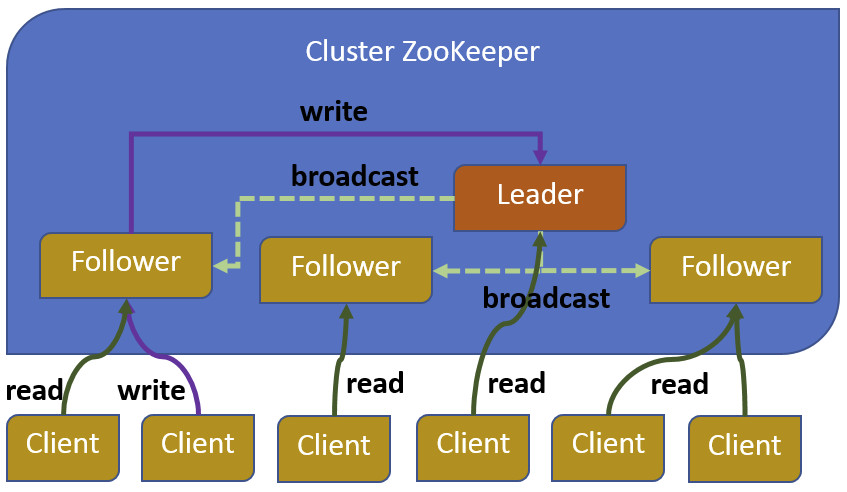
Nella figura 1 viene rappresentato un tipico cluster di ZooKeeper dove un server del cluster ha compiti di leader mentre i restanti di follower. All’avvio del servizio viene eletto il leader del cluster e tutti i follower replicano il loro stato con il leader. Tutte le scritture vengono instradate attraverso il leader e tutti i cambiamenti sono propagati a tutti i follower.
Kafka
L’architettura di Kafka [1] consiste in uno o più nodi broker che accettano la pubblicazione di messaggi aggiungendoli alla partizione di un topic; messaggi che verranno ricevuti da tutti i sottoscrittori di questo topic. Un tipico cluster di Kafka è costituito da più broker. Al fine di bilanciare il carico, un topic viene diviso in partizioni multiple e ciascun broker memorizza una o più di queste partizioni. Più broker e sottoscrittori possono a loro volta contemporaneamente pubblicare e recuperare messaggi (figura 2).
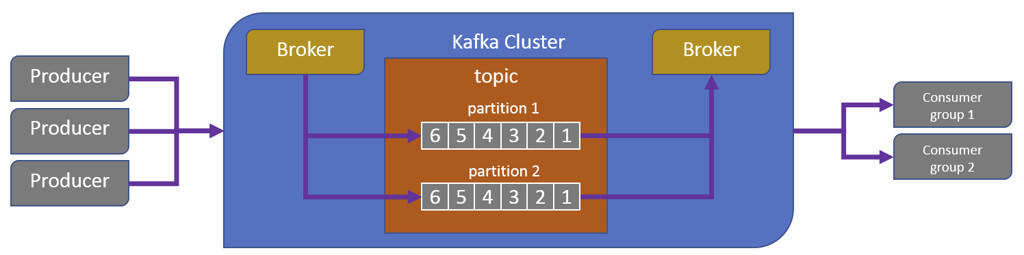
Di seguito la sintesi delle caratteristiche e del funzionamento di un cluster Kafka.
- ciascun topic è suddiviso in partizioni multiple
- i messaggi sono aggiunti in coda alle partizioni
- ogni partizione si comporta come una coda di messaggi
- i sottoscrittori possono essere organizzati in gruppi, e ogni messaggio viene consegnato a ciascun membro di ogni gruppo
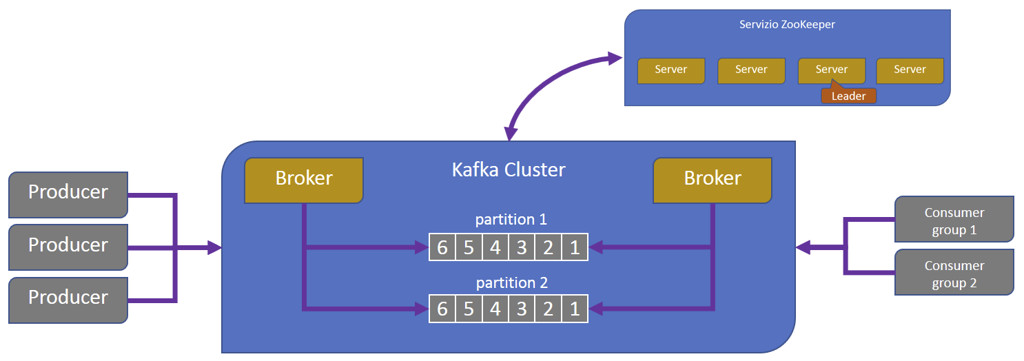
Le istanze dei broker Kafka vengono coordinate da un cluster di Zookeeper che, come già illustrato, fornisce anche il servizio di elezione del leader del cluster. In caso di fault del leader corrente, l’elaborazione riprende non appena viene eletto un altro leader, che recupera lo stato di quello diventato indisponibile. I tempi di ripristino avvengono nell’ordine di pochi minuti e hanno impatto sulle nuove pianificazioni, mentre quelle in esecuzione restano inalterate. I broker corrispondono ai processi Kafka di elaborazione dei messaggi dove ogni elaboratore appartenente al cluster di Kafka può eseguire un solo broker. In un cluster solo uno dei broker agisce come leader di una partizione, di cui gestisce la consegna e la persistenza dei messaggi, gli altri broker invece agiscono come follower.
Kafka e Zookeeper
Il compito di Zookeeper [3] è quello di gestire il coordinamento dei broker Kafka [4] appartenenti a un cluster. Publisher e subscriber di messaggi di una partizione ricevono la notifica dal servizio Zookeeper circa la presenza, in un cluster Kafka, di nuovi broker o di un loro eventuale fault. Alla notifica della presenza di nuovi broker o del fault di quelli esistenti, Publisher e Subscriber di messaggi prendono l’iniziativa di avviare o continuare il loro lavoro coordinandosi con altri broker.
Cassandra
Apache Cassandra è un database non relazionale open source progettato e ottimizzato per gestire significative quantità di dati in alta affidabilità. È caratterizzato da funzionalità di scalabilità lineare ottenibili su elaboratori standard o su infrastrutture cloud. Il supporto alla replica tra datacenter è comunemente considerato tra i più efficaci.
Gli elementi di base di Cassandra sono il KeySpace, il Cluster, la Column Family e le tabelle Cassandra Query Language (CQL).
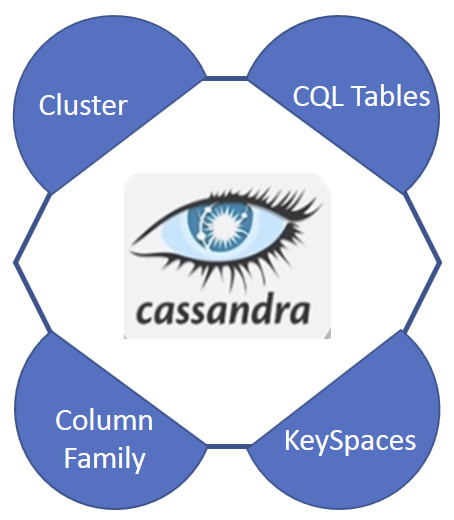
La struttura più esterna di Cassandra è rappresentata da un cluster di server. Ciascun cluster è un contenitore di uno o più Keyspace. Il cluster viene anche definito ring in quanto Cassandra realizza la persistenza dei dati nel cluster organizzandoli in un anello.
Il Keyspace di Cassandra, che raggruppa insieme una o più Column Families, è il contenitore di persistenza dei dati ed è caratterizzato da un gruppo di attributi che ne definiscono il comportamento: le strategie di organizzazione delle repliche e le scritture permanenti.
Strategia di organizzazione delle repliche
La strategia di organizzazione delle repliche definisce la modalità in cui le repliche dei dati vengono attuate nel ring. Ci sono due strategie per determinare quali nodi otterranno le copie delle chiavi:
- La Simple Strategy, che, attraverso la definizione di un fattore di replica (replication_factor), determina il numero di nodi che devono contenere la copia di ciascun record. Se il replication_factor vale, per esempio, 3 allora tre nodi diversi persisteranno una copia di ciascun record.
- La Network Topology Strategy che definisce un fattore di replica distinto per ciascun datacenter del cluster. Anche se un cluster è attestato su un unico datacenter, questa strategia dovrebbe essere preferita alla Simple Strategy perché facilita l’aggiunta di nuovi datacenter al cluster stesso.
Il parametro DURABLE_WRITES istruisce Cassandra ad usare o meno la modalità “CommitLog” sul KeySpace corrente. Si tratta di una opzione non obbligatoria, con valore di default a “True”, utilizzata per migliorarne le prestazioni. In questo modo Cassandra, invece di persistere su disco ogni aggiornamento di colonna, conserva i nuovi dati in memoria, che solo periodicamente vengono trasferiti su disco al fine di ottimizzare le performance, attraverso un utilizzo ragionevole dell’input-output su disco. Per evitare che un problema di crash di un nodo si possa far perdere i cambiamenti recenti ancora in memoria, Cassandra li persiste nel proprio “CommitLog”.
Una Column Family è un contenitore di collezioni ordinate di record, ciascuna delle quali è essa stessa una collezione ordinata di colonne. È sempre possibile aggiungere una colonna a una Column Family.
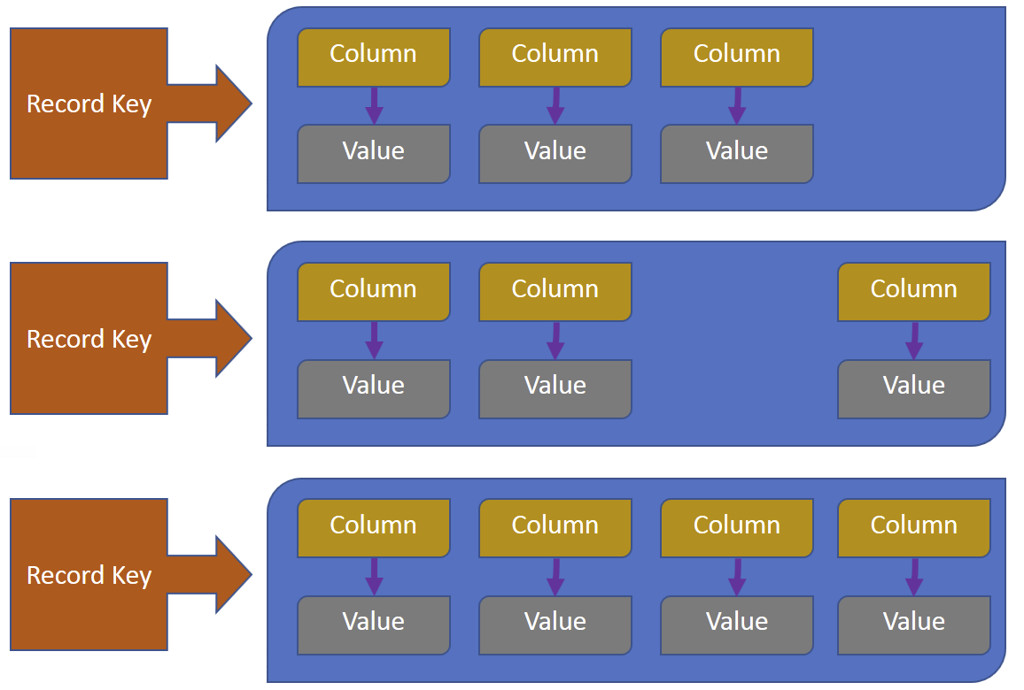
Una tabella CQL, Cassandra Query Language, fornisce una vista a due dimensioni di una Column Family che potenzialmente può contenere dati multi-dimensionali. In questo senso una colonna Cassandra Query Language e una Column Family rappresentano termini intercambiabili.
Conclusioni
In questa seconda parte sono state presentate le principali caratteristiche di funzionamento dei framework che saranno integrati e utilizzati per realizzare il sistema digitale di monitoraggio oggetto di questa serie di articoli.
Nel prossimo articolo la presentazione dei framework verrà completata con la descrizione di Spark.
Riferimenti
[1] Kafka
https://kafka.apache.org/quickstart
https://www.slideshare.net/mumrah/kafka-talk-tri-hug?next_slideshow=1
https://www.youtube.com/watch?v=U4y2R3v9tlY
https://kafka.apache.org/10/javadoc/org/apache/kafka/clients/producer/KafkaProducer.html
[2] Spark e Cassandra data connector
https://www.datastax.com/dev/blog/accessing-cassandra-from-spark-in-java
[3] Zookeeper
https://www.youtube.com/watch?v=gifeThkqHjg
https://www.slideshare.net/sauravhaloi/introduction-to-apache-zookeeper
[4] Kafka e Zookeeper
https://www.youtube.com/watch?v=SxHsnNYxcww
[5] Hadoop
https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html
Luigi Bennardis si è laureato in Scienze Statistiche ed Economiche all’Università di Roma. Si occupa di informatica da un po’ di tempo ed è attualmente impegnato su tematiche DevOps. Nel tempo libero ancora gioca a basket, nuota ed è appassionato di elettronica vintage.