

Cominciamo a scrivere un’applicazione demo
Nell’articolo precedente abbiamo discusso già lo schema dell’applicazione che vogliamo realizzare (figura 1): si tratta di un immaginario sistema per calcolare statistiche sui tweets.
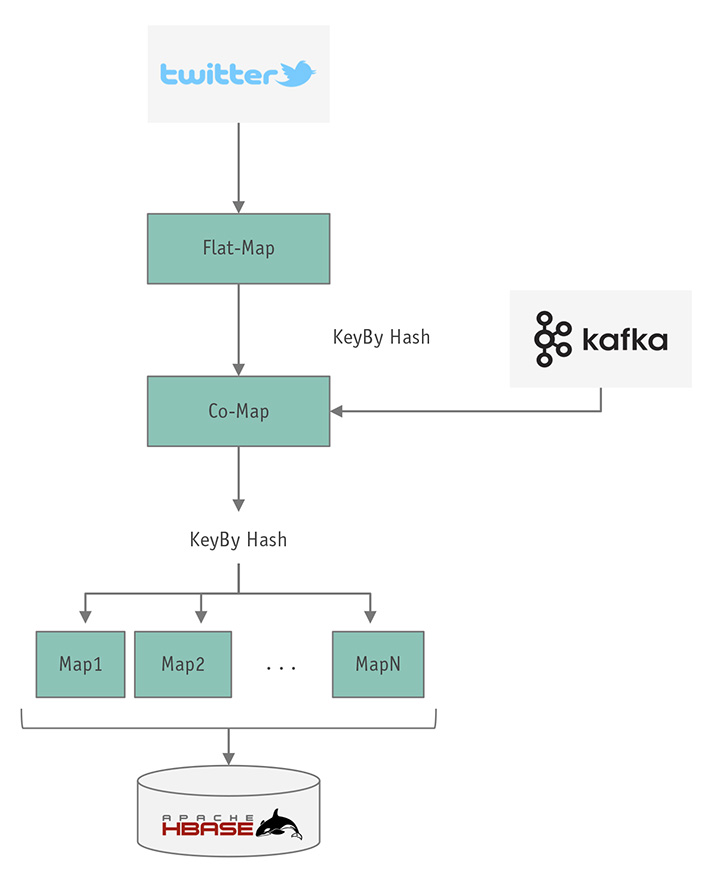
Prepariamo l’ambiente
Dopo essersi assicurati di avere a disposizione Maven 3.0.4 (o superiore) e Java 8.x, possiamo generare un progetto di prova dall’archetipo messo a disposizione dal tema di Flink. Per questo usiamo il comando:
mvn archetype:generate \ -DarchetypeGroupId=org.apache.flink \ -DarchetypeArtifactId=flink-quickstart-java \ -DarchetypeVersion=1.5.0
Come sempre con gli archetipi, avremo da rispondere solo a un paio di semplici domande ed il progetto è pronto.
Scegliendo la versione 1.5.0 dell’archetipo abbiamo Implicitamente scelto anche la versione di Flink che useremo nell’esempio. La 1.5.0 è l’ultima “stable” attualmente disponibile (rilasciata a maggio 2018). Qualora questa versione non risultasse abbastanza recente per i vostri esperimenti, al momento è disponibile anche la preview della 1.6: il corrispondente archetipo è quello con la versione 1.6-SNAPSHOT.
Una volta importato il progetto nel vostro IDE preferito — noi per questo esempio abbiamo utilizzato IntelliJ IDEA, ma un qualsiasi IDE con supporto maven dovrebbe andare bene — non è difficile trovare la classe StreamingJob che sarà il punto di partenza della nostra esplorazione.
NOTA: nel progetto generato dall’archetipo c’è anche una classe chiamata BatchJob della quale non ci sarà occasione di parlare; si osservi comunque che quella classe è la base di partenza per progetti che operano su dati bounded, seguendo il paradigma batch processing invece che quello stream processing di cui vogliamo occuparci noi.
Metodo main
Come si vede dal codice di StreamingJob, una applicazione Flink si compone almeno di un (rassicurante) metodo main. Per la verità, lo scopo del metodo main nella nostra streaming application è però abbastanza peculiare da valere una descrizione.
main viene effettivamente eseguita come ci si aspetta, ma le operazioni sugli stream vere e proprie (e la conseguente esecuzione multithread/parallela) avviene tramite l’interazione con l’oggetto chiamato StreamExecutionEnvironment che deve essere configurato e poi eseguito chiamandone il metodo execute.
Struttura generale di un’applicazione Flink
La struttura generale di una applicazione Flink sarà dunque sempre molto simile alla seguente:
...
public static void main(String[] args) throws Exception {
//PRENDIAMO UN executionEnvironment.
StreamExecutionEnvironment
env = StreamExecutionEnvironment.getExecutionEnvironment();
//CREAZIONE DELLA STRUTTURA DELL’APPLICAZIONE E CONFIGURAZIONE
//ESECUZIONE
env.execute("Flink Streaming Java API Skeleton");
}
Esecuzione ed eccezione
Provare ad eseguire il nostro main a questo punto è purtroppo poco interessante. Si ottiene infatti solamente la seguente eccezione:
Exception in thread "main" java.lang.IllegalStateException: No operators defined in streaming topology. Cannot execute.
Non molto avvincente, ma l’errore ci indica la direzione da seguire. Effettivamente la nostra applicazione al momento non ha nessun operatore, e neanche una sorgente o una destinazione: è tutto sommato ragionevole che Flink non trovi nulla da eseguire.
Importare i dati
Logicamente la nostra prima preoccupazione deve essere quella di aggiungere il codice necessario per “importare” nell’applicazione lo stream di dati che vogliamo elaborare, creare cioè, in terminologia Flink, una SourceFunction.
Flink ha un numero considerevole di sorgenti a disposizione ed è relativamente semplice anche crearne delle nuove, anche se rendere le nostre eventuali implementazioni efficienti e capaci di garantire “exactly once semantics”, è operazione che richiede una certa comprensione della piattaforma. Ad ogni modo, perderci nella vastità dei connettori a disposizione non è il nostro obiettivo; piuttosto il nostro target è quello di leggere in tempo reale ed elaborare tweets.
Leggere i tweet
Come si vede consultando la lista ufficiale dei connectors forniti insieme ad Apache Flink [1], direttamente nella distibuzione esiste org.apache.flink.streaming.connectors.twitter.TwitterSource:
The Twitter Streaming API provides access to the stream of tweets made available by Twitter
Bene, questo sembra fare proprio al caso nostro.
Per utilizzare questa sorgente, è necessario aggiungere la dipendenza al nostro pom.xml:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-twitter_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
Successivamente, si aggiunge nel nostro main quanto segue:
Properties properties = new Properties(); properties.setProperty(TwitterSource.CONSUMER_KEY, ""); properties.setProperty(TwitterSource.CONSUMER_SECRET, ""); properties.setProperty(TwitterSource.TOKEN, ""); properties.setProperty(TwitterSource.TOKEN_SECRET, ""); TwitterSource twitterSource = new TwitterSource(properties); DataStream<String> tweetsAsStrings = env.addSource(twitterSource); tweetsAsStrings.print();
Autenticazione
Per quanto l’accesso al firehose di Twitter sia gratuito, almeno per quello che serve a noi in questo esempio, esso è comunque soggetto ad autenticazione; quindi per eseguire il codice che stiamo scrivendo è necessario registrare la propria applicazione e ottenere le credenziali di autenticazione. La cosa non è troppo complicata ed è descritta sulla guida dello sviluppatore di Twitter [2].
Sconsigliamo di scaricarla a questo punto della lettura, ma l’applicazione che stiamo scrivendo è anche disponibile su github [3].
Per comodità d’uso, nella versione su github le credenziali invece che essere specificate in linea nel codice sono in un opportuno file di configurazione chiamato app.properties.
Come funziona il processo di lettura
Il primo blocco di codice prepara le configurazioni e crea una istanza di una SourceFunction specifica per leggere tweets, mentre le ultime due righe mostrano come in generale vadano trattate le sorgenti in Flink.
Una volta ottenuta un’ istanza di una sorgente la “aggiungiamo” all’environment che ci restituisce un oggetto di tipo DataStream<T> parametrizzato con il tipo “prodotto” dalla sorgente (String nel caso di string).
Il DataStream è l’oggetto su cui potremo applicare le trasformazioni; sostanzialmente da questo punto in poi l’intera applicazione verrà scritta sotto forma di trasformazioni applicate al DataStream. Le trasformazioni saranno applicate a ciascun elemento prodotto dalla sorgente a partire dal momento in cui chiameremo il metodo execute dell’environment.
La prima trasformazione interessante è print() che, con poca sorpresa, avrà l’effetto di stampare su standard-out tutti gli elementi prodotti dalla sorgente. Eseguendo il main, ad esempio direttamente dal vostro IDE, si dovrebbe ottenere sulla console un output simile a quello seguente.
Prima di eseguirlo ricordate che lo stream dei tweet è unbounded, quindi l’applicazione non è destinata a terminare (a meno di errore) quindi dopo pochi secondi di esecuzione dovrete terminarla voi.
2> {"delete":{"status":{"id":961573338219982848,"id_str":"96...
1> {"delete":{"status":{"id":948653057386205190,"id_str":"94...
3> {"delete":{"status":{"id":764217615451553793,"id_str":"76...
8> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
7> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
4> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
1> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
3> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
6> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
1> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
4> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
2> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
5> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
8> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
6> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
7> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
5> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
2> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
5> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
2> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
4> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
7> {"created_at":"Fri Jun 29 21:24:54 +0000 2018","id":10128...
Quella scritta sulla console altro non è che la lista dei tweet recuperati dalla sorgente; è preceduta, per chi se lo chiedesse, dal numero del thread che ha effettuato la stampa.
Nel nostro caso possiamo anche osservare che la nostra applicazione è eseguita con 8 threads completamente indipendenti. Qualora si volesse cambiare o conoscere il parallelismo di esecuzione (che essendo su un unico nodo di calcolo corrisponde al numero di thread) si potrebbero usare i metodi setParallelism(int n) e getParallelism() di environment.
Elaborazioni successive
Nel resto dell’applicazione saremo interessati a processare i tweet; di sicuro la prima trasformazione di cui abbiamo bisogno è quella che, date le stringhe recuperate dalla sorgente, crea degli oggetti sui quali potremo basare le nostre successive elaborazioni.
Va osservato che, anche solo dall’output precedente, possiamo concludere che insieme ai tweet (quelli che iniziano con “created_at”), la sorgente — per la verità l’endpoint messo a disposizione da Twitter — restituisce anche altri messaggi che non sono considerabili propriamente tweet: nell’esempio, le prime 3 righe sono probabilmente la conseguenza della cancellazione di un tweet da parte di un utente, messaggio che non ci interessa.
La nostra prossima trasformazione dovrà quindi assolvere a due compiti: eliminare le stringhe che non rappresentano un tweet e trasformare le altre in un oggetto. Per scegliere quale operatore dovremo utilizzare basta una rapida occhiata alla documentazione sugli operatori[4], e la nostra scelta non può che cadere su flatMap, la trasformazione che dato uno stream di elementi e (le stringhe in input) produce per ciascun e uno stream composto da n elementi (non necessariamente del medesimo tipo degli elementi in input).
Essendo n >= 0 è chiaro come flatMap sia sufficientemente flessibile per il nostro compito.
La nuova linea di codice da aggiungere sarà quindi della forma:
DataStream<Status> tweets = tweetsAsStrings.flatMap(new TweetsParser());;
In buona sostanza, una trasformazione che dato uno stream di stringhe ne genera uno di Status, l’oggetto che contiene la struttura di un tweet. Status per la verità non è un oggetto nostro ma abbiamo scelto di usare la libreria twitter4j per il parsing dei tweet.
twitter4j richiede la dipendenza:
<dependency> <groupId>org.twitter4j</groupId> <artifactId>twitter4j-core</artifactId> <version>4.0.4</version> </dependency>
Come ci segnala il compilatore, se proviamo a compilare il codice, per poter essere usata come argomento alla funzione flatMap di DataStream, la classe TweetsParser deve implementare:
org.apache.flink.api.common.functions.FlatMapFunction<String, Status>
e di conseguenza il metodo flatMap:
public void flatMap(String s, Collector<Status> collector) {
try {
Status status = TwitterObjectFactory.createStatus(s);
collector.collect(status);
} catch (TwitterException e) {
//we assume that the only case here is a
//message we do not want to process.
//it is a test afterall
}
}
Con queste ultime modifiche l’applicazione è in grado di trasformare le stringhe, restituite dalla Twitter source, in oggetti di tipo twitter4j.Status e filtrare via tutte le stringhe che non corrispondono effettivamente a un Tweet.
Se, per esempio, a questo punto chiamassimo il metodo print del DataStream tweets, otterremmo qualcosa di simile alla lista di stringhe precedente, ma con omesse tutte le stringhe “spurie” (il codice a questo punto dello sviluppo è quello che trovate sul repository [3] con il tag “first-step”).
Classificazione dei tweet
Come segue dalla descrizione dell’applicazione che abbiamo fatto nei paragrafi precedenti il nostro obiettivo è di creare statistiche dei thread per #hashtag o @mention, in pratica “classificare” i tweet.
Per fare questo vogliamo procedere ad avere uno stream in cui ogni tweet sia ripetuto per ciascuno dei suoi hashtag e/o mention.
Tweet{text: “... #hashtagA … #hashtagB … @mention1 …” }
->
{“#hashtagA”, Tweet{text: “... #hashtagA … #hashtagB … @mention1 …”}
{“#hashtagB”, Tweet{text: “... #hashtagA … #hashtagB … @mention1 …”}
{“@mention1””,Tweet{text: “... #hashtagA … #hashtagB … @mention1 …”}
Forse questo approccio non è il più efficiente che si possa immaginare, richiedendo la duplicazione dei tweet, ma è d’altro canto estremamente semplice da descrivere e implementare con gli stream, da risultare preferibile, in questo contesto, a soluzioni più sofisticate ma meno dirette.
Ancora flatMap…
Il lettore attento avrà a questo punto intuito che, per implementare questa nuova trasformazione, abbiamo bisogno nuovamente di una flatMap: per ogni tweeter4j.Status in input può essere generato un numero arbitrario di coppie {“hashtag”, Status}.
L’implementazione è, ancora una volta, molto semplice:
class TweetsPerSearchCriteria implements FlatMapFunction<Status, Tuple2<String, Status>> {
@Override
public void
flatMap(Status status, Collector<Tuple2<String, Status>> collector) throws Exception {
if (status != null) {
Arrays.stream(status.getHashtagEntities()).forEach(
hte -> collector.collect(new Tuple2<>("#" + hte.getText(), status))
);
Arrays.stream(status.getUserMentionEntities()).forEach(
ume -> collector.collect(new Tuple2<>("@" + ume.getText(), status))
);
}
}
}
Concatenare quest’ultima trasformazione alla nostra pipeline richiede ancora una volta una singola riga di codice:
DataStream<Tuple2<String, Status>>
classifiedTweets = tweets.flatMap(new TweetsPerSearchCriteria());
classifiedTweets è adesso lo stream delle coppie sopra descritte. Questa versione dell’applicazione è disponibile su github [3] con il tag “second-step”.
Connettere due stream
Di trasformazione in trasformazione, adesso abbiamo a disposizione uno stream in cui ogni tweet è associato a uno (ed un solo) search–criteria, che poi sarebbe una mention (@username) oppure un hashtag (#hashtag).
Il passo successivo per l‘applicazione sta nell’aggiungere un nuovo stream — proveniente eventualmente da una coda Apache Kafka contenente le configurazioni —, i search-criteria a cui siamo interessati e i nomi degli “utenti” che sono interessati al criterio di ricerca.
Possiamo immaginare che le configurazioni arrivino sotto forma di stringhe del tipo:
“SearchCriteria,+/-,Username”
con la convenzione che la stringa contenente ‘+’ deve essere interpretata come il fatto che l’utente “Username” è interessato a statistiche circa quel search criteria. Tali statistiche restano da precisare, e per il momento immaginiamo si tratti di un rate, tipo numero di tweet per secondo).
Un ulteriore passo: Kafka
Aggiungere Kafka all’esempio è tutto sommato semplice: esiste una specifica SourceFunction che è possibile utilizzare semplicemente con una singola riga di codice simile a quella seguente:
FlinkKafkaConsumer011<String> kafkaConsumer
= new FlinkKafkaConsumer011<>("topic", new SimpleStringSchema(),
parameters.getProperties());
Usare quindi una coda Kafka è semplice, ma farlo durante lo sviluppo è laborioso in quanto richiede di configurare, popolare con i dati e mantenere attiva durante lo sviluppo una Kafka. Fortunatamente, esiste con Flink un modo più semplice: usiamo una lista “statica” di subscription e aggiungiamo a posteriori la coda vera.
Seguendo questa strategia, l’ingestion delle configurazioni si conclude in poche linee di codice come quelle seguenti:
List<String> subscriptions =
Arrays.asList("Alberto,+,#HR", "Francesca,+,#Job", "Alberto,+,@DemGovs");
// ”Alberto” è interessato ai tweet che citano
// “#HR” e “@DemGovs” mentre “Francesca” è interessata al
// solo hashtag “@DemGovs”
DataStream<String>configurationsAsStrings =
env.fromCollection(subscriptions);
//Crea un DataStream dalla collecction
DataStream<Tuple3<String, String, String>>
configurations = configurationsAsStrings.map(
new SubsriptionsParser());
//Processa le stringhe trasformandole in oggetti in cui la chiave
//l’utente e l’azione (aggiungi/rimuovi) sono facilmente usabili.
flatMap SubscriptionParser
La struttura della flatMap SubsriptionsParser è molto semplice, ma la riportiamo di seguito per chiarire il ruolo dei 3 campi della tupla che parametrizza lo stream configurations:
class SubsriptionsParser
implements MapFunction<String,
Tuple3<String, String, String>> {
@Override
public
Tuple3<String, String, String> map(String s) throws Exception {
String[] parts = s.split(",");
return new Tuple3<>(parts[2], parts[1], parts[0]);
//key, add/remove, user
}
}
Avendo a questo punto a disposizione due stream (classifiedTweets e configurations), la nostra preoccupazione è trovare un modo per far sapere a Flink che intendiamo processare questi due canali di dati “insieme”, in modo tale che i messaggi che arrivano su configurations possano regolare come l’altro stream viene processato.
Connected streams
Il modo giusto per effettuare questa connessione tra i due stream è quella di utilizzare l’operatore di Flink appositamente fornito per accoppiare due stream: connect.
ConnectedStreams<Tuple2<String, Status>, Tuple3<String, String, String>> tweetsAndConfigurations = classifiedTweets.connect(configurations);
L’oggetto creato dall’operazione di pairing dei due stream è di un tipo non visto fino ad ora e si chiama ConnectedStreams<A,B>. Si tratta di uno stream in cui passeranno messaggi sia di tipo A che di tipo B. Gli operatori che potranno essere usati per trasformare questo stream dovranno quindi avere cura di processare nel modo opportuno i messaggi di tipo diverso.
Elaborare gli stream di tipologia connected è meno complesso di quanto possa sembrare dalla descrizione. Se, ad esempio, volessimo applicare una mappa al connected stream al fine di stamparne il contenuto, potremmo farlo con una CoMapFunction come quella descritta di seguito:
//processa i due stream accoppiati e stampa un
//messaggio identificativo in entrambe le map.
tweetsAndConfigurations.map(
new CoMapFunction<
Tuple2<String,Status>,
Tuple3<String,String,String>, String>() {
@Override
public String
map1(Tuple2<String, Status> value) throws Exception {
return "Map1, processing Tweet id: " + value.f1.getId() +
", relative to searchCriteria: " + value.f0;
}
@Override
public String
map2(Tuple3<String, String, String> value) throws Exception {
return "Map2, processing subscription od " + value.f2 +
", relative to searchCriteria: " + value.f0;
}
}).print();
L’operatore di tipo CoMap sostanzialmente può essere pensato come una coppia di map-operatore, la prima verrà invocata da Flink per ogni messaggio sul primo stream, la seconda per ogni messaggio nel secondo stream “connected”.
L’applicazione con la mappa di pretty-printing mostrata sopra, è disponibile sul repository [3] con il tag “third-step” e genera un output simile a quello seguente.
2> Map2, processing subscription od Francesca, relative to searchCriteria: #Job 3> Map2, processing subscription od Alberto, relative to searchCriteria: @DemGovs 1> Map2, processing subscription od Alberto, relative to searchCriteria: #HR 4> Map1, processing Tweet id: 1013546502608867328, relative to searchCriteria: @Basti_msg 1> Map1, processing Tweet id: 1013546502600392706, relative to searchCriteria: @ACLU 6> Map1, processing Tweet id: 1013546502621409286, relative to searchCriteria: @RealPrittStift 2> Map1, processing Tweet id: 1013546502625677312, relative to searchCriteria: #CSU 6> Map1, processing Tweet id: 1013546502592090112, relative to searchCriteria: @mckrodney 5> Map1, processing Tweet id: 1013546502625558529, relative to searchCriteria: @qualvocescolhe 7> Map1, processing Tweet id: 1013546502591877120, relative to searchCriteria: @aluciagarcia 2> Map1, processing Tweet id: 1013546502625677312, relative to searchCriteria: @humanproduct 8> Map1, processing Tweet id: 1013546502604587009, relative to searchCriteria: @pamdoraboxx 5> Map1, processing Tweet id: 1013546502596321280, relative to searchCriteria: #ローソン
L’output ci conferma che entrambi gli stream vengono processati nel nostro operatore; resta adesso da capire come gestire lo stato interno al nostro operatore in modo tale che, senza alcuna memoria condivisa tra i diversi thread, l’applicazione sia comunque in grado di operare correttamente sulle subscriptions. I thread nell’esecuzione in un cluster, infatti, potrebbero venire eseguiti su nodi fisicamente diversi ed è quindi importante che non ci sia memoria condivisa tra i thread.
Conclusioni
Trovare il modo di gestire lo stato dei threads ci porterà ad affrontare due concetti ancora non trattati: per prima, la possibilità di associare ai dati in uno stream delle chiavi di partizionamento che permettono a Flink di distribuire efficientemente le operazioni su molteplici thread/nodi; in secondo luogo, il keyed-operator-state che rappresenta invece il modo di Flink per associare ad ogni chiave di partizionamento uno stato persistente in ciascun operatore.
Ma per questa volta ci fermiamo qui: queste parti saranno affrontate nel prossimo articolo della serie, insieme alla seconda parte del codice d’esempio.
Freelance, Web & Mobile Developer and Architect, with a passion for fine tuned details.
Co-founder at K-TEQ Srls (http://www.k-teq.com).
GDG-Firenze Lead and founder. Intel Software Innovator.
#Java #GWT #StreamProcessing #MachineLearning
https://www.linkedin.com/in/francescatosij/
Sviluppatore web e mobile, freelance, teacher, sysadmin.
Attualmente lavoro come Java Developer e Architect per l'azienda di cui sono co-fondatore: K-TEQ Srls (http://www.k-teq.com)
#Java #GWT #JavaScript #HTML5 #Flink #MachineLearning
https://www.linkedin.com/in/abmancini/