

Introduzione
In questa serie di articoli parliamo di come utilizzare dati e metriche per rispondere a domande di business come “Quanto tempo ci vorrà? Cosa possiamo consegnare per la prossima scadenza? Questa feature sarà pronta in tempo? … “.
Nella prima parte abbiamo visto come i comuni approcci alle stime (per esempio, story point) spesso falliscono nel darci la prevedibilità che cerchiamo. Per ottenere una migliore prevedibilità, conviene abbandonare modelli deterministici (le classiche “stime”, estimates) a favore di modelli probabilistici (“previsioni”, forecasting).
In questo articolo spieghiamo come utilizzare la metrica Lead Time per fare previsioni, con molti esempi pratici di conversazioni che la maggior parte dei team si trova spesso ad affrontare.
Raccolta dati
Parlando di metriche sorge spontanea la domanda: “Quali dati occorrono? Quanti dati mi servono per iniziare?” Ne abbiamo parlato in dettaglio in un articolo [1] di qualche anno fa ma riassumiamo qui nuovamente le risposte a queste domande.
Quali dati e quanti?
Il minimo indispensabile per iniziare è davvero poco, è sufficiente raccogliere la data in cui una storia viene iniziata, e la data in cui la storia è considerata conclusa (secondo la definizione di “conclusa” seguita dal team, DoD). Queste due date sono sufficienti per calcolare il Lead Time, ossia quanti giorni ha impiegato la storia per essere completata, e per sapere in quale Sprint la storia è stata completata per poi calcolare il Throughput, ossia il numero di storie completate in un periodo di tempo.
Tutto quello che faremo vedere in questa serie di articoli si può ricavare dalla raccolta di queste due date. Se poi avete occasione, è utile — ma non indispensabile — raccogliere qualche dato in più:
- Metadati della storia, che aiutano successivamente in fase di analisi delle metriche per interpretare i nostri dati. Per esempio: tipo di lavoro; feature o bug; dimensione stimata; ecc.
- Eventi interessanti che sono accaduti, per aiutarci a capire cosa può aver causato particolari trend. Per esempio: qualcuno si aggiunge al team o lo lascia; periodi con molte assenze; riorganizzazione aziendale.
- Transizioni di stato della storia, ossia le date in cui la storia si muove da uno stato all’altro nel nostro processo. Ci aiuta a sapere quanto tempo è trascorso in ogni stato, per analizzare colli di bottiglia e opportunità di miglioramento
Sono sufficienti tra 5 e 11 campioni per fare previsioni prevedibili:
- Con 5 campioni sappiamo che la mediana sarà compresa tra questi 5, quindi possiamo iniziare a farci un’idea dei nostri tempi e a fare semplici proiezioni [3].
- Con 11 campioni conosciamo il range dei campioni: c’è il 90% di probabilità che ogni altro campione sarà compreso in quel range (“German tank problem [4]). È abbastanza per essere nel range giusto di numeri e per ridurre drasticamente l’incertezza.
Ovviamente ogni campione successivo aiuta a raffinare ulteriormente la nostra precisione, ma per partire bastano pochissimi dati.
Tool digitali per raccolta dati
Per chi utilizza tool digitali, molto probabilmente questi dati vengono raccolti automaticamente ed è sufficiente farne una estrazione. Jira per esempio ha un plugin chiamato Exporter [5] che permette di estrarre le date di ogni transizione delle storie.
Per chi invece utilizza una lavagna fisica, si può fare lo stesso scrivendo le date sul Post-it o cartellino della storia, per poi raccoglierle in uno spreadsheet.

Una volta che abbiamo i dati a nostra disposizione, quando si tratta di analizzarli il mio consiglio è di iniziare con uno spreadsheet, per avere il massimo della flessibilità mentre prendiamo familiarità con le nostre metriche e impariamo come usarle. Per aiutarvi a partire, potete trovare dei fogli elettronici d’esempio al link [10].
Una volta che ci avete preso la mano, allora potete provare qualche tool. Negli ultimi anni sono emersi diversi software con buone funzionalità di metriche e forecasting. Alcuni si integrano con le applicazioni che già usate (Jira, Azure DevOps, Trello etc.) e si limitano ad analizzare i vostri dati, mentre altri sono veri e propri tool di “software lifecycle management”.
Nei riferimenti [6] [7] [8] [9] trovate qualche indicazione, visto che questa è una domanda che ricevo spsso. Ci tengo tuttavia a precisare che non ho alcuna affiliazione con nessuno dei produttori e che la lista non è esaustiva: sono semplicemente dei tool che ho provato e che posso raccomandare.
Metrica: Lead Time Distribution
La prima metrica di cui vogliamo parlare è la Lead Time Distribution. È un tema già affrontato su queste pagine[11], ma ne scriviamo qui un riassunto per poi vedere come questa metrica ci aiuta a fare previsioni e rispondere a numerose domande di business. Per cominciare, chiariamo come prima cosa si intende con Lead Time.
Lead Time: definizione
Il Lead Time di una storia rappresenta quanto tempo la storia ha impiegato per essere completata, da inizio a fine. Per esempio, un Lead Time di 5 giorni significa che la storia ha impiegato 5 giorni da quando è stata iniziata a quando è stata considerata completata.
Per misurare il Lead Time in modo efficace il team deve chiarire dove, nel suo processo, una storia viene considerata iniziata e dove invece viene considerata finita. Kanban raccomanda di utilizzare questi due punti, rispettivamente come inizio e fine:
- Il Commitment Point è il punto nel processo dove una storia passa dall’essere considerata una opzione — per esempio, si trova in un backlog o in un pool di idee — ad essere selezionata come prossima attività. Quando una storia supera il commitment point, il team si sta impegnando per portarla a termine e, se è sufficientemente maturo, comunica una previsione agli stakeholder su quando la storia sarà pronta: “Stiamo iniziando la tua storia, siamo sicuri all’80% che sarà completata entro 10 giorni o meno”. Spesso il commitment point è la prima colonna che ha un WIP Limit.
- La coda infinita è il punto nel processo dove il team non ha più influenza, dove i tempi non sono più dettati da noi. Un esempio potrebbe essere “Waiting for Release”: non possiamo decidere noi quando fare un rilascio ma dobbiamo aspettare un particolare momento, quindi le storie si accumulano in questa colonna fino ad allora. Solitamente le colonne senza WIP Limit sono code infinite: non possiamo limitarle perché non ne abbiamo il controllo.
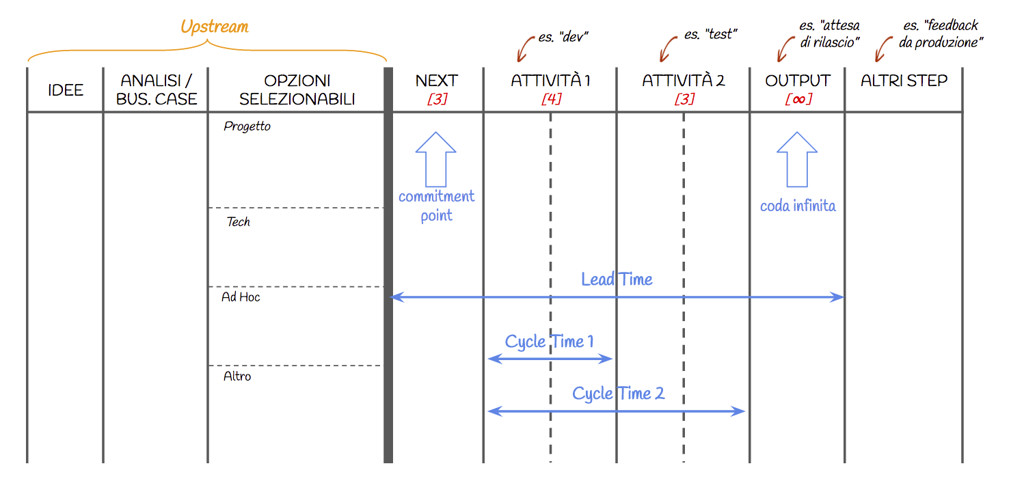
Lead Time Distribution
Per calcolare la Lead Time Distribution contiamo la frequenza di ogni Lead Time nelle storie completate in passato. In pratica, per ogni possibile Lead Time che abbiamo avuto in passato, contiamo quante storie hanno avuto quel Lead Time.
Nell’esempio di figura 3 il conteggio è il seguente:
- 7 storie hanno impiegato tra 0 e 1 giorno;
- 8 storie hanno impiegato tra 1 e 2 giorni;
- 3 storie hanno impiegato tra 2 e 3 giorni;
- e così via.
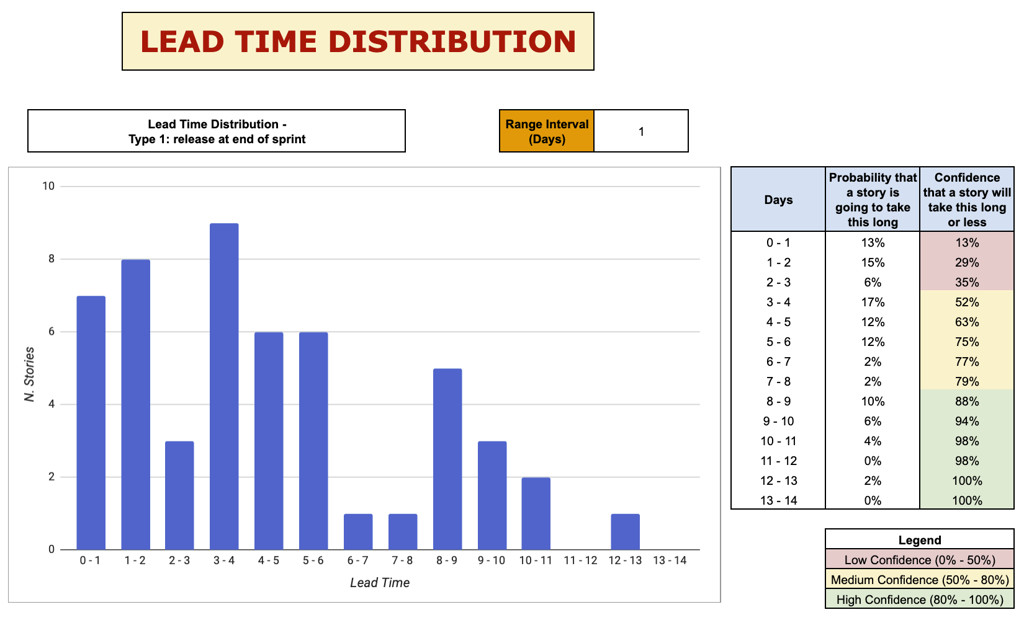
Inoltre, sulla destra mostriamo alcuni dati per rendere facilmente accessibili queste informazioni:
- La probabilità di ogni Lead Time, ossia la probabilità che una storia impieghi esattamente quel tempo. Per esempio: il 13% delle storie impiega 0-1 giorno; il 15% impiega 1-2 giorni, e così via.
- La somma cumulativa delle singole probabilità per trovare la percentuale di storie che impiega quel tempo o meno. Per esempio: il 52% delle storie impiega 4 giorni o meno; l’88% di storie impiega 9 giorni o meno, e così via.
I colori rosso, giallo e verde rappresentano diversi livelli di “sicurezza” che vogliamo avere quando usiamo questi dati per fare previsioni. Vediamo cosa si intende e come utilizzare questi dati in pratica per rispondere alle seguenti domande di business.
“Quanto tempo impiegherà questa storia?”
È una domanda tipica, che i nostri team si sentono chiedere regolarmente. Per rispondere, prendiamo in mano i nostri dati e andiamo a guardare la riga dove ci sentiamo sufficientemente “sicuri” della nostra risposta (cerchiata in rosso nell’immagine).
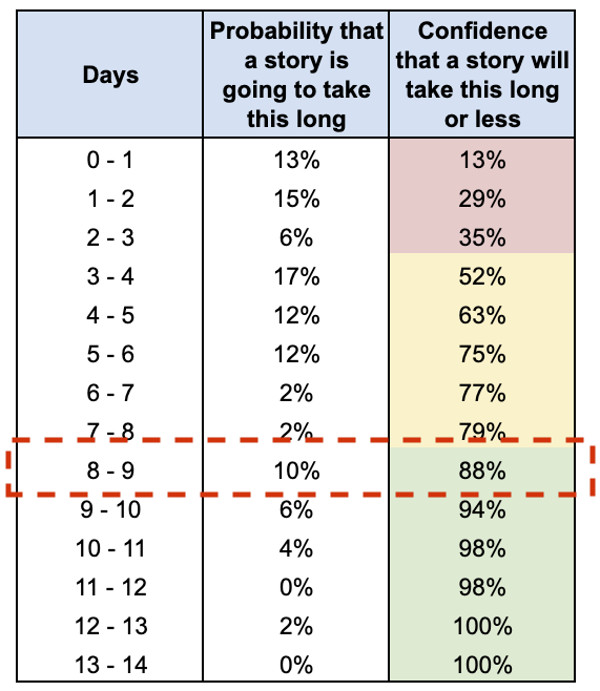
È comune utilizzare 80% come soglia del livello di alta sicurezza. Dati alla mano, la nostra risposta è quanto segue: “Abbiamo più dell’80% di sicurezza che questa storia non impiegherà più di 9 giorni. Potrebbero bastare 4 giorni, ma c’è solo il 50% di probabilità. Nel peggiore dei casi potrebbero volercene 10, ma c’è solo il 10% di probabilità che succeda”.
Conversazioni più precise
Notate come questa conversazione è diversa da una classica discussione di una stima? Normalmente diremmo “Ci vorranno circa x giorni”, mentre ora parliamo apertamente dei possibili scenari che possono avvenire, e del loro impatto. “Se in effetti questa storia finisse per impiegare 10 giorni, quale sarebbe l’impatto per il business? Possiamo permetterci di prenderci il rischio? Cosa possiamo fare per ridurlo? Qual è il valore della storia per giustificare tale rischio?”. La conversazione si è spostata dal parlare di stime al discutere di valore e rischio.

Ci sono purtroppo casi in cui qualcuno dei nostri stakeholder non è aperto a questo tipo di discussioni. Li sentiamo dire cose come “No no, dammi un numero!” e vogliono che promettiamo una data. Quando succede, il primo passo per me è sempre di chiarire quello che sto dicendo, e spiegarne i vantaggi. Se tuttavia lo stakeholder non è disposto ad ascoltarmi, allora solitamente scelgo un livello alto di sicurezza e fornisco quel numero, per esempio: “Ci vorranno 9 giorni”. Attenzione però che, così facendo, perdiamo il vantaggio più importante di questo approccio, che sta nella conversazione. Allo stesso tempo, ci stiamo assumendo tutto il rischio, invece di parlarne onestamente.
“Questa storia sarà pronta in tempo?”
C’è anche la variante “Sarà pronta entro la data x?”. Cerchiamo di rispondere spiegando la probabilità che la storia sia pronta in tempo, e discutendo dell’impatto nel caso ci sbagliassimo.
Ecco un esempio reale, avvenuto nel team da cui ho estrapolato i dati che sto usando come esempio. Il team stava lavorando su un software di telecomunicazioni per analizzare la connessione internet dei clienti. Il software era utilizzato nel call center che forniva supporto ai clienti, per diagnosticare problemi. Per vari motivi tecnici, il software seguiva un ciclo di rilascio mensile.
Quattro giorni prima del rilascio successivo, il manager del call center chiede al team di lavorare su una storia per implementare una nuova feature per diagnosticare un nuovo tipo di errore: “So che il prossimo rilascio è tra 4 giorni. Questa storia sarà pronta in tempo? Ho bisogno di saperlo perché, se il rilascio conterrà la nuova funzionalità, devo spiegare al mio staff come utilizzarla”.
Per rispondere, andiamo a rivedere i nostri dati.
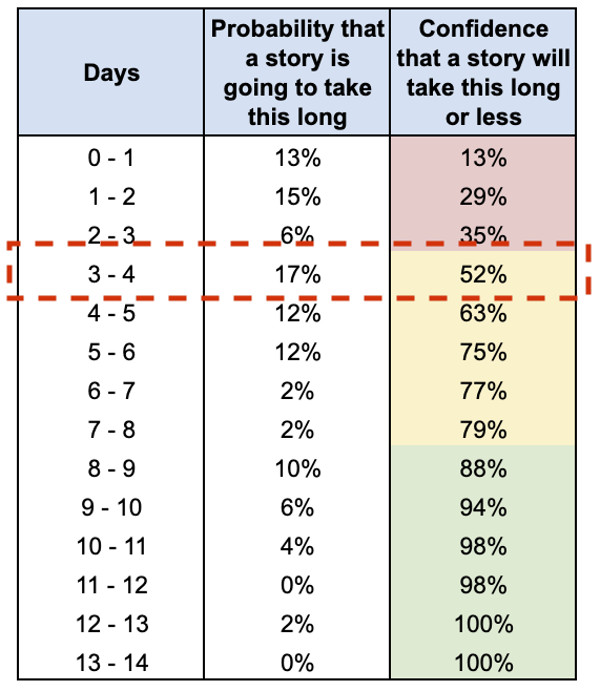
I nostri dati storici ci dicono che solamente il 50% circa delle storie sono completate in 4 giorni. Ecco quindi la nostra risposta a quel manager: “Siamo sicuri solo al 50% di poter completare questa funzionalità in tempo. Vuoi correre il rischio? Qual è l’impatto se non facciamo in tempo?”.
E il manager rispose: “No, allora preferisco aspettare il rilascio successivo. Se faccio il training dello staff e poi la funzionalità non c’è, creerebbe confusione, ho bisogno di più certezza. Grazie per l’onestà”.

Voglio sottolineare come, in scenari come questi, è molto facile per il team sentirsi sotto pressione e finire per dire di sì, promettendo di completare in tempo per poi finire a lavorare di notte o al weekend, prendendo ogni tipo di scorciatoie che nel lungo termine creano solo danni. Avendo dati alla mano, invece, è molto più facile resistere alla pressione e parlare dei possibili scenari, creando aspettative realistiche.
Ancora a proposito di conversazioni
Quello che veramente mi stupì in questo esempio fu la frase finale del manager: “Grazie per l’onestà”. Era talmente abituato a lavorare con fornitori che gli promettevano l’impossibile, che restò felicemente impressionato dall’avere finalmente una conversazione aperta e onesta. Personalmente, trovo che sempre più stakeholder apprezzino questo tipo di approccio, dove parliamo apertamente di cosa è possibile o no, e prendiamo decisioni in collaborazione.
“Quando dobbiamo iniziare questa storia? Ci serve entro X”
“Qual è il miglior momento per iniziare questa storia? In quale Sprint dobbiamo metterla?”. Ecco un altro esempio reale. Il team era impegnato a lavorare su una storia importante, quando il PO di ritorno da un meeting annuncia:
“Team, mi spiace interrompere ma l’altro team ha assolutamente bisogno di un nuovo ambiente di test per il loro progetto. Ho creato una nuova storia; da quando possiamo lavorarci?”
Il team chiede chiarimenti: “OK, entro quando ne hanno bisogno?”
“3 settimane”.
Per rispondere, rivediamo i nostri dati
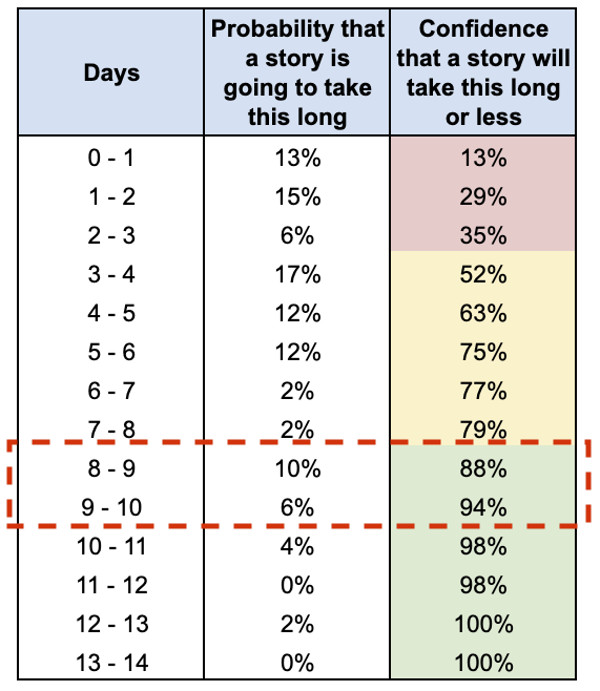
Sappiamo che abbiamo oltre il 90% di sicurezza che qualsiasi storia può essere completata in 9-10 giorni. Possiamo aspettare fino a 10 giorni prima della deadline, e avere comunque un alto livello di certezza di farcela in tempo.
Abbiamo quindi risposto: “Possiamo iniziarla 9-10 giorni prima, ed essere sicuri al 90% di farcela. Non interrompiamo quindi quello su cui stiamo lavorando”.

“Lavora immediatamente su questa storia, ci serve entro X!”
OK, questa non è propriamente una domanda, ma è una scena purtroppo comune quando qualcuno si fa prendere dal panico ed esige che il lavoro sia completato.
In una situazione del genere è molto facile sentirsi sotto pressione e dire di sì, abbandonando quello che stavamo facendo e finendo a prendere scorciatoie o a fare gli straordinari per completare la nuova priorità in tempo. Avendo dati a nostra disposizione invece è più facile restare calmi e dare una delle seguenti risposte:
- “Dai nostri dati storici sappiamo che c’è pochissima probabilità di completare la tua richiesta in tempo, anche se abbandonassimo quello che stavamo facendo e iniziassimo subito. Quali altre opzioni abbiamo? Potremmo invece completarla entro <altra_data>: in questo caso, quale sarebbe l’impatto?”
- “Certo, i nostri dati storici ci dicono che possiamo completare quello che ci stai chiedendo in tempo. Niente panico!”
- “Al momento stiamo lavorando su una storia che è in corso da 6 giorni. È molto probabile che la completeremo oggi o al massimo domani, dopodiché possiamo concentrarci sulla tua richiesta urgente”.

Conclusioni
In questo articolo abbiamo discusso quanti e quali dati raccogliere, per poi spiegare come utilizzare il Lead Time per fare previsioni, con molti esempi pratici di conversazioni che la maggior parte dei team si trova spesso ad affrontare. Nel prossimo articolo continuiamo la serie utilizzando la metrica Throughput per risponderere a un’altra serie di domande.