

Pubblichiamo il resoconto di questa edizione di Better Software, con le nostre riflessioni ‘a freddo’ e il racconto di alcuni degli interventi più significativi cui abbiamo assistito. È stata una conferenza caratterizzata dalla perfetta organizzazione, dalla qualità degli interventi e dallo spirito collaborativo e positivo che si respira per tutta la durata dell’evento.
Introduzione
A distanza di un paio di settimane dalla conclusione della conferenza, pubblichiamo questo articolo riassuntivo, divenuto un appuntamento consueto per MokaByte. Senza lunghi preamboli, diciamo subito che, delle varie edizioni fin qui viste, peraltro sempre interessanti, questa ci è parsa ad oggi la più “matura” ed “equilibrata”. Argomenti diversificati, ma non inutilmente dispersivi o, se preferite, alcune tematiche ampie all’interno delle quali si sono mossi interventi dal taglio e dal tenore molto vario, per tutti i palati e i tipi di pubblico, distribuiti su tre sessioni parallele: Auditorium, Workshop e Startup (al mercoledì) / Interactive (al giovedì).
L’organizzazione [1], poi, è stata davvero puntuale ed efficace: dagli orari rispettati perfettamente (senza però che si avvertisse mai un senso di fretta o di “ansia” come capita a volte in certi eventi), alla location, alla copertura wi-fi ben funzionante e che ha messo molti dei partecipanti in grado di pubblicare sui social network i loro commenti immediati.
A noi, però, spetta invece una riflessione “a freddo”, in una sorta di retrospective, se vogliamo usare una terminologia propria delle metodologie agili, che hanno rappresentato una tematica importante, ma assolutamente non l’unica, di Better Software 2012. Ripetiamo, come sempre, che il ricco programma [2] della conferenza si arrichisce, nei mesi successivi all’evento, della pubblicazione dei video e delle slide dei vari relatori sul sito di Better Software. E a tal proposito, vogliamo usare le parole di uno di essi che dichiarava “Le conferenze sono oasi per scambiare idee. Articoli, slides e video sono utili, ma esserci è un’altra cosa”. Ecco, il discorso è proprio questo, ed è la ragione che giustifica la partecipazione a una conferenza come Better Software: al di là di quello che si ascolta, o si dice, e degli spunti/stimoli che si possono ricevere da alcuni interventi, è proprio la possibilità di scambiare idee in un contesto adatto, con persone sveglie e ricettive, che fa nascere progetti, collaborazioni, lavori e amicizie. Non poco per una “semplice” conferenza.
Le tematiche trattate
Detto questo, che è il succo delle riflessioni, vediamo un po’ di analizzare ciò di cui si è discusso: le grandi aree tematiche sono state quelle dell’Agile & Lean, quelle dell’UX e dintorni con studi sulla progettazione/valutazione dell’esperienza utente e delle interfacce, quella “commerciale” in cui sono stati trattati argomenti inerenti a contratti, licensing e rapporti con i clienti, quella che definisco Architetture & Sviluppo, oltre a una serie di interventi variegati che comunque sono afferenti a un ambito Mobile & IoT. Visione e aggregazioni di temi, le mie, sicuramente opinabili, ma che ci aiutano a tenere una organizzazione nel nostro resoconto.
Agile & Lean
Oramai i dati parlano chiaro: anche le roccaforti della “tradizione a cascata” (per non parlare di chi seguiva le già più evolute metodiche iterative) stanno progressivamente adottando le metodologie agili e la filosofia lean (i sostantivi sono scelti volutamente) per gestire processi aziendali complessi, itinerari di cambiamento, innovazioni nella produzione. D’altro canto, continuano ad esistere tante resistenze ai cambiamenti, specie nelle organizzazioni più strutturate e più incanalate su certi binari da tempi lunghi.
Better Software si è fin dall’inizio posta come un punto di riferimento per la comunità Agile italiana, e tra i suoi relatori “storici” ci sono alcuni eminenti professionisti che hanno cominciato a lavorare con tali metodologie quando in molti non ne parlavano ancora. Un aspetto importante dell’emersione mainstream di tali pratiche è però paradossalmente andato a beneficio proprio degli “adepti” della prima ora, che si sono oramai spogliati completamente di certi atteggiamenti da “detentori della sacra verità”, inizialmente anche giustificabili visto il generale scetticismo con cui venivano accolte le loro proposte, ma oramai divenuti, anch’essi, waste.
Le aziende e i loro processi: sistemi complessi
L’intervento del giovedì mattina “Fare pipì controvento: come danneggiare la propria organizzazione con le migliori intenzioni” di Alberto Brandolini [3], ha affrontato il tema a lui caro della strutturazione delle organizzazioni, dei processi tipici che si instaurano all’interno delle aziende, delle loro cause, presentando alcune soluzioni. Non si è trattato di un intervento “tecnico” che abbia illustrato una particolare implementazione di metodologie agili o un caso di esempio, ma piuttosto di una riflessione, peraltro piuttosto azzeccata, su come sia possibile migliorare i processi aziendali per migliorare i prodotti che da essi devono essere realizzati, grazie a quello che le teorie della complessità e la gestione agile dei progetti ci insegnano.
Il talk parte da un assunto che dovrebbe essere alla base di ogni conoscenza: antropologicamente, il cervello umano funziona sostanzialmente con due modalità. C’è un, diciamo così, sistema 1 caratterizzato da risposte associative immediate a basso costo e in parallelo, e un sistema 2 che fornisce risposte complesse ritardate, necessitanti di concentrazione e di un alto costo energetico, che possono svilupparsi sono a prezzo della dedizione focalizzata a quel determinato task. Il problema di ogni organizzazione strutturata nasce proprio quando si risponde a problemi complessi con la prima modalità: in sistemi complessi, le spiegazioni non possono essere semplicistiche. In tal senso va anche la tipica considerazione per cui, se qualcosa non funziona, è necessariamente colpa dell’IT…
Grazie alla presentazione dei rapporti tra i team auto-organizzanti e il tradizionale organigramma rigido, l’intervento ha messo in luce come la consueta struttura a piramide, per stare su, sta su bene, ma a prezzo di una discrepanza: le informazioni stanno alla base, le decisioni restano in alto. Quindi molte volte le decisioni sono prese nel posto e nel modo sbagliato. È seguito un elenco tipico dei comportamenti “deleteri” riscontrabili in azienda, con la presa d’atto di come spesso le aziende tendano all’auto replicazione di comportamenti, ruoli, figure, piuttosto che alla ricerca di ciò che è davvero cruciale per le sue attività. Ma non tutto è perso: ci sono delle “tecniche” per facilitare i processi di decisione e sbloccare i meccanismi che li frenano. E in certe situazioni, con buona pace del decisionismo di stampo manageriale vecchio stile, sarebbe meglio non prendere nessuna decisione se non si è nelle condizioni giuste per farlo. La piramide ha una alternativa ed è la catena di generazione del valore.
Inutile dire che queste riflessioni, peraltro proposte con la solita ironia, hanno trovato forte riscontro fra i presenti. Ci si rammarica, però, del fattoche a questo tipo di conferenze dovrebbero partecipare di più proprio coloro che stanno ai vertici della piramide, e non quelli che ne costituiscono la base o i filari immediatamente sopra, che già detengono le informazioni e tendenzialmente le condividono…
Seppur con approccio diverso e con esempi distanti, sono stati anche altri gli interventi che hanno affrontato il modo in cui ripensare, organizzare, gestire e migliorare il modo di lavorare dei team che hanno in carico la produzione del software, per rendere più efficaci e sostenibili i processi che ne sono alla base. Non ho assistito al talk di Andrea Provaglio [4] “The Beating Heart of Agile” (ne seguivo un altro in parallelo) ma i dettagliati resoconti che mi sono stati fatti mi hanno permesso di percepire quanto esso abbia toccato un aspetto cruciale, seppure apparentemente banale e spesso dimenticato, ossia che le organizzazioni son fatte di persone e che funzionano bene solo se queste persone operano in modo “organico”, creando un “ecosistema” sostenibile e volto all’evoluzione, al miglioramento continuo, all’apprendimento, nella consapevolezza che c’è un’intelligenza collettiva in grado di emergere dai sistemi sociali complessi, quando essi si auto-organizzano e auto-regolano.
Di conoscenza collaborativa e condivisione delle informazioni ha parlato anche il nostro Giovanni Puliti [5] in “Enterprise community management: creare una comunità all’interno dell’azienda“, che ha presentato un caso di esempio della creazione di comunità per la condivisione di conoscenze nelle grandi organizzazioni, riprendendo i temi trattati in una serie di articoli su MokaByte e ampliandoli con una retrospettiva sull’esperienza di consulenza svolta nel dipartimento IT di una grande azienda assicurativa italiana.

Figura 1 – Creare comunità collaborative all’interno di una grande azienda per migliorare la qualità del lavoro.
Quel che è apparso chiaro da questi interventi, e anche dalle impressioni scambiate con molti partecipanti durante i momenti di pausa e a pranzo, è il fatto che certe competenze tecniche informatiche, alcuni aspetti del project management “tradizionale”, dei basici concetti di psicologia, varie conoscenze derivanti dal marketing più illuminato, le metodologie agili, e l’impostazione lean stanno convergendo verso le cosiddette soft skills della gestione dell’IT. Si tratta probabilmente di un percorso che ancora deve trovare il suo compimento, ma la cui direzione appare tracciata e i cui sviluppi saranno sicuramente interessanti e produttivi.
Strumenti agile e filosofia lean: un approccio razionale
Quasi a fare da contraltare a questi interventi più generali (ma non generici!), Fabio Armani [6] ha presentato due contributi molto puntuali, focalizzati su specifici aspetti dei progetti agili (oltre a condurre una sessione hands on nello spazio Interactive). I suoi talk, che in genere presentano nel dettaglio le più innovative metodologie e tecniche, prendendo spunto da casi di esempio derivanti dal mondo reale, sono divenuti oramai un classico punto di riferimento per queste conferenze e si connotano da un lato per la chiarezza espositiva e la linearità dei concetti esposti (un po’ come nella serie di articoli di introduzione alle metodologie agili pubblicati su queste pagine circa un anno fa [7]), dall’altro per la gran mole di informazioni che riescono comunque a passare, frutto delle sue esperienze lavorative e dei suoi studi (nell’ambito della gestione di progetto e delle metodologie di sviluppo, Armani è una sorta di “repertorio bibliografico vivente”…).
L’intervento che ha concluso i lavori della seconda giornata, “Liftoff: come lanciare team e progetti agili” parte da una considerazione evidente che però spesso non viene portata a conseguenza: la fase di partenza di un progetto è molto importante, specie per mettere tutti i partecipanti nelle condizioni migliori per entrare (e magari rimanere) al meglio nel progetto. Per il lancio dei progetti, viene fatto un parallelismo con la scienza missilistica: per portare in orbita un satellite, una sonda spaziale etc., occorre un vettore, un booster. Lo stesso succede nell’ambito dei progetti agili. Si passa quindi a una analisi dettagliata di alcune pratiche e dei principi agile che ne sono alla base che si sono dimostrati utili nell’affrontare il lancio di attività anche molto complesse. Prendendo spunto dal libro di Diana Larsen e Ainsley Nies [8], vengono descritte alcune pratiche legate a progetti reali mettendone in luce i vantaggi, descrivendone i costi, dettagliandone lo svolgimento. In breve, l’attività di liftoff rappresenta una sorta di Iterazione 0 per un processo come Scrum: l’esempio più volte ripetuto da Fabio Armani può essere riassunto sempre con la metafora del missile; in tal senso Scrum ci dice dove indirizzare e come guidare il missile… Ma prima sul missile occorre far salire gli astronauti: e a questo scopo l’attività agile chartering si struttura sulla base di tre capisaldi: Purpose, Alignment, Context che daranno impeto alla partenza delle attività.
Purpose rappresenta, banalmente, lo scopo del progetto: siamo sempre sicuri che in una grande organizzazione i partecipanti a un progetto abbiano ben presente lo scopo dello stesso e siano pertanto realmente motivati a partecipare al progetto e a lavorare per la sua riuscita? È chiaro che non stiamo parlando di una motivazione superficiale da televenditori quanto piuttosto del fatto che la consapevolezza propria di un modello a rete, e non piramidale, fa ottenere i migliori risultati. Stabilire una visione comune, degli obiettivi chiari, e dei criteri per cui si potrà considerare la “missione compiuta” serve a spingere tutta l’organizzazione in maniera continua e non sulla base di un transitorio entusiasmo.
Alignement punta a creare una sorta di “alleanza” tra tutti i partecipanti, basata su valori condivisi riguardo al lavoro, su pratiche comuni per il lavoro di squadra (working agreement) e su gruppi “multidisciplinari” che lavorano a un obiettivo comune
Context prende in considerazione le risorse, i limiti, gli strumenti analitici con cui si avrà a che fare nel progetto.
Uno degli argomenti su cui si insiste è che questa modalità “live” di operare è molto più fattiva rispetto al classico scambio di “documenti”: i documenti non vengono letti! (o, peggio, vengono letti e interpretati in maniera non allineata dai diversi attori). L’informazione diretta è più veloce e coinvolgente.
Alcuni “giochi” possono aiutare nella conduzione del live chartering: il gioco dell’elevator pitch per capire bene la vision generale e sintetizzarla in poche frasi che ben descrivono il progetto; il gioco della scatola del prodotto in cui, lavorando insieme per creare anche fisicamente la presentazione del prodotto finale, si riesce a capire bene quel che si vuol fare, e quello che non deve stare dentro il progetto. Si conclude mettendo in chiaro come sia bene definire nel dettaglio i flussi di comunicazione e i rapporti tra tutti coloro che sono coinvolti, stabilendo onestamente e realisticamente i valori che si danno alle varie attività del progetto per quanto attiene a tempo, budget, qualità (non tutto può stare “al massimo”, e in ogni progetto ci sono delle priorità). Altra cosa fondamentale è il personale: ossia capire le caratteristiche di tutte le persone che dovranno lavorare al progetto.
Si è trattato di un talk ampio, pieno di informazioni, di sicuro interesse per chi si trovi a dover gestire progetti ampi in organizzazioni molto strutturate.

Figura 2 – Anche se per l’orario (ultimo evento in scaletta al pomeriggio del giovedì), l’intervento sul Liftoff non è stato affollato come quello del mattino, ha però rappresentato uno dei momenti più interessanti.
Nell’altra presentazione, tenuta al mattino, Fabio Armani aveva affrontato il tema “Lean UX: team integrati“, in cui è partito mettendo in relazione la UX tradizionale (basata sulle interviste utente e le ricerche di contesto) con quella agile (basata su interazione diretta e iterazioni che si susseguono rapidamente) e quella Iean (basata su ipotesi, esperimenti e convalide di quello che si apprende). Sviluppando questo discorso, e presentando l’immagine di figura 3, viene messo in luce come l’approccio “tradizionale” all’esperienza utente si concentri su design e usabilità (“il cosa”), l’Agile eXperience Design (AXD) si concentri sulla collaborazione dei vari attori coinvolti nel processo e sulla consegna di elaborati progressivamente più raffinati (“il come”), la Lean UX si concentri sulla misurazione e la validazione per comprendere le ragioni per cui stiamo procedendo in una certa direzione (“il perche’”).

Figura 3 – Le “domande” cui rispondono i diversi approcci alla progettazione della UX.
Lo user centred design è oramai un concetto assodato, anche perche’ impostare il lavoro su quei principi è fonte di valore: nel momento in cui le aziende (in particolare le startup) vedono che concentrarsi sull’esperienza utente accresce il valore del prodotto, esse cominciano a considerare il design della UX come un investimento, e non come un costo aggiuntivo.
Il ciclo di Lean UX si basa su tre fasi: think (pensare), make (creare), check (controllare) che si svolgono in maniera iterativa, ed è agevolmente inseribile in un più ampio contesto di sviluppo che utilizzi, ad esempio, Scrum.
Non basterebbe gran parte dell’articolo per riportare tutto quel che è stato detto in questo corposo intervento (di nuovo, vi invitiamo a visitare il sito Better Software quando saranno disponibili i video, se volete farvi un’idea completa) e quindi ci limitiamo a riassumere alcuni punti salienti della seconda parte della presentazione: ma, davvero, si è trattato di un talk estremamente interessante, pieno di spunti e con una visione globale del problema davvero ampia. Quel che ne resta, comunque, è la continua insistenza sul non stare isolati, sulla collaborazione e su alcune pratiche decisive:
- la risoluzione collaborativa dei problemi;
- la pratica dello sketching con la realizzazione di schizzi, bozzetti, anche incompleti, che però diano informazione;
- il passaggio a più strutturati prototipi in grado di fornire comunque un’esperienza reale, seppure limitata, del prodotto;
- il pairing, cioè l’abbinamento continuo tra creativi e tecnici;
- la diffusione di guide di stile per tutti.
Oltre a questo, l’insistenza sui concetti base di iterativo e incrementale è stata volta proprio a far comprendere come le due idee, per quanto complementari, siano due cose ben diverse. La concentrazione sull’incrementale, per garantire comunque la realizzazione in tempi brevi di un prodotto in qualche modo consegnabile, attraverso le necessarie iterazioni, non deve far perdere di vista la visione d’insieme. Le metodologie agile fanno bene le cose, ma è la filosofia lean che, in maniera olistica, tiene d’occhio il tutto (“see the whole”).
UX e dintorni
Il talk appena descritto trattava anche di UX, inserendola in un processo di sviluppo globale, più ampio e generale. Ma, nel corso della conference, ad argomenti inerenti lo studio dell’esperienza utente e il design di interfacce sono stati dedicati svariati spazi, con presentazioni di taglio anche molto diverso e discussioni piuttosto sensate. In particolare, abbiamo seguito alcune presentazioni di taglio più teorico (ma non prive di esempi concreti derivanti da progetti reali) e altre più orientate a mettere le mani su aspetti più circoscritti e più immediati che influenzano direttamente l’esperienza utente, come l’ottimizzazione delle pagine web.
UX: tra teoria e sperimentazione
Nicolò Volpato [9] ha presentato un intervento intitolato “Creatività vs. visual design” e si è concentrato su uno degli aspetti che contribuiscono a una buona progettazione della UX: il visual design. La parte introduttiva della sua presentazione è suonata abbastanza assodata per tutti coloro che abbiano a che fare con la progettazione di interfacce grafiche e con lo sviluppo di software, app mobili e siti Web: sono stati esposti i problemi tipici della mancanza di una vera UX design e dell’integrazione tra visual design e sviluppo; è stato ricordato che molte aziende necessitano di una migliore cultura del design; è stato ribadito come il visual designer non sia un artista ma un professionista del “migliorare il buono” e che, anche se poi è vero che ogni visual designer ha il suo stile “personale”, questo non deve essere rilevante ma occorre limitare l’ego affinche’ sia il prodotto a risaltare. Come diceva Bruno Munari, occorre puntare a un design “esatto” (che non vuol dire “perfetto” o genericamente “bello”); il design esatto non è basato solo sul gusto personale, ma è la soluzione giusta per quel determinato contesto/progetto. L’estetica segue il contenuto, altrimenti è decorazione: il design non è designer-centric ma user-centred.

Figura 4 – Visual design nei processi di sviluppo: quali sono i parametri su cui basare la valutazione?
Dopo questa prima parte abbastanza teorica, si è passati al tentativo di proporre i criteri per una “misurabilità” del visual design, partendo da alcune considerazioni pratiche: da un lato il limite del mockup, del bozzetto grafico “inanimato”, deve spingere verso una progettazione interattiva, verso il “design in the browser” che sia responsivo; dall’altro, sia gli sviluppatori, sia i grafici devono sempre ricordare che design e sviluppo sono due facce della stessa medaglia (“design leads development, development informs design“).
Sulla base di tali considerazioni, i parametri di valutazione UX che vengono proposti sono sostanzialmente due: l’adeguatezza e la coerenza. Questi parametri possono essere a loro volta scomposti in elementi che è più facile identificare all’interno di una progettazione visuale.
Costituiscono elementi dell’adeguatezza:
- il tono: registro, stile, linguaggio, contesto;
- la metafora: skeuomorfismo, texture;
- le storie: narrazione, illustrazioni/foto, personaggi, animazioni, transizioni;
- le emozioni: personalità, anticipazione, sorpresa, ricompensa.
Costituiscono elementi della coerenza:
- la visione complessiva del design;
- i miglioramenti continui;
- i controlli a ritroso.
Più orientato all’architettura dell’informazione è stato “Choosability. Come facilitare la scelta nelle interfacce di navigazione”, in cui Luca Rosati [10] e Stefano Bussolon [11] hanno affrontato il cosiddetto “paradosso della scelta”, ossia la difficoltà e la diffidenza nella scelta quando le opzioni tra cui scegliere siano troppe. Gli studi di psicologia cognitiva ci informano di come la scelta migliore sia quella che si può effettuare fra un lotto limitato di opzioni. Esistono diverse tipologie di utente:
- il tipo A: chi conosce bene l’oggetto di scelta, ha le idee chiare e ha già ha già scelto;
- il tipo B: chi ha delle preferenze, ma non ha ancora scelto, per così dire “marca e modello” precisi;
- il tipo C: chi non conosce neanche i criteri su cui basare la scelta.
Paradossalmente, il tipo A si trova bene anche con tante opzioni (tanto ha già scelto), ma B e C si trovano meglio con meno opzioni.

Figura 5 – Facilitare le scelte nelle interfacce di navigazione.
In definitiva, scegliere è un processo cognitivo che richiede sforzo: la ricerca informazioni non ha una sola modalità ma si muove su diversi piani, in base al fatto che il nostro cercare sia più o meno indirizzato e più o meno attivo. Queste diverse modalità di ricerca hanno dei “costi” differenti e, generalmente, tendiamo a utilizzare modalità di ricerca meno faticose almeno fin quando funzionano: solo quando queste falliscono, allora passiamo a modalità più faticose e “consapevoli”. Si pensi, ad esempio, al modo in cui Amazon “facilita” le ricerche, prevedendo quello che all’utente potrebbe piacere, in maniera abbastanza contestuale ai suoi acquisti pregressi. Si tratta di concetti già noti da diversi studi [12]: quel che è importante è come sia possibile derivare da tali studi delle linee guida per la progettazione di GUI navigabili.
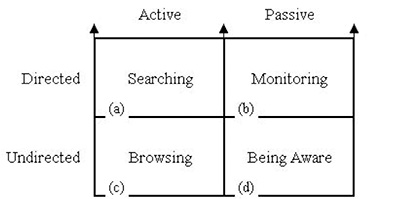
Figura 6 – Lo schema delle diverse modalità di ricerca (attive o passive, direzionate o prive di direzione) secondo la ricercatrice Marcia Bates.
Quello che viene enunciato è piuttosto semplice, almeno sul piano teorico, eppure spesso continuiamo a vedere applicazioni, siti, prodotti che non tengono presenti tali principi e anzi sembrano violarli volutamente. Le linee guida devono pertanto seguire tre criteri fondamentali:
- flessibilità: occorre progettare per le diverse modalità/strategie di ricerca, consentendo un facile passaggio dal “searching” (direzionato) al “browsing” (non direzionato).
- “convenienza dell’ordine”: raggruppare insieme ciò che è simile, tenendo presente che il concetto di similitudine “percepita” va verificato sul campo, con gli utenti; al supermercato i prodotti “simili” sono presentati insieme, ma su cosa si basa la “similitudine”?
- categorizzazione: raggruppare in categorie e sottocategorie, senza esagerare, ma rendendo chiaro un percorso di scelta possibile.
E a proposito di questi criteri, vengono presentati i risultati di un esperimento effettuato in un college statutinense. Agli avventori di un bar, venivano presentati, a loro insaputa, menù diversi per i caffè. In uno, i numerosi tipi di caffè disponibili, venivano presentati in rigoroso ordine alfabetico; nell’altro menù, i caffè erano organizzati per tipologia e categorie, in piccoli gruppi. Al termine delle consumazioni, l’utente “cavia” che aveva scelto dal menu strutturato era mediamente molto più soddisfatto del gusto del caffè di coloro che avevano avuto il menù non ordinato.
Il fatto era che qualsiasi caffè fosse servito a chiunque, si trattava sempre di un unico, medesimo prodotto… Choosability la “sceglibilità” degli elementi, può davvero risultare un elemento importante nella progettazione dell’architettura dell’informazione.
Sempre nell’ambito delle strategie per l’ottimizzazione della progettazione UX, ma con la presentazione di un caso di esempio molto pratico, si è mosso l’intervento di Luca Mascaro e Michela Perotti di Sketchin [13] intitolato “Governare l’evoluzione del software analizzandone l’esperienza d’uso”.
Anche questo talk parte con una premessa legata a quello che viene definito “product management agile”: le user story non sono sempre veramente derivate dall’utente, e possiamo “certificarlo” solo quando gli utenti veri usano il prodotto. In tal senso, la UX è sempre più centrale: se agli albori e nella prima fase della rivoluzione informatica la cosa fondamentale erano le funzioni del software, oggi è sempre più la UX a farla da padrone.

Figura 7 – L’intervento sui criteri di misurazione della UX di Luca Mascaro e Michela Perotti.
La parte centrale del talk è dedicata a capire come possiamo allora, in qualche modo, “misurare” l’esperienza utente. I relatori dicono subito, con chiarezza, che quantificare in modo numerico piacerebbe tanto ai manager tradizionalisti, ma non è possibile. Esiste però un modello interessante che consente senza dubbio di valutare qualitativamente la cosidetta curva d’esperienza: oramai è chiaro ciò che costituisce una buona curva UX. Vediamo di capire allora come si svolge l’esperienza che un utente ha di un qualche prodotto e, nel nostro caso precipuo, dell’interfaccia di un software o di un sito web:
- la prima impressione conta, seppur non sia tutto;
- l’esperienza non è mai troppo lunga, ne’ troppo corta;
- conta la media totale: l’esperienza ha alti e bassi, ma alla fine, alla lunga riusciamo a ricordare e valutare l’esperienza complessiva, nella sua media;
- però i momenti “eccezionali” contribuiscono ad alzare la media;
- se il momento finale è mediamente migliore dell’inizio, pur buono, allora l’esperienza è giudicata molto positiva.
Quindi si possono usare le “curve di esperienza” e la loro forma, per valutare e migliorare il software. Come si misurano le curve di UX? Ci sono metodi ispettivi (protocollo da seguire e check sulle varie voci) e metodi a test (ci sono degli utenti “cavia” che usano il prodotto e poi dicono le loro impressioni).
A questo punto del talk, viene presentato un protocollo ispettivo che è stato usato e ha dato ottimi risultati. Esso si basa su tre categorie (utile, semplice, piacevole) con cui valutare una determinata esperienza: le categorie ci devono essere tutte, perche’ non basta solo una caratteristica a definire l’esperienza utente. L’esame pratico di un task si fa su una scala a 3 punti dando un giudizio per ciascuna categoria (non presente, migliorabile, totalmente adeguata). Ripetendo il protocollo, a mano a mano che il software/sito evolve, si valutano i miglioramenti. La cosa davvero notevole è che, a meno di aspetti veramente molto scarsi, conviene di più alzare i punti rilevanti già alti (cosiddetti win points) che aumentare i punti bassi: quello che conta è la forma della curva UX; appiattirla significa renderla “sbagliata”.
Queste analisi risultano molto utili per i product owner che potranno infatti prendere decisioni che ottimizzano i costi, con tempi di analisi e di scelta relativamente brevi, due-tre giorni. Certo, anche i test con utenti hanno la loro importanza, e possono essere svolti di tanto in tanto per verificare i risultati ottenuti. Ma i test con utenti sono più lunghi e costosi, mentre questi protocolli ispettivi si sono dimostrati validi e, su progetti medi del costo di circa 250.000 euro annui, queste analisi incidono per non più del 4%-5 % del totale.
UX: web e ottimizzazioni delle prestazioni
Alcune presentazioni, che in qualche modo sono connesse all’esperienza utente, si sono concentrate si aspetti piuttosto concreti della fruizione del web. Visti i contenuti molto tecnici, consigliamo ai lettori più interessati di andarsi a recuperare il materiale sul sito di Better Software, quando sarà disponibile.
In breve, Matteo Papadopoulos [14] in “Modular CSS / HTML5: Organize the chaos” ha affrontato alcuni argomenti tecnici importanti per chi si occupi di frontend. Dopo una introduzione incentrata sul concetto di modularità, modulo e riuso, ha detto chiaramente che i CSS modulari sono effettivamente complessi, ma proprio per questa loro complessità risultano utili e validi. Quando ha senso usarli? Secondo Matteo, sempre! La domanda da porsi è piuttosto “come?”. La precisione e l’ordine sono importanti, anche se costano fatica ed energia.

Figura 8 – Non sono mancati interventi dedicati precipuamente alla progettazione e ai linguaggi web-oriented.
L’intervento si è poi concentrato su una serie di consigli, molti dei quali oramai di dominio comune, ma che è sempre bene ricordare:
- usare librerie come Modernizr;
- i DIV non sono il male assoluto…
- uso dello sketching per fornire informazioni agli attori coinvolti nel processo;
- markup no style per una visualizzazione comunque accettabile e chiara anche senza foglio stile;
- pensare OOP anche per i grafici (la figura del “devigner”, metà sviluppatore e metà designer);
- importanza della denominazione dei file;
- SASS / SCSS sono strumenti fondamentali;
- importanza del file system per la modularità: base, layout, modules, sections, themes;
- bridging: un file CSS che “tiene in ordine” tutti gli altri CSS.
Andrea Pernici [15] è stato uno dei relatori più divertenti, ma “Web Performance Optimization: non puoi più astenerti e ignorarle” non va solo ricordato per le numerose risate strappate al pubblico dal suo approccio molto poco “ortodosso”.
Il tema della ottimizzazione per le prestazioni (WPO) di siti e di app ha un impatto economico sui motori di ricerca, sulle page-views di siti editoriali e sui tassi di acquisto di siti e-commerce (crescita del 15% per i siti ottimizzati). Da esperimenti su animali di laboratorio (un po’ come quelli sul “cane di Pavlov”) basati sullo stimolo e sulla ricompensa si è visto che se il topolino riceveva la ricompensa con ritardo, rispetto al compito portato a termine, metteva in atto una “depressione neuronale”. In pratica: la velocità di risposta dei sistemi è qualcosa che piace in maniera “innata” negli esseri viventi.
Gli umani che hanno una risposta lenta da siti e app “si stressano”. L’esperienza di navigazione soddisfacente invece aiuta a “stare meglio”. Il tempo medio di attesa “tollerata” degli utenti è di 2 secondi su PC desktop, 3 secondi su tablet, 4 secondi su smartphone; ma la media di caricamento dei siti è di circa 7.5 secondi su desktop, e ancora maggiore su mobile. Bene, “è tutta colpa della connessione”, si dirà, ma la cosa che spesso non si tiene presente è che ciò che impatta di più sulle performance non è il backend (server, hosting, connessione) ma il frontend (codice JavaScript, CSS etc.). A questo punto non resta che farsene una ragione e lavorare con una Web Performance Optimization che punti a ottimizzare il frontend con regole assodate e implementabili:
- ridurre le richieste HTTP: combinare CSS e JS, usare sprite CSS;
- minimizzare JavaScript, CSS, HTML: quello che serve, serve, ma evitare le ridondanze;
- usare la compressione: il 70% dei siti non lo fa!
- rimandare il superfluo: se qualcosa non è vitale, va caricato alla fine (widget social, script secondari etc.);
- parallelizzare: i moderni browser hanno un limite di 6 risorse parallele;
- JavaScript alla fine: sono bloccanti;
- CSS all’inizio: senza CSS vedo poco, quindi è la prima cosa da mettere;
- impostare le scadenze: per usare come si deve la cache del browser;
- comprimere le immagini e servirle nei tagli giusti (il che va contro il responsive design…);
- usare prefetch e prerender, che ora sono sempre più supportati.
Oltre a queste indicazioni, Andrea Pernici si è soffermato sull’uso di alcuni tool per monitorare gli utenti reali come Google Analytics (traccimento degli elementi che fanno da collo di bottiglia), Mod_Pagespeed, Page Speed Insights per Chrome, concludendo con una considerazione quanto mai condivisibile: non importa quanto aumenterà la disponibilità di banda o l’efficienza generale del backend, perche’, a fronte dell’aumento di dimensione e peso dei siti sempre crescente, occorre lavorare sempre più sulla WPO.
Commerciale è bello: contratti, clienti, stime e mercati… in salsa agile
Una fetta di talk ha affrontato delle tematiche “trasversali” molto interessanti: cresce la cultura della gestione dei progetti, si diffondono le metodologie agili, ma il modo in cui ci si rapporta con clienti e fornitori e in cui si concordano contratti e rapporti di lavoro non va di pari passo con i mutamenti in atto.
Michele Luconi ha trattato “L’approccio agile ai contratti e la consegna di valore” partendo da un “paradosso”: i contratti sifanno all’inizio delle attività, e in linea di massima, non si cambiano. I progetti agile, invece, sono tutto il contrario. E allora come si fa? Viene presentato un tipo di contratto “agile” la cui caratteristica è di essere basato su “iterazioni settimanali” proprio come Scrum. È una forma di contratto “soddisfatti o rimborsati”, con pagamento “a settimana”, che però finora ha dato ottimi risultati.

Figura 9 – Nuovi processi di sviluppo richiedono nuove tipologie di contratto.
Nella sua “Agile, Lean Startup and Market-Driven. How to understand customers’ needs for products that sell” Donato Mangialardo [17] ha fornito un interessante quadro di quello che definisce pragmatic marketing. Attraverso una narrazione incentrata sulle scelte di una ipotetica azienda, e sulle conseguenze delle varie decisioni, ha messo in mostra come spesso le aziende sono “driven” (cioè guidate) dal cliente, dal marketing, dai costi o dalla tecnologia, dimenticando che lo scopo fondamentale di una azienda è quello di essere invece market-driven, ossia orientata alla realizzazione di prodotti che effettivamente vendono perche’ incontrano i reali bisogni del cliente. Con una serie di errori tipici delle strategie di prodotto, Donato Mangialardo è riuscito a comunicare questi concetti: i presenti non dimenticheranno facilmente l’esilarante concetto di “profumare il maiale”, per nasconderne la puzza e tentare di rifilarlo a un qualsiasi acquirente, il che che spesso si sostituisce alla vera operazione di mercato (e non di marketing come viene in genere inteso) che consiste nel sapere a chi bisogna parlare e di cosa bisogna parlare. Discorso generale, applicabile a ogni prodotto, e proprio per questo anche al software: il software di valore deve risolvere esigenze urgenti, pervasive e critiche.
La tematica delle stime di progetto (e dei preventivi spesso sbagliati) è stato affrontato da Gaetano Mazzanti [18] in “Ti stimo fratello”. Con un approccio molto divertente, ma che va al sodo, si tenta di rispondere alla domanda “Perche’ si fanno le stime?” “Perche’ ce le chiedono”. Fare le stime è più facile quando siamo a “metà dell’opera”, quindi quando si comincia un lavoro è invece problematico. Completare un progetto in tempo, non necessariamente equivale a produrre valore per il cliente e a questo proposito viene proposta una “equazione” relativa al Gantt “critical path + critical chain = critical pain”.
L’approccio classico alla stima “Valutiamo il passato e muoviamoci di conseguenza” non funziona semplicemente perche’ ogni progetto ha delle sue caratteristiche ben diverse. Siamo però capaci di fare stime “relative”, ma nel quadro generale sbagliamo; e a tal proposito viene mostrata una serie di esempi sulle stime sbagliate (come gli effetti ottici), o di comportamenti assodati dalle scienze cognitive come il “framing effect”, la paura della perdita (“loss aversion”), la valutazione “emozionale”. L’approssimazione regna sovrana: ma è meglio essere un po’ fuori dalla stima, abbastanza nel giusto, che perfettamente sbagliati. Le “idee di massima” sono utili, poiche’ consentono aggiustamenti progressivi.
Sul piano pratico, ci sono delle tecniche che possono aiutare. Planning poker è buono ma non eccezionale. Preferire sempre range a valori assoluti. Un esempio è rappresentato dalla velocity in Scrum e dal control chart di Kanban che è utile per valutare il range di velocity (non il valore assoluto). Però c’è un caso in cui il valore assoluto ha senso: contare il numero assoluto di user stories invece che gli story points può rivelarsi davvero funzionante. In tal senso, Kanban è ottimo.
Abbiamo visto all’opera in svariate occasioni Francesco Fullone [19] che in “Compromessi, non soluzioni” racconta la sua di “ex” tecnico nelle nuove vesti di “commerciale”. Sebbene paia ancora più a suo agio con le difficili sottigliezze dello sviluppo web che con il nuovo ruolo, l’analisi del suo percorso, degli errori e delle conquiste della startup da lui fondata con due colleghi, e una serie di considerazioni sui rapporti con i clienti hanno reso questo intervento un momento piacevole di riflessione.

Figura 10 – Francesco Fullone nel suo nuovo ruolo di “commerciale”.
Architetture & Sviluppo
Riportiamo in questa categoria due talk tra loro di taglio e argomento diverso ma accomunati dall’idea che sia possibile fare meglio il software.
In uno dei talk che hanno aperto i lavori al mercoledì mattina, intitolato “Stai guardando i dati sbagliati” Alberto Brandolini [3] ha fatto una lunga digressione sulla architettura più diffusa, proponendo poi delle alternative volte al miglioramento del modo in cui i sistemi funzionano e vengono progettati. Le architetture attuali, nella gran parte dei casi, sono basate sull’integrazione al database: applicazioni che accedono ai dati e che, metaforicamente, vengono rappresentate come dei maiali che mangiano (alla loro maniera) dal trogolo.

Figura 11 – La database integration è in fondo questo… SOA non risolve del tutto il problema, ma si limita a “insegnare ai maiali a mangiare con le posate”.
Questo porta spesso ad avere dati “sporchi”, e architetture costruite a pezzi e che divengono sempre più complicate. Non è solo una questione di stile o di eleganza, ma tutto ciò ha degli impatti reali sul lavoro delle aziende: in certi casi, sistemi costruiti in maniera rappezzata forniscono report mensili… con 50 giorni di ritardo.
Le soluzioni offerte dal Domain Driven Design possono costituire una valida alternativa. Ma quali sono le mosse da intraprendere per realizzare architetture migliori?
- Aggregates: tenere insieme le cose che cambiano insieme, non quelle che cambiano per motivi diversi; in tal senso, l’ORM avrà tutti i suoi limiti, ma gli vengono ascritte troppe colpe.
- Event Sourcing: la verità è nel flusso degli eventi che viene registrato. Questo pattern architetturale permette alle entità di tener traccia del loro stato interno attraverso la lettura e l’affidamento di eventi a un “event-store” un registro del susseguirsi dei diversi stati. Lo “stato del sistema” altro non è che il risultato della serie degli eventi che lo hanno interessato. Le aziende complesse funzionavano anche ai tempi della carta e non del computer (registri cartacei che tenevano traccia di tutto, evento dopo evento).
- CQRS: “segregare”, cioè separare, l’architettura ottimizzata per i comandi e quella ottimizzata per le ricerche è un pattern architetturale concettualmente semplice ma che implementa uno dei principi base troppo spesso dimenticati: “tell, don’t ask”.
- Bounded Contexts: per definire i reali confini dei componenti. Possibili più rappresentazioni degli stessi concetti, anche se questo sembra andare contro le regole dell’Object Oriented Programming.
Tutte queste mosse portano valore, migliorano le prestazioni del sistema, e consentono di avere una “narrazione” di ciò che accade nel sistema, sulla base di eventi e relazioni. E quindi i flussi di lavoro ben si integrano sulla Kanban Board che funge da identificatore dei colli di bottiglia.
“Quanto conosci il tuo debito tecnico?” è la domanda che Alan Franzoni [20] pone alla platea nel suo intervento lineare, e anche un po’ “didascalico”, ma molto utile per mettere in ordine una serie di considerazioni inerenti il cosiddetto “debito tecnico”. Il debito tecnico è strettamente connesso all’evolvibilità e alla manutenibilità del software. Economicamente, con un parallelismo finanziario, il debito tecnico è paragonabile a una opzione scoperta (“naked option”): non so se e quando sarò chiamato a pagarla. Se l’opzione va in un certo senso, negativo, sarò chiamato a scontarla tutta insieme.

Figura 12 – L’intervento sul debito tecnico viene seguito con estrema attenzione.
Ma ora che è chiaro il concetto di debito, nella prassi dello sviluppo IT, che cosa significa “debito tecnico”? Be’, esistono molte tipologie di debito tecnico:
- Debito di qualità del software: è fatto male, testato poco, tirato via.
- Debito di architettura o di design: ripropongo una architettura già usata ma non necessariamente esatta per lo scopo, oppure utilizzo uno strumento che conosco bene e so usare, ma che magari non era il tool più adatto; questo non sempre viene fatto in cattiva fede, ma dipende dalla fumosità iniziale del problema: è ammissibile uno spike per partire con il progetto, ma dopo si deve correggere.
- Debito da mancanza di visione: il modello non è conosciuto bene da tutti gli sviluppatori, quindi ci sono duplicazioni di codice, funzionalità duplicate. Si arriva al limite della unica classe che fa quasi tutto.
- Debito di requisiti: il software è ottimo, ma non fa la cosa fondamentale per cui serviva. Questo mette ancora una volta in luce l’importanza delle user stories scritte bene e adoperate nel modo giusto.
- Debito di infrastruttura: tutto bene, ma poi è un gran problema installare il software. E sono allora fondamentali gli script, gli strumenti di automazione, la continuous integration etc.
- Debito di hardware: computer vecchi, monitor di cattiva qualità etc. che fanno rendere male il team.
Ragioni del debito: gli sviluppatori devono spiegare il debito tecnico ai clienti. Perche’ si fa? Anche il modo in cui si fa può essere diversificato:
- sconsideratezza: non si capisce che si fa debito tecnico, poiche’ non si hanno gli strumenti “culturali” per rendersene conto;
- nascondimento: si fa debito tecnico deliberatamente per nascondere qualcosa; si fanno cose di cattiva qualità per far funzionare il software a tutti i costi… e poi vada come vada;
- quick fix consapevole: si fa un debito tecnico consapevole e di proposito; si è a conoscenza del fatto di fare debito, ma lo si corregge alla prima iterazione utile; è meglio evitarlo, ma è un debito accettabile, se tutti ne sono al corrente.
Cosa fare per prevenire il debito:
- coinvolgere gli stakeholder, tenendoli al corrente e spiegando cosa si sta facendo (anche gli eventuali debiti tecnici volontari e quando saranno corretti);
- far assumere la responsabilità del debito a chi impone di contrarlo (se il responsabile di progetto vuole tutto e subito, deve essere consapevole che i team di sviluppo potranno consegnare, loro malgrado, software in cui c’è molto debito tecnico, ma i responsabili non sono gli sviluppatori);
- ipotizzare dei budget di “manutenzione” futura.
Importanti sono anche gli aggiornamenti del software con cui si sviluppa: non bisogna correre dietro con ansia alle nuove release di librerie, framework e linguaggi, ma guai a rimanere indietro. È bene fare delle prove, capire, magari aspettare qualche settimana, ma comunque conviene migrare non appena possibile in tutta sicurezza: sembra strano, ma ci sono aziende che sviluppano ancora con tool e librerie vecchie di tanti anni.
Mobile & IoT
Anche i temi relativi ai mobile OS e alla Internet of Things (IoT) hanno avuto il loro spazio in Better Software 2012. Ho seguito in particolare due interventi.
Matteo Collina [21] ha affrontato alcune tematiche di IoT in “Making ‘things’ that work with us” presentando un esempio: chattare con dei dispositivi in casa tramite Hubot e Coffee script. Utilizzando dispositivi basati su Arduino, occorre disporre di un protocollo binario. Volendo poi interconnettere più di una cosa, HTTP in questo senso ha dei limiti: la soluzione migliore sarebbe un pattern Publish / Subscribe che però si sposa male con HTTP.
I protocolli adatti comunque ci sono: MQTT è publish subscribe e c’è poi anche Web of Things che è basato su architettura REST: MQTT è al momento lo stato dell’arte e si basa sul concetto di topic. Arduino “parla” MQTT, ma tutto il resto, lo sappiamo bene, “parta” HTTP. La soluzione proposta, frutto del lavoro di ricerca dell’autore, è QEST cioè
- MQTT to REST in cui ogni topic ha il suo URI;
- REST to MQTT in cui ogni PUT HTTP è trasformata in un messaggio MQTT.
QEST ha una buona scalabilità e questo potrebbe garantirne il successo in un quadro ancora liquido ma denso di sviluppi come quello dell’IoT.
Giovanni Ciaffoni [22] si occupa delle tematiche dell’accessibilità in quanto lavora per l’Istituto F. Cavazza di Bologna che fornisce prodotti, ausili e servizi per non vedenti. La sua presentazione “Ariadne GPS. Mobilità e mappa tattile per iOS” racconta la nascita e lo sviluppo di uno strumento per l’accessibilità geolocalizzata: Ariadne GPS, una app di orientamento e navigazione terrestre utile non solo per i non vedenti ma per tutti. Si tratta della “solita” applicazione GPS, che però ha dalla sua un ulteriore sistema di avvertimento per l’utente (audio e vibrazione). Più di altre spiegazioni, per chi non ha l’applicazione, possono aiutare a comprenderla i primi minuti di un video [23] mostrato alla conferenza degli sviluppatori Apple, la WWDC2012.
Sessioni “hands on”: le mani in pasta…
A fianco delle diverse presentazioni, che hanno comunque avuto momenti di interattività con le domande e risposte alla fine di ogni talk, ci sono state delle vere e proprie sessioni pratiche, denominate Hands on. Tra queste, almeno a detta di chi ci ha partecipato, grande interesse hanno suscitato “Cynefin Lego Game” e “Kanban Pizza Game” condotte da Gaetano Mazzanti e Roberto Bettazzoni [24].

Figura 13 – Anche il gioco del Lego può servire per spiegare i concetti alla base del modello interpretativo Cynefin, che consente di definire i sistemi a seconda del dominio in cui ricadono (semplice, complicato, complesso, caotico).
Le immagini farebbero pensare a ben altro… ma i concetti alla base dei giochi, e le riflessioni che ne derivano, hanno entusiasmato più di qualche “tradizionalista” presente.
Conclusioni
Abbiamo già esposto gran parte delle nostre considerazioni nella parte introduttiva. Uno dei punti di forza di questa edizione è stato probabilmente quello di dare spazio a contributi da parte di nuovi relatori senza però togliere alcuni punti di riferimento oramai divenuti classici. L’altro aspetto positivo è stata l’offerta diversificata degli argomenti (dalle presentazioni alle sessioni di pratica) senza che però si percepisse una “atomizzazione” degli interventi e senza che una tematica andasse a prevalere sulle altre. Nelle prossime edizioni ci piacerebbe che questa impostazione fosse mantenuta, magari con qualche ulteriore intervento dedicato alle tematiche web-oriented che in altre edizioni sono state maggiormente presenti. Ma sono dettagli: la sensazione generale è stata di diffuso gradimento. Ah, e alla fine della due giorni, in molti tra i partecipanti si sono dichiarati “rilassatamente stanchi”: segno del fatto che non si è trattato solo di giocare con il Lego…
Riferimenti
[1] Develer
http://www.develer.com/website/it
[2] Il programma della conferenza, con slides e video dei diversi interventi (in arrivo)
http://www.bettersoftware.it/2012/programma
[3] Il blog di Alberto Brandolini
[4] Il sito di Andrea Provaglio
[5] Gli articoli di Giovanni Puliti sulla conoscenza collaborativa e sui wiki
https://www.mokabyte.it/2012/01/wikipattern-1/
[6] Open Ware
http://www.open-ware.org/ita/home.htm
[7] Gli articoli di Fabio Armani di introduzione alle metodologie agili
https://www.mokabyte.it/2011/09/metodoagile-1/
[8] Diana Larsen – Ainsley Nies, “Liftoff: Launching Agile Teams & Projects”, Onyx Neon Press, 2011
[9] GNV & Partners
[10] Luca Rosati: architettura dell’informazione
[11] Stefano Bussolon
[12] Marcia J. Bates, “Toward an integrated model of information seeking and searching”, New Review of Information Behaviour Research, 3, 2002, pp. 1-15
[13] Sketchin
[14] Cantiere creativo
http://www.cantierecreativo.net/it/home
[15] Non conventional web dev
[16] e-xtrategy
[17] Crystal-ize
[18] Gama-Tech
[19] Ideato – Web ideas for sale
[20] Alan Franzoni
[21] Matteo Collina
[22] Giovanni Ciaffoni
[23] Apple iOS Apps Film from WWDC 2012 (i primi minuti sono dedicati all’app Ariadne)
http://www.youtube.com/watch?feature=player_embedded&v=lQr9vsHxU6E&gl=IT
[24] Agile42
A MokaByte mi occupo dei processi legati alla gestione degli autori e della redazione degli articoli. Collateralmente, svolgo attività di consulenza e formazione nell‘ambito dell‘editoria "tradizionale" e digitale, della scrittura professionale e della comunicazione sulle diverse piattaforme.