

Introduzione: analizzare e capire i dati a disposizione
In un intricato labirinto di tecnologie, denso di idee rivoluzionarie ma anche di hype poco concreto, una delle necessità aziendali di questi tempi ste nell’effettuare, sulle disponibili basi dati, analisi previsionali con la capacità di fornire una qualche forma di vantaggio competitivo: nell’ottimizzazione dei processi, nel miglioramento della soddisfazione del cliente o anche solo nella comprensione dei processi aziendali.
Le analisi effettuate vanno dalla predizione di fluttuazioni di mercato, previsione di failure di dispositivi, analisi dei sentiment, alerting; in molti casi, le tecniche impiegate appartengono al dominio di Complex Event Processing, Data Mining o Machine Learning propriamente detta. Indipendentemente però dalle tecniche di analisi utilizzate e dagli obiettivi delle previsioni, tutte queste analisi sono caratterizzate dall’esigenza di elaborare imponenti volumi di dati in tempo quasi reale.
Ci si propone, in quanto segue, di analizzare il problema dell’analisi dei dati in tempo quasi reale a prescindere dalla tecnica di predizione impiegata, ma discutendo una delle piattaforme di data processing al momento più potenti e promettenti: Apache Flink [1], un framework di stream processing open source.
Big Data e loro elaborazione
Per definire cosa sia lo “Stream Processing” è necessario partire da una analisi delle caratteristiche dei dati su cui questo approccio di calcolo opera: i Big Data. I Big Data rappresentano certamente uno dei fattori evolutivi nel mondo dell’analisi dei dati e della business intellingence e sono caratterizzati da enormi volumi, formati destrutturati e formati eterogenei e, spesso, vengono prodotti con estrema velocità. Si dice comunemente che volume, varietà e velocità sono i fattori che li identificano.
Il volume e la varieta dei Big Data
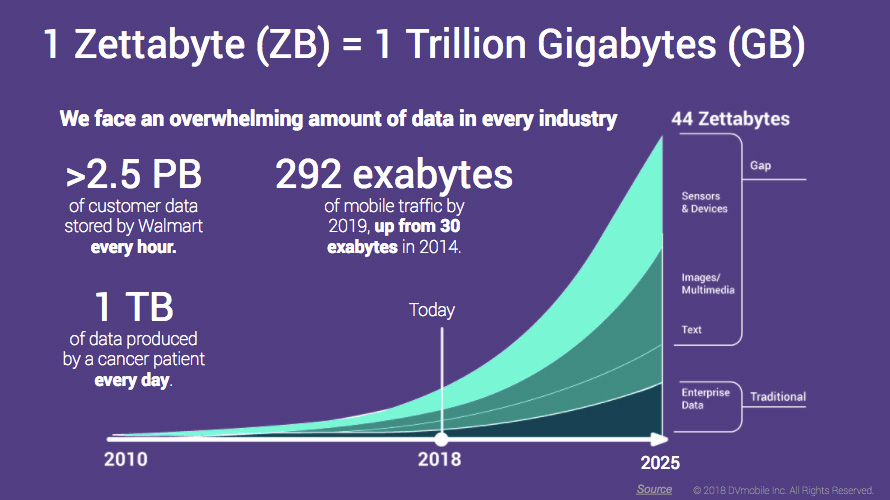
Per tentare di avere un’idea di quali siano i volumi di dati di cui stiamo parlando, si consideri che in un articolo del 2014 IBM stimava che venissero generati 5.5 miliardi di dati ogni giorno (CITE).
Una stima più recente (figura 1) regala una ancora più precisa visione [2]; non solamente si prevede che in meno di 10 anni si raggiungeranno 44 zettabytes (270 bytes!) di dati, ma la maggior parte dei dati saranno generati da sensori e device, e saranno quindi sostanzialmente dati totalmente non strutturati e che per giunta spesso non hanno gran senso e significato di per sé, se non come dati aggregati.
La velocità dei Big Data
Ancora, guardando il grafico, possiamo notare che Walmart, per esempio, produce 2.5 PB di dati ogni ora, il che significa che i dati arrivano con un rate vicino ai 300 GB/sec; velocità impossibili da gestire senza l’impiego di un cluster di nodi di calcolo.
L’idea di raggiungere performance di calcolo capaci di analizzare enormi volumi di dati grazie al calcolo parallelo non è certamente nuova: si pensi solo che è alla base del modello di calcolo comunemente chiamato MapReduce già reso popolare da Google nella scorsa decade.
Il modello di calcolo “classico”
Il classico modello di calcolo applicato potrebbe, per la verità, essere schematizzato come in figura 2.
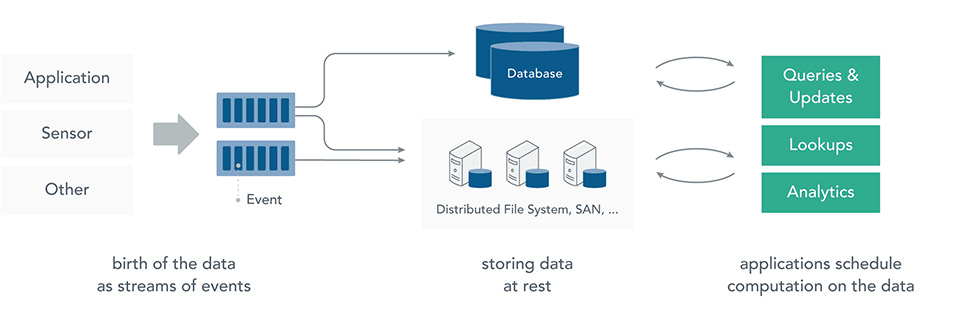
I dati vengono registrati su (enormi) sistemi di storage (HDFS, HBASE o simili) e poi analizzati. Questo approccio è certamente scalabile ed è stato applicato con successo in numerosi contesti a problemi di dimensione gigantesca.
Tuttavia nel contesto di cui stiamo parlando, presenta due principali problemi:
- Registrare e poi processare i dati introduce artificiali delay nelle computazioni, introducendo inutili (e costosi) ritardi.
- Registrare i dati potrebbe essere più dispendioso del necessario; infatti, come detto in precedenza, spesso i dati non sono interessanti di per sé, ma solo in forma aggregata; una loro registrazione quindi costringe ad avere uno spreco di storage, per dati che non ha realmente un senso mantenere.
Un nuovo modello di calcolo: Stream Processing
Pertanto, nei contesti in cui si vogliano analizzare near-realtime grandi volumi di dati, emerge la necessità di esplorare un nuovo modello di calcolo, quello che comunemente viene detto Stream Processing.
In figura 3 è schematizzato lo Stream Processing e si mette in evidenza come sia sua caratteristica l’elaborazione dei dati ancora in movimento, senza l’esigenza di memorizzarli e quindi senza dover introdurre ritardi “artificiali” nel calcolo.
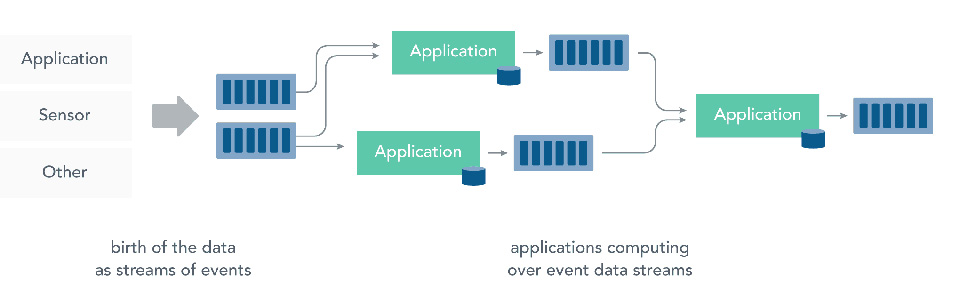
Il passaggio a questo nuovo modello di calcolo si porta dietro molte più conseguenze di quanto si possa immaginare; si rende possibile la computazione near-realtime ma si aprono anche numerose nuove problematiche da affrontare tra le quali quelle relative a throughput, fault tolerance, interoperability, community. Vediamole brevemente di seguito.
Throughput
Se le computazioni avvengono direttamente sui dati mentre questi arrivano, il nostro sistema di calcolo deve essere sempre in grado di analizzare e processare i dati al medesimo rate a cui questi arrivano.
Fault tolerance
Se i dati non vengono memorizzati, ma elaborati on-the-fly, il sistema è nella situazione di non potersi fermare pena la perdita di dati.
Interoperability
Il sistema di analisi dati deve essere in grado di utilizzare come sorgenti e/o destinazione di dati una gran varietà di piattaforme e sistemi che, nel vorticoso ambiente del big data processing, nascono e si evolvono con estrema rapidità.
Community
La messa in produzione di un sistema di calcolo distribuito per lo stream processing su larga scala è per sua natura dispendioso e complesso ed è quindi importante investire le energie in una piattaforma con almeno una comunità attiva che possa far sperare su un supporto di almeno qualche anno nel futuro.
Apache Flink è esattamente uno dei più attivi player nell’ambito dello stream processing. Nei paragrafi che seguono, cercheremo di capire come questo framework risponda alle esigenze sopra menzionate.
Flink, il progetto e la community
Apache Flink [1] è un framework open source per lo stream processing nato come fork del progetto di ricerca Stratosphere [3], finanziato dalla Comunità Europea e di cui fanno parte alcune università tedesche dell’area di Berlino (TU Berlin, HU Berlin, HPI Potsdam). Flink è attualmente sviluppato dalla Apache Software Foundation.
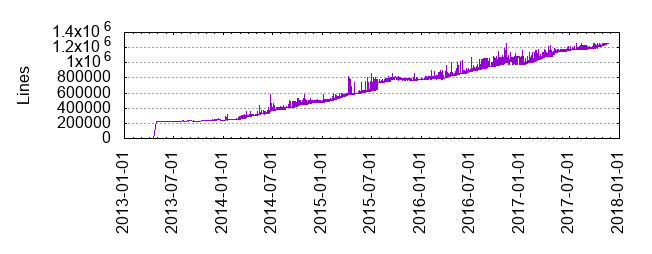
Il progetto, accettato come Top Level Apache project dal 2014, è mantenuto su Github [4] da oltre 25 committers e più di 350 contributors che hanno prodotto oltre 10k commits e quasi 50 release.
Prendendo spunto da Apache Flink in 2017: Year in Review [5] si può osservare come Flink sia un progetto in grande evoluzione e supportato da una comunità dinamica. A dimostrazione di questa evoluzione, nell’ultimo anno, infatti, sono in crescita sia il numero dei contributors che le stars e i forks.
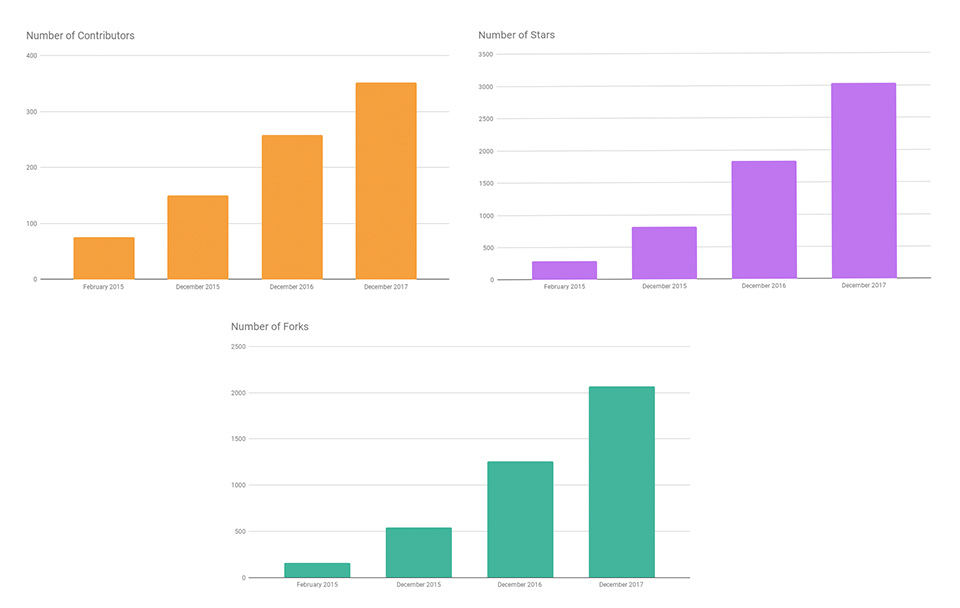
Anche se non si tratta di una metrica totalmente sensata, per il codice è interessante osservare che Flink su github ha superato un milione di righe di codice nel 2016, e nel 2017 il trend è continuato, con il codice base che ora conta circa 1,257,949 linee corredate da diverse migliaia di test case [5].
Flink: caratteristiche principali
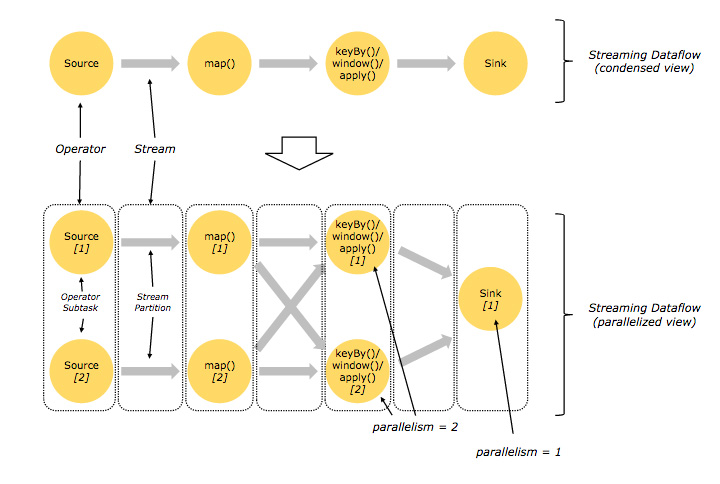
Il core di Apache Flink è un motore per l’elaborazione stateful e distribuita di stream di dati scritto in Java e Scala, che permette di lavorare sostanzialmente con la medesima API su dataset bounded e unbounded, adattandosi quindi sia come piattaforma per le esigenze di batch processing che per quelle di stream processing.
A grandi linee, un’applicazione Flink può essere immaginata come un insieme di operatori (distributed, stateful) che rappresentano i core di calcolo, connessi tra di loro da vere e proprie pipeline, con Flink che si occupa sia della implementazione delle connessioni che dell’esecuzione degli operatori su thread separati eventualmente distribuiti su molteplici host.
Con oltre 1M di righe di codice, le caratteristiche di Flink degne di nota sarebbero numerose e di molte di esse non ci sarà modo di parlare in questo articolo; ma alcuni aspetti meritano di sicuro una nota.
Esecuzione parallela con elevato throughput e bassa latenza
Apache Flink è stato costruito sin dal principio per supportare l’esecuzione su cluster di centinaia o addirittura migliaia di nodi (con supporto anche per YARN and Mesos)
Grazie a una architettura estremamente efficiente, basata su Actor Model (e Akka), Flink riesce a raggiungere elevate performance e bassissime latenze nell’analisi in continuo di eventi streamed, mantenendo grossa parte dei dettagli della distribuzione dei dati su cluster ininfluenti per lo sviluppatore che può continuare a pensare l’applicazione come una sequenza di trasformazioni eseguite (quasi) sequenzialmente.
Fault tolerance e state versioning.
Grazie ad un sosfisticato sistema di checkpoint, Flink è in grado di resistere alla failure di nodi di calcolo e ripartire automaticamente da apposite materializzazioni su filesystem del proprio stato interno (checkpoint).
Se i checkpoint sono pensati per la fault tolerance, esiste anche una variante (relativamente) portabile dei checkpoint, chiamata savepoint, che permette di esportare lo stato di un’applicazione in esecuzione e di renderne possibile il restore in un secondo momento, eventualmente su hardware diverso oppure addirittura dopo il fix di bug e/o modifiche al codice.
Entrambe queste operazioni sono possibili in Flink soddisfacendo la cosiddetta exactly-once semantics, cioé la garanzia che, sotto opportune ipotesi circa le sorgenti dati e la topologia delle applicazioni, sia possibile mantenere una relazione uno-a-uno tra lo stato dell’elaborazione e i dati elaborati, che anche in caso di failure o restart si possa garantire che ogni “event” sia elaborato esattamente una volta.
Ecosystem
Flink si occupa di rendere relativamente facile lo sviluppo di applicazioni distribuite per l’analisi di dati ma non fornisce alcuna primitiva o componente per lo storage o il salvataggio dei risultati delle elaborazioni. Piuttosto, Flink mette invece a disposizione delle API ad alto livello per descrivere sorgenti e sink di dati, con le quali possono essere realizzati connettori con gli esistenti strumenti.
Numerosi connettori sono forniti anche insieme al runtime di Flink, tra i quali è interessante ricordare
- Apache Kafka, utilizzabile sia come sorgente che come destinazione dei dati
- Apache Cassandra
- RabbitMQ
- Apache NiFi
- ElasticSearch
A questi, si aggiunge una completa compatitilità con le Apache Hadoop MapReduce Interfaces e l’esteso set di connettori mantenuti sotto il progetto Apache Bahir [6].
È da notare che è disponibile per Flink anche un layer di compatibilità con Apache Storm che permette di eseguire applicazioni scritte per Storm sull’architettura più performante di Flink.
API
A disposizione degli sviluppatori, Flink mette delle API sia per Scala che per Java, con features sostanzialmente identiche, alle quali si è di recente aggiunta una API Python che nel tempo si sta arricchendo.
Scrivere un’applicazione per Flink consiste in buona sostanza nel comporre, attraverso le primitive messe a disposizione dalla API, operatori e connettori che vanno pensati come trasformazioni successive dei dati.
Le sole primitive per la trasformazione degli unbounded data set che permettono con grande naturalezza di effettuare join, connect, map, filter sugli stream sono oltre trenta, alle quali vanno aggiunte le operazioni sulle time-window che rendono possibili operazioni di manipolazione (riordino, segmentazione etc.) dei dati in base a finestre temporali. Tale vastità di API rende impossibile una descrizione completa: piuttosto che cercare di illustrare tutti i metodi e gli operatori — descritti comunque nella documentazione ufficiale [7] — preferiamo procedere con un esempio, che illustri come avviene la composizione delle trasformazioni per realizzare un’intera applicazione con Apache Flink.
Un caso d’esempio
Senza pretendere di descrivere a fondo come testare, eseguire ed eventualmente deployare in produzione un’applicazione Flink — cose che cercheremo di fare nel prossimo articolo con taglio hands-on — vogliamo descrivere ad alto livello una piccola applicazione Flink che ci permetta di evidenziare alcune delle principali caratteristiche della “elegante” streaming API.
La regola principale quando si progetta una applicazione Flink è quella di pensare l’elaborazione come la composizione di operatori applicati direttamente allo stream di dati che “attraversano” l’applicazione che possiamo immaginare come una pipeline di calcolo.
Con le dovute cautele, un’applicazione flink è immaginabile in modo molto simile a come si immagina un pezzo di codice Java che utilizza i Java 8 stream, con però una piattaforma di esecuzione che provvede per noi alla parallelizzazione e distribuzione del processo.
La struttura dell’applicazione
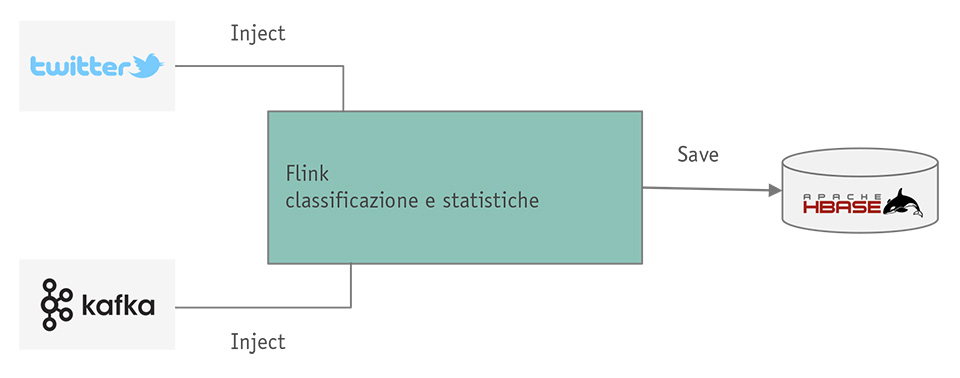
Ovviamente, la struttura dell’applicazione che vogliamo immaginare è molto semplice, ma non banale. Vogliamo considerare un’applicazione che elabora contemporaneamente dati provenienti da due sorgenti: uno stream di tweet ed una coda Kafka (usata come sorgente di dati di configurazione).
Le sorgenti che dobbiamo usare sono la Twitter source — ampiamente documentata sulla guida ufficiale [8] — e il connettore per Kafka, disponibile in numerose varianti [9].
L’applicazione d’esempio, una volta “ingeriti” entrambi gli stream, dovrà elaborarli in modo tale che per ogni tweet in arrivo sia calcolata una statistica sul numero di hashtag utilizzati e si riceveranno dalla coda Kafka invece subscriptions, cioé triplette di stringhe {<username>,<+/->,<hashtag>}, che verranno interpretate come: “l’utente <username> vuole essere informato delle statistiche circa l’hashtag <hashtag>”.
Infine decidiamo che la nostra applicazione, una volta classificati i tweet e determinati gli utenti che vogliono le notifiche, salverà i dati elaborati in una base dati HBASE. Lo schema dell’applicazione pipelined è semplicemente quello descritto nella figura 8.
Nella figura 9, invece, se ne mostra la struttura in termini di operatori e primitive di Flink.
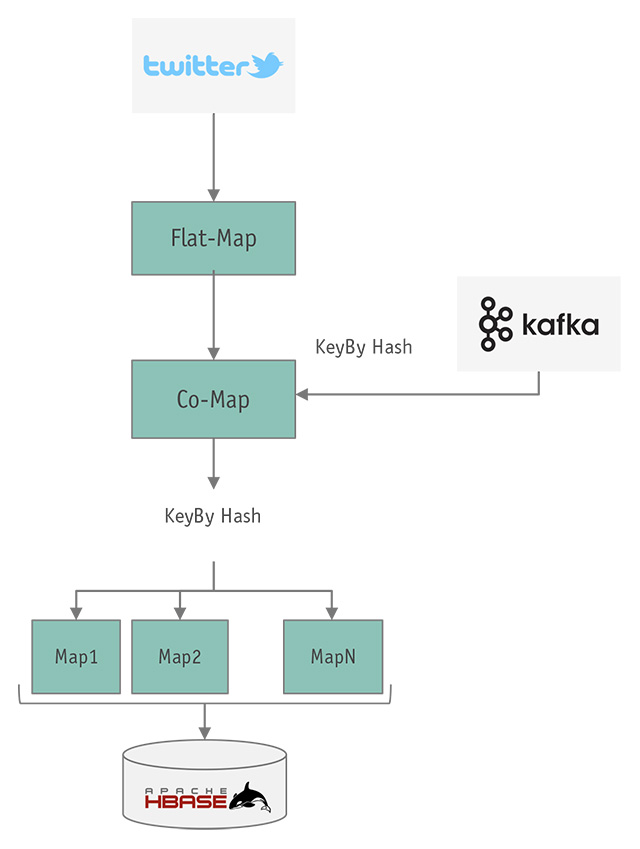
Qualche dettaglio in più…
Non è difficile osservare che, nello schema dettagliato, sono combinati operatori il cui preciso uso sarà chiarito nell’articolo successivo in cui parleremo di codice. Già qui, abbiamo comunque la possibilità di descrivere le caratteristiche di alcuni degli operatori.
Abbiamo, subito dopo la lettura dei dati dallo stream di Twitter, un operatore di tipo flat-map, cioé un operatore che, per ogni elemento in entrata, può emettere un numero arbitrario di elementi in uscita; lo useremo per eliminare eventuali elementi che non ci interessano — nella Twitter streaming API, oltre ai tweet, ci sono altri dati di controllo che noi vogliamo trascurare — e per duplicare i tweet uno per ogni hashcode, in modo da poter processare hashtag diversi come fossero stream diversi.
Alla flat-map, segue un operatore di tipo co-map: questo operatore è caratterizzato dal fatto che riceve due stream in input (tweets e configurazioni) ed è la parte di codice in cui effettueremo sia la registrazione delle subscription (quindi mantenendo uno stato) che la selezione dei tweet per subscription.
A cascata, dopo la co-map, avremo delle map che effettueranno le statistiche e genereranno l’output che un opportuno operatore di tipo sink provvederà a scrivere su HBase.
Nella figura si è evidenziato una sorta di parallelismo per le sole operazioni map alla fine della catena, in quanto questi operatori saranno quelli che calcoleranno le statistiche sui nostri tweet e quindi saranno la componente “computazionale” dell’intera applicazione.
Va comunque osservato che tutti gli operatori nell’applicazione potranno essere eseguiti in parallelo su thread e/o nodi diversi e grazie alle nostre scelte di keyBy, primitiva mostrata in figura ma non ancora descritta, potranno essere eseguite parallelamente anche le operazioni stateful (cioé quelle in cui gli operatori accumuleranno uno stato interno) senza perdite di efficienza a causa di comunicazioni e/o trasferimenti di dati da un nodo/thread all’altro.
Sostanzialmente keyBy, in base a una chiave specificata nel codice, consente di partizionare i dati provenienti dallo stream originale e processarli in parallelo.
In questo flusso, Flink si occupa di gestire le operazioni sugli stream, del parallelismo… ma la business logic deve essere descritta e sviluppata dal developer, ed è quindi esterna a quanto gestito dal framework Flink.
Un po’ di codice
Come detto, la descrizione e il funzionamento dell’intero codice sarà argomento di un futuro approfondimento; ma, a testimonianza dell’eleganza e della compattezza della API di Flink, quello che segue è l’intero main method dell’applicazione appena descritta.
Se si tolgono le inizializzazioni per connettersi alle sorgenti di dati si tratta sostanzialmente di 10 righe di codice. Non male anche per il nostro semplice test case.
// set up the streaming execution environment
final StreamExecutionEnvironment env
= StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty(TwitterSource.CONSUMER_KEY, "");
properties.setProperty(TwitterSource.CONSUMER_SECRET, "");
properties.setProperty(TwitterSource.TOKEN, "");
properties.setProperty(TwitterSource.TOKEN_SECRET, "");
TwitterSource twitterSource = new TwitterSource(properties);
FlinkKafkaConsumer011<String> kafkaConsumer
= new FlinkKafkaConsumer011<>("topic",new SimpleStringSchema(), properties);
kafkaConsumer.setStartFromLatest();
DataStream<String> kafkaSource = env.addSource( kafkaConsumer );
env.addSource(twitterSource)
.flatMap(new TweetsParser()) //decodes tweets
.flatMap(new TweetsPerSearchCriteria()) //duplicate tweets, one per hashtag/mention
.connect(kafkaSource.map(new SubsriptionsParser())) //parse subs and connect the streams
.keyBy(new ClassifiedTweetsKeySelector(),new SubscriptionsKeySelector())
.flatMap(new TweetsPicker()) //pick tweets according to subscriptions
.keyBy(new CombinedKeySelector())
.map(new TweetsPerSubscriptionAnalyzer()) //analyze tweets per subscription/tag
.writeUsingOutputFormat(new MyHBaseOutputFormat()); //write data
// execute program
env.execute("Mokabyte/Flink sample");
Conclusioni
In questo articolo abbiamo introdotto le potenzialità di Apache Flink, un framework open source pensato per analizzare ed elaborare imponenti volumi di dati in tempo quasi reale. In un mondo dominato dall’importanza dei Big Data, un’infrastruttura di questo tipo può trovare svariati tipi di applicazione.
Abbiamo poi visto la struttura concettuale di un’applicazione di esempio, corredandola di una piccola porzione di codice che mette in luce l’eleganza e l’efficacia delle soluzioni basate su Flink.
Nel prossimo articolo vedremo nel dettaglio l’implementazione dell’applicazione di esempio e la sua esecuzione su un cluster.
Freelance, Web & Mobile Developer and Architect, with a passion for fine tuned details.
Co-founder at K-TEQ Srls (http://www.k-teq.com).
GDG-Firenze Lead and founder. Intel Software Innovator.
#Java #GWT #StreamProcessing #MachineLearning
https://www.linkedin.com/in/francescatosij/
Sviluppatore web e mobile, freelance, teacher, sysadmin.
Attualmente lavoro come Java Developer e Architect per l'azienda di cui sono co-fondatore: K-TEQ Srls (http://www.k-teq.com)
#Java #GWT #JavaScript #HTML5 #Flink #MachineLearning
https://www.linkedin.com/in/abmancini/