

Blockchain come strumento di integrazione
Negli articoli precedenti della serie abbiamo parlato delle basi della tecnologia blockchain, di aspetti implementativi e di qualche applicazione — sotto forma di proof of concept — a cui potrebbe essere applicata.
In questo intervento pongo un ulteriore punto di vista sull’adozione di questa tecnologia in un modello applicativo diverso. In particolare mi riferisco al suo utilizzo come strumento di tracciamento e audit di dati tra sistemi eterogenei.
Ho due scenari in mente: il primo è quello di un’unica entità che adotta più sistemi di acquisizione dati, magari sistemi SCADA o altri sistemi IoT. Il secondo scenario, invece, si estende al di fuori della singola entità e coinvolge più sistemi di più aziende o attori differenti.
È possibile vedere la tecnologia blockchain come uno strumento di integrazione di sistemi eterogenei?
Primo scenario: singolo attore, molteplici sistemi
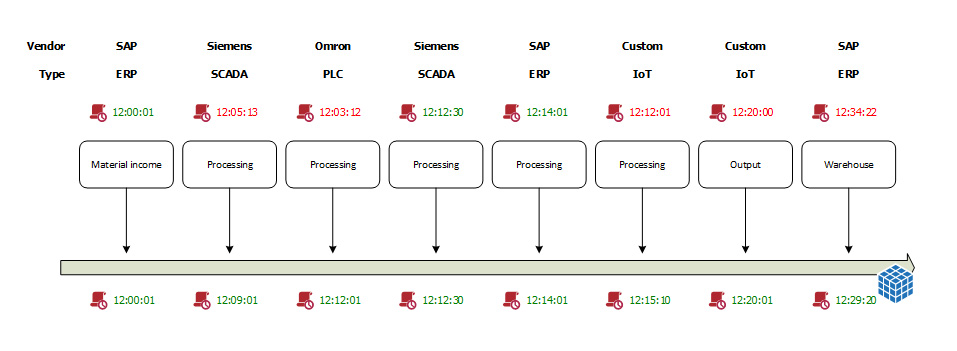
Partiamo dal primo scenario, definendo per prima cosa l’obiettivo, ossia la necessità di avere uno strumento che tenga traccia dei rilievi fatti da più sistemi PLC [1], SCADA [2] o IoT [3].
Sistemi diversi, produttori diversi, dati organizzati in modo differente, che necessitano di molteplici sistemi per essere elaborati, e che spesso non sono in grado di aggregare le informazioni per avere una visione di insieme. E aggiungiamo il fatto che possano essere sistemi che hanno una capacità di memoria limitata per la conservazione delle informazioni.
Perchè usare il blockchain in un contesto simile?
La possibilità di raccogliere i dati di più sistemi in un unico contenitore come la blockchain potrebbe dare una visibilità importante ai dati raccolti:
- le informazioni raccolte non sono manipolabili una volta salvate nel sistema;
- la cronologia di inserimento dei dati sarebbe garantita dalla cronologia delle transazioni nel blockchain;
- i dati potrebbero essere analizzati e confrontati con i dati di produzione (ERP);
- i dati potrebbero essere analizzati con strumenti largamente diffusi (per esempio, script di Python, ma anche infrastrutture tecnologiche più complesse di analisi ed elaborazione dei dati).
Per quale ragione una struttura dovrebbe chiedere ai propri fornitori di fare modifiche affinché i dati vengano salvati (anche) in una blockchain? Le ragioni possono essere diverse, ma le prime che mi vengono in mente sono controllo di qualità o conformità a regolamentazioni come, per esempio, GMP (Good Manufacturing Practices) [4], che regola le buone pratiche di fabbricazione dei materiali e degli oggetti destinati a venire a contatto con prodotti alimentari.
Secondo scenario: attori molteplici
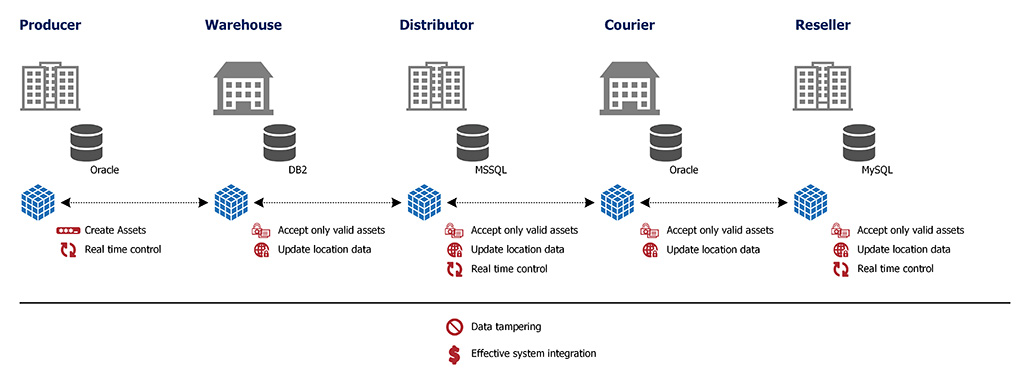
Il secondo scenario è un po’ più articolato, poiché è necessario coinvolgere più attori nell’implementazione. Nello scenario proposto, ogni azienda rappresenta un nodo della rete blockchain, e ogni azienda dispone di un sistema ERP differente (scegliete a caso i nomi dei vari ERP).
All’interno di una filiera come potrebbe essere una supply chain molto regolamentata — come quella farmaceutica, per esempio—, il produttore di un sistema potrebbe voler mantenere il controllo del percorso e della storia del singolo prodotto.
In questo scenario prevedo questi attori:
- Produttore, per esempio di apparecchi elettronici
- Corriere A
- Distributore
- Corriere B
- Rivenditore
- Cliente
Abbiamo sei attori, di cui cinque dispongono di sistemi gestionali differenti, con scopi e funzionalità differenti.
Gli elementi del processo
Nello scenario ideale, il “produttore” è l’unico in grado di creare il prodotto all’interno del database distribuito, quindi lo inserirà con una serie di caratteristiche uniche legate ad esso, per esempio lo SKU e il numero di serie (SN).
I dati salvati nella blockchain, distribuiti su tutti gli attori, informeranno l’intera rete — quindi “l’ecosistema” di questa applicazione — dell’esistenza di un nuovo prodotto, e tutti sapranno che si trova presso il produttore grazie al fatto che l’informazione comprende anche il luogo in cui si trova.
A questo punto il “Corriere A” ottiene il prodotto dal “Produttore”. Il sistema ERP del corriere sarà in grado di verificare se il determinato prodotto (SKU/SN) sia realmente presso il produttore, e quindi prenderlo in carico. Naturalmente alla presa in carico di questo prodotto, l’ERP del corriere in questione si assicurerà di scrivere nella blockchain un aggiornamento in cui indica che il prodotto ora si trova in carico dello stesso.
Il processo continua fino ad arrivare al Rivenditore, il quale al momento della vendita registra l’uscita del prodotto. Inutile dire che il Cliente finale avrà la possibilità di verificare l’identità e la garanzia del prodotto in ogni momento grazie alle informazioni salvate nella blockchain.
Quali sono i vantaggi?
Ma dove sta la novità? Fino ad oggi il processo di vendita ha continuato (e continuerà) a funzionare bene anche senza un’integrazione di questo genere, no? Eppure, questa soluzione presenta dei vantaggi che non vanno sottovalutati.
Cominciamo dal fatto che la tracciabilità del prodotto e la sua verificabilità sono elementi molto importanti per ridurre il rischio di furto o contraffazione. Se solo il produttore fosse in condizioni di creare “l’asset digitale”, nessun’altra parte nella filiera di supply chain potrebbe accettare un prodotto che non esista o con il numero di serie “ribattuto”.
Attraverso l’utilizzo di una rete blockchain tra attori differenti, i singoli ERP potrebbero accedere a informazioni essenziali (sotto forma di metadati) senza necessità di creare complessi sistemi di scambi dati o ETL per comunicare con altri sistemi di terze parti. Per non parlare del fatto che mettere in comunicazione i sistemi informativi tra attori diversi potrebbe rivelarsi un problema insormontabile.
Nei due scenari proposti, una soluzione basata su un database distribuito in sola scrittura incrementerebbe considerevolmente quello che viene denominato “accountability”, ossia la responsabilizzazione delle parti coinvolte in un processo a quello che succede. Questo non necessariamente rappresenta un sistema per “dare la colpa a qualcuno”, bensì permette di individuare i problemi nei processi e facilitarne la risoluzione.
Un altro vantaggio non da sottovalutare è la possibilità di ricostruire o verificare la veridicità dei dati in caso di alterazioni delle banche dati dei singoli attori. Alterazioni che potrebbero derivare da manomissioni dei dati — intenzionali o non intenzionali —, perdita dei dati a causa, per esempio, di ransomware come accaduto in diverse occasioni o durante la migrazione dei dati.
Se anche una copia del database blockchain andasse completamente perduta (in caso di disastro) si potrebbe ricostruire la copia persa reinserendo un nuovo nodo nella rete blockchain (disaster recovery).
Ultimo, non certo per importanza, è il fatto che la cronologia di eventi sarebbe mantenuta da un meccanismo esterno e indipendente, quello dei nodi blockchain.
La sfida
La complessità di un’implementazione di questo genere è definire un modello di dati da conservare all’interno del database blockchain che sia intelligibile e interscambiabile tra i vari sistemi dei vari attori.
Il vantaggio di avere uno strumento accessibile tramite chiamate standard di mercato (HTTP e JSON–RPC) rende il processo di dialogo e di integrazione molto meno costoso rispetto allo sviluppo di una tecnologia o di un protocollo proprietario.
Questo permette alle software house e ai system integrator di abbandonare completamente il problema del trasporto e della condivisione dei dati e concentrarsi unicamente sui (meta)dati da salvare all’interno del database. Al resto ci penserà il sottosistema.
Quindi la sfida diventa quella di definire un modello di scambio dei dati che possa permettere a più attori (aziende) di interscambiare informazioni. Come? È un argomento che affronteremo in modo più pratico in un prossimo articolo.
Mi occupo della progettazione e della protezione di architetture di sistema e di rete da ormai più di 20 anni.
Trasformare l’esigenza in una soluzione tecnologica quanto più semplice ed efficace possibile è una delle attività che maggiormente mi divertono, sfruttando le tecnologie più recenti e adeguate ai vari problemi e affrontando le tematiche operative e normative ad esse legate.
Da qualche tempo ho cominciato a studiare l’applicazione del Blockchain al mondo “reale” con l’idea di trovare un’applicazione reale a questa tecnologia.