

Introduzione
Negli scorsi articoli abbiamo parlato del modo in cui i tipici approcci alle stime (per esempio, story point) spesso falliscono nel darci la prevedibilità che cerchiamo. Abbiamo poi visto come utilizzare le metriche Lead Time e Throughput per rispondere rispettivamente alle domande “Quanto tempo impiegherà questa storia?” e “Quanto lavoro possiamo completare in uno sprint?”.
In questo articolo affrontiamo una domanda ancora più difficile: “Quanto tempo impiegherà questo progetto?”. Ci concentriamo non più sulla singola storia ma su un pezzo di lavoro più corposo, come un progetto o un’intera feature. Spieghiamo come utilizzare una tecnica chiamata Probabilistic Forecasting per fare queste previsioni, con esempi pratici di conversazioni che la maggior parte dei team si trova spesso ad affrontare.
Probabilistic Forecasting
Abbiamo già parlato di Probabilistic Forecasting in un paio di articoli [1] di qualche anno fa, ma ne scriviamo qui un riassunto per poi vedere come usare questa tecnica per rispondere a numerose domande di business.
Cominciamo con una definizione: probabilistic forecasting è una tecnica per prevedere il verificarsi di eventi incerti. Consiste nell’utilizzare dati storici per simulare cosa accadrà in futuro, utilizzando un metodo statistico chiamato metodo Monte Carlo [3]. Il risultato della previsione è espresso come una lista di possibili risultati accompagnati dalla probabilità che quel particolare risultato divenga realtà.
Vediamo passo passo come funziona questa tecnica. Per aiutarvi a mettere in pratica quanto stiamo descrivendo, potete usare degli spreadsheet di esempio [4].
Dati in input
Abbiamo bisogno di due set di dati in input: il throughput passato e la quantità di lavoro da completare.
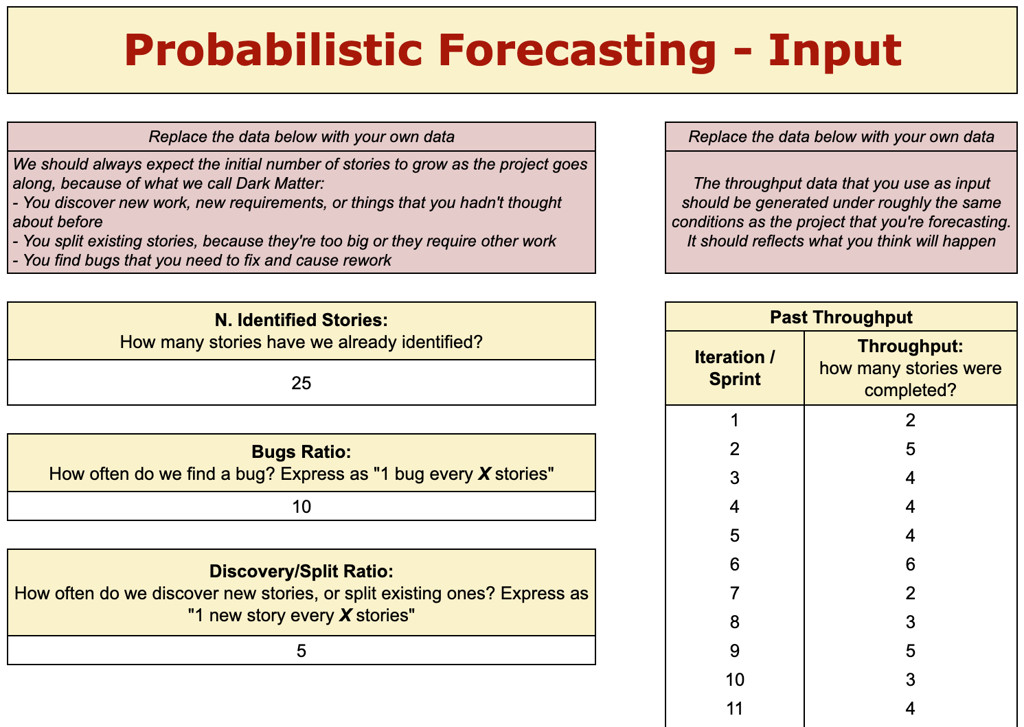
Il throughput passato rappresenta il numero di storie completate dal team per sprint in passato, come descritto nell’articolo precedente. Nella figura 1 in esempio, sulla destra, il team ha completato 2 storie nel primo sprint, 5 storie nel secondo sprint, e così via.
Sulla sinistra, diamo in input la quantità di lavoro da completare per questo progetto, con alcuni accorgimenti.
Per prima cosa, il team fa quanta analisi/design ritiene necessaria per arrivare al breakdown di epiche e storie, identificando così le storie che sono necessarie per questo progetto. Ricordiamo che, idealmente, il team usa tecniche di story slicing per suddividere le storie e ottenerne di più piccole possibili, come spiegato nel primo articolo di questa serie. Nella figura 1, il team ha identificato 25 storie da completare per questo progetto.
Occorre poi tenere conto di quello che David Anderson chiama Dark Matter [5]. Che cosa è questa “materia oscura” che non viene considerata nei tradizionali approcci basati su stime? È il fatto che, durante lo svolgimento del progetto, la quantità di lavoro inizialmente identificata aumenterà a causa di:
- Bug o problemi che vanno sistemati. Nella figura 1, questa crescita è espressa come “Bugs Ratio”, ovvero “ci aspettiamo di trovare 1 bug ogni X storie”. Questo numero è basato su quanti bug il team ha trovato in passato.
- Nuovo lavoro che viene scoperto — per esempio nuovi requisiti o, semplicemente, qualcosa a cui non avevamo pensato inizialmente — o lavoro esistente che viene suddiviso in storie più piccole, quando il team si accorge che una storia è troppo grande o richiede del lavoro preliminare. Nella figura 1, questa crescita è espressa come “Discovery/Split Ratio”, ovvero “ci aspettiamo di create 1 nuova storia ogni X storie”. Questo numero è basato su dati storici del team, per esempio osservando la frequenza con cui nuove storie vengono aggiunte al backlog.
Tutto questo significa che, se a inizio progetto abbiamo identificato 25 storie da completare, è probabile — e normale — che a fine progetto la quantità di lavoro sia diventata 30-35 storie, o anche di più in base al contesto e alla complessità del problema.
Monte Carlo simulation
Con questi dati in input, procediamo con la simulazione. Utilizziamo il metodo Monte Carlo, che consiste nell’estrarre in maniera random campioni dai nostri dati storici per simulare cosa accadrà in futuro, ripetendo la simulazione migliaia di volte per esplorare ogni possibile scenario e scoprire la probabilità di ogni risultato.
Sembra complicato, ma la pratica è molto più semplice della teoria. Vediamo come funziona con un esempio passo passo: il team ha suddiviso un nuovo progetto in 20 storie e vuole prevedere quanto tempo impiegherà per completarle.
Come primo passo, estraiamo in maniera random un campione dal throughput passato del team. In questo esempio abbiamo estratto il numero 3: stiamo simulando che nel primo sprint il team avrà completato 3 storie, perciò resteranno 17 storie da completare.
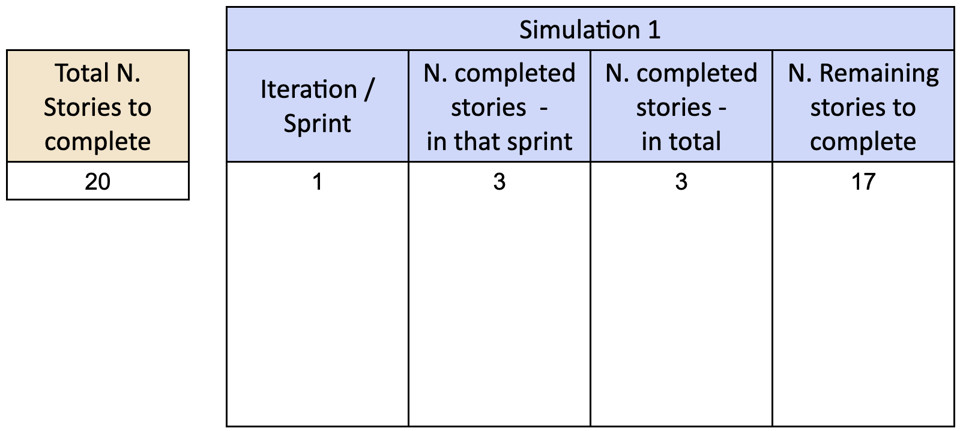
Ripetiamo per il secondo sprint, estraendo un altro campione random dal throughput passato. Nell’esempio abbiamo estratto il numero 5: stiamo simulando che nel secondo sprint il team avrà completato 5 ulteriori storie, perciò avrà completato 8 storie in totale con 12 storie rimanenti da completare.
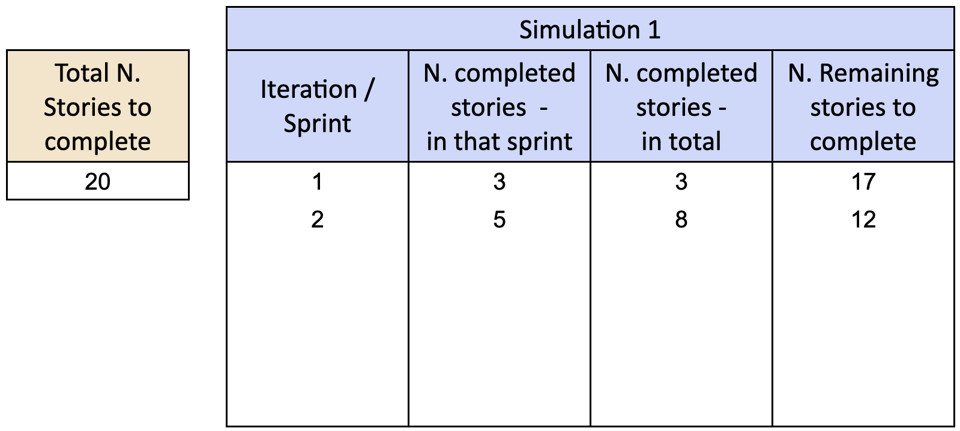
Continuiamo a ripetere, estraendo campioni a random con reinserimento, finché tutte le 20 storie non sono completate. Nell’esempio, al termine del quinto sprint il team ha completato 21 storie, completando quindi il backlog del progetto. Diciamo quindi che nella prima simulazione il team ha impiegato 5 sprint per completare il progetto.
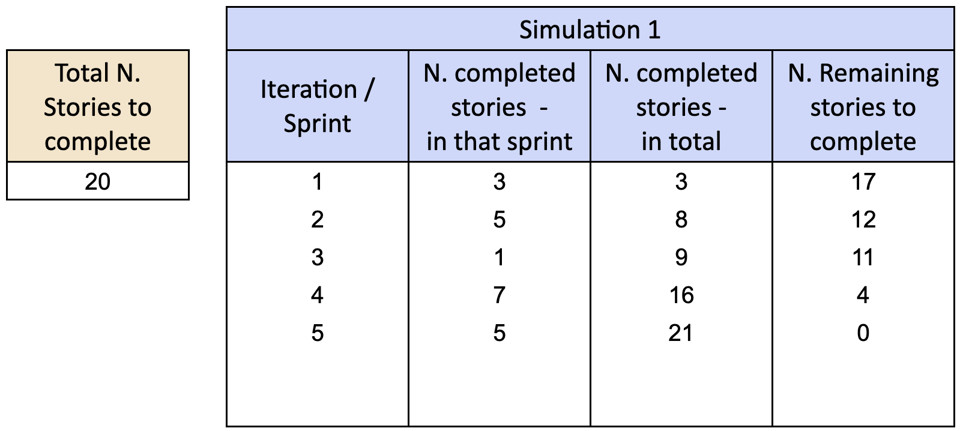
Ripetiamo la simulazione per migliaia di volte, seguendo il metodo Monte Carlo. Nel ripetere l’esercizio così tante volte, scopriamo ogni possibile scenario e osserviamo la probabilità che tale scenario accada. In alcune simulazioni, il team impiega 4 sprint, in altre 7, e così via.
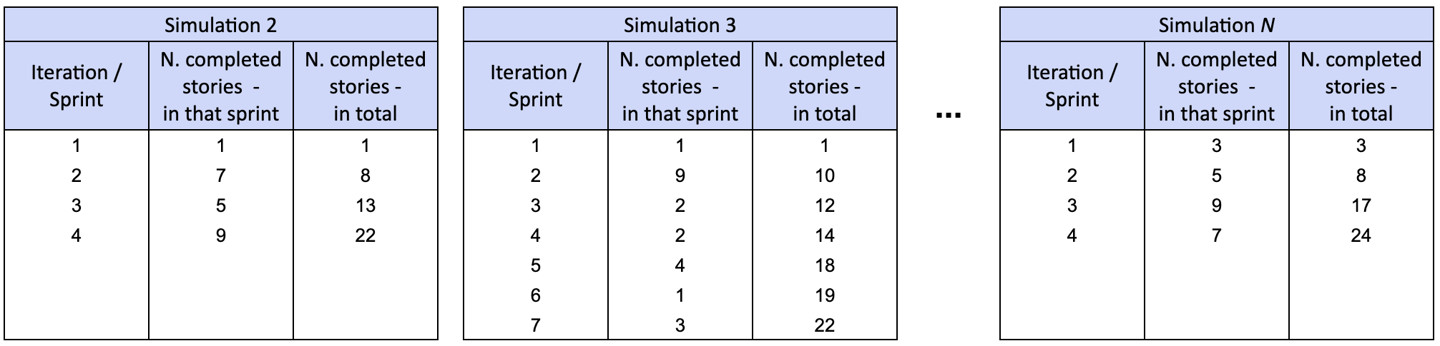
Ci saranno anche simulazioni particolarmente fortunate dove il team impiega solo 3 sprint, o altre particolarmente sfortunate dove il team impiega fino ad 8 sprint, ma possiamo osservare che la probabilità di tali estremi è molto bassa.
Risultati
Esprimiamo i risultati come una lista di possibili scenari con la probabilità che tale scenario si verifichi.
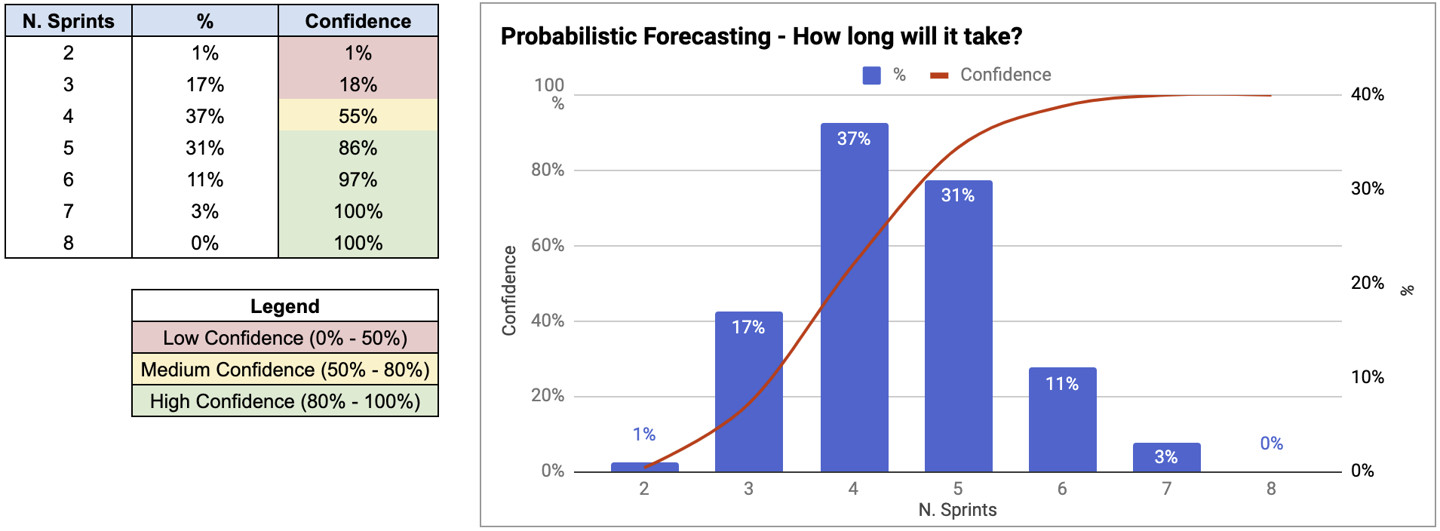
Nella tabella sulla sinistra, la seconda colonna indica la probabilità che il team impieghi esattamente quel numero di sprint per completare il lavoro. Questi numeri ci dicono che nel 17% delle simulazioni il team ha impiegato 3 sprint, nel 37% delle simulazioni ha impiegato 4 sprint, e così via.
La terza colonna è la somma cumulativa delle singole probabilità, che interpretiamo come livelli di sicurezza. Ci dice che nel 55% delle simulazioni il team ha impiegato 4 sprint o meno, e nell’86% delle simulazioni ha impiegato 5 sprint o meno. Il colore verde indica un alto livello di sicurezza nella nostra previsione.
Fare forecasting per rispondere a domande di business
Ora che sappiamo come implementare probabilistic forecasting, vediamo come utilizzare i risultati delle nostre simulazioni per rispondere a domande di business.
“Quanto tempo impiegherà questo progetto?”
Torniamo alla domanda di apertura di questo articolo: “Quanto tempo impiegherà questo progetto?”. Per rispondere, seguiamo i passaggi descritti sopra per preparare la nostra forecast: analizziamo il lavoro e lo suddividiamo in storie, dopodichè eseguiamo la nostra simulazione. Con i risultati alla mano, rispondiamo nel modo seguente: “Abbiamo circa il 50% di sicurezza di completare il lavoro in 4 sprint, ma siamo sicuri all’85% che non ce ne vorranno più di 5”. Inoltre aggiungiamo: “Nel peggiore dei casi potrebbero volerci 6 sprint, ma c’è solo il 15% di probabilità che ciò accada. Se succedesse, quale sarebbe l’impatto?”.
Notate come questa conversazione sia diversa da una classica discussione su una stima? Normalmente diremmo “Ci vorranno X giorni”, mentre ora parliamo apertamente dei possibili scenari che si possono verificare e del loro impatto. “Se in effetti questo progetto finisse per impiegare 6 sprint, quale sarebbe l’impatto per il business? Possiamo permetterci di prenderci il rischio? Cosa possiamo fare per ridurlo? Qual è il valore del lavoro, per giustificare tale rischio?”. La conversazione si è spostata dal parlare di stime al discutere di valore e rischio.

Chiudiamo la conversazione con una promessa che racchiude uno degli enormi vantaggi di forecasting: “Comunque vada, ti forniremo una previsione aggiornata al termine di ogni sprint”. I comuni metodi di stima sono spesso laboriosi e perciò troppo costosi per essere ripetuti frequentemente, per esempio, richiedendo di dover rivedere la stima di ogni storia nel backlog.
Facendo forecasting invece è molto facile aggiornare le nostre previsioni continuamente, usando continuous forecasting: al termine di ogni sprint aggiorniamo la quantità di lavoro rimanente e aggiungiamo un nuovo campione al throughput passato, per registrare quante storie abbiamo completato nello sprint appena concluso. La nostra forecast viene immediatamente ricalcolata e possiamo dare un aggiornamento ai nostri stakeholder.
“Quanto lavoro possiamo completare nei prossimi x sprint?”
Supponiamo che ci sia una scadenza da qui a 4 sprint: potrebbe essere una vera e propria deadline, oppure semplicemente il team vuole applicare una timebox. Il team si chiede “Quanto lavoro possiamo completare nei prossimi 4 sprint?”.
Per rispondere usiamo la stessa simulazione descritta sopra, generando migliaia di risultati con il Metodo Monte Carlo, ma aggreghiamo i risultati in modo leggermente diverso: in ogni simulazione, andiamo a osservare quante storie sono state completate dopo 4 sprint.
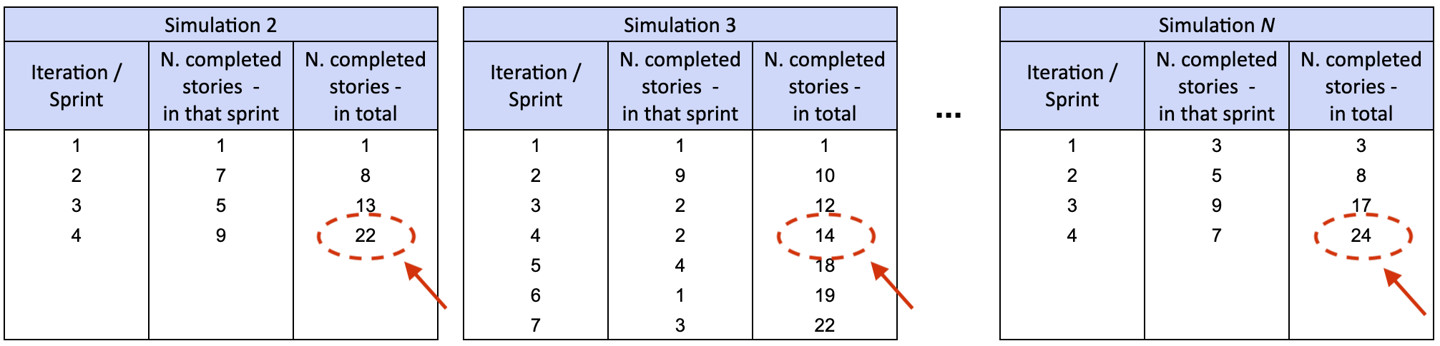
Seguendo poi i principi di forecasting, esprimiamo i risultati come lista di possibili scenari con la relativa probabilità: per ogni numero di storie, che probabilità abbiamo di completare tale quantità?
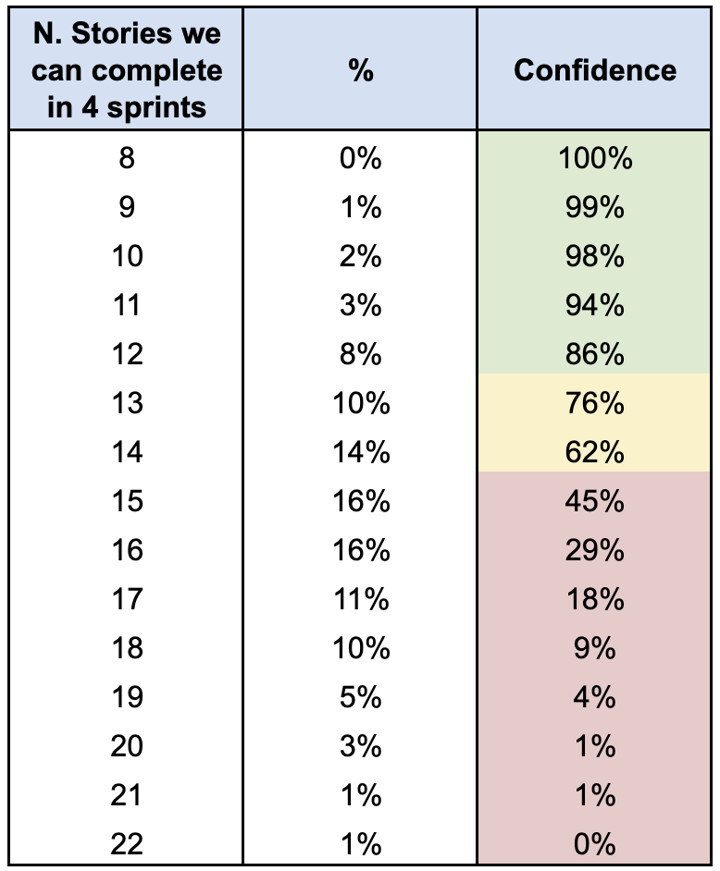
Come nell’esempio precedente, la terza colonna è interpretata come livello di sicurezza nella nostra previsione. L’unica differenza è che invece di essere una somma cumulativa, questa volta è una sottrazione cumulativa: più il numero di storie sale, meno ci sentiamo sicuri di poter completare tale quantità di lavoro.

In questi dati andiamo a leggere la nostra risposta: “Abbiamo oltre l’80% di sicurezza che possiamo completare almeno 12 storie. Su quali storie vogliamo lavorare?”. A questo punto il team può discutere di quali ritiene siano le 12 storie più importanti su cui concentrarsi.
“Questa feature sarà pronta in tempo?”
Prendiamo ad esempio uno scenario in cui il Product Owner presenti al team una nuova feature e chieda: “Questa feature è necessaria per l’integrazione con un altro team, che ne ha bisogno entro 2 sprint, o saranno bloccati. Sarà pronta in tempo?”. Per rispondere, usiamo una combinazione delle due simulazioni usate finora.
Per cominciare, il team suddivide la feature in 10 storie ed esegue una forecast, da cui osserva che la probabilità di completare tutte e 10 le storie in 2 sprint è molto bassa (14%).
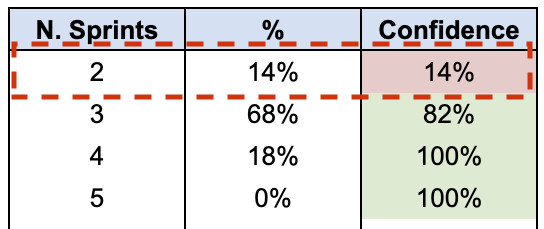
Il team esegue quindi la seconda simulazione per capire quanto lavoro può realisticamente completare in 2 sprint, giungendo alla conclusione che si sente sicuro di poter consegnare 5-6 storie.
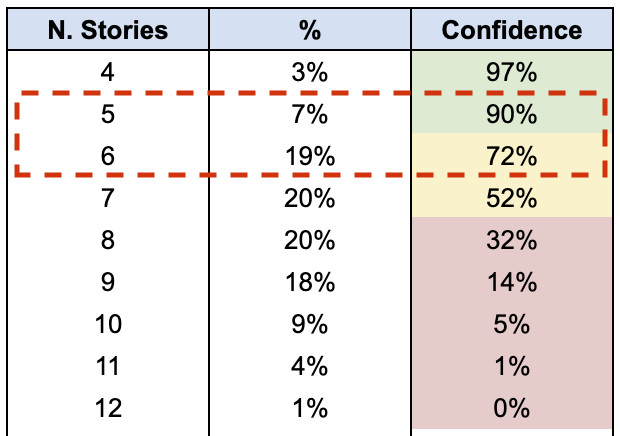
Rispondiamo quindi come segue: “Abbiamo suddiviso la feature in 10 storie. La probabilità di completarle tutte in 2 sprint è molto bassa. Ci sentiamo però sicuri di poter consegnare almeno 5-6 storie. Di queste 10 storie, quali sono le 5-6 più importanti? Possiamo consegnare un MVP che permetta all’altro team di non essere bloccato?”.

Ancora una volta, sottolineiamo come in scenari tipo questi sia molto facile per il team sentirsi sotto pressione e finire per dire di sì, promettendo di completare in tempo per poi finire a lavorare di notte o al weekend, prendendo ogni tipo di scorciatoie che creano solo danni nel lungo termine. Con questa conversazione invece abbiamo spostato il focus dal parlare di stime al discutere di MVP e ordine di priorità del lavoro.
Forecasting: consigli pratici
Vediamo di seguito una serie di consigli pratici cui vale la pena dedicare qualche parola perché possono risultare davvero utili nel creare previsioni utili e attendibili.
Continuous Forecasting
Uno dei grandi vantaggi di questo approccio è che è molto facile fare continuous forecasting. Regolarmente — per esempio, al termine di ogni sprint — aggiorniamo i dati in input alla nostra previsione: quanto lavoro rimane e i dati più recenti del team. Così facendo aggiorniamo continuamente le aspettative dei nostri stakeholder e identifichiamo i rischi il prima possibile.
Usa dati storici che sono rilevanti per il futuro
Quando usiamo dati storici per prevedere il futuro stiamo facendo l’assunzione che questi dati siano rappresentativi di quello che accadrà. Con team stabili questa assunzione è solitamente valida, ma cosa possiamo fare quando questa non è vera? Casi comuni sono quando il team deve lavorare su qualcosa di completamente diverso, o un cambio drastico nella composizione del team, con il caso limite di un team nuovo, quando non abbiamo alcun dato a disposizione.
In queste situazioni il mio approccio è di creare una serie di forecast usando diversi set di dati in input per esplorare diversi scenari:
- Usando dati di team che hanno una composizione che sembra simile, o che lavorano su qualcosa che sembra simile.
- Usando un range di throughput “ideale” basato su quello che personalmente mi aspetto che il team possa completare in uno sprint.
- Usando un ulteriore range di throughput “ideale” basato sul chiedere al team cosa pensano di poter completare in uno sprint quando tutto va bene, quando tutto va male, e varie vie di mezzo.
So bene che questi risultati hanno un alto margine di errore e che vanno quindi presi con le pinze, ma mi danno un’idea di cosa posso aspettarmi. Poi, non appena il team comincia effettivamente a lavorare insieme, sostituisco i dati “ideali” con i dati reali del team.
Prevedere la quantità di lavoro
Un’altra assunzione che abbiamo fatto negli esempi di questo articolo è che sia possibile suddividere il lavoro in storie. Questa assunzione è valida in molti casi quando, previa sufficiente analisi e magari qualche spike, il lavoro è abbastanza chiaro. Ma cosa possiamo fare se il lavoro è troppo grosso, o la soluzione non è ancora ben definita? Non solo sarebbe impraticabile creare tutte le storie in anticipo, ma si tratterebbe anche di un approccio rischioso in quanto ci forza verso la scelta prematura di una particolare soluzione.
In questi casi, invece di creare le storie prematuramente, possiamo usare una simulazione per fare forecasting di quanto lavoro avremo da fare. Ad alto livello di astrazione, funziona così:
- analizziamo il problema quanto basta per identificare l’elenco di epiche;
- da questa lista scegliamo 5 epiche in maniera random e le suddividiamo in storie;
- usiamo il numero di storie in queste 5 epiche per fare una simulazione e inferire quante storie otterremo dalle altre epiche.
Per maggiori dettagli, rimandiamo a un articolo [6] scritto qualche anno fa, dove abbiamo descritto questo approccio.
Non servono troppi dati
Ricordate poi che, come spiegato nel secondo articolo di questa serie (box in alto a destra), sono sufficienti tra 5 e 11 campioni per fare previsioni abbastanza attendibili.
Scoprire il motivo dietro la richiesta di una stima
Quando ci viene chiesta una stima, è importante chiedere “Quali decisioni verranno prese in base a questa stima?” per capire il motivo per cui ci viene fatta questa richiesta. In diversi casi esistono strumenti migliori che una stima (o previsione) per prendere decisioni. Vediamo di seguito un paio di esempi.
- Per decidere budget e priorità, meglio chiederci “Qual è il valore di questo lavoro? Quanto siamo disposti a investire?”. Il budget diventa poi una timebox entro cui lavorare in iterazioni rapide.
- Quando siamo ancora in fase di product discovery e dobbiamo validare le nostre ipotesi, è meglio lavorare in cicli rapidi di sperimentazione e raccogliere feedback velocemente, accettando il fatto che è impossibile prevedere quanto impiegheremo a risolvere un problema che non sappiamo ancora formulare.
Ascoltare le persone, non seguire ciecamente i numeri
Non fate l’errore di fidarvi ciecamente del risultato delle previsioni. Se la nostra forecast dice una cosa ma le persone nel team ne dicono chiaramente un’altra, è possibile che ci sia un problema nei dati o nella simulazione. Occorre ricontrollare e ascoltare il team. In fondo, queste sono le persone che fanno il lavoro giorno dopo giorno: nessuno lo conosce meglio di loro.
Come iniziare
Per iniziare ad applicare queste idee, il mio consiglio è sempre di cominciare in parallelo:
- Non cambiate il vostro processo all’improvviso, ma cominciate intanto a raccogliere i dati descritti in questa serie di articoli.
- La prossima volta che vi verrà chiesta una stima, rispondete nel modo abituale ma, allo stesso tempo, usate i vostri dati che avete raccolto per fare anche una previsione (forecast) e non la solita stima (estimate).
- Durante il corso del progetto, continuate ad aggiornare la forecast.
- Alla fine del progetto, confrontate i risultati della stima e della previsione.
Probabilmente scoprirete che la forecast è stata più accurata della estimate: sarà allora possibile usarla come esempio pratico per introdurre l’idea nel vostro team o nell’intera azienda.
Conclusione
In questo articolo abbiamo discusso di come usare probabilistic forecasting per fare previsioni di progetti o feature.
Concludiamo con questo numero la serie sulle metriche per prevedere il futuro, in cui abbiamo spiegato come usare dati e metriche per rispondere a domande di business e migliorare le nostre conversazioni.
Mattia Battiston è un software developer con una grande passione per il miglioramento continuo. Attualmente lavora a Londra e utilizza Kanban, Lean e Agile per aiutare diversi team a migliorare.