

Dal legacy ai microservizi
Nei precedenti articoli abbiamo visto come progettare e integrare servizi “piccoli abbastanza” per garantirci le due caratteristiche che più desideriamo, ossia strong cohesion e loose coupling vale a dire forte coesione e basso accoppiamento, anche se in inglese suona meglio… Abbiamo discusso l’importanza di fare evolvere il design dei nostri sistemi a piccoli passi, senza grossi traumi. Ma come possiamo gestire il pregresso, ossia tutto il codebase scritto in anni e anni di onorato servizio, che però non rispetta i pattern discussi?
Un monolite cresce continuamente e viene arricchito quotidianamente di nuove funzionalità, il che significa che le righe di codice crescono esponenzialmente di giorno in giorno in maniera allarmante, diventando ben presto una presenza a dir poco inquietante nella nostra organizzazione. Una presenza così ingombrante che nessuno vorrebbe mai toccarla, e la cui conoscenza è celata nella memoria degli anziani del villaggio e mai tramandate ai posteri. Tranquilli però perché, con gli strumenti giusti, possiamo dominare la bestia!
Monoliti e cuciture
In realtà abbiamo già trattato uno strumento fondamentale, ossia il pattern Bounded Context, che ancora una volta ci verrà in soccorso. Nel libro Working Effectively with Legacy Code [1], Michael Feathers definisce il concetto di “cucitura” (seam), inteso come una porzione di codice che può essere trattata isolatamente, senza che la sua modifica impatti sul resto dell’applicazione.
In pratica si tratta di capire cosa rende buona una “cucitura”, che caratteristiche deve avere per poter essere isolata dal resto del monolite e trattata singolarmente. Vaughn Vernon, a proposito dei Bounded Context, scrive “The delimited applicability of a particular model. Bounding context gives team members a clear and shared understanding of what has to be consistent and what can develop independently”. Forse che i due ci stiano indicando la stessa strada?
Il termine cucitura, devo ammetterlo, mi piace perché mi dà l’idea di un abito cucito male che dev’essere sistemato, e solo un abile sarto lo può fare, senza distruggerlo. Certamente il concetto di confine è più appropriato, ma al di là dei termini, il concetto è chiaro.
La statua è già nella pietra
“Ogni blocco di pietra ha una statua dentro di sé ed è compito dello scultore scoprirla”.
Michelangelo era uno che di monoliti se ne intendeva un poco, magari non gli stessi di cui parliamo noi, ma il concetto è identico. Lo stesso Sam Newman, nel suo libro più volte citato [2], ricorre più o meno allo stesso paragone. Quello che serve al nostro cliente è già presente nell’applicazione che probabilmente sta utilizzando da anni; ciò che noi vediamo come una presenza ingombrante, per lui altro non è che l’applicazione che funziona e fa quello che gli serve.
Recentemente, durante una consulenza da un cliente, il responsabile dell’IT mi ha confidato, “il programma funziona benissimo, ma lì sotto è un macello!”. Quindi, tornando alla metafora del vestito da scucire e ricucire, attenzione a come suddividiamo l’abito, a come individuiamo le linee lungo le quali disfare le cuciture per imbastire il nuovo abito. Dobbiamo considerare alcune linee guida che potranno pilotare le nostre forbici a tagliare correttamente, o il nostro scalpello, a togliere esattamente il marmo in eccesso, e nulla di più.
Individuare le parti
Dobbiamo partire dalla nostra applicazione e individuare le parti che possono essere trattare separatamente; se prediamo come esempio un gestionale, potremmo pensare di individuare i confini di separazione in base alle funzionalità che esso espone.
Pensiamo alla classica funzionalità di Gestione ordini, che sicuramente avrà bisogno di accedere alle informazioni del Cliente in una ipotetica tabella Nominativi del nostro database… sempre lì andiamo a finire!. È chiaro che fra questi due Context c’è un accoppiamento, ma c’è altro. La tabella dei Nominativi servirà a molti altri moduli del nostro gestionale, ma di per sé potrebbe anche vivere di vita propria: allora perché non isolarla ed esporre le sue proprietà, ed i suoi comportamenti, come servizio?
La situazione tipica potrebbe essere qualcosa di simile alla figura 1.
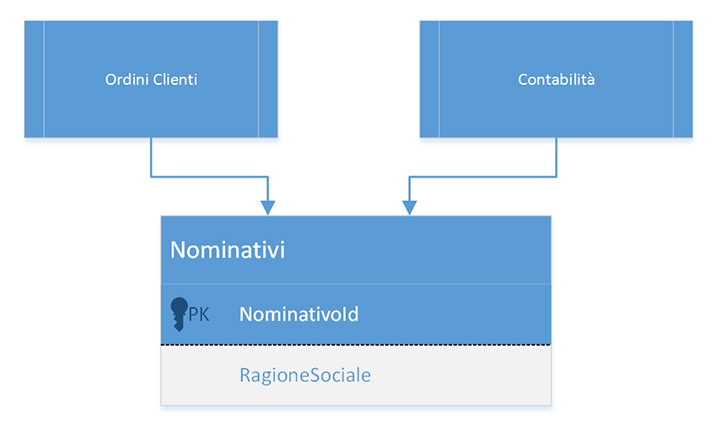
Lavorare sul database: OR/M
Entrambi i moduli accedono, in lettura e probabilmente in scrittura, alla stessa tabella, e noi vorremmo intervenire e tagliare proprio questa relazione. Quello di cui abbiamo bisogno, e che spesso non è modellato nel codice, è il concetto di dominio, perché questo concetto lo abbiamo implicitamente modellato all’interno del database. A noi invece servirebbe un altro concetto, ossia quello di Nominativo.
Che strumenti abbiamo a disposizione per facilitarci la vita in questa fase? Sicuramente un OR/M è lo strumento più appropriato. Poter mappare il nostro database all’interno dell’applicazione ci solleva da molti compiti ingrati, quindi non abbiamo grosse alternative: o esiste una mappatura del database, oppure, se non era stata implementata, bisogna introdurla. Questa è sicuramente la prima operazione da compiere.
Fra i tools che il mercato mette a disposizione ci sono Hibernate — NHibernate per gli amanti come me del mondo .NET — o EntityFramework. Non sto a dire quale sia il migliore o il peggiore, perché come sempre dipende. Grazie a questi strumenti potremo usufruire di un pattern in più per gestire il nostro database, che ci aiuterà a meglio definire i confini del nostro Contesto, il Repository Pattern.
Repository Pattern
Questo pattern, insieme al suo fratello maggiore Unit of Work, ci farà da guida nella comprensione delle relazioni, e quindi dei relativi tagli da apportare, all’interno del nostro schema. Per evidenziare le relazioni e i vincoli esistenti nel nostro database è molto utile un altro strumento, open source, SchemaSpy [3].
Il primo passo che dobbiamo compiere è quello di creare un nuovo progetto software che chiameremo NominativiService, o qualsiasi altro nome vi aggradi, che esporrà la risorsa Nominativo; lo potrà fare in tutti i modi analizzati nel precedente articolo e questo non è importante ora. Possiamo pensare, per semplificare il tutto, a una API esposta via HTTP. Ma possiamo spingerci oltre e pensare di avere anche un OrdiniClientiService e un ContabilitaService. Procediamo per gradi (figura 2).
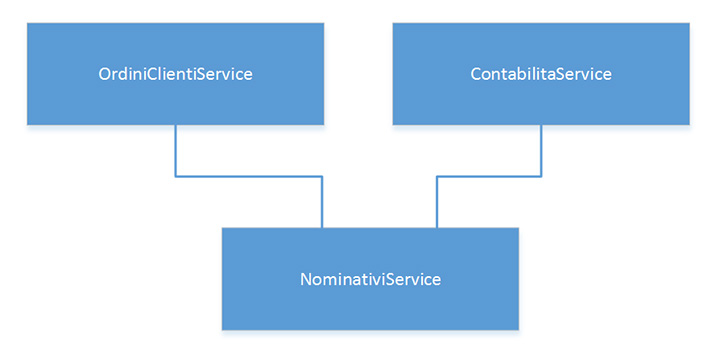
In questo modo abbiamo fatto emergere il concetto di Dominio celato nel database e gli abbiamo assegnato il ruolo che gli spetta. Ora la suddivisione è a livello applicativo, e ogni Dominio è ben esplicitato.
Pronti al cambiamento
Ricapitolando, abbiamo individuato i confini — o i tagli se vogliamo restare all’esempio del sarto — all’interno della nostra applicazione e abbiamo raggruppato il codice attorno ai tanto agognati Bounded Context. Forti della nostra scoperta abbiamo individuato gli stessi raggruppamenti all’interno del database e ora siamo pronti a dividere il tutto e a fare il primo rilascio della nostra applicazione versione microServices … Ma lo siamo veramente?
Meglio procedere per gradi; proviamo a separare il nostro database, che è sempre una presenza ingombrante, e come abbiamo già visto, la prima forma di condivisione da eliminare. Quindi, come primo passo manteniamo i servizi uniti, e dividiamo il database. Questo ci permetterà di avere ancora il controllo sul vecchio codice, prima di poter procedere a dividere anche quest’ultimo per ottenere il risultato finale. La figura 3 tenta i riassumere quanto appena detto.
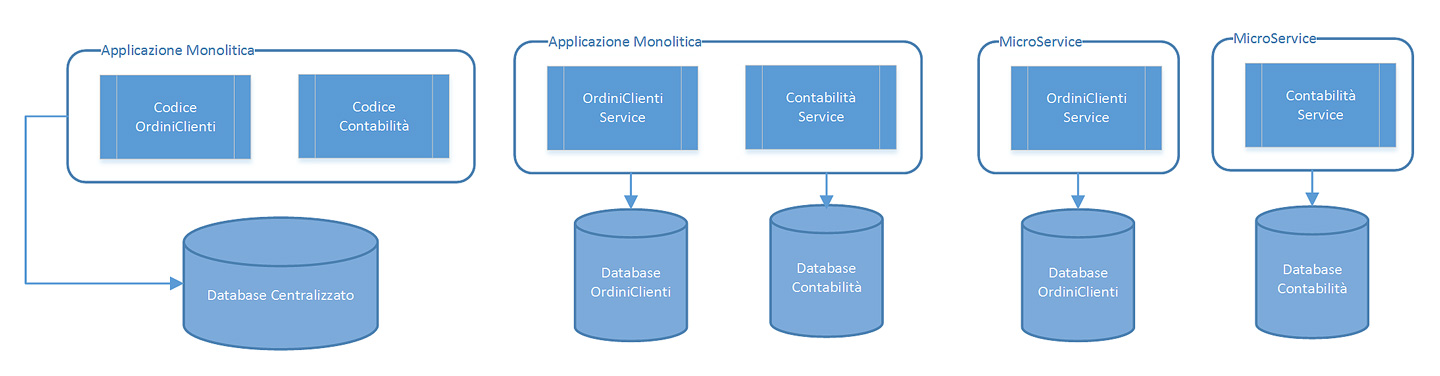
Anche la suddivisione ha i propri inconvenienti…
In pratica siamo passati da una Big Ball of Mud a una situazione più gestibile, più scalabile; ma abbiamo veramente risolto tutti i problemi? O ne abbiamo potenzialmente introdotti di nuovi? Nella prima fase del nostro processo — quando avevamo tutto a portata di… codice — ci bastava una SELECT ben piazzata al posto giusto per avere informazioni raggruppate su un Ordine Cliente, oppure su un Cliente.
Ora invece abbiamo potenzialmente alzato il numero delle transazioni verso il database per avere più o meno le stesse informazioni, e questo deve essere gestito. Ma non è nemmeno l’unico potenziale problema: l’integrità del database è facile da gestire fin quando il database non è suddiviso; ma una volta separato il database, garantire l’integrità dei dati diventa una faccenda un poco più complessa.
Eventual consistency: coerenza e allineamento del database
In un’applicazione monolitica è assai probabile che tutte le tabelle del database interessate in un’operazione vengano aggiornate con un’unica transazione che ci garantisce di lasciare il database stesso in uno stato di sostanziale coerenza e allineamento una volta terminata la transazione: se le cose vanno bene, lo stato del database verrà aggiornato con un Commit, mentre, se vanno male, un RollBack provvederà a garantire un coerente ritorno allo stato precedente.
Ora invece, potenzialmente potremmo avere l’inserimento di un nuovo Ordine Cliente, ma non trovare aggiornato il database della Contabilità. Nel più semplice dei casi potremmo essere di fronte a una questione nota come eventual consistency. La definizione è volutamente lasciata in inglese, e occorre tenere presente che eventual in inglese significa “finale” (e non “eventuale”, come a volte viene erroneamente tradotto) e consistency vuol dire “coerenza”, “uniformità”, “allineamento”. In italiano, infatti, “consistenza” significa “compattezza”, “solidità”, “robustezza”, anche se questo termine italiano è ormai entrato nell’uso comune informatico per indicare proprio “coerenza” e “allineamento” dei dati.
Ciò premesso, l’espressione eventual consistency sta a significare che il database ci dice più o meno questo: “stai tranquillo… per ora non lo sono, ma alla fine i miei dati saranno coerenti e allineati, ossia ‘consistenti’…”.
In presenza di transazioni fra Bounded Context diversi bisogna considerare alcuni fattori che potrebbero rallentare il riallineamento di tutti i database, come ad esempio la latenza della rete, ma anche il fatto che la presenza della rete stessa non è garantita a prescindere, e di questo le nostre comunicazioni devono essere consapevoli. Non a caso, nello scorso articolo, abbiamo citato RabbitMQ per gestire l’invio e la ricezione di messaggi in modo sicuro fra Bounded Context.
Un’altra opzione che abbiamo a disposizione, se veramente constatiamo che qualcosa non ha funzionato, è quella di abortire l’intera transazione, e questo lo possiamo fare con una compensating transaction, ossia una nuova transazione che si dovrà occupare di ripristinare i disastri lasciati dalla prima… Eh sì, ma se anche questa fallisse?
Transazioni distribuite
Un’alternativa alla gestione manuale della transazione compensativa — o delle transazioni, in caso di scenari un po’ più complessi — è quella di utilizzare una Transazione Distribuita. In pratica si ricorre a un gestore delle transazioni (Transaction Manager) per orchestrare le varie transazioni e assicurarci che il tutto vada a buon fine.
Questo “direttore d’orchestra” esegue lo stesso compito della transazione che conosciamo nel contesto del database, ossia, si assicura che tutte le transazioni che deve gestire vadano a buon fine, oppure, nel caso anche solo una fallisse, di ripristinare il tutto riportando lo stato del sistema allo stato consistente iniziale.
Two-phase
Come procede? Uno degli algoritmi più diffusi in questo caso è quello delle due fasi (two-phase). La prima fase è quella del voto. In questa fase ogni partecipante — termine specifico in questo contesto è cohort — è chiamato a comunicare al direttore d’orchestra le sue intenzioni circa l’operazione che deve compiere: in pratica deve dire se ci sono i presupposti perché vada a buon fine oppure no. Ovviamente ora il gioco è facile da capire. Se tutti i partecipanti esprimono voto favorevole, allora il direttore procede; se un solo cohort esprime voto contrario, l’intero processo non parte, lasciando lo stato del sistema inalterato.
Questo algoritmo si basa sull’assunto che chiunque abbia espresso voto favorevole poi porti a termine il proprio lavoro, ma è inutile negare che ogni singolo partecipante potrebbe fallire nel suo intento. Le implementazioni di questo processo cercano di porre rimedio alla maggior parte dei problemi. Sistemi di questo tipo sono stati implementati per diverse tecnologie: Java Transaction API per il mondo Java e la controparte in .NET nel namespace System.Transactions.
È chiaro che una risposta definitiva su come procedere non esiste: nella più classica asserzione da puro dev, esiste la solita e infallibile risposta “dipende”. Se veramente abbiamo bisogno di gestire la consistenza, e non abbiamo alternative valide, come primo step vale la pena considerare una suddivisione a grana grossa del database, in modo da mantenere unite le tabelle che devono essere gestite in questo modo, e magari pensare alla loro suddivisione in una seconda fase del processo di refactoring dell’intero monolite.
Quanto costa cambiare?
Come al solito, è necessario dare un senso alle divagazioni sin qui tenute. In questo articolo siamo partiti dall’idea che un’applicazione monolite sia difficile, se non addirittura impossibile da manutenere, e quindi, abbiamo visto una possibile strada per trovare una soluzione a questo problema. Tanto per citare ancora qualche fonte autorevole, nel loro libro Scalability Rules: Principles for Scaling Web Sites [4], Martin Abbot e Michael Fisher hanno presentato un modello per le possibili alternative alla scalabilità, riassumibile in figura 4.
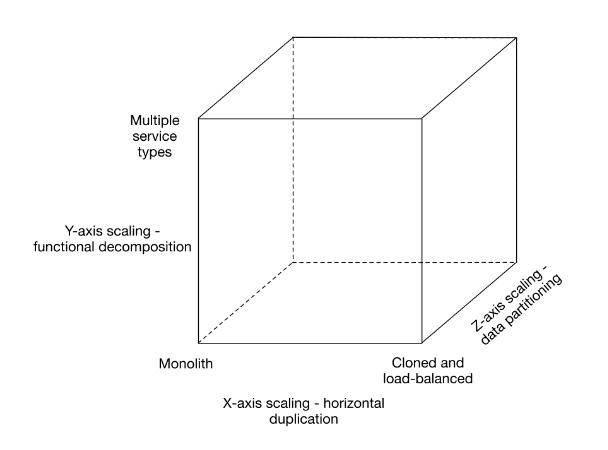
Noi abbiamo scelto di muoverci lungo l’asse delle Y, suddividendo il monolite in tanti piccoli microservices.
Se il nostro scopo è quello di ottenere una soluzione immune agli errori, allora non esistono pattern o guru che ci possano aiutare. L’errore è parte integrante del nostro lavoro, e bisogna accettarlo. Il vantaggio che si ha suddividendo il sistema in tante piccole parti è che, quando commetteremo un errore, ne commetteremo uno di piccole dimensioni, facilmente individuabile e quindi facilmente risolvibile, il tutto con un impatto minimale sull’intero sistema.

Nella più assoluta coerenza con i principi Lean, dobbiamo monitorare l’intero sistema, non la singola parte. Ma poter modificare un solo servizio per rilasciare una nuova funzionalità ci espone a rischi decisamente più bassi che non dover rilasciare l’intero sistema ogni volta, senza considerare quello che spesso accade quando si devono affrontare personalizzazioni ad hoc per particolari clienti e/o esigenze. Quindi, dovendo valutare i costi di questi cambiamenti, risponderei con un’altra domanda: “Quanto costa lasciare le cose inalterate?”.