

Introduzione
In questa sesta parte si conclude la descrizione dell’implementazione del modulo applicativo di Data Ingestion & Computing. Verranno presentati i dettagli di data processing Spark e di persistenza su Cassandra.
Esecuzione delle attività di data processing e di persistenza su Cassandra
Nella parte precedente sono stati descritti i passi che portano alla definizione del JavaDStream da utilizzare per eseguire le attività di data processing. Su quest’ultimo, ogni iterazione del batch esegue i metodi statici della classe che implementa i calcoli di traffico totale, quelli basati sulla finestra temporale definita e quelli di monitoraggio di uno specifico POI (Point of Interest). Il batch si conclude con la persistenza di questi risultati su Cassandra.

La computazione di streaming viene avviata e interrotta utilizzando rispettivamente i metodi context.start() e context.stop(). Il metodo context.awaitTermination() permette al thread corrente di attendere il termine di un contesto di streaming, causato da un’istruzione context.stop() o da una eccezione. Di seguito le istruzioni Java utilizzate in questo caso.

Calcolo dei dati di traffico e persistenza su Cassandra
Questo metodo statico esegue le trasformazioni necessarie per ottenere un JavaDStream di tipo ChiaveAggregata, costituito dal numero di veicoli raggruppati per tipo e per direttrice stradale di rilevazione. Questo risultato si ottiene applicando in sequenza i metodi mapToPair e ReduceByKey al DStream precedentemente persistito in memoria. A ques’ultimo JavaDStream viene quindi applicato il metodo mapWithState che imposta un timeout di conservazione dello stato. L’ultima operazione consiste nella persistenza di quest’ultimo DStream su Cassandra.

Di seguito viene riportato il codice relativo alla chiave aggregata.

Ecco poi la codifica della funzioneDatiTrafficoTotale
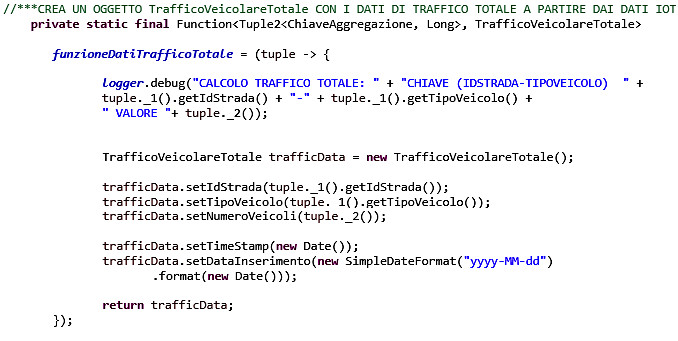
E infine la codifica della funzioneCalcoloTotale
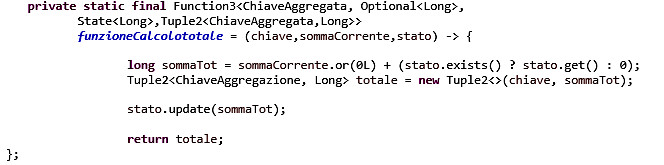
Computazioni su finestre temporali
Attraverso l’applicazione su un DStream del metodo reduceByKeyAndWindow, Spark Streaming supporta i calcoli sui dati acquisiti all’interno di finestre temporali, come illustrato dalla figura 1.
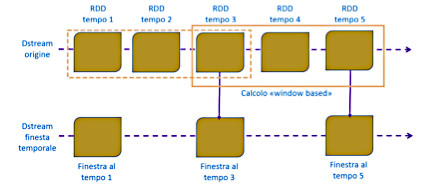
Questa funzione permette di unire gli RDD che rientrano nella finestra temporale che scorre su una sorgente DStream. Nell’esempio riportato in figura 1, lo slittamento temporale applicato su due unità temporali di dati (“RDD tempo 3” – “RDD tempo 5”) determina un’operazione di unione applicata alle ultime tre unità di tempo. Ne deriva che, per tutte le operazioni di questo tipo, è necessario specificare due parametri: l’ampiezza della finestra e l’intervallo di scorrimento. Questi parametri devono essere multipli dell’intervallo del batch di origine.
Di seguito il fragment di implementazione del metodo reduceByKeyAndWindow che permetterà di calcolare il numero di veicoli all’interno di finestre temporali con ampiezza e slittamento di trenta e dieci secondi rispettivamente. In altre parole sarà possibile visualizzare il traffico totale osservato nei trenta secondi precedenti a intervalli di dieci secondi.

Nel dettaglio sul JavaDStream in cache, di tipo IoTData, vengono applicati in sequenza i metodi mapToPair (necessario a filtrare per idStrada e tipoVeicolo) e reduceByKeyAndWindow ottenendo così un nuovo DStream con chiave di aggregazione idStrada e tipoVeicolo sulla finestra temporale corrente.
Per agevolare la lettura, non viene riportata la codifica di trasformazione in DStream di questo ultimo JavaPairDStream, implementazione necessaria alle operazioni di persistenza delle informazioni su Cassandra. Il lettore potrà fare riferimento a quanto riportato nel paragrafo precedente.
Rilevazione dei veicoli in prossimità di un Point of Interest
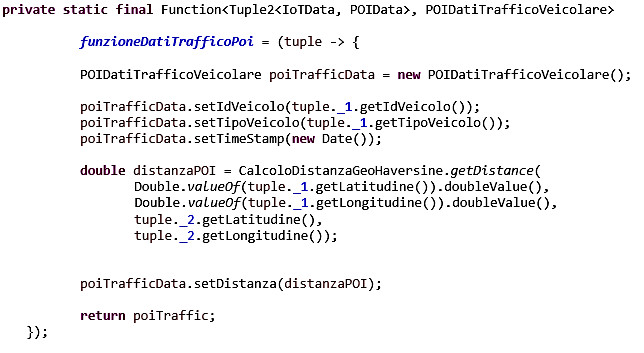
Di seguito la codifica della funzione che permette la rilevazione dei veicoli presenti nel raggio di un Point of Interest calcolandone anche la distanza da quest’ultimo.
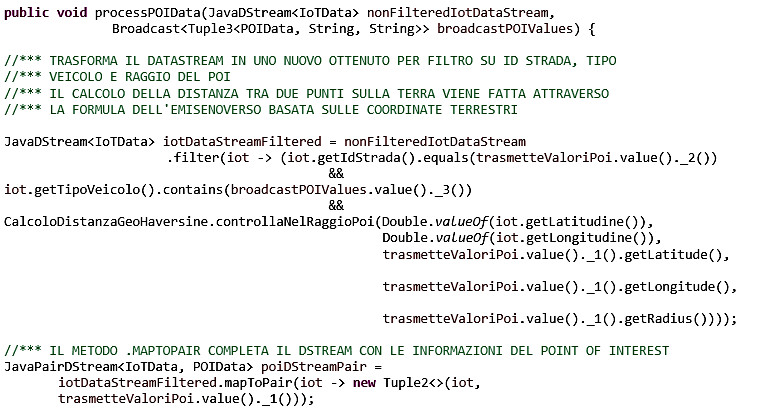
Analogamente a quanto indicato nel paragrafo precedente, al fine di agevolare la lettura non viene riportata la codifica necessaria alle operazioni di persistenza su Cassandra, rimandando il lettore ai paragrafi precedenti.
Ed ecco infine il codice che implementa il calcolo della distanza dal POI di ciascun veicolo rilevato nel raggio stabilito.
Conclusioni
In questa sesta parte sono stati completati i dettagli di implementazione del componente applicativo di Data Ingestion & Computing, relativi all’applicazione delle funzioni di calcolo e persistenza su Cassandra, necessarie a soddisfare i requisiti di monitoraggio. Nella prossima parte verrà presentato l’ultimo componente applicativo, la dashboard di visualizzazione.
Riferimenti
Socks
socks-client
https://github.com/sockjs/sockjs-client
Kafka
https://kafka.apache.org/quickstart
https://www.slideshare.net/mumrah/kafka-talk-tri-hug?next_slideshow=1
https://www.youtube.com/watch?v=U4y2R3v9tlY
https://kafka.apache.org/10/javadoc/org/apache/kafka/clients/producer/KafkaProducer.html
Spark
https://spark.apache.org/docs/latest/index.html
https://data-flair.training/blogs/spark-rdd-tutorial/
https://data-flair.training/blogs/apache-spark-rdd-features/
Spark e Cassandra data connector
https://www.datastax.com/dev/blog/accessing-cassandra-from-spark-in-java
Zookeeper
https://www.youtube.com/watch?v=gifeThkqHjg
https://www.slideshare.net/sauravhaloi/introduction-to-apache-zookeeper
Kafka e Zookeeper
https://www.youtube.com/watch?v=SxHsnNYxcww
Price Waterhouse and Cooper “The Bright Future of Connected Cars” https://carrealtime.com/all/pwc-the-bright-future-of-connected-cars/
Hadoop
https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html
Spark
RDD
https://www.usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf
WebSocket
http://jmesnil.net/stomp-websocket/doc/
Stomp
https://stomp-js.github.io/guide/stompjs/rx-stomp/ng2-stompjs/using-stomp-with-sockjs.html