

The Old New Things
Abbiamo visto nei precedenti articoli che Data Mesh è un set di principi socio–tecnici per progettare moderne architetture dati. Non stiamo quindi parlando di un framework, ma sostanzialmente di principi. Potremmo riassumere il senso di Data Mesh affermando che lo scopo ultimo è quello di promuovere il dato come prodotto a tutti gli effetti, con tutto ciò che questo comporta.
Ma, se i concetti espressi in Data Mesh sono relativamente nuovi, i problemi che si propone di risolvere non lo sono affatto. In questa puntata vedremo come Data Mesh propone di risolvere questi problemi, e, in particolare, come il concetto di event streams rappresenti un ottimo alleato.
Da dove partiamo?
Il primo principio di Data Mesh (Principle of Domain Ownership), sancisce il ritorno del controllo del dato al Bounded Context di riferimento. Ma i dati prodotti dal normale flusso operativo all’interno di un Bounded Context sono innanzitutto dati operativi — ricordate la differenza fra dati operativi e dati analitici? — e, in secondo luogo, sono appunto dati del dominio.
Data Mesh, dal nome stesso, si propone di costruire una rete di dati condivisi, più precisamente di Data Product, ognuno proveniente dal proprio Bounded Context, con il fine ultimo di fornire valore al sistema in generale. Se penso al modello che utilizzo spesso, quello del fantomatico birrificio BrewUp, un esempio potrebbe essere la correlazione delle vendite di birra con il comportamento degli utenti in prossimità di qualche manifestazione sportiva, in modo da proporre la birra giusta in base all’evento programmato. Il fatto stesso che si verrà a creare un nuovo dataset implica la creazione di un nuovo team che si dovrà occupare del suo mantenimento, e probabilmente anche l’individuazione di un Data Product Owner per gestirne le evoluzioni. La domanda a questo punto è “Come trova i dati da aggregare questo nuovo team?”.
Un passo alla volta
Abbiamo detto che, al pari della frammentazione di un monolite in microservizi, così operiamo per suddividere il nostro Data Lake in tanti Data Product distribuiti, individuando nel pattern del Bounded Context lo strumento per suddividere il problema. È ovvio, a questo punto, che l’aver promosso il dato a Data Product rappresenta un cambiamento fondamentale nel modo in cui le organizzazioni creano, archiviano e comunicano i dati aziendali importanti. In soldoni significa che ogni Bounded Context è responsabile nel decidere quali dati, all’interno del proprio dominio, possono essere condivisi perché creano valore per l’organizzazione, e quali invece devono rimanere all’interno del dominio perché ritenuti, per esempio, sensibili o comunque privati.
I più attenti potrebbero obiettare dicendo che già DataWarehouse ha come scopo quello di creare dei set di dati condivisibili, e avrebbero ragione. Ma l’approccio DataWarehouse richiede un modello di dati e uno schema ben definiti al momento della scrittura, e questo schema, solitamente, viene definito e realizzato dal team che si occupa dei dati.
È senza dubbio una strategia che risolve molti problemi di disponibilità e qualità dei dati; ma oltre a delegare l’onere di mantenere un modello di dati così strutturato su un unico team, che costituisce il classico collo di bottiglia alla scalabilità, rappresenta una soluzione rigida alla condivisione del dato. Coloro che vogliono consumare questi dati si devono adeguare a questo modello. Gli esperti di Domain-Driven Design direbbero che il pattern di Context Mapping in questo caso sarebbe di tipo upstream per chi fornisce e downstream per chi deve consumare, in particolare conformist, proprio perché ci dobbiamo conformare al team che produce i dati.
Building a Data Product
Se vogliamo promuovere una decomposizione della proprietà dei dati orientata al dominio, allora dobbiamo modellare un’architettura che organizza i dati analitici per dominio. In questa architettura le API del dominio stesso, utilizzate per esporre i dati operativi al resto dell’organizzazione, dovranno esporre anche i dati analitici che il dominio genera e possiede.
Ogni domino controlla i propri dati, siano essi operativi o analitici. Partendo dal presupposto che ogni dominio possiede già il suo set di API per esporre il proprio ReadModel, allora si tratta si estendere queste interfacce con un set di API che espongono anche i dati analitici
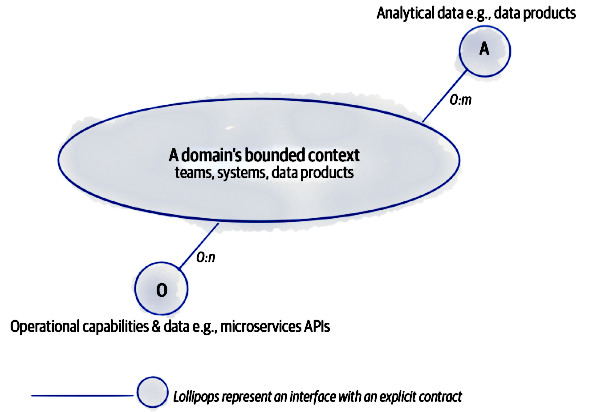
Le API per i dati analitici sono in genere progettate per accedere a volumi di dati ridotti e forniscono un’istantanea near–real–time dello stato del sistema. Per esempio, restando sul nostro fantomatico ERP di gestione di un birrificio, potremmo avere un endpoint per ricevere informazioni sui pub distribuiti per zona geografica, e magari con l’indicazione del tipo di birra maggiormente consumata per pub/zona.
Un aspetto importante da sottolineare è che Data Mesh non cambia l’architettura già esistente, anzi, ne riconosce l’esistenza e la estende. Queste stesse API dei dati analitici posso a loro volta essere utilizzate da altri domini per aggiornare i propri Data Product. In fondo le API dei dati analitici altro non sono che un modo per implementare le proprietà che un Data Product deve avere per essere definito prodotto, ossia la possibilità di essere trovato, compreso e osservato. Per soddisfare il principio della Data Governance il Data Product definisce e controlla le API che lo espongono al mondo esterno.
Architecture Quantum
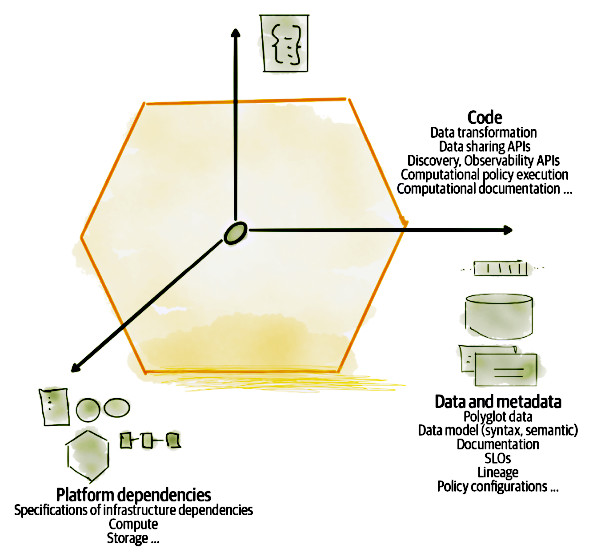
Nel libro Building Evolutionary Architecture [3] troviamo il concetto di Architectural Quantum, ossia la più piccola unità architetturale che può essere distribuita in maniera indipendente per il fatto che ha un’elevata coesione funzionale e include “tutti gli elementi strutturali richiesti per la sua funzione”. Nel caso di Data Mesh un Data Product è un Architectural Quantum. Non si tratta solo del dato, ma di tutte le componenti necessarie a far sì che questa unità possa essere distribuita in maniera autonoma.
Ogni Data Product ha tre tipi di componenti strutturali: codice, dato (compresi i metadata e la configurazione) e dipendenze infrastrutturali per gestirlo.
Codice
Per essere indipendente, ogni Data Product deve includere il codice che lo genera. Questo è un aspetto fondamentale che differenzia Data Mesh da altre forme di condivisione di dati. Un Data Product è un oggetto attivo, a differenza di altri elementi come tabelle o data storage che sono passivi. Il Data Product può sottoscrivere stream di eventi provenienti da altri domini, oppure può interrogare le API di altri Data Product, e poi trasforma tutti questi dati per ottenere le informazioni necessarie per sé.
Questo rimuove la necessità di ricorrere a pipeline esterne all’architettura per trasformare i dati provenienti da diverse fonti, rendendo il Data Product indipendente. Il codice incaricato alla trasformazione dei dati produttivi in dati analitici è specifico per il dominio e incapsula regole di business, logica di aggregazione e modellazione dei dati. È su questo codice che il team che si occupa del Data Product impiega la maggior parte del suo tempo, implementando anche i test necessari. La trasformazione dei dati include anche la relativa pulizia, a differenziare ulteriormente Data Mesh dagli approcci tradizionali, ricevere dei dati sporchi dal Data Product è un errore, o comunque un’eccezione.
Interfacce
il Data Product deve fornire l’accesso ai suoi dati, a questo servono le estensioni alle normali API normalmente esposte dal dominio. Al momento non esistono delle standardizzazioni al riguardo, almeno non specifiche per Data Mesh, ma restano valide le normali regole di scritture delle API stesse.
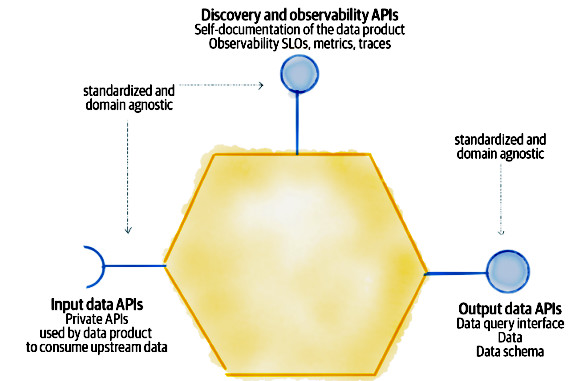
In figura 4 vediamo le possibili interfacce implementate dal Data Product
- Output data API: si tratta di un set di API che hanno lo scopo di condividere i dati con l’esterno in modo che possano essere affidabili e comprensibili.
- Input data API: si tratta di API interne al Data Product utilizzate per sottoscrivere stream di eventi provenienti da altri Data Product, nel caso di comunicazioni asincrone, oppure per inviare richieste ad altre API nel caso di comunicazioni sincrone. In ogni caso, all’arrivo di nuovi dati, vengono avviati i processi di trasformazione necessari.
- Discovery and observability API: forniscono ulteriori informazioni riguardanti la discoverability del Data Product.
Policy as code
L’ultimo tassello di incapsulamento del Data Product è il codice responsabile della configurazione e dell’esecuzione di vari comportamenti quali politiche di accesso, controllo di accesso, qualità e conformità.
Tipi di Data Product
Dovendo rispettare il principio della Self-Serve Data Platform non è pensabile fornire un solo tipo di Data Product. A tale scopo ne sono infatti previste tre tipologie diverse, in grado di soddisfare, se non tutte, gran parte delle richieste. Vediamo di scoprire quali sono.
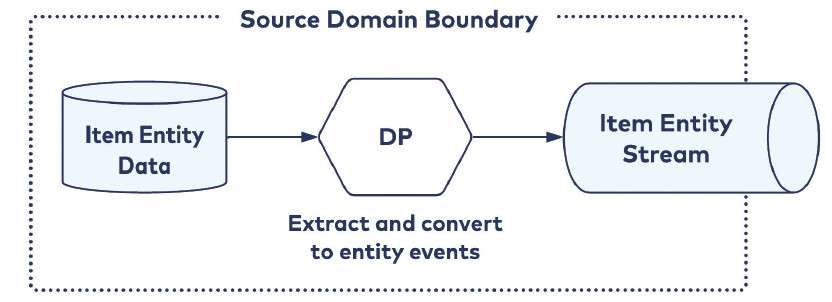
Source Aligned
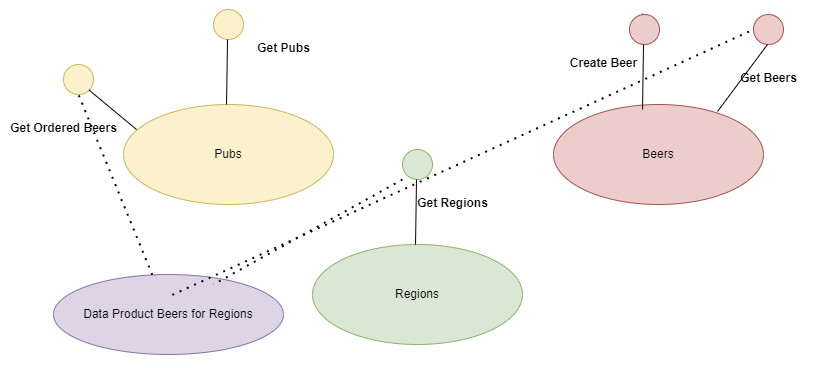
Questi Data Product riflettono i fatti aziendali. Sempre con riferimento al nostro sistema di produzione della birra, potremmo sottoscrivere i fatti relativi al click sulla visualizzazione delle proprietà della birra visualizzata, per capire quale risulta più apprezzata.
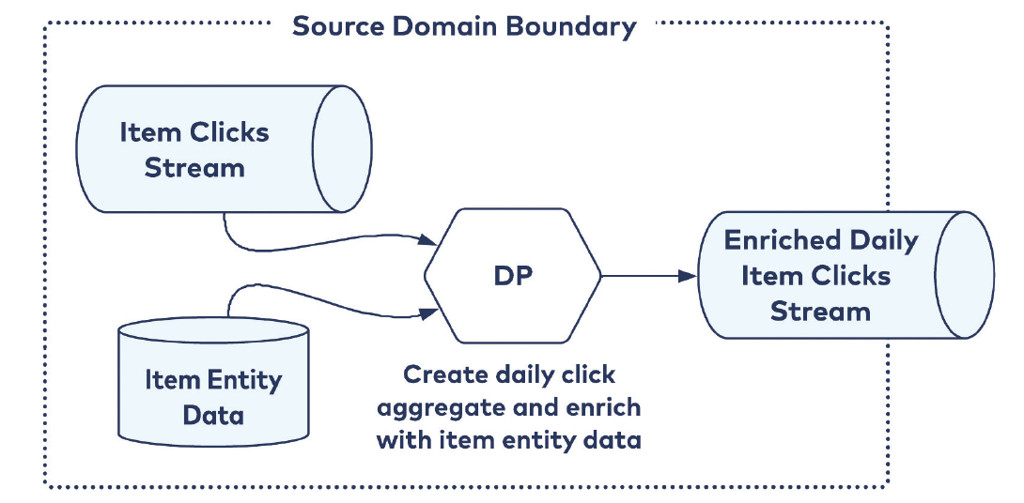
Aggregate Aligned
Questi Data Product rappresentano l’aggregazione di fatti provenienti da uno o più Data Product. Ad esempio, l’aggregazione giornaliera dei click sulla birra e la classificazione per tipologia della birra stessa. Normalmente sono utili per incrociare informazioni provenienti da Bounded Context diversi.
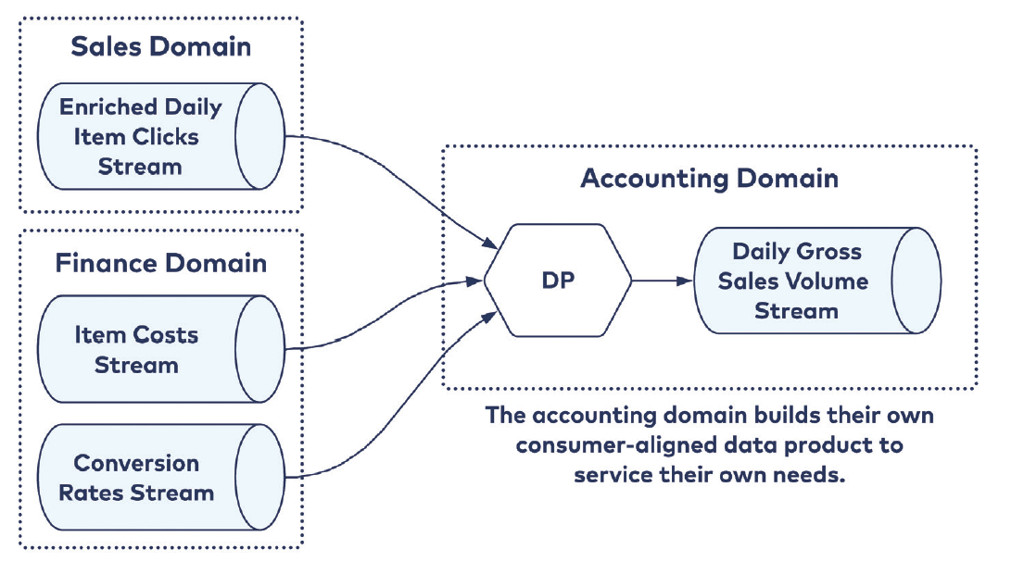
Consumer Aligned
Questi Data Product vengono preparati per servire dei casi d’uso specifici di un determinato consumer.
Nessuna scelta obbligata
Un Data Product Owner non deve necessariamente scegliere fra una di queste modalità di pubblicazione; anzi, ha la possibilità di esporre i propri Data Product in differenti stili in base alle richieste dei vari consumer.
Per le stesse ragioni, ossia in base alle esigenze e alle richieste dei consumer, un Data Product Owner non deve necessariamente rendere accessibili i propri Data Product esclusivamente tramite un solo canale, come nel caso citato in precedenza dei DataWarehouse, dove tutto è stabilito prima di iniziare a popolare e condividere i dati.
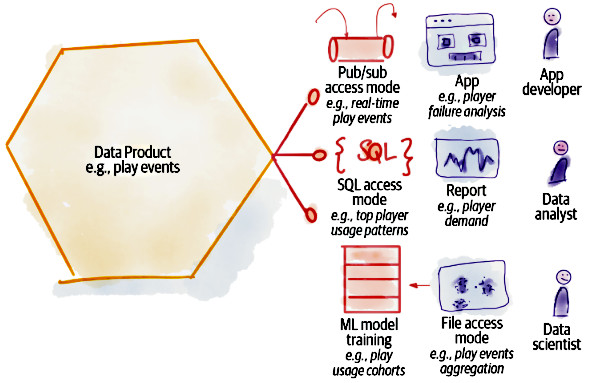
Un singolo Data Product può essere servito attraverso differenti modelli.
- SQL API: i fatti prodotti popolano un database relazionale che potrà essere interrogato, in sola lettura, dai consumer.
- Cloud Storage: i Data Product vengono aggiornati in uno storage a intervalli regolari tramite operazioni calendarizzate.
- Event stream: i consumer possono sottoscrivere un topic per avere informazioni in tempo reale.
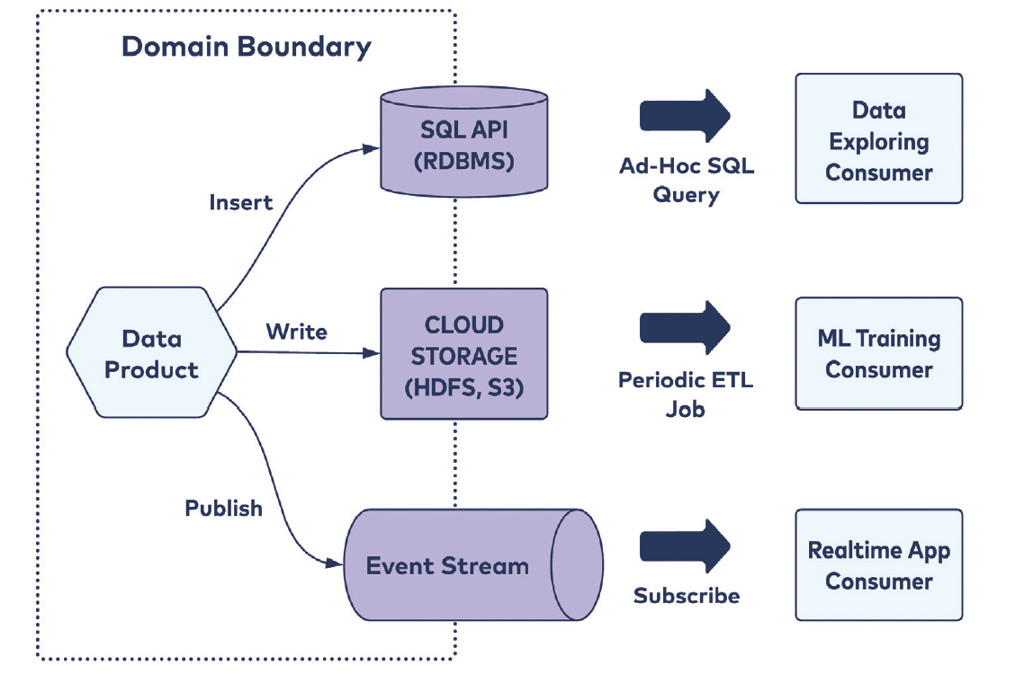
Come già anticipato poco sopra è il Data Product Owner che sceglie come pubblicare i propri Data Product, ma questa scelta sarà fortemente influenzata dall’organo di Federated Governance.
Tutti questi fattori offrono ai consumer la possibilità di utilizzare gli stream per riprodurre e aggregare i fatti emessi dai vari Bounded Context: i nuovi consumer possono partire dall’inizio di ogni stream e ricostruire i loro storici, mentre i consumatori esistenti possono riprodurre gli stream per creare nuove aggregazioni, il tutto in perfetta autonomia, esattamente come consumeremmo gli eventi pubblicati su uno stream per ricreare i nostri Read Model in un’applicazione che gestisce dati operativi.
Indipendentemente dal modo in cui un Data Product Event Stream viene allineato, rimane la necessità di avere a disposizione dei metadati in grado di descriverlo e di validarlo.
Event Schemas e Metadati
L’accesso ai dati analitici è lo scopo per cui esiste il Data Product. Affinché i dati siano utilizzabili, i Data Product mantengono e offrono un set di informazioni sui dati stessi, spesso chiamate metadati. Ad esempio, i metadata possono includere la semantica, la documentazione sul dato, la sintassi. La maggior parte dei metadati cambia quando un Data Product genera nuovi dati. Anche in questo caso, la produzione dei metadati è responsabilità del Data Product: non esistono processi esterni di documentazione, a differenza sempre dei tradizionali approcci.
Conclusioni
Dopo aver visto l’approccio socio–tecnico proposto da Data Mesh negli articoli precedenti, in questo articolo abbiamo visto come è possibile, in una situazione reale, applicare il concetto di Data Product nel rispetto, ovviamente, del resto dei principi del Data Mesh stesso.
Chiaramente siamo all’inizio della storia di questo approccio; e, come la stessa autrice si augura, tanto c’è ancora da scoprire e scrivere. Non esistono, per esempio, degli standard specifici per le API riguardanti i dati analitici — e forse non servono nemmeno — ma esistono pur sempre degli standard per esporre delle API.
Non esiste nemmeno un solo tipo di Data Product, perché, se è vero che ogni dominio è responsabile per i propri Data Product, è pur vero che potrebbe sorgere la necessità di crearne di nuovi; e in nome del principio dell’autonomia, lo stream di eventi è senza dubbio un ottimo alleato.
Riferimenti
[1] Zhamak Dehghani, Data Mesh: Delivering Data-Driven Value at Scale. O’Reilly Media, 2022
[2] Adam Bellemare, Practical Data Mesh: Building Decentralized Data Architectures with Event Streams. Confluent, 2022
https://bit.ly/3XQGbxO
[3] N. Ford, R. Parsons, P. Kua, P. Sadalage, Building Evolutionary Architectures: Automated Software Governance. O’Reilly, 2022
Sono fondamentalmente un eterno curioso. Mi definisco da sempre uno sviluppatore backend, ma non disdegno curiosare anche dall'altro lato del codice. Mi piace pensare che "scrivere" software sia principalmente risolvere problemi di business e fornire valore al cliente, e in questo trovo che i pattern del DDD siano un grande aiuto. Lavoro come Software Engineer presso intré, un'azienda che sposa questa ideologia; da buon introverso trovo difficoltoso uscire allo scoperto, ma mi piace uscire dalla mia comfort-zone per condividere con gli altri le cose che ho imparato, per poter trovare ogni volta i giusti stimoli a continuare a migliorare.
Mi piace frequentare il mondo delle community, contribuendo, quando posso, con proposte attive. Sono co-founder della community DDD Open e Polenta e Deploy, e membro attivo di altre community come Blazor Developer Italiani.