

Introduzione
Ci siamo lasciati alla fine dell’articolo precedente della serie con l’applicazione disponibile su github [1], (tag third-step [2]). Che può di fare questa applicazione?
- Ci sono flussi di dati in tempo reale disponibili attraverso il Twitter streaming endpoint [3].
- L’applicazione è in grado di processare tale il flusso di “cinguettii” , o meglio, le stringhe fino al momento della loro trasformazione in Status che effettua la nostra flatMap TweetsParser.
- L’applicazione è poi in grado di accoppiarli in uno stream di tipo ConnectedStreams con un secondo stream proveniente da una coda Kafka: da notare che il codice è pronto per ricevere dati da Kafka ma, per comodità di sviluppo, la sorgente Kafka è commentata in favore di una più maneggevole stream costruito a partire da una lista di stringhe.
Provando ad eseguire l’applicazione direttamente da Idea, otteniamo nella console una lista di messaggi simili a quelli seguenti:
... 6> Map1, ... searchCriteria: #BTS 1> Map1, ... searchCriteria: #BTSARMY 6> Map1, ... searchCriteria: #BTSARMY 3> Map1, ... searchCriteria: #BlueJays 3> Map1, ... searchCriteria: #CamilaCabello 6> Map1, ... searchCriteria: #EstaVez 4> Map1, ... searchCriteria: #FSRádioBrasil 8> Map1, ... searchCriteria: #FakeNews 4> Map1, ... searchCriteria: #Giveaway 1> Map1, ... searchCriteria: #HarryStyles 2> Map1, ... searchCriteria: #IDOL 7> Map1, ... searchCriteria: #IDOL ...
Qui si vede chiaramente che i messaggi con il medesimo “search criteria” vengono elaborati da thread diversi, il thread 1 e il 6 nel caso di #BTSARMY ed il 2 ed il 7 per #IDOL, rendendo quantomeno complessa l’aggregazione.
Stream Partitioning/Keying
Il problema che ci si presenta adesso è che, per poter elaborare — calcolare statistiche come ci eravamo proposti nella prima parte di questa serie — gli elementi dello stream, dobbiamo riuscire a distribuirli in modo da essere sicuri che l’esecuzione parallela faccia finire nel thread giusto, eventualmente su uno dei server di un cluster, tutti i messaggi rilevanti per le nostre computazioni.
Detto in un altro modo, dobbiamo istruire flink a instradare i messaggi con il medesimo tag nella medesima istanza dell’operatore di aggregazione.
L’operazione di dividere uno stream in “parti” (dette partizioni) in modo che possano essere elaborati opportunamente, in flink è chiamata keying dello stream e consiste sostanzialmente nell’associare ad ogni elemento una key che verrà usata per selezionare l’istanza dell’operatore che riceverà tutti gli elementi con la medesima key.
Associare key ai connected stream
La flink API ci permette di associare key ai nostri connected stream come segue:
//partition the stream using a key extractor,
//elements with the same key will be processed in the same partition
ConnectedStreams<Tuple2<String, Status>, Tuple3<String, String, String>>
keyedTweetsAndConfigurations = tweetsAndConfigurations.keyBy(
new KeySelector<Tuple2<String, Status>, String>() {
@Override
public String getKey(Tuple2<String, Status> v) throws Exception {
return value.f0;
}
},
new KeySelector<Tuple3<String, String, String>, String>() {
@Override
public String getKey(Tuple3<String, String, String> v)
throws Exception {
return value.f0;
}
}
);
Nel precedente blocco di codice siamo stati costretti ad implementare due KeySelector in quanto l’oggetto ConnectedStreams su cui operiamo è composto da due stream; la medesima operazione di keying su uno stream “semplice” avrebbe richiesto un singolo KeySelector.
Sintassi più semplici
A onor del vero, esiste una sintassi più semplice nei casi in cui, come il nostro, gli stream sono composti di Tuple* e il blocco di codice precedente si potrebbe ridurre a
tweetsAndConfigurations.keyBy(0,0);
Ma, secondo noi, la forma estesa è più comprensibile, anche se più prolissa, e abbiamo deciso di presentare il codice in questa forma.
Anche l’uso delle Java8 Lambda per implementare i KeySelector avrebbe semplificato il codice e l’implementazione di molti degli operatori ma purtroppo questa strada non è percorribile senza speciali precauzioni, per il modo in cui le Lambda con generics sono trasformate in bytecode. Invitiamo tutti gli interessati a fare una prova e ad approfondire la questione a partire dal messaggio di errore che riceveranno durante l’esecuzione dell’applicazione.
Avendo effettuato il keying su entrambi gli stream connected con la medesima key, lo stesso operatore riceverà anche le subscription (oltre ai tweet) per ogni dato hashtag (o mention) e sarà in grado di elaborare opportunamente anche queste.
Keyed state
Una volta partizionati gli stream in modo opportuno, per implementare il nostro sistema di statistiche sui tweet dobbiamo essere in grado di mantenere uno stato per ogni chiave. Nello specifico:
- ad ogni messaggio sullo stream delle subscriptions dovremo salvare/eliminare l’identificativo del subscriber ed, eventualmente, emettere un messaggio con la statistica corrente per il nuovo subscriber;
- ad ogni messaggio sullo stream degli status dovremo incrementare le statistiche ed emettere un messaggio con specificati i subscriber, le statistiche ed, eventualmente, la key per comodità.
Per ogni key, le statistiche correnti e la lista delle subscriptions rappresentano lo stato del nostro operatore.
Keyed State e Operator State
Esistono due tipi di stati in Flink: il Keyed State e l’Operator State [4]. Entrambi vengono completamente gestiti da Flink e salvati (checkpointed) per eventuale recupero da failure.
L’Operator State è lo stato associato ad ogni istanza parallela di un operatore, mentre il Keyed State è lo stato che Flink mette a disposizione quando si intende mantenere in memoria dati relativi a una partizione (una key), esattamente come nel nostro caso.
Per capire quale sia la differenza tra i due stati, conviene osservare che in Flink non viene istanziato un thread per ogni key, ma piuttosto le istanze parallele degli operatori vengono condivise da molteplici key e ciascuna istanza riceve durante l’esecuzione tutti gli elementi con la medesima key, ma non solo quelli; ogni operatore parallelo, infatti, elabora un sottoinsieme delle key, non una singola key.
Il Keyed State è la API di Flink strutturata in modo da renderci la vita facile e permetterci di organizzare il codice come se effettivamente esistesse una istanza di un operatore per ogni key.
Gestire gli stati
Il codice che dobbiamo scrivere per gestire lo stato si trova nella classe Aggregator.java (disponible nel repository su github [1] con il tag fourth-step) ed estende RichCoFlatMapFunction, una FlatMap come abbiamo già avuto modo di vedere in precedenza, di tipo Co cioè nella variante pronta per lavorare su ConnectedStreams; ma, e questa è la novità, tale FlatMap è anche Rich, cioè capace di accedere al RuntimeContext e di gestire il proprio stato.
Innanzi tutto RichCoFlatMapFunction è una classe astratta dotata di metodi — per esempio open(…) e close(…) — che vengono chiamati prima della effettiva messa in servizio dell’operatore, che sono utili per le operazioni di inizializzazione, tra cui l’inizializzazione dello state.
Come si vede dal frammento di codice seguente, nel metodo open ci occupiamo di inizializzare le variabili di istanza (subscriptionsState e countState), che contengono il riferimento allo stato dell’operatore che poi sarà usato nei metodi che verranno chiamati per ogni elemento dello stream, per accedervi e manipolarlo.
class Aggregator extends RichCoFlatMapFunction<Tuple2<String, Status>,
Tuple3<String, String, String>,Tuple3<String, Set<String>, Statistic>> {
//state variables
private transient ValueState<Set<String>> subscriptionsState;
private transient ValueState<Integer> countState;
@Override
public void open(Configuration parameters) throws Exception {
//setup state
ValueStateDescriptor<Set<String>>
sDescriptor = new ValueStateDescriptor<>(
//state name
"subscriptions",
//state type information
TypeInformation.of(new TypeHint<Set<String>>() {}));
//instance variable to hold the state reference
subscriptionsState = getRuntimeContext().getState(sDescriptor);
ValueStateDescriptor<Integer>
cDescriptor = new ValueStateDescriptor<>(
"count",
// the state name
Integer.class);
// type
countState = getRuntimeContext().getState(cDescriptor);
}
…
}
Ecco l’istruzione con la quale si crea il descrittore dello stato:
ValueStateDescriptor<Set<String>>
sDescriptor = new ValueStateDescriptor<>(
//state name
"subscriptions",
//state type information
TypeInformation.of(new TypeHint<Set<String>>() {}));
Essa può risultare complessa a una prima lettura, ma diventa relativamente semplice quando è scomposta nelle sue parti.
Variabile di stato
Per definire una variabile di stato, abbiamo bisogno di informare Flink del tipo della variabile; nel nostro caso, per ogni chiave vogliamo mantenere un singolo valore e quindi usiamo ValueState, ma esistono stati di tipo Map, List, etc. per casi più complessi del nostro [5].
Deciso che la nostra variabile sarà un singolo valore, dobbiamo specificarne l’effettivo tipo Java. Per l’insieme delle subscriptions noi utilizzeremo un java.util.Set e quindi il type parameter di ValueState è appunto un Set.
Allo stato dobbiamo assegnare un nome che potrà eventualmente risultare utile per usi più sofisticati (per esempio, Queryable State [6]), e per logging. Infine dobbiamo specificarne nuovamente il tipo per permettere a Flink di serializzarlo, ad esempio per poterlo spostare tra nodi diversi del cluster e per salvarlo su disco durante le operazioni di chackpointing.
A causa della type erasure e dei tecnicismi che accompagnano sempre la serializzazione, per specificare il tipo per oggetti complessi come il Set, è necessario usare le classi helper TypeInformation e TypeHint. In casi più semplici, è sufficiente passare al costruttore di ValueStateDescriptor la classe stessa, come si vede nella riga di codice qui sotto, in cui il descrittore per il contatore è parametrizzato con Integer:
cDescriptor = new ValueStateDescriptor<>("count", Integer.class);
Tutto qui! Creato il descrittore, non resta che registrarlo nel runtimecontext e mantenerne un riferimento pronto all’uso:
subscriptionsState = getRuntimeContext().getState(sDescriptor);
e
countState = getRuntimeContext().getState(cDescriptor);
Una volta “inizializzato” (chiamando il metodo open), l’operatore viene messo in servizio da Flink e, grazie al fatto che lo stream è keyed, tutti i messaggi con la medesima key verranno processati dalla medesima istanza.
RichCoFlatMapFunction
La struttura di calcolo della nostra RichCoFlatMapFunction non è dissimile da quella della CoMapFunction vista alla fine del precedente articolo: avremo due metodi flatMap1 e flatMap2 che verranno chiamati per ogni messaggio che passerà attraverso uno dei due stream connected, le subscriptions e gli status.
flatMap2: subscriptions
Con lo stato già suddiviso per key e la certezza di ricevere solo i messaggi di tipo subscription, implementare la logica delle iscrizioni è quantomai semplice.
public void flatMap2(Tuple3<String, String, String> value,
Collector<Tuple3<String, Set<String>, Statistic>> collector)
throws Exception {
String subscriber = value.f2;
//get the state variable
Set<String> currentSubscriptions = subscriptionsState.value();
//handle the null (unitialized) case
if(currentSubscriptions == null)
currentSubscriptions = new HashSet<String>();
if (subscriber != null) {
if ("-".equals(value.f1)) {
//cancel subscription
//remove eventual subscription
currentSubscriptions.remove(subscriber);
} else {
//register subscription
if (currentSubscriptions.add(subscriber)) {
Integer count = countState.value();
count = count == null ? 0 : count;
//eventually send ‘welcome’ to new subscriber
collector.collect(new Tuple3<>(value.f0,
Collections.singleton(subscriber),
new Statistic(count)));
}
}
subscriptionsState.update(currentSubscriptions);
}
}
Sostanzialmente, tolti i null check, le azioni svolte sono le seguenti:
- prendiamo lo stato;
- lo aggiorniamo;
- in caso di una nuova subscription, emettiamo un messaggio con la statistica iniziale;
- salviamo lo stato modificato.
Dopo ogni messaggio di iscrizione, lo stato dell’operatore conterrà la lista aggiornata di subscriber ed alla fine verrà emesso un messaggio con una statistica corrente.
flatMap1: tweets
Analogamente, per ogni Status non c’è altro da fare che:
- prendere lo stato (il contatore);
- aggiornarlo e salvarlo nuovamente;
- prendere la lista delle subscriptions;
- emettere un messaggio con la statistica aggiornata, questa volta con destinatari tutti i subscriber.
public void flatMap1(Tuple2<String, Status> value,
Collector<Tuple3<String, Set<String>, Statistic>> collector)
throws Exception {
//increment (or initialize) the number of seen tweets with the given key
Integer count = countState.value();
count = (count == null) ? 1 : (count + 1);
countState.update(count);
Set<String> currentSubscriptions = subscriptionsState.value();
//emit stat if there are subscriptions
if (currentSubscriptions != null && currentSubscriptions.size() > 0)
collector.collect(new Tuple3<>(value.f0, currentSubscriptions,
new Statistic(count)));
}
Analisi completata
Una volta eseguita, la nostra mappa genererà un elenco di statistiche in cui sono specificati sia la chiave (SearchCriteria) a cui la statistica si riferisce, che il Set dei subscriber a cui un eventuale altro operatore downstream si occuperà di “inviare” la notifica.
Eseguendo il codice, in questa versione otteniamo dunque nella console un output simile a quello seguente. Ovviamente va fatto notare ai lettori che stiamo elaborando un sottoinsieme dei tweet pubblicati in tempo reale. Pertanto è assai improbabile ottenere il medesimo risultato eseguendo il codice in momenti diversi. Probabilmente per avere qualche messaggio in output, sarà necessario cambiare i search criteria scegliendone alcuni tra i trendind topics nel momento in cui si effettua l’esecuzione del codice.
2> (#IDOLCHALLENGE,[Francesca],Statistic{count=0})
8> (#HR,[Alberto],Statistic{count=0})
3> (#IDOLChallenge,[Francesca],Statistic{count=0})
5> (#IDOL,[Francesca],Statistic{count=0})
5> (#IDOL,[Alberto],Statistic{count=0})
2> (#IDOLCHALLENGE,[Francesca],Statistic{count=1})
2> (#IDOLCHALLENGE,[Francesca],Statistic{count=2})
5> (#IDOL,[Francesca, Alberto],Statistic{count=1})
2> (#IDOLCHALLENGE,[Francesca],Statistic{count=3})
5> (#IDOL,[Francesca, Alberto],Statistic{count=2})
2> (#IDOLCHALLENGE,[Francesca],Statistic{count=4})
5> (#IDOL,[Francesca, Alberto],Statistic{count=3})
2> (#IDOLCHALLENGE,[Francesca],Statistic{count=5})
5> (#IDOL,[Francesca, Alberto],Statistic{count=4})
5> (#IDOL,[Francesca, Alberto],Statistic{count=5})
2> (#IDOLCHALLENGE,[Francesca],Statistic{count=6})
5> (#IDOL,[Francesca, Alberto],Statistic{count=6})
2> (#IDOLCHALLENGE,[Francesca],Statistic{count=7})
5> (#IDOL,[Francesca, Alberto],Statistic{count=7})
Come si vede, gli Status con hashtag IDOL e IDOLCHALLENGE vengono elaborati ed emessi in messaggi che riportano, oltre alla desiderata statistica, anche la lista dei subscriber.
Sink
Dopo la generazione delle statistiche con annessa la lista delle iscrizioni, è chiaro come potremmo procedere a smistare nuovamente i messaggi. Ad esempio, si potrebbe smistarne uno per ogni subscriber per poi eventualmente partizionarli nuovamente, questa volta usando magari come key l’identificativo del subscriber, per poi processarli in parallelo.
Essendo però queste trasformazioni lunghe da descrivere e tutto sommato prive di interessanti concetti, vogliamo utilizzare questa ultima parte dell’articolo per concentrarci nell’unica operazione di cui non abbiamo ancora parlato: la scrittura di uno stream in un database (HBase nel nostro caso).
Sink e HBase
In Apache Flink, la destinazione finale di uno stream è chiamata Sink e per costruirla è necessario implementare una SinkFunction o estendere una RichSinkFunction. A tale scopo, la distribuzione di Flink contiene già molti connettori pronti all’uso: Cassandra, ElasticSearch, Kafka (sink), filesystem, NiFi e altri.
La brutta notizia è che non c’è un connettore per HBase: proprio per questo lo abbiamo scelto, per mostrare come, anche in mancanza di un connector dedicato, sia facile aggiungere una sink a Flink, perlomeno in un caso semplice come quello presentato.
Basta infatti usare il metodo writeUsingOutputFormat di DataStream — il quale, a sua volta, usa internamente una SinkFunction preconfezionata che nasconde al programmatore tutte le complicazioni — e implementare l’interfaccia OutputFormat, che ci mette a disposizione gli hook per preparare la connessione a HBase (in open), popolare la tabella via via che i dati arrivano (writeRecord) e chiudere la connessione (in close).
Chiaro e semplice come una toy application; ma pronta, grazie a Flink, per essere eseguita multithread, eventualmente distribuita su molteplici nodi di un cluster.
public class HBaseOutputFormat
implements OutputFormat<Tuple3<String, Set<String>, Statistic>> {
private static final long serialVersionUID = 1L;
private transient Connection connection = null;
private byte[] tableName;
public HBaseOutputFormat(String tableName) {
this.tableName = Bytes.toBytes(tableName);
}
@Override
public void configure(Configuration parameters) {
}
@Override
public void open(int taskNumber, int numTasks) throws IOException {
connection = ConnectionFactory.createConnection();
}
@Override
public void writeRecord(Tuple3<String, Set<String>, Statistic> record)
throws IOException {
try(Table table = connection.getTable(TableName.valueOf(tableName))) {
for (String s : record.f1) {
Put put = new Put(Bytes.toBytes( s + record.f0 ));
//a row for each subscriber/key
put.addColumn(Bytes.toBytes("stats"),
Bytes.toBytes(record.f0),
Bytes.toBytes( record.f2.toString() ));
table.put(put);
}
}
}
@Override
public void close() throws IOException {
connection.close();
}
}
In tutto una ventina di righe di codice nonostante il consueto amore per il boilerplate di Java…
Il codice completo è disponibile sul già citato repository [1] con il tag “last-step”.
Questa ultima versione usa sia la coda Kafka che HBase ed è quindi necessario installarle entrambe e configurarle prima di poter eseguire il codice.
Deployment
Per i volenterosi che non sono ancora stanchi di Flink, scritto il codice e verificatone il funzionamento usando Maven e lo IDE, è adesso il momento di eseguirlo su un cluster (eventualmente formato da solo localhost).
Ecco i passi da seguire:
- scaricate l’ultima versione di Flink [7], configuratelo e fatelo partire sui vostri nodi;
- avviate Kafka e HBase;
- compilate l’applicazione (mvn install) e poi andate con un browser alla porta 8081 del server su cui avrete lanciato il TaskManager (http://localhost:8081);
- potrete fare l’upload del JAR dell’applicazione direttamente dall’interfaccia web, per poi eseguirlo.
Sulla web console di Flink, la struttura della nostra applicazione comparirà come nell’immagine di figura 1.
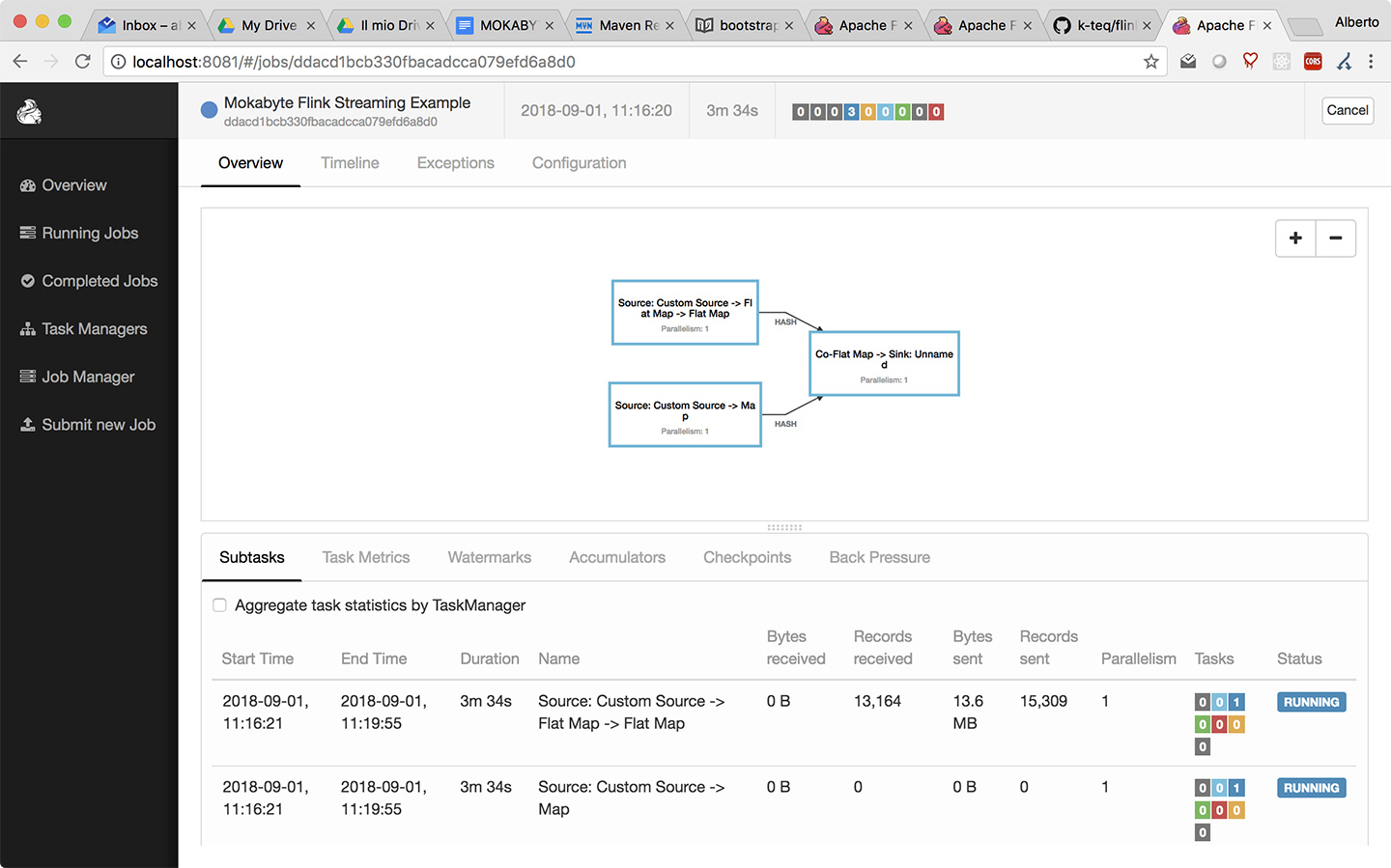
Lo schema riportato al centro è l’execution plan, sostanzialmente la struttura dell’applicazione come vista da Flink. Lo schema è in verità più semplice di come ce lo saremmo aspettato visto il numero di operatori che abbiamo implementato.
Il Plan è semplice in quanto una delle (molte) funzionalità di cui non abbiamo avuto modo di parlare è quella chiamata OperatorChaining, che consiste nella capacità di Flink di ottimizzare le catene di operatori “aggregandoli” in gruppi che possono essere eseguiti più efficientemente, riducendo quanto più possibile le comunicazioni tra thread e nodi; gli operatori “concatenati” non richiedono infatti lo spostamento di dati, in quanto sono eseguiti sul medesimo thread.
Conclusioni
Speriamo che questa introduzione a Flink e alla sua API abbia suscitato l’interesse dei lettori. Ci sarebbe ancora molto da dire su Flink: come funzionano i checkpoint, come si salva lo stato, come si gestisce il parallelismo, come si aggregano i dati temporalmente… Ma certamente il modo migliore per scoprire questi aspetti è la documentazione in rete e tanto “trial and error”.
Il sito ufficiale di Flink [8] e le mailing list dedicate [9] [10] possono comunque rappresentare dei validi punti di riferimento per risolvere dubbi e consentire approfondimenti sulle diverse funzionalità.
Buon Stream Processing!
Freelance, Web & Mobile Developer and Architect, with a passion for fine tuned details.
Co-founder at K-TEQ Srls (http://www.k-teq.com).
GDG-Firenze Lead and founder. Intel Software Innovator.
#Java #GWT #StreamProcessing #MachineLearning
https://www.linkedin.com/in/francescatosij/
Sviluppatore web e mobile, freelance, teacher, sysadmin.
Attualmente lavoro come Java Developer e Architect per l'azienda di cui sono co-fondatore: K-TEQ Srls (http://www.k-teq.com)
#Java #GWT #JavaScript #HTML5 #Flink #MachineLearning
https://www.linkedin.com/in/abmancini/