

Implementare la tecnologia Blockchain in Java
Il modo migliore per capire come funziona qualcosa è quello di provare a realizzarla. Per questo motivo inizia questo mese il mio diario di viaggio sull’implementazione della tecnologia Blockchain in Java.
Lo scopo è quello di affrontare tutti i concetti legati a Blockchain, introdotti prima da Bitcoin e successivamente ampliati e sviluppati per altre criptovalute e prodotti legati a questa tecnologia.
L’implementazione verrà fatta in Java, con l’aggiunta di una serie di librerie e framework open source, rilasciando il progetto su Github [1] in modo da poter seguire l’avanzamento dello sviluppo e raccogliere eventuali suggerimenti e integrazioni.
MBBlockchain
In tutti i progetti che affronto, il primo problema che devo risolvere è quello di trovare un nome adeguato, che rappresenti quello che voglio realizzare, che non sia troppo tecnico, che sia facilmente riconoscibile, che non sia già stato utilizzato, che non sia narcisista e che mi piaccia: impossibile!
Alla fine ha vinto la banalità, il narcisismo e il fatto che le mie iniziali MB (Matteo Baccan), siano le stesse di MokaByte (ma anche di Mario Balotelli e di Monza–Brianza… ma questa è un’altra storia…).
Per questa ragione ho voluto dare il nome di MBBlockchain [1] al progetto che svilupperò nel corso dei prossimi mesi, in modo da coprire tutte le specifiche di un progetto che si pone l’obiettivo di implementare Blockchain.
Nel tempo, estenderò poi il prodotto in modo da seguire le richieste degli utenti, ricordando sempre che si tratta principalmente di un esercizio di stile, pur volendo essere anche qualcosa di funzionante e utilizzabile.
Che cosa è Blockchain?
Chiarite le motivazioni che mi hanno spinto a partire con questo progetto, provo a semplificare il concetto di Blockchain, guardandolo dal punto di vista di un programmatore che passerà le proprie notti davanti a enormi tazze di caffè e interminabili compilazioni di codice.
Blockchain è una catena immutabile di informazioni, legate fra di loro tramite un algoritmo di controllo
Questo basterebbe a chiarire il concetto di Blockchain, ma sarebbe riduttivo per spiegare l’intera tecnologia. Servono infatti una serie caratteristiche aggiuntive per riuscire a chiudere lo sviluppo di un prodotto basato su Blockchain.
Concetti costitutivi di Blockchain
Una di queste è la distribuzione della catena all’interno di nodi distribuiti su una rete, pubblica o privata, dove le informazioni sono presenti in copie multiple, senza la necessità di avere un centro di controllo dato che la decisione dell’aggiornamento della catena è demandato all’approvazione da parte della maggioranza dei nodi.
Su questi concetti sono nate molte criptovalute come Bitcoin, Ethereum, Ripple e Litecoin [2]; per questo motivo è facile sovrapporre i concetti di criptovaluta con quelli di Blockchain, pur essendoci delle chiare differenze.
Oltre ad essere la base sulla quale implementare una criptovaluta, infatti, Blockchain può servire per effettuare un’infinità di operazioni: allevare gattini virtuali [3], garantire delle transazioni finanziarie, garantire delle compravendite di immobili o di auto, e gestire tutti quegli ambiti in cui è necessario garantire nel tempo le operazioni [4].
Partiamo con i blocchi
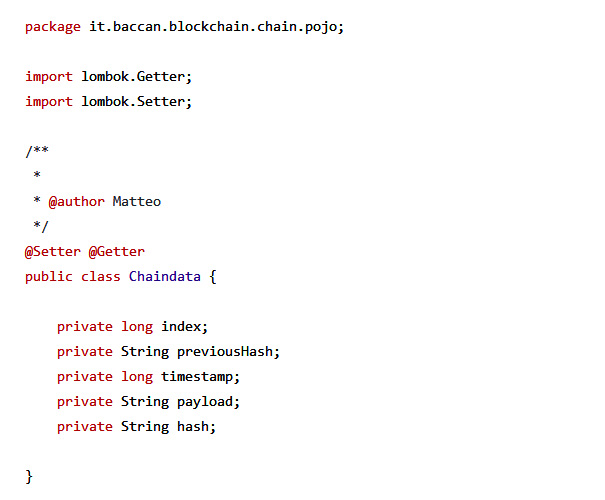
Dato che stiamo parlando di un elenco di blocchi, il primo codice realizzato per MBBlockchain è quello che definisce il POJO con la struttura di un blocco base: Chaindata.
Questo blocco deve poi essere gestito all’interno di una Blockchain, per questo motivo la seconda classe da scrivere è il servizio che si occupa di gestire la sequenzialità dei blocchi, creando le informazioni di contorno e il giusto HASH per inserire il blocco nella catena.
A monte di queste classi serve poi un controller in grado di utilizzare i parametri inviati ai servizi REST e di interrogare il servizio di gestione Blockchain.
Le informazioni nel blocco
Esistono molte informazioni che possono essere inserite in un blocco; esiste però un sottoinsieme dal quale possiamo partire per costruire un’implementazione base.
I dati minimi si possono così riassumere come segue
- index: valore intero positivo in grado di dare la posizione assoluta del blocco;
- previousHash: valore di HASH del blocco precedente;
- timestamp: timestamp di creazione del blocco;
- payload: blocco generico di informazioni, per non creare un vincolo su una struttura predeterminata;
- hash: valore di HASH del blocco attuale, calcolato sui dati precedenti.
Dobbiamo considerare questa struttura come un MVP [7] del prodotto, dato che varierà nei prossimi mesi, a mano a mano che verranno implementati i concetti di Blockchain e arriveranno le richieste di approfondimento da parte dei lettori.
Il problema che si deve risolvere in questo momento è quello di trovare il numero minimo di informazioni per poter realizzare la versione 1.0 di MBBlockchain.
Index per il posizionamento del blocco
Essendo una lista di blocchi, il primo dato necessario è quello di posizionamento del blocco che stiamo gestendo: index. Questa informazione è importante per una serie di motivi: ci permette di ordinare i blocchi in ordine crescente e ci permette di gestirli in modo sparso, magari chiedendoli in modo distribuito a più nodi, in modo simile a quanto viene fatto da altri protocolli come quello di BitTorrent [5].
Anche se l’indice potrebbe apparire come un doppione del valore di HASH, in quanto entrambi rappresentano il blocco di informazioni, dobbiamo ricordare che il valore di HASH potrebbe collidere fra due blocchi, creando informazioni potenzialmente intercambiabili, mentre un indice assoluto dovrebbe evitare il problema e garantirci una univocità di informazioni.
Data di creazione e hash del blocco precedente
Allo stesso modo sono importanti altre due informazioni: la data di creazione del blocco (timestamp) che deve essere compresa fra quella del blocco precedente e successivo e l’HASH del blocco precedente (previousHash).
In realtà questo dato potrebbe essere dedotto leggendo il blocco precedente ma diventa un’informazione necessaria se vogliamo poter applicare una validazione al singolo blocco.
Payload e hash del blocco in questione
Le ultime due informazioni sono il payload da trasportare e l’HASH del blocco, in modo da garantirne la sua immutabilità.
Ho volutamente introdotto un concetto di payload e non di transazione, per dare a MBBlockchain un aspetto di trasporto generico e non un legame con una struttura dati predefinita. In questo modo potremo trasportare transazioni finanziare, ma anche informazioni contrattuali o qualsiasi dato in grado di trarre vantaggio da una struttura immutabile e distribuita.
Operazioni base con i blocchi
Ora che è stato strutturato un blocco, occorre pensare al servizio che deve gestire le operazioni base sui blocchi:
- creazione di una struttura vuota di Blockchain;
- calcolo del blocco;
- aggiunta di un nuovo blocco;
- accesso all’ultimo blocco;
- accesso a tutti i blocchi.
Persistenza
Il modo corretto di gestire una struttura di questo genere passa sicuramente attraverso la persistenza delle informazioni su disco, in modo transazionale e sicuro, per garantirne la conservazione nel tempo ed evitare la possibile saturazione di RAM del nodo che la gestisce.
Nella prima implementazione di MBBlockchain, tuttavia, ho invece deciso di gestire i dati interamente in memoria, senza occuparmi per il momento della persistenza. In questo modo, riusciremo a snellire la prima implementazione e ad azzerare i tempi di attesa fra nodi. Ma il problema della persistenza rimane comunque un task aperto che verrà risolto nei prossimi mesi, in base alle caratteristiche di MBBlockchain.
Da questa scelta adottata per il momento, consegue che il modo più veloce di gestire i Chaindata è quello di avere una lista nel servizio di gestione:
private final ArrayList<Chaindata> blockchain = new ArrayList<>();
Vista l’implementazione e il fatto che stiamo ancora lavorando senza prevedere nessun tipo di errore, l’accesso all’ultimo blocco della lista e l’esportazione di tutti i blocchi diventano delle banali operazioni su ArrayList:
public boolean addBlock(Chaindata cd) {
blockchain.add(cd);
return true;
}
public Chaindata getLastBlock() {
Chaindata ret = null;
if (blockchain.size() > 0) {
ret = blockchain.get(blockchain.size() - 1);
}
return ret;
}
public ArrayList<Chaindata> getChain() {
return blockchain;
}
Aggiungere un nuovo blocco
L’operazione più complicata sulla Blockchain diventa così il calcolo del nuovo blocco da aggiungere, che coinvolge una serie di setter su Chaindata e il calcolo dell’HASH della somma di payload e previousHash:
public Chaindata createBlock(Transaction t, Chaindata lastBlock) {
// Chain
Chaindata cd = new Chaindata();
cd.setTimestamp(System.currentTimeMillis());
Gson gson = new GsonBuilder().create();
String payload = gson.toJson(t);
cd.setPayload(payload);
if (lastBlock != null) {
cd.setPreviousHash(lastBlock.getHash());
cd.setIndex(lastBlock.getIndex() + 1);
} else {
cd.setPreviousHash("");
cd.setIndex(1);
}
try {
MessageDigest digest = MessageDigest.getInstance("SHA-256");
byte[] hash = digest.digest((payload + cd.getPreviousHash())
.getBytes(StandardCharsets.UTF_8));
String hashString = Base64.getEncoder().encodeToString(hash);
cd.setHash(hashString);
} catch (NoSuchAlgorithmException ex) {
log.error("Error creating hash", ex);
}
return cd;
}
Mentre la creazione dei primi dati (timestamp, payload, hash e index) è abbastanza banale, l’operazione che richiede maggior attenzione è quella del calcolo dell’HASH di blocco.
In questa fase ho optato per l’utilizzo di una sottoparte di dati del blocco, sui quali implementare il calcolo di un digest SHA256 [8]. Il dato ricavato viene poi convertito Base64 per favorirne il trasporto.
Blockchain controller
Ora che è stato definito il blocco base e il servizio in grado di controllare la catena, occorre iniziare a pensare ai servizi in grado di esportare le operazioni su Blockchain, in modo che possano essere effettuate tramite dei semplici servizi REST.
Vista la natura Java del progetto, per strutturare i servizi mi sono affidato a Spring Boot [9], realizzando una MBBlockchain Application.
All’interno dell’Application ho realizzato un primo RestController in grado di gestire tutte le route esposte sulla Blockchain, richiamando i metodi del service Blockchain appena realizzato.
BlockchainController espone così direttamente i servizi Blockchain, facendo da pass-through fra i parametri ricevuti dal servizio REST e il controller, utilizzando il @RequestMapping(“/chain”).
@GetMapping(value = "/list", produces = "application/json; charset=utf-8")
public ArrayList<Chaindata> chain() {
return blockchain.getChain();
}
@GetMapping(value = "/lastblock", produces = "application/json; charset=utf-8")
public Chaindata lastblock() {
return blockchain.getLastBlock();
}
Per facilitare i test di questa fase ho anche realizzato un servizio per la creazione di blocchi all’interno di Blockchain. In questo momento, in assenza di controlli, è ancora una pratica possibile.
Nei prossimi mesi andremo ad analizzare la fase del primo popolamento di Blockchain e il concetto di ICO [10] che coinvolge questa attività.
@GetMapping(value = "/addFakeTransaction", produces = "application/json; charset=utf-8")
public Map<String, String> addFakeTransaction() {
// Transaction to add
Transaction t = new Transaction();
t.setSender("Matteo");
t.setReceiver("Giovanni");
t.setAmount(new Random().nextInt());
// Chain
Chaindata cd = blockchain.createBlock(t, blockchain.getLastBlock());
blockchain.addBlock(cd);
// Return
Map<String, String> ret = new HashMap(2);
ret.put("result", "ok");
return ret;
}
Una prima verifica
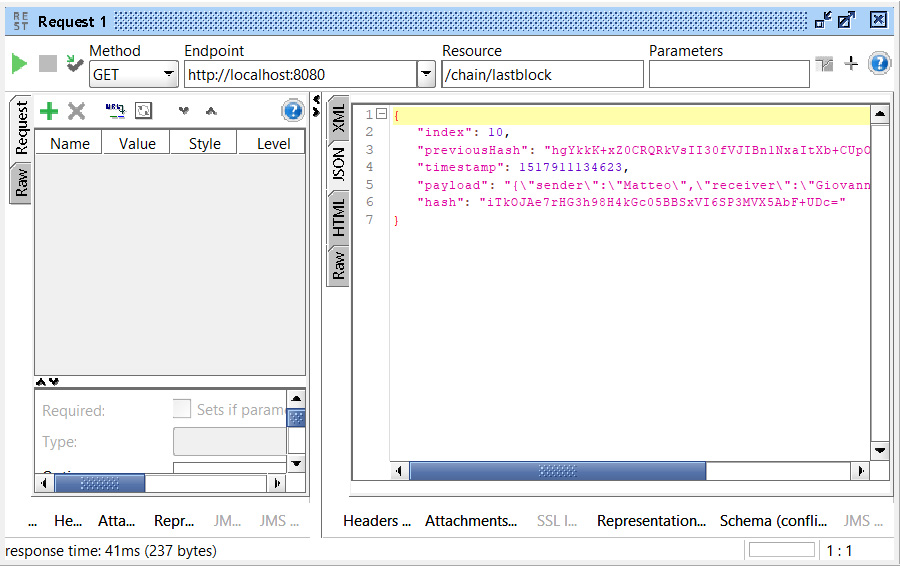
Ora abbiamo una prima implementazione di Blockchain pronta per l’uso, testabile direttamente da un browser con i seguenti comandi:
- Visualizzazione Blockchain: http://127.0.0.1:8080/chain/list
- Aggiunta di una transazione fake: http://127.0.0.1:8080/chain/addFakeTransaction
- Visualizzazione dell’ultimo blocco: http://127.0.0.1:8080/chain/lastblock
Volendo fare un test, possiamo chiamare in sequenza questi comandi per visualizzare la creazione di nuovi blocchi.
Creazione dei nodi
Fino a questo punto tutto bene, ma non benissimo: mancano ancora i servizi in grado di gestire la rete di nodi che andrà a replicare i dati della Blockchain e che si occuperà di “minare” i blocchi che andremo a inserire nel tempo.
Rispetto alla scelta fatta sulla Blockchain, in questo caso potrebbe essere corretto implementare in memoria la lista dei nodi della rete. Per questa ragione è stato replicato l’approccio della lista in RAM, creando una lista composta da IP e PORTA.
I metodi per l’aggiuta di un nodo
Sopra queste informazioni è sufficiente creare i metodi per l’aggiunta di un nodo e per la restituzione dell’elenco dei nodi presenti:
// PeerList
private final ArrayList<Peerdata> peers = new ArrayList<>();
public void addPeer(String ip, String port) {
Peerdata peer = new Peerdata();
peer.setIp(ip);
peer.setPort(port);
peers.add(peer);
}
public ArrayList<Peerdata> list() {
return peers;
}
Anche in questo caso si rende necessaria la creazione di un controller, PeerController, in grado di aggiungere nodi alla rete e di restituirli per eventuali sincronizzazioni:
@GetMapping(value = "/add/{ip}/{port}", produces = "application/json; charset=utf-8")
public Map<String, String> addPeer(@PathVariable String ip, @PathVariable String port) {
// Add to peerList
peers.addPeer(ip, port);
Map<String, String> ret = new HashMap(2);
ret.put("result", "ok");
return ret;
}
@GetMapping(value = "/list", produces = "application/json; charset=utf-8")
public ArrayList<Peerdata> list() {
return peers.list();
}
Come si può notare, al momento non vi sono verifiche sulla correttezza dei dati. In gergo si parla di codice in grado di lavorare nei “sunny day”, approccio molto diffuso durante la creazione di un MVP o quando non si dispone del tempo e delle risorse necessarie per chiudere un progetto.
Nelle prossime puntate verranno riscritte alcune parti, in modo da irrobustire il codice e affrontare altri aspetti legati all’affidabilità di un’architettura di questo genere.
Sincronizziamo i dati
Ora che il singolo nodo può venire a conoscenza degli altri nodi, possiamo iniziare a realizzare un algoritmo in grado di risolvere eventuali conflitti di Blockchain. L’idea di base è quella di interrogare gli altri nodi, scaricare l’intera Blockchain e in caso di maggiore consistenza, sostituire la Blockchain corrente con quella ricevuta.
Chiaramente l’approccio potrebbe essere assolutamente distruttivo, ma a questo livello implementativo è il modo più veloce ed elegante per sincronizzare i nodi.
Un buon prodotto per effettuare chiamate HTTP in Java è Unirest [6], molto semplice da implementare e da leggere. Per questa ragione mi sono appoggiato a Unirest per interrogare i nodi e scaricare le Blockchain.
Una volta scaricata, senza farne un controllo di congruenza, verificavo se la lunghezza fosse superiore alla Blockchain in mio possesso e, in caso affermativo, procedevo alla sua sostituzione:
for (Peerdata pd : apd) {
HttpResponse<JsonNode> chainDataResponse;
try {
chainDataResponse = Unirest.get("http://" + pd.getIp()
+ ":" + pd.getPort() + "/chain/list")
.header("accept", "application/json")
.asJson();
ArrayList<Chaindata> peerBlockchain = new ArrayList<>();
for (int n = 0; n < ja.length(); n++) {
Chaindata node = new Chaindata();
...
peerBlockchain.add(node);
}
// Sostituisco sempre
if (peerBlockchain.size() > blockchain.size()) {
blockchain.clear();
blockchain.addAll(peerBlockchain);
}
} catch (UnirestException ex) {
log.error("Error readming chain", ex);
}
}
Conclusioni
Durante questa puntata abbiamo affrontato i concetti base di Blockchain: il concetto di blocco, di HASH del blocco, di concatenazione e risoluzione delle differenze. Oltre a questo ci siamo soffermati sul concetto di peer e di interconnessione.
Nella prossima puntata vedremo come rendere più robusto e sicuro il calcolo dell’HASH, come verificare la congruenza della Blockchain e come ottimizzare le sincronizzazioni fra i nodi; introdurremo poi il concetto di mining.
Matteo Baccan è un informatico per passione.
Si occupa di sviluppo e architetture software da quando 64k erano sufficienti per qualsiasi tipo di applicazione.
Al momento gestisce team di programmatori e sviluppa progetti mission critical per alcune aziende italiane e internazionali.
Parte del suo lavoro è consultabile sul sito http://www.baccan.it