

Introduzione alle metriche in Kanban
In questa serie di articoli parleremo di metriche [1]: perché usarle, quali usare, come usarle. Le metriche descritte sono particolarmente utilizzate in Kanban [2] ma si possono facilmente applicare alla maggior parte dei team.
Ogni metrica serve a rispondere a una domanda in particolare. Alcune potrebbero non essere applicabili al contesto in cui si lavora ma spero di mostrare come, raccogliendo anche pochissimi dati, possiamo generare metriche e grafici che ci aiutano ad avere discussioni migliori, risolvere problemi specifici e a migliorare. Il mio invito è di prendere spunto da questi articoli per decidere cosa può aiutare il vostro team, nella vostra situazione.
A tal fine, gli esempi mostrati sono presi da dati reali raccolti dal mio team e dall’uso quotidiano che ne facciamo.
Perché usare metriche
Usiamo le metriche descritte in questi articoli per due principali motivi: perseguire il miglioramento continuo e raggiungere un certo grado di prevedibilità (intesa come possibilità di fare delle previsioni relativamente attendibili).
Per guidare il miglioramento continuo, le metriche ci danno indicazione di dove possiamo migliorare e validano l’efficacia dei cambiamenti che introduciamo. Una delle pratiche di Kanban dice “evolve experimentally”; le metriche ci aiutano a trattare i cambiamenti come una serie di piccoli esperimenti che sopravvivono solo se si dimostrano positivi.
La prevedibilità si persegue usando i dati storici che raccogliamo per migliorare le nostre previsioni. Quando ci viene chiesta una stima, possiamo basarci su dati reali invece che solo sul nostro intuito, e addirittura usare semplici modelli matematici per effettuare simulazioni.
Buone metriche
Quando si parla di metriche la reazione iniziale di molti è di starne alla larga: abbiamo tutti visto o vissuto “film dell’orrore” incentrati sulle metriche, in cui queste hanno finito per fare più danni che altro.
Pensiamo all’esempio più famoso di metrica andata storta: la velocity [3]. Non c’è voluto molto perché i manager iniziassero ad esigere velocity più alte dai loro team, e perché i team capissero che, per farli contenti, bastava raddoppiare i punti di ogni storia: manager felici, team felici, premio produzione per tutti! Mmmh, peccato che non funzioni proprio così…
Diciamolo chiaramente: con ogni metrica si può barare e ogni metrica può causare disfuzioni. Per questo è importante capire quali sono le caratteristiche di buone metriche e come usarle a buon fine: vediamo di seguito alcune caratteristiche tipiche di una buona metrica.
Migliorare il sistema
Le buone metriche aiutano a migliorare il sistema, invece che a premiare o punire singoli individui. William Edwards Deming osservò che il 95% delle performance di un sistema è attribuibile al design del sistema stesso e solo il 5% è legato alle persone che ne fanno parte: è la cosiddetta regola 95/5 di Deming [4]. Questo significa che per migliorare non basta dire alle persone: “Lavora più sodo! Dài il massimo!”. Prima di tutto è offensivo perché assume che le persone non stiano già facendo del loro meglio; ma anche nel caso in cui migliorassero, si avrebbe un impatto minimo. Per fare la differenza dobbiamo cambiare il sistema: migliorare il processo, fornire gli strumenti necessari, creare un ambiente ottimale, rimuovere impedimenti, eliminare sprechi, etc.
La metrica non è un obiettivo
Le metriche di buona qualità, poi, non sono mai un obiettivo da raggiungere ma un semplice feedback su come stiamo andando. Ci interessa sapere se stiamo migliorando, ma non arrivare a un particolare numero. Il trend è più importante del numero in sé.
Leading indicator
Le metriche, poi, sono dei leading indicator: si tratta cioè di indicatori che denotano una tendenza e ci avvertono dell’insorgere di un problema quando ancora non si è manifestato nelle sue conseguenze. In tal modo possiamo adottare delle adeguate misure volte a intervenire su questo aspetto.
Il team influenza la metrica
Metriche buone sono influenzabili dal team con le sue considerazioni e le sue azioni. Altrimenti, metriche su cui non si può fare nulla avrebbero solo l’effetto di demoralizzarci…
Le buone metriche vanno guardate nel complesso
Spesso si corre il rischio di valutare l’andamento del progetto analizzando una sola metrica. Invece, per poter dire che stiamo migliorando, le metriche buone devono migliorare tutte. Se ci concentriamo solo su una di esse, finiamo per cadere nella classica trappola delle ottimizzazioni locali cui non corrisponde necessariamente un miglioramento globale.
Raccolta e analisi dei dati
È chiaro che, se non abbiamo dei dati da “misurare” in qualche maniera… non potremo neanche creare delle metriche, buone o cattive che siano. La raccolta e l’analisi dei dati possono apparire a volte come attività difficili e faticose, ma la realtà è diversa. Vediamo alcune considerazioni in tal senso.
Registrare le transizioni di stato
Il modo più semplice meno faticoso per raccogliere dati consiste semplicemente nel registrare quando avvengono le transizioni di stato per una storia.
Noi lo facciamo fisicamente: ogni volta che la storia si sposta sulla lavagna, la “timbriamo” con la data del giorno per registrare il cambio di stato, e poi regolarmente copiamo queste date in uno spreadsheet che genera tutte le metriche mostrate in questi articoli.

Quasi ogni metrica è ricostruibile da questi semplici dati in input: le date delle transizioni infatti sono sufficienti per ricostruire quanto tempo la storia ha impiegato dall’inizio alla fine, quanto tempo ha trascorso in ogni stato, e quali storie erano in ciascun stato in ogni giorno particolare.
Se può aiutarvi a comprendere meglio questi concetti, potete dare un’occhiata alla versione pubblica del nostro spreadsheet [5].
Work Item Type
È molto importante identificare quelli che tecnicamente in Kanban si chiamano Work Item Type: i “tipi di lavoro” che possono capitare nel nostro processo.
Spesso diversi tipi potrebbero seguire un diverso processo: per esempio, saltare alcune colonne o avere step aggiuntivi. O magari, tipi diversi di lavoro potrebbero seguire gli stessi passaggi ma con regole diverse: ad esempio, per un particolare tipo possiamo fare un deploy subito, per altri dobbiamo aspettare fino al venerdì e così via.
Nel mio team, al momento abbiamo tre tipi di storie: uno che può essere rilasciato solo ogni due settimane, uno che può essere rilasciato appena è pronto, e uno che va direttamente da “dev” a “done” saltando molti step.

Perché tutto questo è importante? Perché quasi ogni metrica ha senso solo se applicata ad un singolo tipo di lavoro! Non ha senso comparare storie che seguono diversi processi… perché i tempi possono essere molto differenti.
Nota per chi è un po’ più addentro alle definizioni di Kanban: quando dico work item type non intendo class of service. Sono due cose diverse che spesso vengono confuse. La class of service riguarda l’urgenza del lavoro, non il tipo.
Tool o no tool?
Una delle domande che ricevo più spesso è: “ma perché invece di uno spreadsheet non usate <inserire il tool preferito>?”.
Nella mia esperienza personale molti tool hanno due problemi:
- nella raccolta dati hanno spesso limitazioni a rappresentare la realtà, e quindi raccolgono dati che non sono reali;
- nell’analisi dei dati, le metriche e i grafici che offrono sono limitati; magari ne implementano alcune bene, ma non c’è modo di fargli fare quello di cui abbiamo bisogno.
In definitiva: se uno si trova bene con il suo tool, va benissimo che continui a usarlo, visto che il mio obiettivo con questi articoli non è di far cambiare idea sui tool. Però tenevo a precisare questi aspetti relativi ai limiti dei tool, affinché le decisioni siano prese in modo ragionato: nel mio team ci siamo resi conto che, per il nostro uso, lo spreadsheet è il miglior compromesso tra libertà di implementare quello che ci serve e sforzo nel mantenerlo.
Ignorare i dati vecchi
Può sembrare strano ma io consiglio di non utilizzare dati troppo vecchi. Se si sta facendo veramente Agile o Kanban, il team dovrebbe trovarsi in un processo di miglioramento continuo: quindi dati vecchi idealmente non sono più rappresentativi del team e del processo attuale.
Quale periodo esattamente tenere in considerazione dipende dal contesto; nel mio team solitamente usiamo gli ultimi 4-5 mesi, massimo 6. I dati più vecchi smettono di essere tenuti in considerazione: li spostiamo in spreadsheet “storici”, che archiviamo nel caso un giorno possano tornare utili.
Quanti dati mi servono per iniziare?
Ogni metrica serve a risolvere un problema in particolare, quindi la quantità di dati necessari dipende dalla metrica e da cosa stiamo cercando di risolvere. In generale però bastano molti meno dati di quello che si pensa.
- con 5 campioni sappiamo che la mediana sarà compresa tra questi 5, quindi possiamo iniziare a farci un’idea dei nostri tempi e a fare semplici proiezioni (rule of five [6])
- con 11 campioni conosciamo il range dei campioni: c’è il 90% di probabilità che ogni altro campione sarà compreso in quel range (German tank problem [7]). È abbastanza per essere nel range giusto di numeri e per ridurre drasticamente l’incertezza
Ovviamente ogni campione successivo aiuta a raffinare ulteriormente la nostra precisione, ma per partire bastano pochissimi dati.
Metriche per il flusso: Cumulative Flow Diagram
La metrica più famosa in assoluto in Kanban è il Cumulative Flow Diagram (CFD). Serve a osservare il flusso di lavoro e a rispondere a domande quali
- “C’è un buon flusso di lavoro?”
- “Le storie si muovono in modo regolare sulla lavagna?”
- “Ci sono impedimenti?”
- “Ci sono colli di bottiglia?”
- “Le storie si spostano in modo fluido o in grandi gruppi?”
e a molti altri interrogativi.
Come funziona il CFD
Per ogni giorno si contano quante storie sono in ogni stato (figura 3).
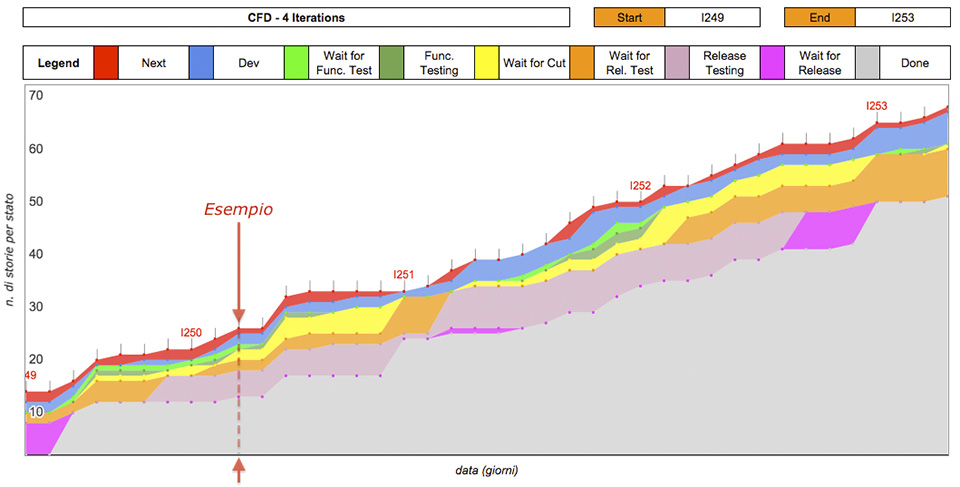
In questo esempio, nella data evidenziata, c’erano 11 storie in “Done”, 5 storie in “Release Testing”, 2 storie in “Waiting for Release Testing”, 2 storie in “Waiting for Cut”, 1 storia in “Waiting for Functional Testing”, 2 storie in “Development”, 1 storia in “Next”.
A noi piace annotare anche qualche informazione aggiuntiva, per esempio quando inizia ogni iterazione (I250, I251, etc.)
Un buon CFD, per un team che ha un buon flusso di lavoro, mostra linee che crescono in modo costante in parallelo. Significa che le storie si muovono di stato in stato in modo regolare.
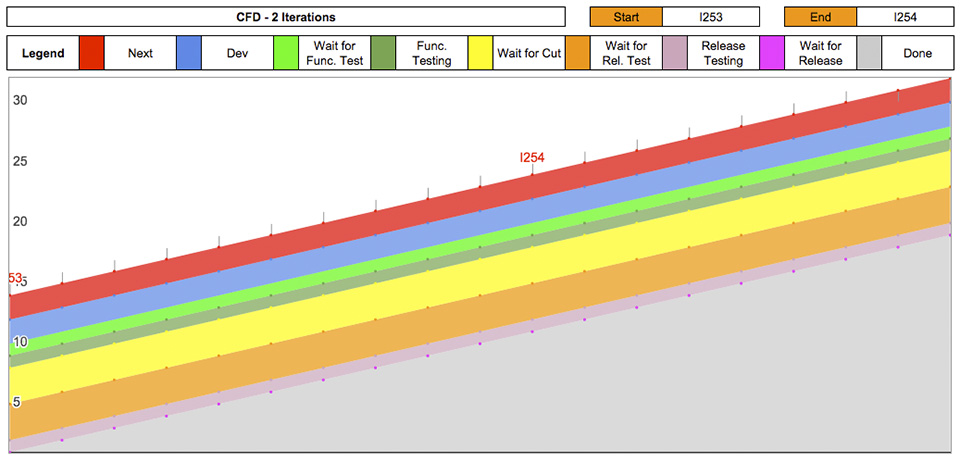
Nonostante sia piuttosto famoso il CFD non è particolarmente facile da interpretare. Molti si trovano in difficoltà a capire come si usa in pratica, soprattutto le prime volte. Ma se si impara a leggerlo se ne può ricavare una grande quantità di informazioni: un coach esperto può guardare il CFD di un team e farsi un’idea dei loro problemi.
Il CFD si presta a svariati utilizzi, anche a seconda del contesto in cui lo si adotta. Di seguito se ne riportano alcuni tra i più comuni, ma a questi si possono aggiungere anche altri usi.
Uso 1: in retrospettiva
Si può usare un CFD in una retrospettiva o una Root Cause Analysis per:
- ricostruire gli eventi in un particolare periodo di tempo di cui stiamo discutendo;
- discutere dei pattern che osserviamo.

In questo esempio ho evidenziato un gruppo di storie che si stanno accumulando nella zona in verde chiaro, “Waiting for Functional Testing”. In quel periodo avevamo un solo tester e il Test Manager aveva imposto una policy per cui solo i tester potevano testare le storie; agli sviluppatori non era permesso. L’unico tester era impegnato e quindi le storie si stavano accumulando in attesa di essere testate. Abbiamo fatto una retrospettiva con il Test Manager usando il CFD per mostrare l’effetto della sua policy e lo abbiamo convinto a rimuoverla: l’intero team ora collabora per sviluppare e testare una storia.
È un classico esempio di come la disponibilità di dati e grafici aiuta ad avere discussioni migliori: invece di dibattere su opinioni personali, si parla di fatti e dati reali.
Uso 2: validare esperimenti
Nel CFD possiamo osservare se gli “esperimenti” che introduciamo hanno effetto positivo o negativo (figura 6).
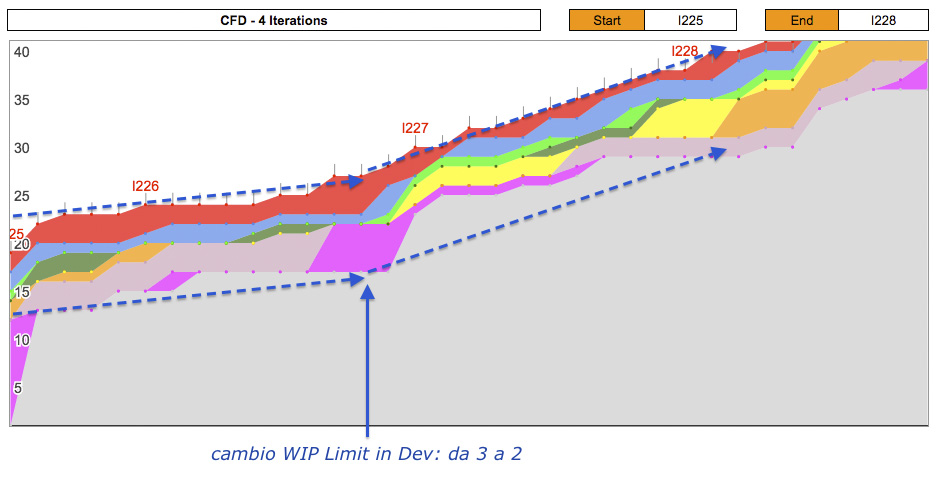
Questo esempio mostra un periodo in cui avevamo 6 sviluppatori; noi lavoriamo in pair programming, quindi c’erano 3 coppie. Nel periodo del CFD sulla sinistra il WIP Limit in sviluppo era 3, e si vede come le linee sono quasi piatte. Linee piatte sono un segnale di allarme, significa che le storie non si muovono sulla lavagna. Non c’è flow.
Decidemmo quindi di provare un esperimento: ridurre il WIP Limit in sviluppo a 2. Ci sarebbe sempre stata una coppia libera per aiutare gli altri, proteggere da interruzioni, etc. Questo è quello che in Kanban viene detto slack [8] [9] [10].
Vedete come il flusso cambia immediatamente direzione? Ora le storie si muovono molto più rapidamente, sono completate più in fretta e l’intero team è sempre aggiornato su ogni storia così da poterla continuare in caso di necessità.
La domanda lecita è: “Bene così… ma cosa faceva tutto il giorno la coppia che era libera?”. È una domanda tipica per chi non ha molta esperienza con i WIP limit. Abbiamo pertanto creato un cheatsheet [11] per aiutare i membri del team a decidere cosa fare quando sono liberi o bloccati: po’ essere un esempio per creare i vostri, tenendo presente che le nostre regole potrebbero non valere per altri team.
Uso 3: estrarre informazioni
Dal CFD si possono estrarre alcune informazioni: Lead Time approssimativo, Work In Progress approssimativo, Throughput approssimativo e si può persino fare una proiezione della Delivery Date, in stile burnup chart.
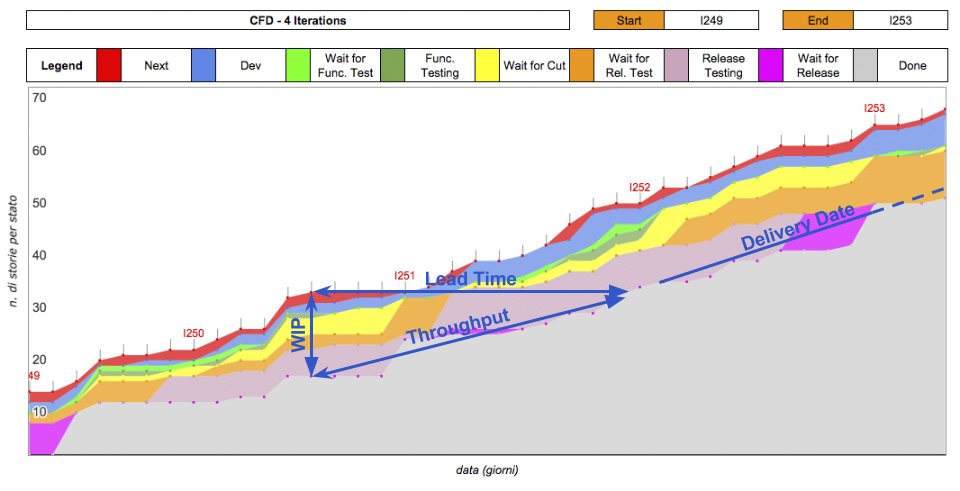
In rete ci sono molti esempi [12] che spiegano come leggere queste statistiche nel CFD. Se poi avete a disposizione le date delle transizioni delle storie, queste statistiche sono ancora più facili da ottenere e più precise nel loro valore informativo.
Pattern in CFD
Nei Cumulative Flow Diagram, si possono evidenziare una serie di pattern ricorrenti, i quali sono in grado di darci indicazioni piuttosto chiare sui problemi del team. Noi abbiamo creato una “slide” di riferimento con i vari pattern che ci danno informazioni in base all’andamento del grafico (figura 8).
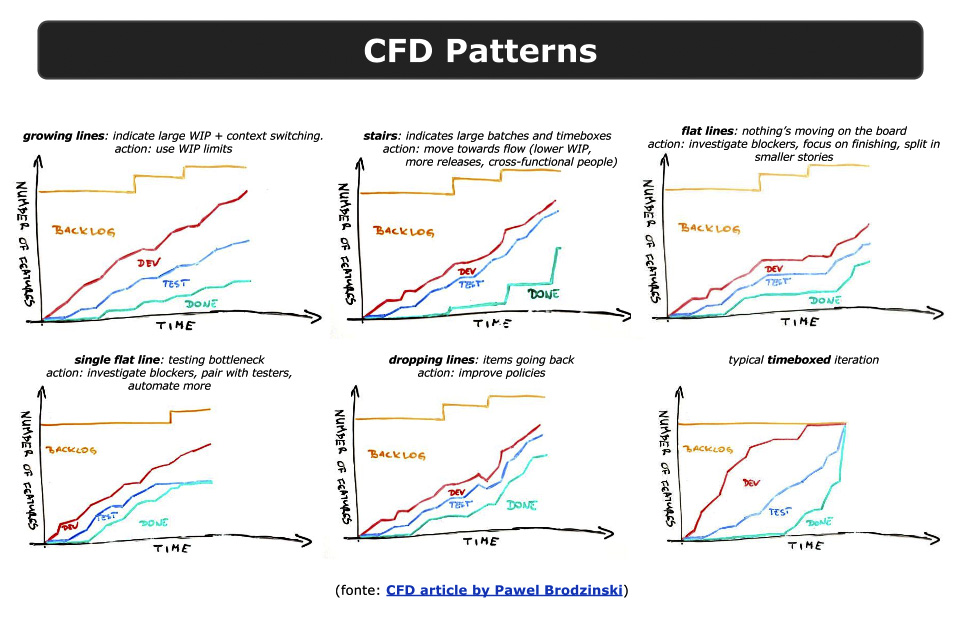
Consiglio di leggere l’articolo [13] da cui sono presi gli esempi per una spiegazione più dettagliata di ciascun pattern.
Conclusioni
In questo articolo abbiamo spiegato i motivi per cui usare le metriche, come usarle a buon fine e come raccogliere i dati che ci servono. Abbiamo poi visto come utilizzare il primo tipo di metrica, il Cumulative Flow Diagram, per osservare il flusso, il flow.
Nei prossimi articoli di questa serie parleremo di altri tipi di metriche (Delivery Time, Prevedibilità, Qualità, e Miglioramento Continuo) e di come usare i nostri dati per fare previsioni.
Riferimenti
[1] Daniel S. Vacanti, Actionable Agile Metrics for Predictability: An Introduction, 2015
[2] Una guida agli elementi essenziali di Kanban
http://www.leankanban.com/guide
[3] Il concetto di velocity
http://guide.agilealliance.org/guide/velocity.html
[4] Sulla regola 95/5 di Deming
[5] Versione pubblica del nostro spreadsheet:
[6] Rule of five
http://www.r-bloggers.com/simulating-the-rule-of-five/
[7] German Tank Problem
https://en.wikipedia.org/wiki/German_tank_problem
[8] Lo “slack time”
http://brodzinski.com/2012/05/slack-time.html
[9] A Myth of 100% Utilization
http://brodzinski.com/2012/03/myth-of-100-utilization.html
[10] Slack is not a dirty word: How ‘slack’ can improve your products
[11] How to use slack time – Example
[12] Statistiche dal CFD:
http://scrumandkanban.co.uk/littles-law-and-cfds/
[13] Cumulative Flow Diagram
http://brodzinski.com/2013/07/cumulative-flow-diagram.html
Mattia Battiston è un software developer con una grande passione per il miglioramento continuo. Attualmente lavora a Londra e utilizza Kanban, Lean e Agile per aiutare diversi team a migliorare.