

Introduzione
In questa serie di articoli parliamo di metriche che ci aiutano nel miglioramento continuo. Negli scorsi numeri abbiamo discusso di metriche per osservare, migliorare e prevedere il flusso di lavoro e i tempi di consegna.
In questo articolo proseguiamo la discussione, introducendo metriche che ci aiutano a migliorare la nostra prevedibilità: nonostante l’uso di pratiche come Story Point sia quasi la normalità, vedremo che queste tecniche possono presentare dei problemi. Discuteremo al riguardo di ciò che è possibile fare per integrarle e migliorarle.
Ci tengo sempre a ricordare che probabilmente non tutto è applicabile al vostro contesto, o magari non lo è al momento attuale. Mi auguro però che queste idee possano esservi di ispirazione per generare spunti di miglioramento. Se sarò riuscito a convincere un po’ di lettori a usare anche solo una o due metriche tra quelle prsentate… potrò considerare questi articoli un successo!
Il problema di Story Point e Velocity
Tradizionalmente i metodi agili suggeriscono l’uso di tecniche come Story Point [1] e Velocity [2] per fare previsioni. In Scrum per esempio il team stima le storie in punti e poi usa la velocity per rispondere a domande come “Quante storie dovrei includere nel prossimo sprint?” o “Quando completeremo questo gruppo di storie, o questo progetto?”.
L’uso di queste pratiche è così diffuso tra i team agili che è ormai quasi considerato la normalità. Eppure esiste anche un problema con questo approccio, che vediamo di seguito.
Problema: scarsa correlazione con Lead Time
Quando sono arrivato, circa due anni fa, nel gruppo in cui lavoro, il team era abituato a usare il Planning Poker [3] per stimare in punti. All’epoca seguivamo ancora Scrum, prima di introdurre Kanban.
Trovandomi in un team nuovo, ero curioso di capire se le nostre stime avessero senso e se fosse possibile capire il nostro grado di prevedibilità, nel senso di accuratezza delle pervisioni che facevamo. Pertanto, iniziai a raccogliere alcuni dati trovando qualcosa di molto interessante.
Il grafico di figura 1 mostra la relazione tra i punti stimati per una storia e tempo impiegato da quella storia per essere completata (Lead Time).
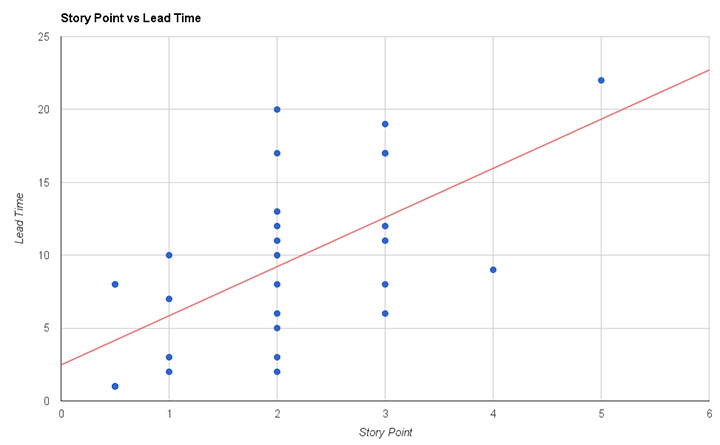
Rimasi assolutamente sorpreso dallo scoprire che storie di 1 punto impiegavano da 2 a 10 giorni; storie di 2 punti impiegavano da 2 a 20 giorni; storie di 3 punti impiegavano da 2 a 18 giorni. C’era pochissima correlazione tra i punti stimati ed l’effettivo lead time.
Con così poca correlazione le nostre stime erano praticamente inutili: basandosi sui punti stimati non avevamo modo di sapere quanto tempo una storia avrebbe impiegato a giungere a conclusione… Di conseguenza anche la nostra velocity non aveva senso ed era altamente imprevedibile.
Previsioni senza stime
Questo grafico funzionò come elemento di shock per il team. Decidemmo che non valeva la pena di continuare a investire tempo ed energie a cercare di stimare le nostre storie. La svolta stava invece nel basare le nostre previsioni su dati storici.
È da questa riflessione che abbiamo sviluppato il nostro attuale metodo di previsione: suddividiamo i requisiti in storie, e poi usiamo le nostre metriche per prevedere quanto tempo queste storie impiegheranno a giungere a conclusione.
In molti casi è sufficiente usare la Lead Time Distribution descritta nello scorso articolo [4] o le metriche descritte in questo articolo, in particolare il Throughput. Per altri casi complessi invece, come la stima di un intero progetto, utilizziamo una tecnica chiamata Probabilistic Forecasting, di cui parleremo in dettaglio tra qualche numero.
Come interpretare questa scarsa correlazione?
Non è che gli Story Point siano un concetto sbagliato in sé, ma ci sono altri fattori che hanno molto più impatto sul Lead Time rispetto ai soli Story Point: spesso questi fattori non vengono considerati e finiscono per rendere inattendibili i nostri tentativi di previsione. Invece si tratta di fattori importanti; vediamoli brevemente di seguito.
- WIP: la quantità di work in progress è un aspetto cruciale. Quando lavoriamo su troppe cose allo stesso momento non siamo concentrati sul completare le attività già in corso, perdiamo troppo tempo nel passare da un contesto all’altro, la qualità di ciò che realizziamo diminuisce. Alla fine anche storie all’apparenza semplici finiscono per impiegare più tempo di quanto ci si potrebbe aspettare.
- Code: i tempi di attesa… sono tempi da computare nel processo e da visualizzare in qualche modo. Molto spesso nei nostri processi ci sono tempi di attesa tra una attività e l’altra. Per esempio: attesa che uno sviluppatore sia libero per iniziare una storia, attesa che qualcuno sia libero per testare la storia, attesa del rilascio, etc. Queste code sono spesso “invisibili”: non vengono rappresentate sulla lavagna, ed è quindi comportamento comune ignorarle quando si fanno le stime. Quando queste code non sono gestite portano all’accumularsi di attività in attesa e a conseguente imprevedibilità nel Lead Time.
- Imprevisti: eventi inaspettati come blocchi, problemi urgenti, bug e quant’altro… che ci portano a interrompere e mettere in attesa attività già iniziate. Anche la più semplice delle storie impiegherà molto a lungo se non siamo concentrati, se perde tempo in numerosi passaggi di consegne, o se viene scavalcata da problemi più urgenti.
In Kanban il modo più efficace di limitare questi problemi è usare WIP Limits: l’imposizione di un limite per le attivitù che si possono svolgere in contemporanea ci forza a terminare le attività prima di iniziarne di nuove, impedisce alle code di crescere troppo, e rende visibile il costo delle urgenze impreviste.
Smettere con gli Story Point? Dipende…
A scanso di fraintendimenti: non sto dicendo che gli Story Point sono necessariamente cattivi e che dovremmo tutti buttarli via! Per molti team hanno rappresentato un enorme passo avanti dal passato e nel loro processo vengono usati con successo.
Invito però i lettori a farsi una domanda: “Le nostre stime stanno davvero funzionando?”. Qualunque sia processo di stima attuale — che sia in Story Point, T-shirt size [5], ore ideali, e così via — provate a generare un grafico come quello visto in figura 1: c’è correlazione tra le stime e il lead time delle storie? Potreste rimanere sorpresi dal risultato…
Il mio consiglio è di iniziare a raccogliere qualche dato e generare qualche metrica, ma inizialmente senza smettere di seguire l’attuale processo. Dopo un po’ avrete dati alla mano per decidere quali pratiche funzionano meglio per voi e vi rendono più prevedibili. E se doveste decidere di abbandonare gli Story Point, avendo qualche dato a disposizione sarà molto più facile convincere chi vi sta intorno che è meglio cambiare.
Il dibattito nella comunità Agile
Quello di stime e previsioni è un tema caldo che sta generando numerose discussioni. Molte persone hanno opinioni forti su stime e Story Point, sia a favore che contro.
Sempre più team nella comunità Agile stanno trovando simili a quelli qui presentati, come nel caso di Vasco Duarte [6] alfiere dell’approccio “no estimates”. Soprattutto per chi usa Kanban, la tendenza è di dare sempre meno importanza alle stime in favore di metriche e dati reali.
In modo provocatorio, Pawel Brodzinski ha creato un nuovo set di carte per planning poker [7] dove gli unici valori sono “1”, “Troppo grande” e “Non ne ho idea”: in quest’ottica l’unica domanda interessante è se la storia sia sufficientemente piccola, senza bisogno di stimare se la dimensione esatta sia 5 o 8.
Throughput: quante storie completerò nel prossimo periodo?
Il Throughput — spesso chiamato anche Delivery Rate — rappresenta il numero di storie completate in un particolare periodo di tempo. È utilissimo per rispondere a domande del tipo “Quante storie possiamo completare nelle prossime due settimane?”. È semplicissimo da calcolare e dà moltissimo valore: per questo è una delle metriche più conosciute.
Come funziona
Basta contare il numero di storie che sono state completate in un periodo di tempo. Il periodo potrebbe essere ogni due settimane, ogni mese, ogni trimestre, etc. Nel mio team pur usando Kanban facciamo ancora riferimento a periodi di due settimane e li chiamiamo “iterazioni”.
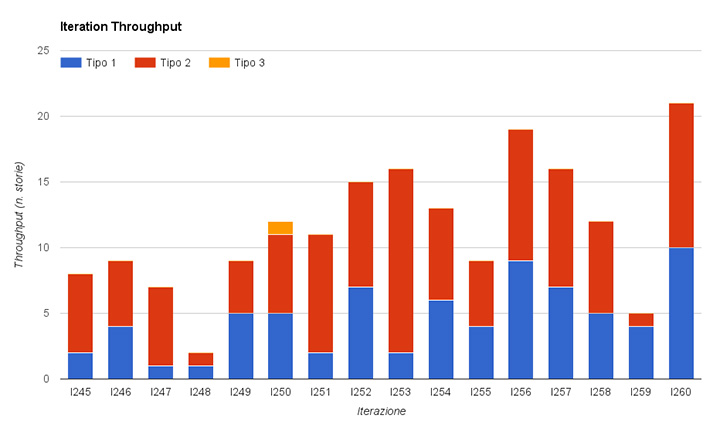
È importante suddividere il Throughput per tipo di lavoro per sapere quante storie di un particolare tipo completiamo solitamente in una iterazione; poi si può usare questa informazione per fare previsioni.
Uso: previsioni nel breve periodo, per esempio queue replenishment
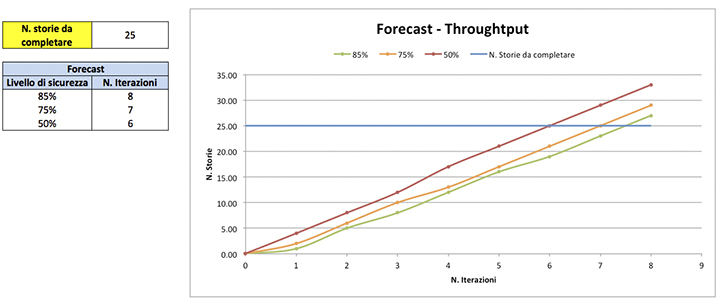
“Quante storie posso completare nel prossimo periodo?”. Per chi usa Kanban la domanda potrebbe sorgere durante il queue replenishment [8] quando stiamo decidendo quante e quali storie dovremmo tirare dentro il nostro sistema. Per chi invece usa Scrum è una domanda fondamentale durante lo Sprint Planning. Possiamo facilmente rispondere usando qualche statistica sul Throughput (figura 3).
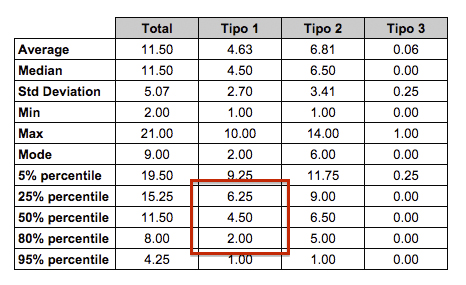
Concentriamoci per un attimo solo sul Tipo 1: guardando i nostri percentili sappiamo che nell’80% dei casi completiamo almeno 2 storie. Il 50% delle volte arriviamo a completarne anche 4 o 5, ma solo il 25% delle volte raggiungiamo 6 storie. Quindi per stare in un alto livello di sicurezza conviene tirare dentro almeno 2-3 storie, ma probabilmente anche 4. Potremmo assumere più rischio e scegliere 6 storie ma c’è una alta probabilità che alcune non verranno completate.
Sappiamo inoltre che, oltre a quelle storie di Tipo 1, nell’80% delle iterazioni completiamo anche 5 storie di Tipo 2, quindi potremmo tirare dentro anche un po’ di queste. In totale potremmo quindi scegliere qualcosa come 4 storie di tipo 1 e 5 storie di tipo 2.
In base alla priorità delle storie osserviamo il Throughput di quel tipo di storie per decidere quante storie possiamo completare nel prossimo periodo.
Notate come questo approccio rende i meeting di planning molto più veloci: se sappiamo che raramente completiamo più di 6 storie diventa inutile discutere di storie che neanche inizieremo; ci concentreremo solo sulle prime sei.
Uso: stiamo migliorando?
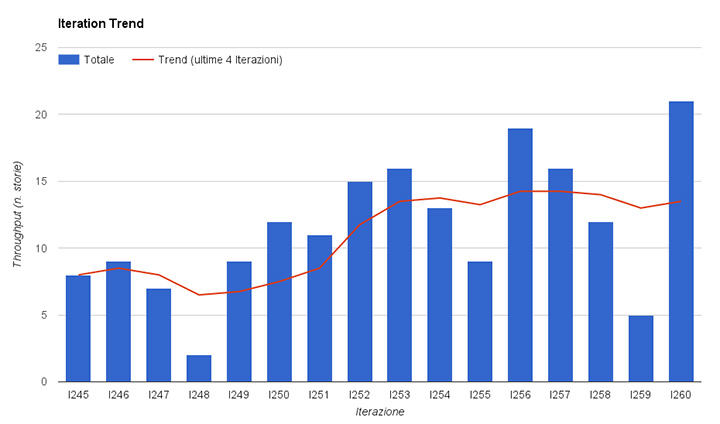
Troviamo utile visualizzare il trend del Throughput per capire in quale direzione sta andando. Stiamo completando più o meno storie? Stiamo diventando più o meno veloci?
Nel nostro team, usiamo il Throughput durante i meeting di Metrics Review, quando rivediamo i nostri dati e decidiamo se gli ultimi cambiamenti che abbiamo introdotto stanno avendo effetto positivo o negativo.
In figura 4, il trend è calcolato come la media sulle ultime 4 iterazioni.
Uso: previsioni nel lungo periodo
Supponiamo di dover analizzare un gruppo di storie – potrebbe trattarsi di una nuova grossa funzionalità, o di un progetto — e di dover rispondere alla classica domanda “Quando sarà pronto?”.
Se non è necessaria una precisione altissima, potete semplicemente usare la media del Throughput per fare una proiezione in stile Burn-Up Chart. Usare la media è pericoloso [9] ma, se state solo cercando di farvi un’idea dei tempi, potrebbe essere abbastanza indicativa.
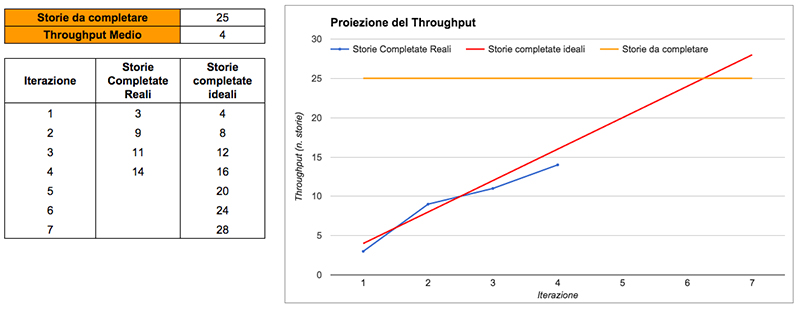
Se volete più precisione, e soprattutto se volete gestire il rischio associato al progetto, occorre rivolgersi al cosiddetto Probabilistic Forecasting. In ogni caso, il valore Throughput è il dato di base per fare Probabilistic Forecasting e quindi resta una metrica importante. Torneremo su questo argomento in dettaglio in uno dei prossimi articoli ma, per non lasciare il discorso totalmente sospeso in questa occasione, il Probabilistic Forecasting funziona grosso modo così: si estrae Throughput a random dai nostri dati storici per simulare quante storie possiamo completare in una iterazione. Il risultato è espresso come range di probabilità: abbiamo l’85% di sicurezza che completeremo tutte le storie entro 8 iterazioni, ma solo il 50% di sicurezza che le completeremo entro 6 iterazioni.
Uso: migliorare il nostro processo
Possiamo interpretare i dati del throughput per effettuare alcuni aggiustamenti al nostro processo e migliorarlo. Ad esempio:
- possiamo analizzare la percentuale di tipi di lavoro che completiamo per capire meglio su cosa lavoriamo maggiormente, da dove viene quel lavoro e chi sono i principali stakeholder;
- possiamo decidere la dimensione della coda di input del nostro processo. Quante storie dovremmo tenere pronte in “Next”? Se sappiamo che in due settimane di solito completiamo da 2 a 5 storie e che il Product Owner è disponibile solo una volta alla settimana per discutere delle prossime storie, probabilmente dovremmo avere 2-3 storie in Next per dare al team sufficiente lavoro per una settimana.
Ma il Throughput non dipende dalla dimensione delle storie?
In effetti sì. Ma come spiegato nell’articolo precedente quando si parlava di Lead Time distribution, il fatto che le le storie debbano avere dimensione simile è un falso mito, perché storie dello stesso tipo seguono la stessa distribuzione. Avremo molte storie veloci, alcune storie un po’ più lente e, di tanto in tanto, qualche storia più grossa.
Capiterà l’iterazione con una storia grossa che abbassa il throughput, ma probabilmente nell’iterazione successiva avremo più storie piccole: quindi questo sbilanciamento tra storie si compenserà.
Work in Progress: su quante cose stiamo lavorando in un giorno?
Kanban ci insegna che limitare il Work In Progress (WIP) ha numerosi vantaggi: più attenzione a terminare attività piuttosto che iniziarne di nuove, maggiore qualità, più flessibilità, slack time per assorbire variabilità, e così via. Per questo vogliamo sapere “su quante cose stiamo lavorando?”, per mantenere questo numero nei limiti che abbiamo stabilito.
Come funziona
Contiamo quante storie sono in corso ogni giorno, e calcoliamo la media giornaliera su periodi di due settimane.
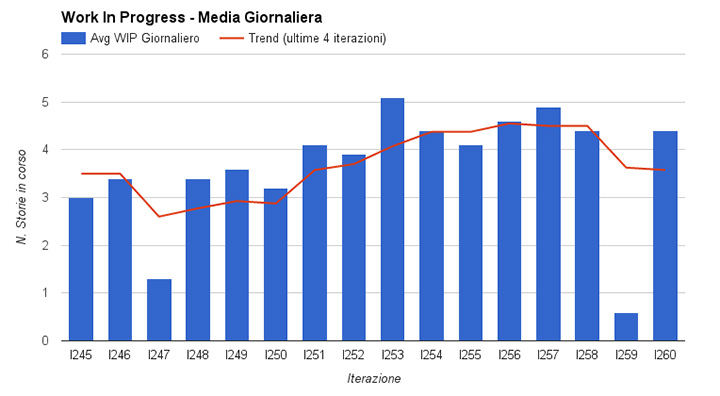
È interessante notare se questa media è stabile, se ci sono oscillazioni, e che impatto queste hanno sulle altre metriche.
Questa è una delle poche metriche che non segmentiamo per tipo di lavoro. Qualsiasi storia in corso conta per il Work In Progress tanto quanto le altre: pertanto preferiamo contarle tutte insieme.
Disney Stations: quando sarà terminata questa storia?
È piuttosto usuale in un parco divertimenti collocare dei cartelli che servono alle persone in fila a capire quanto tempo occorrerà per arrivare a entrare nell’attrazione o nella giostra. Ai giusti intervalli, vengono posizionati cartelli che dicono, ad esempio, “Da qui circa 15 minuti di attesa”. Lo stesso viene fatto, a volte, con i biglietti di prenotazione in certi uffici postali o in certe aziende sanitarie: in pratica si viene messi al corrente del tempo approssimativo che manca alla “evasione dell’ordine”.
Possiamo applicare lo stesso concetto del parco giochi al nostro processo, usando indicatori che definiamo, appunto, Disney Stations per ricordare i cartelli di Disneyland: visualizziamo i nostri tempi di attesa sulla lavagna. Per ogni stato indichiamo “quanto impiegherà da qui la storia per essere finita” e “quanto starà in questo stato”.
Come funziona
Per ogni stato del nostro processo calcoliamo quanto tempo in passato le storie sono rimaste in quello stato e quanto hanno impiegato per andare da lì a “Done”. Da questi risultati si prendono alcuni percentili e li si usano come livelli di affidabilità.

Per esempio: quando una storia è in “Next” siamo sicuri all’80% che la storia starà in “Next” per al massimo 3 giorni e raggiungerà “Done” in 10 giorni o meno. Solo nel 50% dei casi la storia starà in “Next” per un solo giorno e raggiungerà “Done” in 5 giorni.
È un modo semplice e immediato per visualizzare le nostre previsioni. Ci aiuta a prendere decisioni come “Quanto manca per questa storia?”, “Meglio fare un rilascio ora o aspettare che sia conclusa la storia?”, “Possiamo iniziare un’altra storia o è meglio concentrarci su questa?”.
Task Time: quanto manca?
Nel processo seguito dal team in cui lavoro, abbiamo introdotto una policy particolarmente importante: affinché una storia possa muoversi da “Next” a “Development” deve essere stata definita una lista di task che implementeremo come parte della storia.
Spezzare la storia in task ha numerosi vantaggi. Uno in particolare riguarda la prevedibilità: usiamo il numero di task per rispondere alle domande “Quanto tempo impiegherà la storia che stiamo per iniziare ad arrivare a conclusione?”, “Quanto manca all’arrivo?”.
Come funziona
Tenendo traccia di quanto tempo impiega ogni task, abbiamo trovato i seguenti dati: circa il 90% dei nostri task impiega meno di un giorno (il 70% rientra nei tempi di una mezza giornata e un altro 19% necessita di tempi che vanno dalla mezza giornata a un giorno.
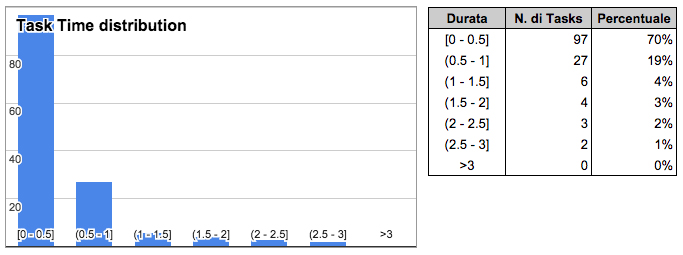
Usando questa informazione possiamo prevedere la durata di una storia non appena ne conosciamo il numero di task: se abbiamo identificato 10 task la storia impiegherà ragionevolmente 6-7 giorni, perché la maggior parte dei task impiegherà mezza giornata e qualcuno impiegherà tutto il giorno.
Notate che questo tipo di previsione è applicabile solo quando la storia sta per iniziare il Development, perché è solo in quel momento che ha senso discutere dei dettagli e definire una lista di task.
Uso: prendere decisioni allo Standup
Allo Standup, per ogni storia, ci chiediamo “Quanti task restano da completare per questa storia?”. In base alla risposta ci facciamo un’idea di quanto tempo manca per finire la storia e decidiamo come assegnare le persone.
Per esempio, se a una storia mancano 8 task significa che potrebbero volerci altri 4-5 giorni di lavoro, quindi preferiamo fare swarming e avere due o più coppie a lavorarci. Se invece mancano solo 2 task preferiamo lasciare una coppia a terminarla, mentre gli altri possono iniziare qualcos’altro.
A proposito, usare task è un ottimo modo di facilitare lo swarming: diverse persone possono lavorare su diversi task e completare la storia molto più in fretta.
Conclusioni
In questo articolo abbiamo analizzato alcuni problemi con i classici metodi di stima. Abbiamo poi introdotto alcune metriche che ci aiutano a fare previsioni basate su dati storici, che possiamo usare per integrare le nostre stime, e un giorno forse addirittura rimpiazzarle. In quest’ottica, la metrica del Throughput, riveste una certa importanza, anche perché può prestarsi a essere integrata in altre tipologie di previsioni.
Nel prossimo articolo di questa serie proseguiremo parlando di metriche per la qualità e per il miglioramento continuo.
Riferimenti
[1] Story Points secondo Agile Alliance
http://guide.agilealliance.org/guide/points-estimates-in.html
[2] Velocity secondo Agile Alliance
http://guide.agilealliance.org/guide/velocity.html
[3] Planning Poker secondo Agile Alliance
http://guide.agilealliance.org/guide/poker.html
[4] Mattia Battiston, Metriche Kanban per il miglioramento continuo – II parte: Metriche per il Delivery Time, MokaByte 215, marzo 2016
http://www.mokabyte.it/2016/03/kanbanmetrics-2/
[5] T-shirt size: stimare le storie con la misura delle magliette
[6] Vasco Duarte, Story Points Considered Harmful – Or why the future of estimation is really in our past…
[7] Le carte da Planning Poker… rivedute e corrette
http://brodzinski.com/2015/02/story-points-velocity-the-good-bits.html
[8] Giovanni Puliti, Kanban, dall’idea alla pratica – In azione: tecniche e suggerimenti, MokaByte 213, gennaio 2016
http://www.mokabyte.it/2016/01/kanban-5/
[9] Sam Savage, The Flaw of Averages, Harvard Business Review
https://hbr.org/2002/11/the-flaw-of-averages
[10] Versione pubblica del nostro spreadsheet:
https://drive.google.com/folderview?id=0B2p8TYBgYF-MdmVrbnk3aDB2dE0&usp=sharing
Mattia Battiston è un software developer con una grande passione per il miglioramento continuo. Attualmente lavora a Londra e utilizza Kanban, Lean e Agile per aiutare diversi team a migliorare.