

Premessa
Nel riordinare il materiale di MokaByte, in vista dell’imminente restyling del sito, ci stiamo soffermando, qua e là, in diversi articoli di molti anni fa. Ce ne sono alcuni che, a distanza di tanti anni, mantengono una loro validità.
I database non relazionali sono oggi una realtà, conosciuta e utilizzata, e sono alla base di alcune tra le piattaforme digitali più usate nel pianeta. Ma la loro affermazione, almeno agli inizi, non mancò di suscitare qualche perplessità e diffidenza
Questa pagina, pubblicata poco più di dieci anni fa, fu uno dei primi articoli in cui affrontammo la tematica NoSQL (n.d.r.).
Marzo 2011
Con questo articolo introduttivo ai database NoSQL, vediamo quali sono le motivazioni che hanno portato alla realizzazione di un gran numero di progetti di database NoSQL e quali sono le loro caratteristiche principali in relazione ai modelli di dati.
Storia e motivazioni
NoSQL è l’acronimo di “Not only SQL” e viene usato generalmente per indicare quei database che non usano un modello di dati relazionale e quindi potrebbero non usare SQL come linguaggio di interrogazione. Dunque il concetto è di per se’ stesso più antico dei RDBMS, eppure è tornato in auge quando, per varie motivazioni, i database non relazionali hanno mostrato diversi vantaggi, rispetto ai database SQL tradizionali.
Una delle principali motivazioni per l’uso di tali database è rappresentata dalla scalabilità. La scalabilità è un requisito sempre più importante per le applicazioni web, e ciò è dovuto a molti fattori: l’esplosione del numero di utenti della rete (letteralmente esponenziale negli ultimi dieci anni secondo i dati del ISC Domain Survey[1]), la sempre maggiore diffusione di OpenID, quindi la sinergia tra le varie community e tra esse e i fornitori di servizi, ma anche la crescente disponibilità di dispositivi con accesso ad Internet come smartphone, tablet e altri dispositivi portatili.
Vediamo allora come deve essere un sistema, in concreto, per essere scalabile. Tradizionalmente la scalabilità di un sistema è la sua proprietà di avere un incremento di prestazioni che è grosso modo direttamente proporzionale al suo aumento di risorse [2]. Infatti, se l’aumento delle prestazioni non è direttamente proporzionale, significa che il sistema spreca risorse. Ma le risorse possono essere aumentate in due modi, ognuno dei quali genera un diverso modello di scalabilità [3]: entrambi questi modelli di scalabilità hanno vantaggi e svantaggi. Vediamoli più da vicino.
Scalabilità orizzontale
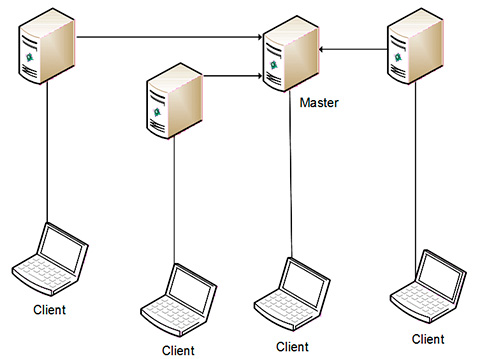
La scalabilità orizzontale (scale out) si ha se l’aumento delle risorse si riferisce all’aumento dei nodi nel sistema, cioè il sistema riesce a parallelizzare il carico di lavoro.
Un tipico esempio di applicazione è il sito web statico: esso è quasi perfettamente scalabile orizzontalmente: raddoppiando il numero di server che lo ospitano si ottiene un esatto raddoppio dei potenziali utenti serviti.
Il vantaggio più importante dato da questo tipo di scalabilità è il costo: infatti, con un’applicazione perfettamente scalabile, si potrebbero impiegare molti nodi a basso costo, ottenendo anche una maggiore prevedibilità del costo marginale. Un altro vantaggio è la maggior fault-tolerance: l’errore in un nodo non pregiudica totalmente il funzionamento dell’applicazione.
Gli svantaggi risiedono nei maggiori sforzi in fase di progettazione perche’ l’applicazione deve innanzitutto supportare questo modello di scalabilità; inoltre l’applicazione deve essere facile da amministrare, per ridurre i costi d’installazione.
Scalabilità verticale
La scalabilità verticale (scale up) si ottiene quando, per aumentare le prestazioni dell’intero sistema, si aumentano le risorse di un singolo nodo del sistema, ad esempio utilizzando una CPU con frequenza maggiore o incrementando la memoria disponibile. Il vantaggio di questo tipo di scalabilità è che generalmente non è necessario modificare le applicazioni, ne’ sono richiesti interventi amministrativi. Lo svantaggio consiste innanzitutto nel costo, perche’ l’aggiornamento spinto di una macchina può essere economicamente molto più gravoso dell’acquisto di una ulteriore macchina di pari potenza.
Premesso ciò, dunque, consideriamo un’applicazione con la classica architettura web three-tier, come in figura 3.
Se il Presentation Tier e il Business Logic Tier sono scalabili orizzontalmente, perche’ sviluppati rispettivamente per un web server e, per esempio, un container EJB, non si può dire lo stesso del Data Tier.
L’anello debole
Se l’applicazione è destinata a un vasto numero di utenti in Internet e il budget è ristretto, questo livello costituisce il vero anello debole, perche’ costringe a un upgrade delle macchine sempre più importante e costoso.
Ad avvalorare il fatto che si tratta di un limite intrinseco e non tecnologico c’è la congettura di Brewer, detta anche teorema CAP [4] dalle iniziali delle tre parole chiave. Essa stabilisce che possono essere soddisfatte contemporaneamente soltanto due delle tre proprietà che desidereremmo avere sempre in un sistema distribuito.
- Consistency. Dopo ogni operazione il sistema si trova in uno stato consistente: dopo che un’operazione di scrittura è stata effettuata, chi in seguito andrà a leggere quel dato dal sistema leggerà il nuovo dato.
- Availability. L’eventuale fallimento di un nodo non blocca il sistema.
- Partition tolerance. Il sistema continua a operare anche in seguito ad un partizionamento della rete.
A seconda se il sistema sacrifica Availability o Consistency o Partition tolerance è possibile classificare i database distribuiti in tre categorie: CA, CP e AP. Risulta evidente che i tradizionali RDBMS possono essere classificati come sistemi CA, cioè garantiscono consistenza e disponibilità ma non tolleranza alle perdite di messaggi.
Le alternative possono essere invece cercate in modelli di tipo CP e AP: sono questi, ma non solo, i sistemi non relazionali; infatti, alcuni database NoSQL sono tali non per scelte dovute al modello di sistema distribuito (CA, CP o AP), ma meramente in base al modello di dati, non relazionale. Attenzione, se un sistema è stato architettato in modo da garantire disponibilità e tolleranza al partizionamento, ciò non significa che il sistema non è mai consistente, ma che, in certe situazioni potrebbe non esserlo, ossia il sistema garantisce, per così dire, una consistenza “debole”.
Modelli di dati
I database NoSQL, anche perche’ spesso servono a garantire proprietà diverse dai RDBMS, utilizzano dei modelli logici di dati di tipo non relazionale. Questi modelli sono riconducibili grosso modo a quattro grandi famiglie. Vedremo che questi modelli logici non hanno la stessa potenza espressiva del modello relazionale, proprio per ciò che riguarda le relazioni tra entità,. Infatti, per sintetizzare, per la scalabilità orizzontale dei RDBMS, i più grandi problemi sono dovuti a JOIN e a foreign key. Un’altra proprietà dei database NoSQL è di essere schemaless, con i pro e i contro che ne conseguono: più facilità di deploy ma anche, talvolta, maggiori difficoltà d’interrogazione.
Passiamo dunque ad analizzare le quattro tipologie di modelli di dati più comuni. Spesso un database non ne utilizza uno in modo rigoroso: in molti casi quello che succede è che vengono utilizzati dei modelli compositi che assomigliano di volta in volta all’uno o a all’altro modello.
Chiave-valore
Il modello a chiave-valore si basa su una API analoga ad una Map:
/* inserisce un oggetto nel database */ void put(String key, Object value); /* rimuove un oggetto con una certa chiave */ void remove(String key); /* cerca un oggetto nel database */ Object get(String key);
Proprio come in una mappa, il valore è un oggetto del tutto trasparente per il sistema, cioè fondamentalmente non è possibile fare query sui valori, ma solo sulle chiavi. Il modello chiave-valore è il modello logico più semplice; ciò non significa che sia di facile implementazione, tutt’altro: può presentare problematiche molto complesse.
Sebbene sia possibile estendere una tale API per permettere transazioni che coinvolgono più di una chiave, ciò sarebbe controproducente in un ambiente distribuito, dove l’utilità di avere coppie chiavi-valore non legate fra loro permette di scalare orizzontalmente in modo molto semplice: è sufficiente, infatti, suddividere le coppie tra i server. Anche le ricerche nel database possono essere fatte in parallelo, ad esempio con funzioni Map e Reduce.
A prima vista il modello sembra semplicistico se paragonato a quello relazionale, effettivamente però in molti ambiti possiamo utilizzare strutture di tipo chiave-valore, ad esempio in un sito di e-commerce c’è la profilatura utente, il cestino, lo storico degli ordini etc. Un esempio di questo tipo di database è Cassandra[5], un DBMS open source, utilizzato e sviluppato per Facebook.
Orientato ai documenti
Questo modello è simile al modello chiave-valore, tranne che per il fatto che il valore non è trasparente per il database ma è in un formato che il sistema può interpretare e interrogare. I formati più usati sono XML e JSON. JSON, essendo semplicemente un oggetto JavaScript serializzato, può essere ovviamente molto utile in ambiente web. Generalmente i DBMS document-oriented utilizzano una o più proprietà degli oggetti per indicizzarli ed è possibile effettuare delle interrogazioni basate sulle proprietà dell’oggetto. Ad esempio, se consideriamo una collezione di documenti JSON che rappresentano gli utenti di un forum
/* esempio di documento JSON */
{
"userName" : "user1"
"email" : "foo@foo.foo"
"tags" : [ "Java" , "NoSql" , "JSON" ]
}
una query potrebbe essere “tutti gli utenti che hanno ‘Java’ tra i tag dichiarati”, e potrebbe essere espressa tramite un oggetto JSON
/* esempio di query */
{ "tags" : "Java" }
Esempi di DBMS orientati ai documenti sono MongoDB [6], CouchDB [7], JackRabbit [8] e TerraStore [9].
A grafo
I modelli visti fin qui hanno il problema che non sono adatti a contenere dati molto interconnessi: un fattore molto limitante in un’applicazione complessa come ad esempio un social network. Un database a grafi può essere visto come un caso particolare di un database orientato ai documenti in cui alcuni particolari documenti rappresentano le relazioni.
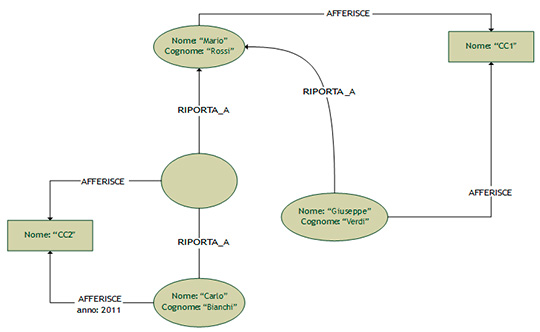
Questo tipo di database è sicuramente molto potente, se consideriamo che il modello permette un’operazione molto interessante: l’attraversamento (graph traversal). Rispetto ad una normale query su database chiave-valore, l’attraversamento stabilisce come passare da un nodo all’altro, utilizzando le relazioni tra i nodi. Ad esempio, se consideriamo il dominio di un social network in cui abbiamo dei nodi di tipo Utente e una relazione di tipo Amicizia, un attraversamento del tipo: “Tutti i nodi di tipo Utente collegati all’utente X tramite la relazione Amicizia con una profondità 2, con ricerca in ampiezza” implementa la funzione “Altre persone che potresti conoscere…”. Portiamo questo esempio su un noto database open source a grafo, Neo4J [10]:
/* definizione relazioni */
enum Relazioni implements RelationshipType
{
AMICIZIA
};
/* creazione nodi */
Node utente1 = graphDb.createNode();
utente1.setProperty("name", "Mario Rossi");
Node utente2 = graphDb.createNode();
utente2.setProperty("name", "Claudia Bianchi");
/* creazione relazioni */
Relationship amicizia = utente1.createRelationshipTo( utente2, Relazioni.AMICIZIA );
/* attraversamento */
Traverser utente1PotrebbeConoscere = utente1.traverse( Order.BREADTH_FIRST,
new StopEvaluator {
public boolean isStopNode(TraversalPosition position) {
return position.depth() == 2;
}
},
new ReturnableEvaluator() {
public boolean isReturnableNode(TraversalPosition position) {
return position.depth() == 2;
}
},
Relazioni.AMICIZIA, Direction.OUTGOING );
Tabulare
Sebbene il nome possa ricordare le tabelle dei RDBMS, qui la grande differenza è che si parla di dati schemaless. Questo modello può essere descritto come un document-oriented con valori multidimensionali e senza schema. Chiariamo il concetto con un esempio: immaginiamo un social network in cui gli utenti possono aggiungere contenuti in varie forme (testo, link, foto, …) e provenienti da vari canali (web, mobile, SMS, …). Volendo impiegare un database di questo tipo per lo storage dei dati, avremmo una struttura in cui ogni contenuto ha una chiave unica e un documento. Il documento a sua volta è composto da un valore oppure una serie di tuple nome-valore e così via.
Le limitazioni, rispetto al modello relazionale, sono evidenti: a parte la chiave primaria, non è facile effettuare interrogazioni; il modello è abbastanza complesso; non è possibile garantire la consistenza con strumenti analoghi alle foreign key. Però il grande vantaggio è che è possibile immagazzinare enormi quantità di dati sparsi in un gran numero di server, proprio come viene fatto con BigTable, il database usato da Google [11].
Conclusioni
In questo articolo abbiamo introdotto alcuni concetti chiave sui database NoSQL e abbiamo visto in quali contesti essi possono essere applicati in modo efficace, ossia laddove la scalabilità sia una specifica molto importante. Si potrebbe pensare che questi ambiti siano circoscritti e che quindi il problema si ponga solo per i grandi social network, ma dobbiamo pensare che, allorche’ cominciamo un nuovo progetto per un’applicazione web, magari compatibile con OpenID, abbiamo potenzialmente un enorme bacino di utenti: la nostra applicazione deve essere scalabile così da avere un impatto minimo sull’architettura del sistema quando e se gli utilizzatori supereranno quel valore critico che può mettere a repentaglio la fruibilità del servizio.
Abbiamo visto che esistono diversi tipi di database, ognuno con il suo specifico modello di dati: pertanto, una volta scelta una di queste tipologie, potrebbe non essere semplice migrare a un’altra soluzione. Il consiglio rimane sempre quello di costruire applicazioni modulari in modo da rendere il più possibile indolore un’eventuale cambiamento.
Per ora ci fermiamo qui, ricordando il blog NoSqlDatabases.com [12] che è ricco di informazioni generali sul mondo NoSQL; per i singoli DB non relazionali, rimandiamo ai siti ufficiali, citati nei riferimenti. Nei prossimi articoli vedremo in pratica come si può utilizzare uno specifico database NoSQL per effettuare le più comuni, e le più potenti, operazioni di storage con Java.
Riferimenti
[1] Internet Systems Consortium, “The ISC Domain Survey”
http://www.isc.org/solutions/survey
[2] LINFO: Scalable definition
http://www.linfo.org/scalable.html
[3] Michael, Moreira, Shiloach, Wisniewski, “Scale-up x Scale-out: A Case Study using Nutch/Lucene”, Parallel and Distributed Processing Symposium, 2007
http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=4228359
[4] Nancy Lynch, Seth Gilbert, “Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services”, ACM SIGACT News, 2002
[5] Apache Cassandra
[6] MongoDB
[7] Apache CouchDB
[8] Apache JackRabbit
[9] Terrastore
http://code.google.com/p/terrastore/
[10] Neo4j
[11] AA.VV., “Bigtable: A Distributed Storage System for Structured Data”, Seventh Symposium on Operating System Design and Implementation, Seattle, 2006
http://labs.google.com/papers/bigtable.html
[12] NoSqlDatabases
http://www.nosqldatabases.com/
Onofrio Panzarino, ingegnere elettronico, lavora ad Ancona come software architect, per Wolters Kluwer Italia. Sviluppatore con esperienza in vari linguaggi e piattaforme, soprattutto web-oriented, è molto interessato a soluzioni scalabili e a linguaggi di programmazione funzionali. È speaker in JUG Marche su argomenti correlati a Scala e database NoSQL.