

Introduzione
Nel precedente articolo avevamo introdotto l’approccio Data Mesh presentandone rapidamente i principi. È quindi arrivato il momento di entrare un po’ più nel dettaglio e scoprire cosa prevede ogni singolo principio.
È bene però chiarire fin da subito che questi principi assumono valore se, e solo se, vengono considerati nel loro insieme e non presi singolarmente. Personalmente, più li osservo e più si rafforza in me l’idea che in realtà il principio sia solo uno, il Domain-Oriented Ownership, e gli atri tre siano da considerare come dei pilastri che lo sostengono. Ma questo è solo un modo di vedere le cose.
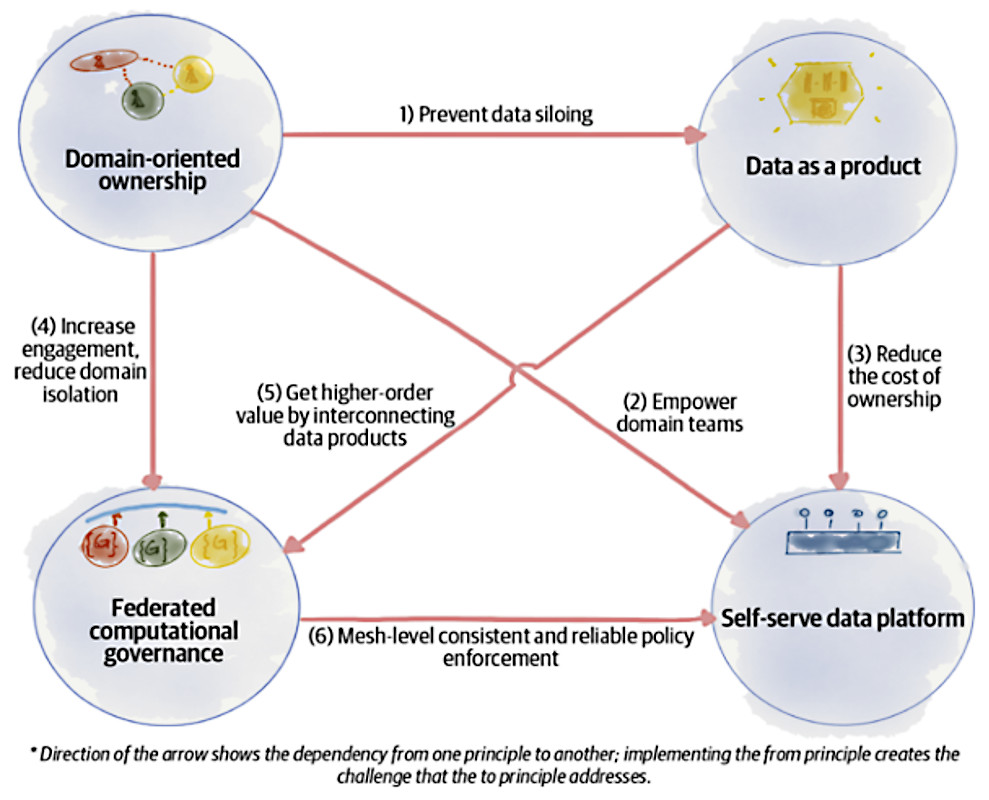
L’idea dell’autrice [1] è quella che i quattro principi siano collettivamente necessari e sufficienti. Matematicamente parlando, ogni principio è una condizione necessaria, ma non sufficiente, e in effetti essi si completano a vicenda, e ognuno affronta e risolve le sfide generate dagli altri.
Infine, prima di procedere, un’ultima nota che potrebbe aiutare nella comprensione dell’approccio fornito da Data Mesh. In Data Mesh è più corretto parlare di pubblicazione dei dati, piuttosto che di importazione, poiché è più importante individuare e utilizzare i dati piuttosto che estrarli e caricarli su qualche DataLake.
Vediamo dunque, nel dettaglio, i quattro principi, che sono
- principle of Domain Ownership (“proprietà del dominio”)
- principle of Data as a Product (“i dati sono un prodotto”)
- principle of the Self-Serve Data Platform (“piattaforma dati self-service”)
- principle of Federated Computational Governance (“gestione dei dati basata su una struttura decisionale di responsabilità federata”)
Principle of Domain Ownership
È il principio che più di tutti si ispira al DDD, in particolare al concetto di dominio espresso proprio da E. Evans. In senso stretto un domain comprende una serie di dati omogenei rispetto ad alcuni criteri che possono essere l’origine, l’aggregazione e il consumo degli stessi. Il modo in cui si individua un dominio non è argomento di questo articolo, ma sappiate che in DDD sono accuratamente descritti i pattern da utilizzare per assolvere a questo delicato compito, che cito come promemoria: Ubiquitous Language, Bounded Context, Context Mapping.
A noi interessa sottolineare che in questo approccio ci sono diversi aspetti che rivoluzionano il tradizionale modo di raccogliere dati. Innanzitutto, il processo di gestione dei dati viene posto sotto la ownership di un team interdisciplinare di attori tutti operanti nella sfera di competenza di questi dati, proprio a rimarcare l’influenza del DDD in questo approccio.
Il risultato, rispetto a un modello a Data Lake che normalmente vede il coinvolgimento di tutti i dati operativi in un unico ambiente, è una riduzione dell’entropia informativa derivante dal fatto che le figure che presidiano il Data Lake, come già espresso in precedenza, non possono essere esperti di tutti i domini interessati. Di questo parleremo anche in uno dei prossimi principi del Data Mesh.
Ci sono diverse motivazioni a supporto di questo principio:
- capacità di mantenere allineate la crescita di un’organizzazione con la condivisione dei dati; si assiste a un aumento del numero delle fonti di dati, un aumento del numero dei consumatori di questi dati e un aumento della diversità dei casi d’uso di consumo degli stessi;
- ottimizzazione del cambiamento continuo grazie alla localizzazione del cambiamento nei domini aziendali;
- supporto all’agilità riducendo la necessità di sincronizzazione tra i team; infatti si rimuovono i colli di bottiglia grazie a un team centralizzato per la raccolta dati che fa riferimento a un unico Data Lake;
- aumento della resilienza delle soluzioni di machine learning, rimuovendo complesse pipeline intermedie di raccolta e trasformazione dati.

Come al solito, non è tutto oro quello che luccica! Scomponendo i dati per dominio si corre il rischio di creare dei silos, con la possibilità di compromettere l’integrazione e la coerenza complessiva. Proprio per questo motivo ci vengono a supporto gli altri principi, o pilastri, del Data Mesh.
Principle of Data as a Product
Se, a livello di sviluppo del software, il Context Mapping risolve il rapporto di comunicazione fra i vari Bounded Context, il principio di “dati come prodotto” indica la modalità con cui i singoli domini interagiscono per garantire una gestione fluida ed efficiente dei processi aziendali.
Cosa si intende per Data as a Product? Il Data Product è un oggetto che va oltre la raccolta di dati, come potrebbe essere un database. Zhamak Dehghani lo definisce come “a new unit of architecture” intendendo con questa definizione l’insieme di tutti i componenti necessari a ottenere, e manutenere, il dato: l’infrastruttura, il codice necessario a generare il dato stesso, e i relativi metadati che lo descrivono.
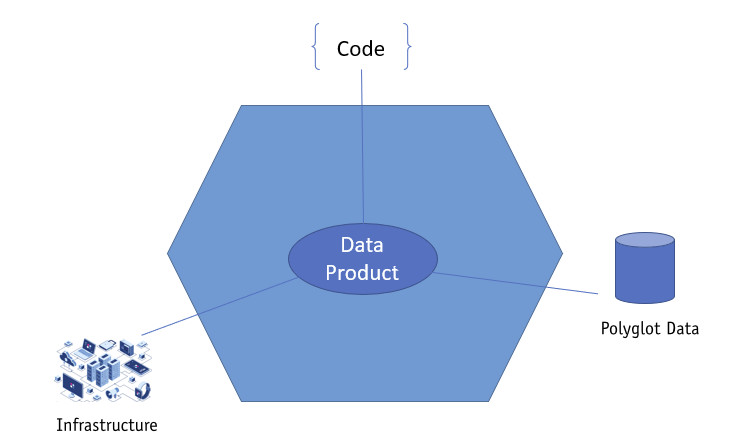
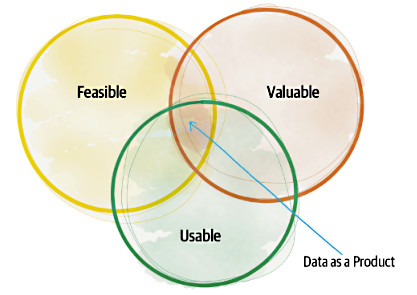
Il concetto di fondo è quello di trattare il dato non come il risultato di una computazione da comunicare agli altri, ma di elevarlo al grado di prodotto, con tutto ciò che questo comporta. Innanzitutto, trattandosi di prodotto, la Dehghani si interroga su quali siano le caratteristiche che un prodotto deve avere per essere definito un prodotto di successo, partendo dal concetto espresso da Marty Cagan nel suo libro Inspired [2] In cui afferma che un prodotto è di successo se è fattibile, se è utilizzabile e se ha valore (figura 4).
L’autrice passa poi in rassegna altri principi per scoprire cosa rende di successo un prodotto, per arrivare a definire un set minimo di caratteristiche di base, non negoziabili, che un Data Product deve incorporare per essere considerato utile (figura 5).
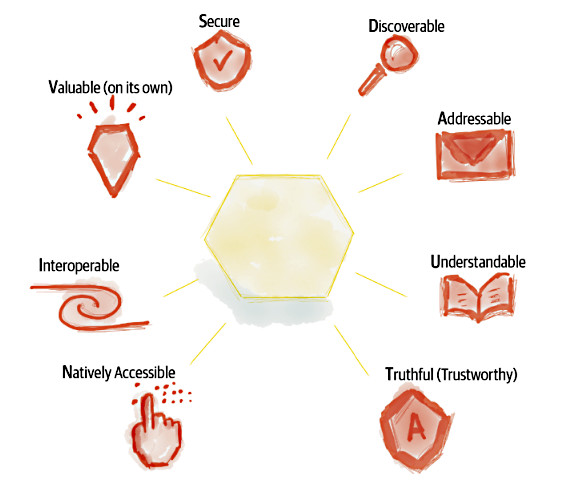
Da notare, fra gli altri, il fatto che il Data Product, nel suo insieme, dev’essere affidabile. Ancora una volta, il DDD influenza pesantemente questa rivoluzione nel trattamento dei dati. Infatti la fiducia deriva dal fatto che il team che produce il dato è lo stesso team che lavora quotidianamente all’interno del Bounded Context di riferimento per il Dato stesso, non un team di specialisti dell’infrastruttura, ma un gruppo di specialisti di quell’area di riferimento.
Nuovamente, l’adozione di questo principio, come nel caso degli altri, comporta l’accettazione di alcune trasformazioni a livello organizzativo, oltre che tecnico. In particolare, i passi da seguire in questo caso sono:
- prendere coscienza che il dato non è un asset generato da una computazione, ma che il dato è un vero e proprio prodotto da condividere;
- il dato non è quindi un semilavorato, o la parte di di un prodotto terzo, ma è il prodotto;
- infine, non più il dato al servizio del codice, ma codice e dato insieme a formare una nuova “unit of architecture”.
Principle of the Self-Serve Data Platform
Se con il secondo principio si intende evitare la nascita di silos isolati di informazioni, con questo principio si intende dare origine a una nuova generazione di servizi di piattaforma di dati che consentono ai team cross-funzionali di dominio di condividere i Data Product stessi.
In questa nuova concezione di piattaforma di dati troviamo i servizi che sono incentrati sull’eliminazione degli attriti che ci possono essere nel percorso end-to-end della condivisione stessa dei dati, dal producer al consumer. Questi servizi gestiscono una rete affidabile di Data Product interconnessi, che possono essere consumati per la generazione di report, sia in forma lineare che in forma di grafi, o come sorgenti per modelli di machine learning. Fra gli scopi di questa tipologia di piattaforme vi è proprio la semplificazione dell’esperienza utente nello scoprire, accedere a e utilizzare i Data Product.
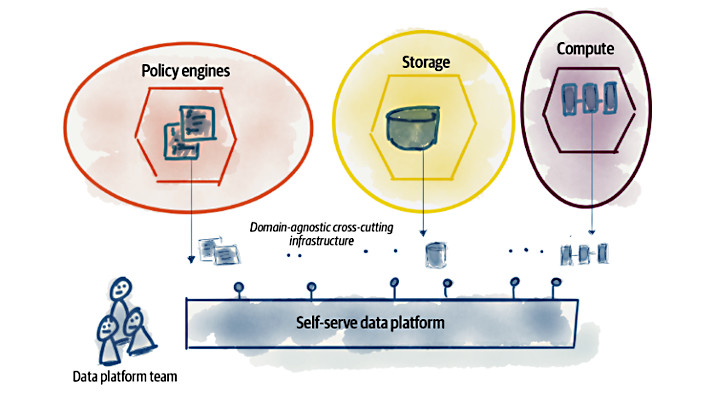
Questo è il principio che più di tutti ha l’obiettivo di eliminare gli attriti attualmente esistenti al cambiamento e all’innovazione. In effetti, se un unico team si deve sobbarcare l’onere di gestire le continue richieste di integrazione e/o modifica degli attuali report, o degli attuali modelli di Machine Learning, va da sé che la fiducia nell’utilizzare i dati come strumento di indagine o di predizione per alcune strategia aziendali viene meno per il rallentamento che questo team introdurrà una volta inondato da richieste da tutti i settori.
Mettendo a disposizione i Data Product tramite standard condivisi, ogni team o, se preferite, ogni Bounded Context, potrà liberamente aggregare i dati secondo nuove richieste in tempi decisamente più rapidi.
Nello sviluppo di un’applicazione software, una figura importante nella gestione delle continue richieste da parte degli stackholder è il Product Owner. È proprio a questa figura che si demandano le responsabilità di prioritizzare le richieste di avanzamento e/o modifica di un prodotto. Allo stesso modo, nel mondo di Data Mesh, troviamo infatti la figura del Data Product Owner, e sarà proprio questa figura l’unica autorizzata a richiedere al team cambiamenti o nuove implementazioni relative al Data Product.
Ovviamente esistono più motivazione che portano ad adottare questo principio, ma tutte con l’obiettivo di semplificare il consumo del dato:
- ridurre il costo totale della proprietà decentralizzata dei dati;
- astrarre la complessità della gestione dei dati e ridurre il carico cognitivo dei team di dominio nella gestione del ciclo di vita dei Data Product;
- mobilitare una generazione di sviluppatori più generalista della tecnologia per lo sviluppo di Data Product, riducendo la necessità di specialisti;
- automatizzare le politiche di governance per creare standard di sicurezza e di conformità per tutti i Data Product.
Principle of Federated Computational Governance
Questo è il principio che più di tutti richiede una trasformazione a livello organizzativo, ed è forse quello che, in molte realtà, potrebbe essere il più difficile da applicare.
La distribuzione della conoscenza, ossia la distribuzione del dato analitico, comporta una distribuzione delle responsabilità, sia in termini di sicurezza che in termini decisionali. Se queste responsabilità venissero lasciate ad ogni team, è chiaro che si andrebbe verso una totale anarchia con conseguente aumento dell’entropia della gestione e dell’accesso ai dati: esattamente ciò che Data Mesh si prefigge di eliminare.
Questo principio nasce proprio con lo scopo di evitare questo problema e per risolverlo propone la creazione di un modello operativo di governance dei dati basato su una struttura decisionale di responsabilità federata, grazie ad un team composto da rappresentati di ogni dominio. Questo modello operativo crea una struttura di incentivi e responsabilità che mantiene l’equilibrio tra l’autonomia e l’agilità dei domini con l’interoperabilità globale della rete e l’affermazione delle politiche di gestione di ogni Data Product.
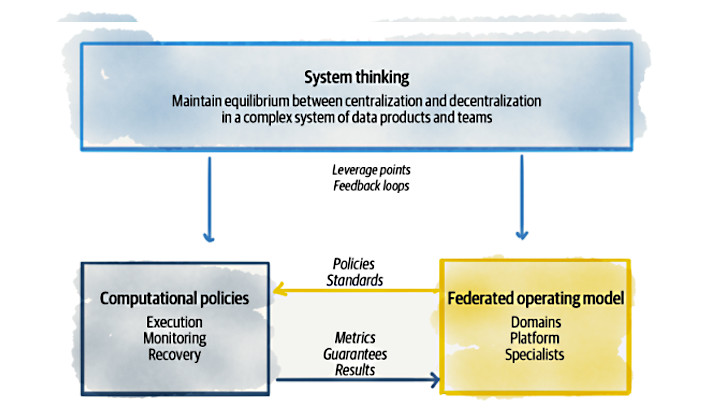
Anche in questo caso, i motivi che portano all’adozione di questo principio sono molteplici:
- la capacità di ottenere un valore di ordine superiore dall’aggregazione e dalla correlazione di prodotti di dati indipendenti, ma interoperabili;
- il contrasto alle conseguenze indesiderate della decentralizzazione orientata al dominio, quali incompatibilità e disconnessione dei domini;
- la possibilità di inserire requisiti di governance trasversali — come la sicurezza, la privacy, la conformità legale — in una rete di Data Product distribuita;
- la riduzione dell’overhead della sincronizzazione manuale tra i domini e la funzione di governance.
Conclusioni
Abbiamo analizzato nel dettaglio i principi alla base di Data Mesh che, come anticipato, non riguardano solamente un diverso approccio tecnologico al problema della gestione dei dati, ma soprattutto una nuova visione della distribuzione delle responsabilità che ruotano attorno ad esso.
Se, da un lato, si prende coscienza che per snellire i processi che portano a consumare i dati bisogna delegarne la relativa produzione e gestione, dall’altro bisogna evitare la nascita di strutture anarchiche e disconnesse che renderebbero i dati di poco valore, ottenendo esattamente il risultato opposto a quello desiderato.
Come sempre, la trasformazione tecnologica è relativamente semplice, e raramente rappresenta un impedimento in senso assoluto; ma Data Mesh implica una trasformazione socio-tecnica importante e invasiva dell’intera catena del dato stesso. Ed è qui che le Aziende si dovranno confrontare per adottare o meno questa nuova visione.
Riferimenti
[1] Zhamak Dehghani, Data Mesh: Delivering Data-Driven Value at Scale. O’Reilly Media, 2022
[2] Marty Cagan, Inspired: How to Create Tech Products Customers Love. 2nd ed., Wiley, 2017
Sono fondamentalmente un eterno curioso. Mi definisco da sempre uno sviluppatore backend, ma non disdegno curiosare anche dall'altro lato del codice. Mi piace pensare che "scrivere" software sia principalmente risolvere problemi di business e fornire valore al cliente, e in questo trovo che i pattern del DDD siano un grande aiuto. Lavoro come Software Engineer presso intré, un'azienda che sposa questa ideologia; da buon introverso trovo difficoltoso uscire allo scoperto, ma mi piace uscire dalla mia comfort-zone per condividere con gli altri le cose che ho imparato, per poter trovare ogni volta i giusti stimoli a continuare a migliorare.
Mi piace frequentare il mondo delle community, contribuendo, quando posso, con proposte attive. Sono co-founder della community DDD Open e Polenta e Deploy, e membro attivo di altre community come Blazor Developer Italiani.