

Introduzione
Dopo aver descritto Kafka, Zookeeper e Cassandra, questa terza parte, completamente dedicata a Spark, completa la presentazione dei framework sulla cui integrazione si basa il sistema di monitoraggio real time del traffico veicolare, oggetto di questa serie di articoli.
Spark
Nato nel 2009 presso l’AMPLab di Berkeley, e successivamente rilasciato dal 2010 come open source nell’ambito del progetto Apache, Spark è un framework di analisi ed elaborazione dei big data, scritto in linguaggio di programmazione Scala ed eseguibile attraverso una Java Virtual Machine (JVM).
I requisiti di elaborazione richiesti dalle analisi dei big data sono soddisfatti da Spark attraverso l’implementazione di alcuni dataset specifici per dati testuali o grafici oppure ottenibili a partire da fonti dati di tipo batch o live streaming.
Oltre che utilizzabile in modo interattivo da linea di comando, nel run-time di Spark è possibile distribuire applicazioni sviluppate in Java, Scala o Python.
Spark dispone di un set integrato di oltre ottanta operatori di alto livello. Oltre alle operazioni Map e Reduce, supporta anche query SQL, streaming di dati e dispone di algoritmi di machine learning e di elaborazione di dati grafici, funzionalità utilizzabili singolarmente o combinabili all’interno di pipeline.
Hadoop e Spark
Hadoop è una tecnologia di elaborazioni di big data ormai diffusa da molti anni. La componente MapReduce, che rappresenta il cuore del sistema di calcolo distribuito di Hadoop, è caratterizzata dall’attuazione di calcoli di tipo one-pass. Applicare questo modello per casi d’uso che richiedono calcoli e algoritmi multi-pass è possibile, attuando, prima dell’inizio del job successivo, la memorizzazione sul file system distribuito dei dati di output di ciascun job MapReduce.
Sono proprio questi meccanismi di replica della persistenza sul file system a rendere questo processo inefficiente. Spark supera questo limite e permette ai programmatori di sviluppare pipeline di dati complesse e a più fasi, utilizzando un modello di Diagramma Aciclico Diretto (DAG). Spark supporta anche la condivisione dei dati in memoria tra i DAG, in modo che job diversi possano accedere agli stessi dati, abilitando la possibilità di eseguire elaborazioni parallele. Spark supera anche il limite di Hadoop che richiede l’integrazione di strumenti esterni per i casi di utilizzo dei big data per il machine learning (p.e.: Mahout) e per lo streaming di dati (p.e.: Storm).
Caratteristiche di Spark
Realizzato in linguaggio di programmazione Scala ed eseguibile attraverso una Java Virtual Machine, Spark implementa le funzionalità riportate di seguito.
- Spark supera le semplici operazioni di mappatura e riduzione definite dal paradigma MapReduce.
- Spark realizza funzionalità integrate di persistenza dei dati in memoria e di elaborazione dati in tempo reale, con prestazioni migliori rispetto ad altre tecnologie di Big Data. Spark è nativamente progettato per gestire la persistenza sia in memoria che su disco, e ottiene in questo modo una maggiore efficienza utilizzando la memoria dell’elaborazione nelle fasi di calcolo intermedio dei dati. Caratteristica particolarmente evidente nei casi d’uso dove è necessario processare in modo ripetuto lo stesso set di dati.
- Spark può essere utilizzato per elaborare set di dati di dimensioni maggiori della memoria complessiva del cluster dove viene eseguito. Infatti durante le operazioni di elaborazione utilizzerà la persistenza su disco una volta saturata la memoria impegnata dai dati in corso di elaborazione, ottenendo per questa via significativi vantaggi prestazionali.
- Fornisce una shell interattiva per i linguaggi Scala e Python.
- Dispone delle API necessarie per sviluppare con i linguaggi di programmazione Scala, Java, Python e R.
Ecosistema di Spark
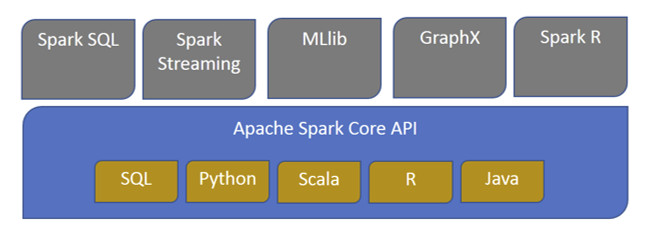
Oltre alle API Core, fanno parte dell’ecosistema di Spark alcune librerie che forniscono funzionalità aggiuntive nelle aree di analisi dei Big Data e del Machine Learning. Vediamole di seguito.
Spark Streaming
Spark Streaming rappresenta il motore di elaborazione dei dati di streaming in tempo reale. Basato sullo stile di elaborazione di micro batch, utilizza quale astrazione di base il DStream, il Discretized Stream, a sua volta rappresentato da una serie di RDD (Resilient Distributed Dataset).
Spark SQL
Questa libreria offre la possibilità di esporre i data-set di Spark attraverso l’API JDBC, consentendo così l’esecuzione di query SQL utilizzando strumenti standard di visualizzazione e di business intelligence. Spark SQL consente agli utenti di attuare trasformazioni ETL dei dati a partire dai formati diversi in cui si trovano (p.e.: JSON, Parquet, database), in modo da esporli attraverso query specifiche.
Spark MLlib
Spark MLlib la libreria di Machine Learning di Spark costituita da algoritmi e funzioni di utilità, tra le quali quelle di classificazione, regressione, clustering, filtraggio collaborativo e riduzione della dimensionalità.
Spark GraphX
È la API Spark per grafici e calcoli paralleli. GraphX estende l’astrazione di Spark RDD introducendo il grafico delle proprietà distribuite resilienti: un multi-grafico diretto con proprietà associate a ciascun vertice e bordo. Per supportare il calcolo del grafico, GraphX espone un insieme di operatori fondamentali (p.e.: joinVertices e aggregateMessages) nonché una variante ottimizzata dell’API Pregel. Inoltre, GraphX include una crescente raccolta di algoritmi e costruttori per semplificare le attività di analisi dei grafici.
Integrazione
Dispone di alcuni adapter di integrazione con altri framework come Cassandra (Spark Cassandra Connector) e R (SparkR).
Il diagramma in Figura 1 sintetizza l’ecosistema di Spark.
La figura 2 descrive i tre componenti del modello architetturale di Spark.
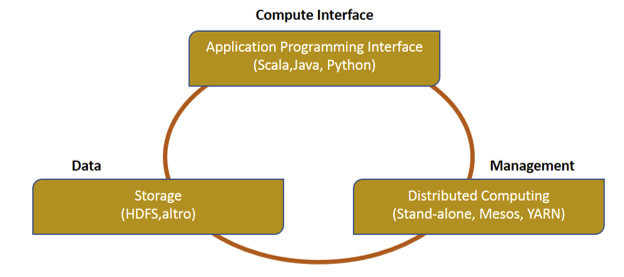
Per l’archiviazione dei dati, Spark utilizza il file system HDFS (Hadoop Distributed File System), fornendo agli sviluppatori un’interfaccia standard per la scrittura di applicazioni in linguaggio Scala, Java e Python. Spark può essere distribuito come server stand-alone o può essere installato su un framework di calcolo distribuito come Mesos o YARN.
Resilient Distributed Data-Sets (RDD)
Il Resilient Distributed Data-Set (RDD) rappresenta l’astrazione principale di Spark. Un RDD può essere immaginato come tabella di un database che può contenere qualsiasi tipo di dato. Gli RDD sono stati progettati e implementati con l’obiettivo di ottimizzare l’elaborazione dei dati e di essere resilienti ai fault. Gli RDD infatti implementano le funzionalità necessarie a ricreare e ricalcolare i data-set. Gli RDD sono immutabili: è possibile modificare un RDD con una trasformazione che ne restituisce uno nuovo, lasciando invariato quello originale.
Gli RDD supportano due tipi di operazioni, la trasformazione e l’azione.
- Trasformazione: l’operazione di trasformazione a partire da un RDD di input ne restituisce uno nuovo. Le principali funzioni di trasformazione sono: map, filter, flatMap, groupByKey, reduceByKey, aggregateByKey, pipe e coalesce.
- Azione: quando una funzione action viene chiamata su un oggetto RDD, tutte le query di elaborazione dati vengono calcolate in quel momento e viene restituito il valore del risultato. Alcune delle operazioni di azione sono reduce, collect , count , first, take, countByKey e foreach.
Spark Streaming
Spark Streaming, estensione dell’API Spark di base, è un sistema di elaborazione di streaming scalabile e fault tolerant. Spark Streaming esegue nativamente elaborazioni di tipo streaming, permette cioè l’elaborazione in tempo reale dei dati provenienti da diverse fonti, e di tipo batch, attraverso l’uso di algoritmi complessi espressi mediante funzioni di alto livello come join, reduce, map e window. Le fonti dati tipiche supportate provengono da Flume, ZeroMQ, Twitter, Kinesis e Kafka. È inoltre possibile elaborare flussi provenienti da socket TCP. È quindi possibile reliazzare la persistenza dei risultati di queste elaborazioni su file system o database, oppure essi possono essere visualizzati su dashboard real-time.
La sua astrazione principale è il Discretized Stream, (DStream) traducibile come flusso discretizzato, che rappresenta un flusso di dati suddiviso in lotti più piccoli.
I DStreams sono basati sull’astrazione base di Spark i Resilient Distributed Dataset, che si potrebbero tradurre come “gruppi” o “collections” di dati distribuiti e resilienti. Attraverso gli RDD, Spark Streaming riesce a integrarsi perfettamente con gli altri componenti del suo ecosistema come MLlib e Spark SQL. Il modello di programmazione unificato per batch e streaming rende Spark completo rispetto a quei sistemi progettati esclusivamente per lo streaming, e che necessitano di strumenti esterni per le elaborazioni combinate batch e streaming. Su tutti questi flussi di dati è possibile applicare gli algoritmi di elaborazione grafica e di machine learning di Spark.
Di seguito le caratteristiche principali di Spark:
- gestione efficiente dei ripristini a seguito dei fault;
- migliore bilanciamento del carico e di utilizzo delle risorse;
- elaborazioni basate sull’integrazione tra dati in streaming, dati statici e query interattive;
- integrazione nativa con librerie di elaborazione avanzate (SQL, machine learning, elaborazione grafica).
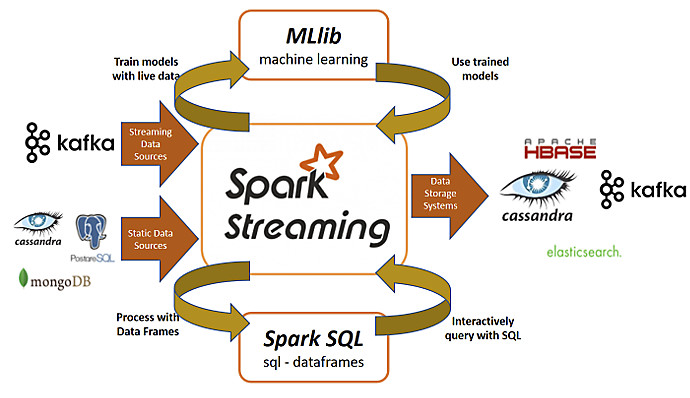
Questo modello di elaborazione unificato dei dati può essere considerato il fattore chiave del successo di Spark Streaming, che semplifica attraverso un unico framework le diverse esigenze di elaborazione.

L’immagine di figura 4, attualizzando la big picture precedente, rappresenta il processo immaginato per la piattaforma digitale di data ingestion e monitoraggio real-time dei dati descritta in questa serie di articoli.
Funzionamento di Spark Streaming
La figura 5 descrive il funzionamento di Spark Streaming. Spark Streaming acquisisce flussi continui di dati di input e li divide in batch. Questi ultimi vengono quindi elaborati da Spark che ne genera un risultato sotto forma di altri batch.
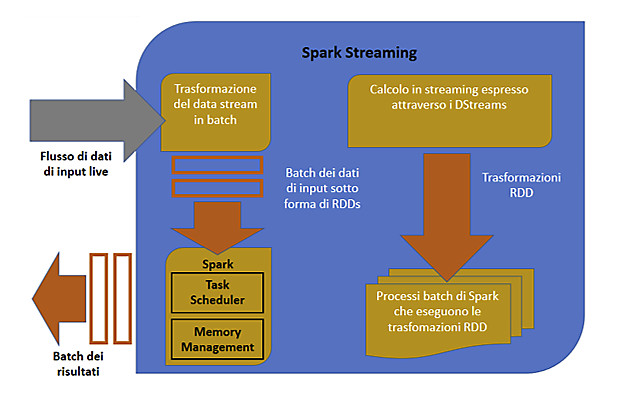
Il funzionamento di Spark Streaming si basa sul Discretized Stream o DStream, una astrazione di alto livello che consiste in un flusso continuo di dati, internamente rappresentato da una sequenza di RDD (Resilient Distributed Dataset). I DStream possono essere creati applicando operazioni di alto livello, quali join, reduce, map, window su altri Dstream o su flussi di dati di input da sorgenti esterne (es: Kafka).
Un RDD rappresenta una raccolta di elementi, partizionati tra i nodi del cluster di Spark, che possono essere gestiti in parallelo. Ciascun RDD viene reso persistente in memoria in modo da poter essere riutilizzato in modo più efficiente in un contesto di elaborazioni eseguite in parallelo. Tra le caratteristiche di un RDD è significativa quella di poter essere ripristinato in modo automatico in risposta a eventuali fault di un nodo.
L’immagine in figura 5 mostra come ogni RDD esistente in un DStream sia relativo a dati di un intervallo temporale specifico.
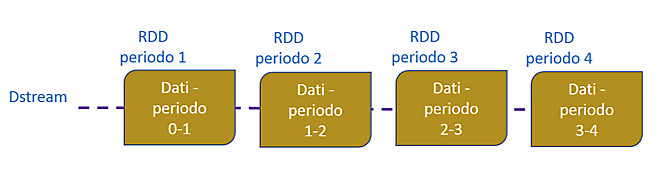
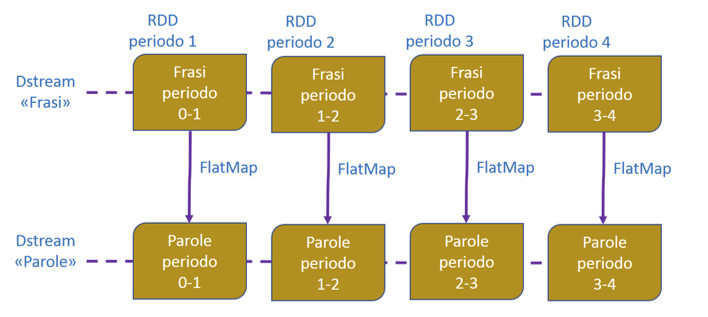
Tutte le operazioni applicate a un DStream vengono tradotte in operazioni applicabili ai corrispondenti RDD. Nell’immagine di figura 7, un esempio di operazione FlatMap è stata applicata a ciascun RDD.
Come abbiamo visto, i DStream rappresentano il flusso di dati di input che viene ricevuto dalle fonti di streaming. Fatta eccezione per il flusso da una fonte di tipo file, ogni input Dstream è collegato a un oggetto Receiver, che memorizza i dati ricevuti nella memoria di Spark, in modo tale che siano pronti per essere sottoposti a una potenziale elaborazione.
Spark Streaming dispone di due categorie di sorgenti di streaming integrate: le fonti standard e le fonti avanzate. Le fonti standard, come le connessioni socket e/o il file system, sono disponibili direttamente nell’API StreamingContext. Per le fonti avanzate, che includono ad esempio Kafka, sono disponibili delle classi di utilità, e per queste è necessario un’integrazione con dipendenze aggiuntive di runtime.
È possibile creare molteplici DStream di input, questo nel caso in cui sia necessario ricevere in streaming flussi di dati in parallelo, attraverso la creazione di ricevitori distinti.
Moduli della piattaforma digitale di monitoraggio “real-time”
In figura 8 è riportata la rappresentazione di alto livello dei framework scelti e dei componenti applicativi sviluppati per la soluzione di monitoraggio real-time del traffico veicolare.
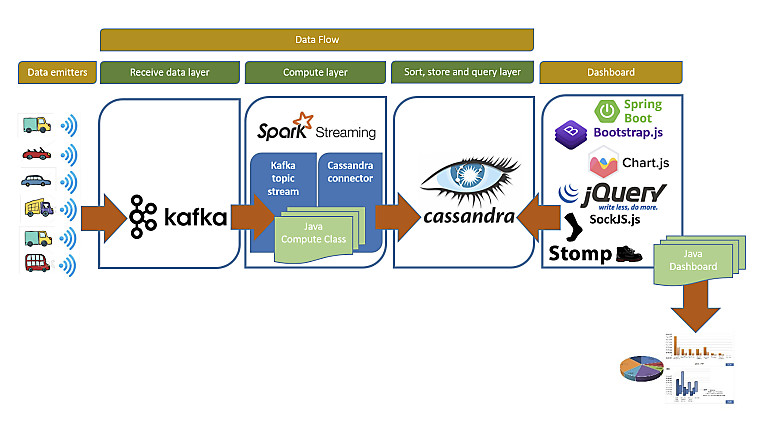
Attraverso i loro dispositivi di connettività di bordo, i veicoli in circolazione inviano a un topic di Kafka, a intervalli regolari, i dati oggetto di analisi di monitoraggio. Si tratta di informazioni sulla posizione, velocità, livello di carburante, temperatura di dispositivi o di dotazioni di bordo potenzialmente critiche (p.e.: frigoriferi), rilevatori di criticità di merci pericolose o di conservazione di merci deperibili.
Il modulo Spark Streaming processerà quindi i nuovi messaggi presenti sul topic Kafka e, dopo aver applicato le elaborazioni necessarie a soddisfare i requisiti di monitoraggio stabiliti, ne renderà persistenti i risultati sull’istanza di Cassandra. Le informazioni di monitoraggio sono quindi visualizzate all’utente attraverso una web application basata su Spring Boot che interroga a intervalli stabiliti le tabelle di Cassandra.
Conclusioni
Conclusa la parte descrittiva dei framework e presentata la big picture del sistema, nelle prossime puntate verranno descritte le integrazioni tra questi framework, mostrando le implementazioni di dettaglio dei moduli del sistema di monitoraggio real-time del traffico veicolare.