

All we need is data!
Siamo onesti. Oggi tutto ruota attorno ai dati! Raccogliamo dati per migliorare i processi di produzione, per capire quali articoli produrre di più e quali lasciar perdere, cosa mostrare e cosa nascondere in base all’utente che si collega al nostro e-commerce… e potremmo continuare a lungo con esempi simili. Almeno, questo è quello che crediamo di fare noi che sviluppiamo software.
Mi sono occupato a lungo di IIoT (Industry Internet of Things), partecipando allo sviluppo di una piattaforma di raccolta e analisi dati industriali, appunto. Per alcune aziende — poche ma buone — si trattava veramente di raccogliere informazioni dai diversi reparti e cercare di aggregarle per meglio capire quali strategie produttive applicare. Ma per molte altre si trattava più di un modo per assolvere agli obblighi delle normative Industry 4.0 in modo da accedere ai finanziamenti.
Siamo ben lontani da una vera e propria cultura dei dati, per svariate ragioni. Intendiamoci, non è proprio un mercato semplice da gestire. Ci sono, giustamente, leggi a protezione della privacy, a tutela dei dati sensibili, ma il vero problema, è un altro. Da una ricerca della NewVantage [1] — un’azienda specializzata nella leadership aziendale guidata dai dati — emerge che, a fronte di investimenti in crescita, diventare data-driven e costruire una cultura dei dati rimangono ancora solo delle aspirazioni per la maggior parte delle organizzazioni. Manca una vera e propria fiducia nei confronti dei dati dovuta a diversi fattori.
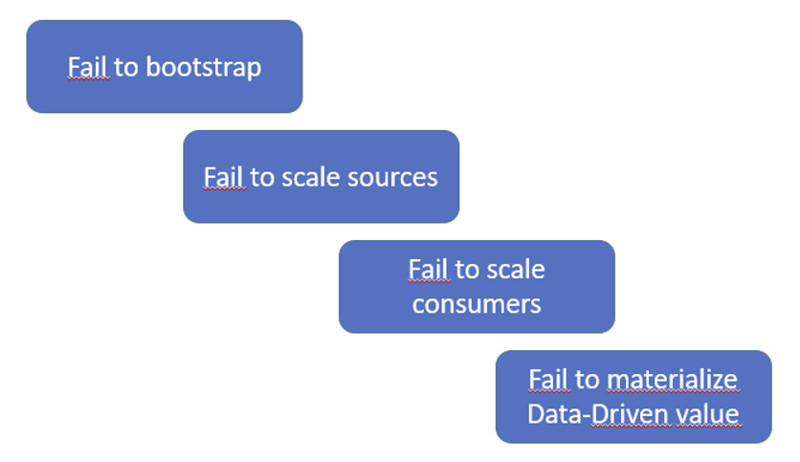
Si fatica a iniziare un percorso vero e proprio di raccolta dati, ma anche dopo che si è partiti, il più delle volte diventa difficoltoso e oneroso mantenere questi progetti. Le richieste di nuove implementazioni, o di modifiche, ricadono nella maggioranza dei casi su un unico team, che si trova subito oberato e fatica a consegnare valore, finendo con il deludere le aspettative e dando vita a un circolo vizioso da cui è difficile uscire.
Cerchiamo allora di capire come risolvere questo problema, con l’aiuto di un nuovo approccio alla gestione dei dati, che molto probabilmente, in molti non si aspettano.
Approcci diversi alla “gestione” dei dati
Probabilmente ai puristi del DDD (Domain-Driven Design) potrà sembrare strano, se non addirittura blasfemo, parlare di gestione dei dati. Per definizione, il dominio non si interessa di “dati”, nel senso lato del termine, ma piuttosto di comportamenti del business da replicare nel codice; come poi vengano salvati i dati prodotti è compito dell’infrastruttura: come dire, è un lavoro secondario, che chiunque può svolgere!
Gli stessi seguaci del DDD però sanno benissimo che, pur essendo alla soglia dei vent’anni, il Domain-Driven Design ha ancora molto da insegnare; oppure, nonostante abbia quasi vent’anni, ancora oggi ci ispiriamo ai pattern esposti nel Blue-Book per risolvere situazioni complicate. In fondo è stato così con i microservizi prima, e i microfronted in seguito, di cui i Bounded Context sono stati eletti pattern di riferimento; eppure, nel 2004, il termine microservice non esisteva proprio, e il termine microfrontend è arrivato assai più tardi. La definizione stessa di microservizio meriterebbe un intero libro, ma non è questo l’argomento del nostro articolo.
Un altro pattern molto caro a chi si occupa di applicare il DDD è l’Ubiquitous Language: nulla è più pericoloso di fraintendere ciò di cui stiamo discutendo! È fondamentale intendersi alla perfezione circa il significato dei termini utilizzati in tutto il processo, dall’esposizione da parte del cliente, con il supporto dei business expert, passando per chi dovrà utilizzare il nostro software, sino ad arrivare a chi lo deve sviluppare e manutenere.
Tutti, ma proprio tutti, si devono intendere alla perfezione quando parlano di qualsiasi concetto che ruota attorno al software che si sta sviluppando; e se un concetto risulta poco chiaro, o ambiguo, ci si deve fermare e chiarire se ancora parliamo della stessa cosa, ma utilizzando parole diverse, oppure, se proprio ci stiamo riferendo sì alla stessa cosa, ma sotto aspetti e comportamenti diversi.
Proviamo a pensare all’utente di un qualsiasi portale web: ne esiste una versione che rappresenta la sua identità, quella che ricalca proprietà e comportamenti tipici per permettergli di autenticarsi e accedere appunto al portale. Ma esiste anche una versione in cui magari acquista, se si tratta di e-commerce, o accede a particolari analisi e report, se si tratta di un portale di statistica; e in questo caso la versione utente che intendiamo avrà proprietà e comportamenti che ci permettono di capire i suoi gusti, rendicontare i suoi acquisti, oppure capire quali statistiche mostrargli e quali nascondere. Due comportamenti completamente diversi dello stesso “utente”, due aggregati e, in questo caso, due Bounded Context. Ma tutto questo cosa ha a che fare con il mondo dei dati?
Dati operativi e dati analitici
Ora provate a pensare al significato della parola “dato”. Cos’è, per noi sviluppatori, il dato?
Dati Operativi
Il dato è l’informazione che salviamo nel database per preservare lo stato del nostro sistema. Salviamo le informazioni dell’utente, quelle necessarie per il login; se abbiamo fatto le cose per bene saranno gestite da un microservizio che si occupa dell’autenticazione, che avrà un suo database, e che sa benissimo come gestire il soggetto “utente” inteso come colui che deve accedere all’applicazione se è in regola con i requisiti necessari.
Ovviamente il microservizio delle vendite avrà la sua copia di “utente”, con altre proprietà e altri comportamenti da gestire. Cos’hanno in comune questi tipi di dati? Sono tutti dati operativi. Per dati operativi intendiamo proprio l’insieme dei dati che ci servono per preservare lo stato dell’applicazione, quei dati che hanno la responsabilità di mantenere lo stato corrente del business. Sono fondamentali per le continue scelte che gli utilizzatori del nostro sistema devono compiere. Mostrano la disponibilità dei prodotti, lo stato degli ordini acquisiti, e altro ancora, inerente appunto al business in cui l’applicazione lavora. Nella realtà quotidiana questi tipi di dati arrivano dagli ERP utilizzati per gestire la produzione, o dai CRM che vengono usati per gestire i clienti.
Ma proprio per la loro natura “specifica”, questi dati non sono affatto utili a chi invece vorrebbe analizzare il sistema nel suo insieme. Magari avere dei report che raffigurino le vendite per fascia di età, per tipologia del prodotto, magari in rapporto appunto allo stato dell’utente (lavoratore, studente, etc.). Un analista ha bisogno di dati che provengono da diverse fonti, per poi aggregarli e ottenere una visione ampia su tutto il sistema e usarli come base per modelli di Machine Learning, oppure per la preparazione di report analitici. Quindi stiamo sempre parlando di dati, ma con un significato diverso; infatti questi sono detti dati analitici.
Dati analitici
I dati analitici rappresentano la visione storica, integrata e aggregata dei dati provenienti da vari fonti. Sono spesso, per non dire praticamente sempre, un prodotto secondario nella gestione aziendale, intendendo con il termine “prodotto secondario” che sono il risultato di complesse pipeline che si occupano, ad intervalli regolari, di scansionare le varie fonti per estrarre ciò che ci interessa aggregare.
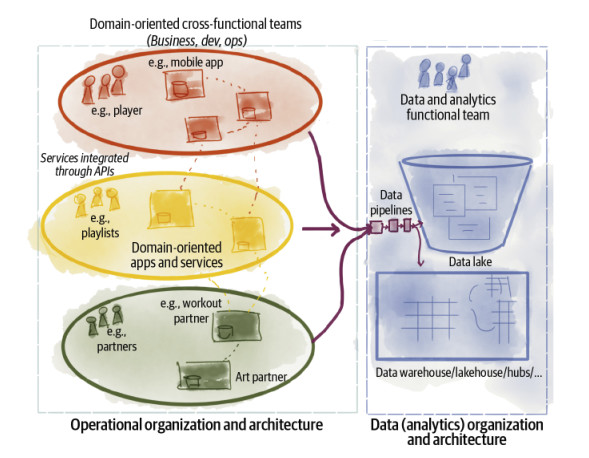
A occuparsi di questi dati troviamo di norma un team, composto per lo più da esperti di statistica, o di Machine Learning, che a sua insaputa si ritrova a dover essere esperto in tutti i settori che coinvolgono l’azienda stessa. Infatti, a fronte di diversi Team che si occupano dell’evoluzione dei software applicativi, ormai tutti progettati secondo architetture a microservizi, nel mondo dei dati ancora si fa riferimento all’unico team di business intelligence.
Limiti alla scalabilità
A questo punto a qualcuno si sarà sicuramente accesa una lampadina, una sorte di deja vu, di film già visto in passato in ambiti diversi.
La premessa sarebbe: “Bisogna voler bene al nostro monolite”, che resta pur sempre la soluzione perfetta per generare e consegnare velocemente valore ai nostri clienti. Ma, d’altro canto, si è ampiamente discusso dei limiti del monolite nell’ambito dello sviluppo software.
In presenza di grandi numeri, per esempio, diventa complicato gestirne la scalabilità; se la progettazione dello stesso non è stata fatta seguendo delle buone pratiche, anche apportare modifiche a singole unità diventa complicato, perché si corre il rischio di romperne altre… Certo — lo so — se non si rispettano le suddette buone regole, con i microservizi si possono avere gli stessi problemi, oltretutto moltiplicati…
E allora che si fa? Passiamo a un’architettura a microdati? In fondo abbiamo già esplorato i microservizi lato backend, i microfrontend per quanto riguarda la UI… non ci resta che provare a rompere i Data Lake e promuovere i microdati.
Potremmo, per esempio, rompere il primo collo di bottiglia a questo vincolo di scalabilità, intervenendo sulle pipeline di aggregazione dati. Già il fatto di non dover dipendere da un solo Team per chiedere la modifica di una pipeline potrebbe aiutare a snellire il lavoro e a renderlo più responsivo nei confronti delle nuove e continue richieste di nuovi report o di modifica a quelli esistenti.
Anziché avere un solo team che si occupa dell’intera pipeline, potremmo creare team diversi che si occupano di raccogliere i dati operativi, aggregarli e servire i dati analitici. Ma sappiamo già, proprio perché lo abbiamo provato altrove, che la decomposizione tecnica, o tecnologica, non è mai la soluzione al problema. Business e tecnologia sono due mondi ortogonali fra loro, non paralleli. Il rischio più grosso, e concreto, è quello di creare team di super specialisti della tecnologia difficili da gestire.
Meglio dunque procedere, come già successo e sperimentato, creando team ortogonali con responsabilità legate alle richieste del business. Team formati da professionisti più generalisti, in grado di intervenire su più livelli dell’infrastruttura, rendendola di fatto, più robusta.
Basandosi proprio su queste constatazioni, e valutando la situazione dal suo lavoro sul campo quotidianamente, Zhamak Dehghani [2] ha provato a rivedere la gestione dei dati nel suo insieme.
Data Mesh
Che cos’è Data Mesh? La definizione ufficiale, quella fornita direttamente dall’autrice Zhamak Dehghani, è
un approccio sociotecnico decentralizzato per la condivisione, l’accesso e la gestione dei dati analitici in contesti complessi e a grande scala, all’interno di un’organizzazione o anche attraverso più organizzazioni
Dimensione organizzativa e “sociale”
Confesso che dopo averla letta non è che io abbia capito esattamente di cosa si trattasse. Però una cosa mi ha colpito subito: “sociotechnical approach”. Qui, infatti, non stiamo parlando solo di un’architettura o di un framework, ma piuttosto di un modo alternativo di gestire il mondo dei dati. In effetti nel libro della Dehghani è presente un’immagine che da sola vale veramente più di mille parole per mostrare l’impatto di Data Mesh sia a livello tecnico che a livello organizzativo (figura 4).
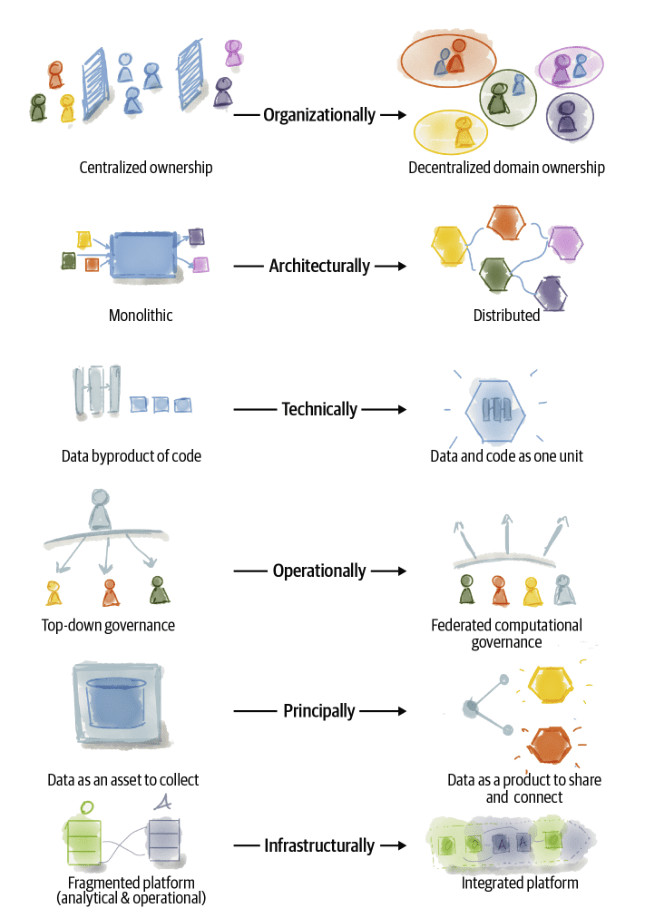
Si parte da una trasformazione dell’organizzazione, a rimarcare che Data Mesh non è un framework, o un’architettura! La gestione centralizzata dei dati da parte di team di specialisti delle tecnologie viene riveduta in nome di un modello decentralizzato che riporta la proprietà, e la responsabilità, dei dati ai settori aziendali da cui i dati sono prodott. Non vi ricorda forse il concetto di Bounded Context?
Dimensione tecnica
Sappiamo tutti però che, senza il supporto di adeguate architetture, i buoni propositi restano tali, un po’ come le diete, che iniziano sempre il lunedì ma poi, se non adeguatamente supportate, finiscono presto. Quale? Il primo cambiamento a livello architetturale, dovuto alla suddivisione delle responsabilità, è la frammentazione degli attuali modelli monolitici (Data Warehouse o Data Lake) in una rete distribuita di Data Product a cui è possibile accedere tramite protocolli standardizzati.
Dal punto di vista più meramente tecnico, questo comporta una nuova visione del dato in sé. Non dovremo più pensare al dato come un dato surrogato, ad un numero che rappresenta il risultato di qualche computazione, ma piuttosto dovremo elevarlo a prodotto vero e proprio, con tutto ciò che questo comporta. Il codice, e il relativo dato, diventano un’unica unità atomica indivisibile.
Governance distribuita
Ovviamente, proprio per effetto dei punti precedenti, la governance del dato non potrà più essere soggetto di un’unica entità, di un unico team, bensì sarà necessario rivedere come distribuire le responsabilità relative ai singoli Data Product distribuiti, senza creare anarchia e confusione.
Tutto questo, per concludere l’analisi dell’immagine (figura 4), senza creare ulteriori costi aggiuntivi all’organizzazione stessa. Lo scopo di Data Mesh è quello di creare una rete di dati, in cui i team possano, in maniera autonoma, intervenire sul loro Data Product, senza dover chiedere l’intervento di altri team, per non ricadere in quello che, lato sviluppo, potremmo definire un monolite distribuito, che è il peggio dei due mondi, monolite vs. microservizio. Quindi sì alla nascita di piattaforme di dati integrate, sotto il cappello di una governance federata, che eleva il dato a prodotto, in modo da consegnare veramente valore a chi lo consuma.
I principi di Data Mesh
È davvero così semplice? È sufficiente creare tanti piccoli Data Lake, ognuno per un dominio, per risolvere in modo definitivo il problema della gestione dei dati? Vista in questo modo Data Mesh sembra un ritorno ai silos di dati ma, proprio come nel mondo dello sviluppo del software il pattern Context Mapping ci aiuta a risolvere i problemi di comunicazione fra i vari sottodomini e a evitare la nascita di silos isolati, anche per Data Mesh la sua autrice Zhamak Dehghani ha descritto quattro principi che ci guidano nella trasformazione. Quali sono questi principi?
- Principle of Domain Ownership
- Principle of Data as a Product
- Principle of the Self-Serve Data Platform
- Principle of Federated Computational Governance
Conclusioni
Data Mesh è un approccio sociotecnico alla gestione dei dati molto interessante e promettente. Nelle prossime puntate andremo a esplorare ognuno dei principi appena esposti, con il supporto di esempi pratici per la loro implementazione.
Riferimenti
[1] Big Data and AI Executive Survey
https://www.newvantage.com/thoughtleadership
[2] Zhamak Dehghani, Data Mesh: Delivering Data-Driven Value at Scale. O’Reilly Media, 2022