

Microservizi: una novità?
L’evoluzione dello sviluppo software negli ultimi anni ha visto l’affermazione di modalità operative quali quella DevOps nell’ottica di un rilascio sempre più ravvicinato di nuove versioni. Ma tali pratiche non possono essere messe in atto senza una solida base archietturale e tecnologica.
Nascono continuamente nuovi pattern e nuovi modelli di progettazione che ci dovrebbero aiutare in questa evoluzione: uno di questi è sicuramente rappresentato dai MicroService. È da un po’ che se ne sente parlare, sono presentati a volte come la panacea di tutti i mali e, allora, in questa serie proveremo a capire di cosa si tratta, e come sia possibile utilizzarli al meglio.
Microservices e principi SOLID
Una definizione comune per lo stile architetturale in questione ci dice che i microservizi sono servizi autonomi, piccoli, che lavorano insieme. Ma come tutte le grandi “rivoluzioni” tecnologiche — e non solo — anche i microservizi affondano le loro radici in un background più profondo.
Qualche tempo fa infatti, un certo Robert C. Martin, meglio conosciuto come Uncle Bob, ci presentò alcuni principi, 5 per l’esattezza, per sviluppare codice secondo il paradigma della Programmazione a Oggetti: si tratta dei principi SOLID [1] che sono noti a tutti coloro che si siano occupati in qualche modo di OOP.
Non è scopo di questo articolo parlare di questi principi, ma il primo di essi calza a pennello con l’argomento ed è il SRP (Single Responsibility Principle). Secondo il SRP, è bene “raccogliere insieme quegli elementi che cambiano per la medesima ragione, e tenere separati gli elementi che cambiano per motivi differenti”. Come spesso succede, Uncle Bob ne sa sempre una più di tanti altri… e c’è arrivato anche qualche annetto prima.

I microservizi seguono appunto lo stesso principio: raggruppano operazioni che fanno le stesse cose e le rendono indipendenti dalle altre. Un microservizio è un’entità separata, che può essere rilasciata su una piattaforma isolata che potrebbe avere un Sistema Operativo diverso da tutte le altre con cui lavora. Questo microservizio — così come tutti gli altri ovviamente — deve poter essere rilasciato in maniera del tutto indipendente dagli altri e, soprattutto, in modo del tutto trasparente ai suoi consumers.
Ancora una volta Uncle Bob vince a mani basse, visto che tutto questo mi ricorda molto la lettera L dei principi SOLID, il cosiddetto Liskov Principle.
Vantaggi dei microservizi
Una volta appurato che cosa sono i microservices e averne riscontrato le radici decisamente sane, chiediamoci perché mai dovremmo passare a questo modo di rilasciare soluzioni, che in effetti sembra un po’ dispersivo e laborioso.
I benefici sono diversi e soprattutto variegati. Eccoli in sintesi:
- Si adattano a sistemi distribuiti e architettura SOA (Service Oriented Architecture); qualcuno ha introdotto un termine che suona decisamente meglio: ROA (Resource Oriented Architecture).
- Si possono adottare tecnologie eterogenee. Non siamo più vincolati a fare tutto con la stessa tecnologia, ma siamo liberi di scegliere di volta in volta la tecnologia migliore per la soluzione che stiamo approntando.
- Favoriscono la resilienza: anche questo termine è molto cool Se un componente della nostra catena fallisce, resta un problema isolato, che non interviene a cascata su tutto il sistema.
- Favoriscono la scalabilità: con tanti servizi piccoli, è facile intervenire solo su alcuni di essi, senza necessariamente modificare nulla degli altri.
- Sono facili da rilasciare: per tutti i motivi riportati sopra, essendo isolati, è facile rilasciare un singolo microservizio, senza dover interrompere tutti gli altri allo stesso tempo.
- Si adattano all’organizzazione: possiamo allineare l’organizzazione della nostra struttura all’architettura dei servizi che andiamo a distribuire.
- Si basano sulla componibilità: è un po’ come giocare con il Lego. Possiamo ampliare la nostra soluzione un po’ alla volta, senza dover rilasciare tutto subito.
Sulla base dell’analisi di questi vantaggi si capisce abbastanza facilmente perché i microservizi siano diventati uno dei pilastri tecnologici di chi sviluppa con un approccio agile.
Ci sono anche svantaggi
Molti lettori — ed è quello che è successo inizialmente anche a chi scrive — staranno pensando: “Bene, i microservices sono la soluzione a tutti i nostri problemi!”. Se però graffiamo un po’ più a fondo questa bellissima superficie, qualche problema emerge, ed è bene esserne consapevoli.
Nell’ambito dei sistemi distribuiti esiste infatti il celebre Teorema CAP [2] messo a punto da Eric Brewer (n.d.r.: ce ne siamo occupati sulle pagine di MokaByte qualche anno fa [3]): quanto appena descritto a proposito dei vantaggi dei microservizi va purtroppo a scontrarsi proprio con certe considerazioni che nascono dal teorema CAP.
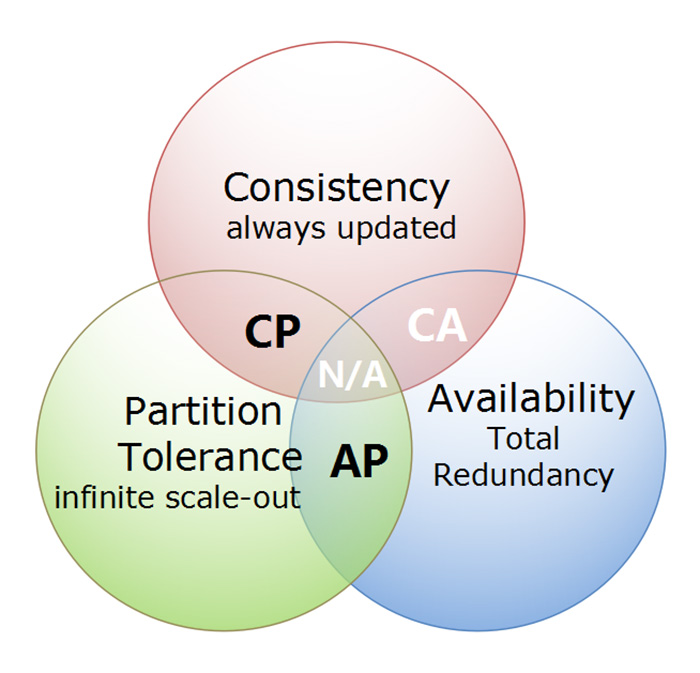
Brevemente, questo teorema sostiene che è impossibile per un sistema distribuito garantire contemporaneamente tutte e tre le seguenti qualità:
- Consistency (coerenza): tutti i nodi vedono gli stessi dati nello stesso momento.
- Availability (disponibilità): ogni richiesta riceve una risposta, senza la garanzia che contenga la versione più recente dell’informazione.
- Partition tolerance (Tolleranza di partizione): il sistema continua ad operare, nonostante un arbitrario numero di messaggi persi.
Ora che abbiamo scoperchiato la pentola, sappiamo di cosa ci stiamo occupando: come in ogni soluzione, ci sono dei vantaggi ma anche delle controindicazioni di cui essere consapevoli. È sulla base di queste considerazioni, che adotteremo uno stile architetturale a micorservizi.
Microservizi: di che cosa abbiamo bisogno?
Preso atto di quanto appena detto, poossiamo continuare il nostro approfondimento sul mondo dei microservizi. Anzitutto, di cosa abbiamo bisogno e su cosa dobbiamo concentrarci?
Le soluzioni che creiamo non sono degli waypoint, non sono dei punti fissi e immutabili nel tempo; una volta rilasciati in produzione i nostri prodotti software continuano a evolvere, perché questo ci insegnano i principi agili. Dobbiamo saper rispondere al cambiamento.
Quello di cui ci dobbiamo realmente occupare dunque, non è tanto quello che succede all’interno dei confini dei nostri servizi, ma quello che succede fra i confini degli stessi. Ciò significa che la nostra preoccupazione maggiore ora è quella di investire tempo per pensare a come interagiscono fra di loro i nostri servizi, preoccupandoci di monitorare la soluzione intera, e non il nostro piccolo orticello. Che poi, senza nasconderci troppo dietro ad un dito, è il compito di un Architetto del Software.
Obiettivi, principi, pratiche
Per fortuna, nel nostro mestiere difficilmente dobbiamo reinventare la ruota, e anche in questo caso ci sono dei “capisaldi” a cui fare riferimento per cercare di farci il meno male possibile. Potremo distinguerli, nel corso di questi articoli, fra tre categorie:
- Obiettivi strategici. Mai perdere il focus sul nostro obiettivo principale, mantenendo sempre una visione d’insieme (see the whole).
- Principi. La definizione, da dizionario, recita “Concetto, idea, nozione che rappresenta uno dei fondamenti di una dottrina, di una scienza, di un’attività o che sta alla base di un ragionamento”. Affermerei senza ombra di dubbio che, nel nostro mestiere, ne abbiamo di validissimi, a partire dai già citati principi SOLID, passando per quelli Lean/Agile.
- Pratiche. Qui facciamo riferimento a linee guida per la scrittura del codice, architetture adottate (HTTP/REST, Event Driven, SOAP, …). Le pratiche possono cambiare spesso, certamente più dei principi. Due team diversi, uno Java, ed uno .NET, possono adottare pratiche diverse, ma entrambi seguiranno gli stessi principi.
Quello che veramente è importante, in un’architettura distribuita, è l’insieme, non il singolo servizio; nei sette principi Lean per lo sviluppo del software troviamo il concetto di Optimise the Whole — o See the Whole a seconda della lettura che scegliamo — ma il concetto non cambia. Quello che stiamo implementando è un sistema coeso composto da piccole parti, che godono di vita autonoma, ma che concorrono tutte per lo stesso obiettivo.
Avremo bisogno si strumenti di monitoraggio, che ci permettano di avere una visione dello stato di salute dell’intero sistema: in pratica dovremo essere wide piuttosto che deep. Non ci interessa più una visione specifica del servizio, se non in un secondo momento, una volta identificato che quel particolare servizio ci sta causando un problema.
Dovendo lavorare con più team distribuiti sarà fondamentale definire un numero limitato di interfacce di comunicazione, questo anche per facilitare l’integrazione con i consumer dei nostri servizi. Un solo standard è un ottimo numero… ma anche un paio non guastano. Meglio non esagerare, in ogni caso.
La sicurezza è un altro aspetto che emerge in un sistema che non è più concentrato in un solo punto.
Come costruisco un MicroService?
Per essere definito tale, un microservizio, deve rispettare due concetti chiave
- Loose Coupling (basso accoppiamento)
- High Cohesion (elevata coesione)
Vediamoli brevemente di seguito.
Loose Coupling
La caratteristica principale di una architettura a microservizi è quella di permetterci di effettuare una modifica su un singolo servizio, e rilasciarla, senza la necessità di richiedere o attendere cambiamenti da parte di nessun altro servizio nel sistema.
High Cohesion
Se abbiamo la necessità di cambiare un comportamento, vogliamo poterlo fare in un solo punto, e rilasciare il relativo servizio il prima possibile. Rilasciare più di un servizio alla volta comporta rischi troppo elevati per l’intero sistema. Solo rispettando il Single Responsibility Principle potremo essere certi di poter lavorare in questo modo.
Quanto micro?
A questo punto sorge allora una domanda spontanea. Quanto piccolo deve essere un servizio per essere correttamente definito microservizio? Potremmo scomodare all’infinito Uncle Bob per avere la riposta, ma essa ce la dà direttamente l’autore del Blue Book [6]. Parlando del suo lavoro, Eric Evans ha sottolineato l’importanza del concetto di Bounded Context per definire correttamente i confini di un Microservizio. Una buona definizione di Bounded Context è “A specific responsability enforced by explicit boundaries” (“Una responsabilità specifica, imposta da confini espliciti”).
Nel suo libro Evans utilizza, come esempio, le cellule del corpo umano; le cellule esistono perché le loro membrane definiscono ciò che è dentro e fuori e determinano cosa può passare. Quando pensiamo ai confini dei nostri servizi, e quindi, come descritto prima ai confini della nostra organizzazione, non dobbiamo pensare a loro in termini di dati da condividere, ma piuttosto alle capacità che forniscono al resto del dominio.
Non pensare solo in termini di dati
Se restiamo alla metafora delle cellule umane, continua Evans, pensare il contesto in termini di dati, basato sulle classiche operazioni CRUD, significa definire un dominio anemico. Quindi le domande da porsi per non incappare in questo errore sono:
- Cosa deve fare questo servizio?
- Quindi, di quali dati ha bisogno per farlo?
Queste sono le operazioni chiave che dovremo esporre se vogliamo modellare adeguatamente il nostro servizio. E di questo ci occuperemo nei prossimi articoli.
Conclusioni
Con questo articolo di introduzione ai microservizi abbiamo dato inizio a una serie che ci porterà ad esaminarne vari aspetti concettuali e operativi. Già dal prossimo articolo ci concentreremo su quale sia la soluzione migliore da adottare per far dialogare fra loro i nostri Microservices, passando in rassegna HTTP/REST, il buo vecchio RPC e un modello Event-Driven.
Sono fondamentalmente un eterno curioso. Mi definisco da sempre uno sviluppatore backend, ma non disdegno curiosare anche dall'altro lato del codice. Mi piace pensare che "scrivere" software sia principalmente risolvere problemi di business e fornire valore al cliente, e in questo trovo che i pattern del DDD siano un grande aiuto. Lavoro come Software Engineer presso intré, un'azienda che sposa questa ideologia; da buon introverso trovo difficoltoso uscire allo scoperto, ma mi piace uscire dalla mia comfort-zone per condividere con gli altri le cose che ho imparato, per poter trovare ogni volta i giusti stimoli a continuare a migliorare.
Mi piace frequentare il mondo delle community, contribuendo, quando posso, con proposte attive. Sono co-founder della community DDD Open e Polenta e Deploy, e membro attivo di altre community come Blazor Developer Italiani.