

Progettare per l’evoluzione
Il primo passo per poter progettare un’architettura evolutiva è disegnare il nostro software in modo che possa evolvere facilmente. Già, facile a dirsi, non proprio facile a farsi.
Cosa significa disegnare un sistema che possa evolvere facilmente con le continue richieste del Cliente? Proviamo a partire dal classico codice legacy. Spesso sento associare il termine “codice legacy” a un applicativo vecchio, che ha bisogno di essere riscritto con un framework nuovo, con nuove tecnologie e linguaggi attuali per essere adattato alle nuove richieste. Niente di più sbagliato. Un codice può essere legacy anche se scritto la settimana scorsa. Ciò che caratterizza un codice legacy è il fatto che l’applicativo in questione è importante per l’azienda, è profittevole, ma la sua manutenzione, o evoluzione, è complicata a causa dell’alta dipendenza degli oggetti al suo interno, al punto che modificarne uno comporta il rischio di dover modificare l’intero progetto, e questo, ovviamente, spaventa chiunque.
Come sempre, Domain-Driven Design ci viene incontro. Il modo migliore per rendere un applicativo semplice da manutenere è dividerlo in tanti piccoli moduli, non necessariamente microservizi, ognuno associato a un’area del business specifica; e per questo abbiamo visto come i pattern strategici, Ubiquitous Language e Bounded Context in particolare, ci siano di grande supporto. Ma sono sufficienti? Il Bounded Context rappresenta comunque un’area abbastanza grande del nostro modello di business; quindi, il rischio di trovarci a maneggiare qualcosa di complesso rimane. E infatti, non a caso, E. Evans ha presentato anche una serie di pattern tattici, molto più orientati allo sviluppo dell’applicativo, che non alla sua comprensione e suddivisione. Non staremo a elencare tutti i pattern tattici, che potete trovare nel libro di Evans, ma ci focalizzeremo su quelli che ci interessano di più per realizzare un applicativo che possa durare nel tempo, ed essere manutenuto senza troppi patemi.
Aggregate
Fra tutti i pattern tattici, quello che ci interessa analizzare è l’aggregato. L’aggregato è la rappresentazione semplificata del modello di business che ci prefiggiamo di risolvere. È un pattern complesso e fondamentale, all’interno del Domain-Driven Design. È composto da una, o più, Entity, e da uno, o più, Value Object.
Detto così sembra quasi semplice disegnare un Aggregato, in realtà è una delle fasi più complesse del processo di sviluppo. Essendo una rappresentazione semplificata del modello di business, dovrà mantenersi il più possibile vicino al modello di business reale; ora, senza entrare troppo in discorsi filosofici, il nostro software riuscirà a risolvere i problemi del business in questione fintanto che i due modelli non divergono troppo. Vale a dire, fino a quando, qualsiasi richiesta che arriva dal nostro cliente può essere implementata nel nostro codice.
Ma quindi siamo tornati al punto di partenza? Assolutamente no. L’aggregato non è solo un contenitore di proprietà che descrivono la realtà, ma implementa tutti i metodi necessari per descriverne il comportamento, e tutto ciò che riguarda il particolare problema che risolve passa da lui, e da nessun altro punto all’interno della nostra applicazione. A questo punto è facile capire che, qualsiasi modifica fatta su questo aspetto del business all’interno del nostro codice coinvolge soltanto questo aggregato, senza andare a influenzare altri parti del codice. Ogni aggregato è un piccolo mondo isolato, che dovrà certo comunicare con gli altri, e vedremo tra poco in che modo, ma non dipende da altri per prendere le sue decisioni e validarle secondo le regole di business implementate, ossia i suoi invarianti.
Le comunicazioni all’interno dell’Aggregate
Per garantire questo isolamento l’unico modo che abbiamo per comunicare con gli oggetti all’interno di un aggregato è quello di passare da una Entità molto particolare, che prende il nome di Aggregate Root, o Entity Root. Nel classico esempio di un ordine di vendita, composto dalla testa e dalle righe, non potremo accedere liberamente alle righe per modificarle, ma dovremo passare dalla testa dell’ordine, indicata come Aggregate Root, che si occuperà di invocare i metodi esposti dalle righe per apportare le modifiche richieste, e al termine delle modifiche, l’aggregate root, ossia la testa dell’ordine, verificherà che le regole di business, o invarianti, siano state rispettate. Ad esempio, che il nuovo totale dell’ordine non superi il budget del cliente.
Facilitare la manutenzione e coerenza dei dati
Concentrare tutti i comportamenti in un solo punto del codice è strategico per la sua manutenzione. Ridurre l’area di intervento dell’aggregato ci aiuta a mantenere uniformità e coerenza attorno al problema che affronta e a ridurre la complessità del nostro codice al solo problema in questione. E cosa dire della coerenza dei dati? Il fatto che l’aggregate root verifichi, a ogni variazione di stato dell’aggregato, che le regole di business siano rispettate, ci garantisce dati coerenti. Non a caso, l’aggregato deve trovarsi sempre in uno stato consistent, sin dalla sua prima istanza. Tecnicamente parlando, un aggregato con una factory senza parametri non si può vedere in un dominio degno di questo nome! E qui cominciano i primi problemi di dimensionamento.
Il dimensionamento dell’Aggregate
Se facciamo un aggregato troppo grande, ci portiamo in casa più complessità e più concorrenza. Sarà più facile, infatti che diverse richieste debbano essere gestite da questo aggregato, che si troverà costretto a gestire molte invarianti, le regole di business; quindi, il codice risultante non sarà facile da manutenere, perché necessariamente complesso. Molto probabilmente però ne guadagneremo in termini di consistency: avendo allargato l’area di intervento, molti più dati resteranno coerenti fra loro a ogni cambio di stato.
Contrariamente, se il nostro aggregato sarà piccolo, perderemo in “consistenza”, ma guadagneremo in complessità e concorrenza.
Un esempio pratico? Provate a pensare alla prenotazione di un posto in una multisala. Se il nostro aggregato è la programmazione giornaliera, avremo una forte “consistenza” dei dati, perché avremo tutto il necessario all’interno dell’aggregato stesso, ma avremo anche molta concorrenza. L’aggregato dovrà occuparsi di gestire le sale con i titoli in programma, i posti disponibili, gli orari, etc.
Se invece il nostro aggregato è la sala, allora il tutto sarà molto più semplice. L’unica serie di comandi che dovremo gestire saranno quelli relativi alla prenotazione dei posti per lo slot di una proiezione. Potremmo scendere ancora? Certamente, potremmo promuovere ad aggregato la fila.
Cosa conviene fare? Qual è la scelta migliore? Ovviamente dipende! Fermo restando che non esistono aggregati troppi piccoli, non bisogna nemmeno esagerare e portarsi a casa un sovraccarico di lavoro, spesso non necessario.
Domain Event
Ora che abbiamo capito come isolare i comportamenti del business per realizzare applicazioni più mantenibili, come facciamo a far comunicare fra loro i singoli aggregati?
Se gli aggregati appartengono tutti allo stesso Bounded Context, la cosa è piuttosto semplice. Ogni aggregato ha il proprio aggregate root, incaricato di mantenere i rapporti con il mondo esterno, quindi, un Domain Service che si occuperà di farli dialogare sarà più che sufficiente. Ma quando un aggregato deve far sapere ad altri aggregati, al di fuori del proprio Bounded Context, che il suo stato è cambiato, come fa?
E a questo punto che interviene un altro pattern. Il Domain Event. Prima di addentrarci nel parlare di questo pattern, vediamo di capire, in poche parole, di cosa si tratta. Un Domain Event ha due caratteristiche principali. Per prima cosa, esprimono fatti che sono già accaduti, qualcosa che è già successo nel passato, e per questo motivo il nome di un domain event è sempre espresso utilizzando il participio passato. La seconda caratteristica è che un domain event è immutabile! Non può essere modificato in nessun caso, proprio perché esprime qualcosa che è successo nel passato e, come nella vita reale, ciò che è successo non si può cambiare, al massimo possiamo compensarlo con qualche azione correttiva.
I domain event sono eventi che appartengono al modello di dominio, e qui cominciamo a entrare nel vivo della questione. Non possono essere distribuiti a chiunque. Una domanda per capire se un evento è un evento di dominio potrebbe essere: “Questo evento interessa ai domain expert?”. Se la risposta è “sì”, allora è un evento di dominio.
Ora che abbiamo chiarito le caratteristiche del domain event, ci potremmo chiedere come mai non erano presenti nel libro di Evans? La risposta reale, ovviamente, non la conosco! Sicuramente gli eventi hanno importanza nel momento in cui da monolite si passa a sistema distribuito, ossia quando si entra nel mondo delle architetture a eventi. In un sistema distribuito, dove appunto i vari pezzi del nostro sistema non devono essere reciprocamente accoppiati fra loro, lo scambio di messaggi diventa la soluzione. L’arrivo dei microservizi, e di questa tipologia di architetture, ha decretato il successo dei Domain Event. Quando si parla di eventi all’interno di Domain-Drive Design non si può non pensare al pattern CQRS+ES introdotto da Greg Young.
CQRS
CQRS (Command Query Responsibility Segregation) è l’evoluzione del pattern CQS (Command Query Separation) di Bertrand Meyer, autore del linguaggio Eiffel, e uno dei padri della OOP, che aveva appunto teorizzato la netta separazione fra un’azione che modifica i dati all’interno del database (Command), da una che legge i dati presenti nel database stesso.
La prima è autorizzata a modificare lo stato di un record, ma non necessariamente deve restituire un risultato, se non il fatto che l’operazione è andata, o meno, a buon fine. La seconda, al contrario, non deve assolutamente apportare modifiche al dato, ma deve limitarsi a restituire i dati che corrispondono alla query di interrogazione. Se nessuno apporta modifiche, la query deve sempre restituire lo stesso risultato (idempotente).
L’innovazione di Greg Young a questo pattern è stata la netta separazione del database nelle due fasi, di scrittura e di lettura, del dato. Il punto di partenza è che se un database è ottimizzato per la scrittura, allora non lo sarà per la lettura, e viceversa. Come spesso accade, un’immagine vale più di mille parole.
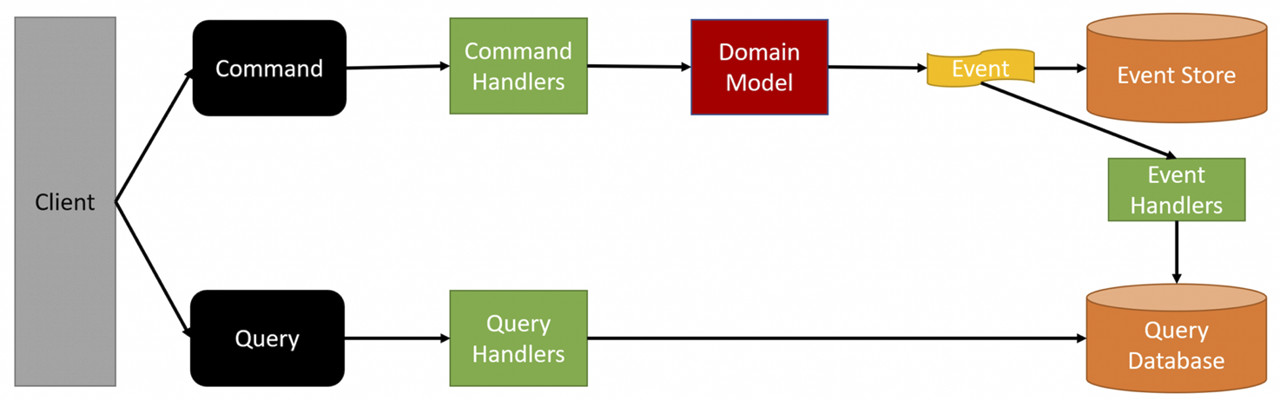
Per essere certi di essere allineati sui principi base di questo pattern, vediamo di esplicitare il significato di figura 1 prima di proseguire.
- Dal Client viene inviato un Command per la richiesta di una variazione di stato del nostro Aggregato. Un esempio potrebbe essere “CreaOrdineDiAcquistoDaPortale”. Il nome del comando dovrebbe esplicitare chiaramente l’intento del business.
- Il Command viene gestito appunto da un CommandHandler. Questo componente si occupa di invocare i metodi descritti all’interno del nostro Domain Model (in pratica il nostro Aggregato). Ricordiamoci che il Domain Model non contiene soltanto le proprietà del nostro oggetto (saremmo di fronte a un Dominio Anemico), ma anche l’implementazione dei comportamenti di business, concretamente, i metodi per gestire le sue variazioni di stato.
- Il Domain Model si prende in carico il Command e, se l’azione richiesta viola le regole di business, ha la facoltà di respingerlo. Ad esempio, il totale dell’ordine viola il budget del Cliente. Al termine dell’azione associata al Command il Domain Model emette un Domain Event. Ricordate che se il vostro sistema è totalmente asincrono, il Domain Model deve emettere un Domain Event sia in caso di successo, sia in caso di fallimento, altrimenti la vostra UI non verrà mai avvertita dell’accaduto.
- Del Domain Event emesso viene effettuata la persistenza nell’EventStore. Non è strettamente obbligatorio salvare l’evento nell’EventStore ma, se vogliamo lavorare con aggregati basati sugli eventi, lo diventa; altrimenti non potremmo più ricostruire lo stato dello stesso a ogni richiesta di variazione di stato. Così come non è necessario avere due database diversi per eventi e Read Model. Per restare semplici è possibile utilizzare un solo database per entrambi gli scopi.
- Lo stesso Domain Event viene pubblicato in modo che tutti i servizi, all’interno del Bounded Context, che sono interessati a ricevere notifica dalla variazione di questo Domain Model, possano effettuare l’iscrizione per per aggiornare il ReadModel, ossia il modello che serve per le interrogazioni, query, del Client.
- Qualsiasi query che arriva dal Cliente andrà a agire sul ReadModel, che conterrà diverse projection in base alle necessità della nostra UI.
Domain Event
Il Domain Event è parte, a tutti gli effetti, del modello di dominio, ed è una rappresentazione di ciò che è successo nel dominio stesso. In pratica, anziché limitarci a salvare lo stato del nostro aggregato, ne salviamo le singole variazioni di stato, espresse appunto tramite il Domain Event. Ogni volta che dovremo intervenire sull’aggregato per applicare un nuovo comando, o per decidere di rifiutarlo perché in contrasto con le regole di business, andremo a rileggere tutti gli eventi relativi a questo aggregato, li applicheremo in maniera sequenziale, sino a ottenere la versione attuale dello stesso. Come mi piace spesso ripetere, è un pò come passare dall’osservare una fotografia del nostro aggregato — lo stato attuale — a osservare il suo film, che ci racconta come è arrivato a trovarsi in questo stato.
Non a caso i Domain Event, come abbiamo già detto, vengono identificati con nomi al passato, proprio perché ciò che esprimono è già successo! Nessun altro elemento all’interno del nostro sistema può permettersi di questionare al riguardo. Questo comportamento ci garantisce flessibilità, e tranquillità, quando andremo a implementare nuovi comportamenti, o a modificare quelli esistenti, all’interno del nostro codice. Tutta la logica di business è racchiusa nel nostro Aggregato, e non distribuita in diversi layer, o servizi, sparsi nella nostra codebase. Perciò, una volta apportate le modifiche, e verificato che i nostri test continuino a essere verdi, potremo tranquillamente rilasciare la nuova versione, con la certezza che non andremo a rompere nulla al di fuori del nostro Bounded Context.
Chiunque sottoscrive un Domain Event lo accetta così com’è, senza inserire nel codice clausole decisionali.
Come è fatto un Domain Event
Ma com’è fatto un Domain Event? Si tratta di un DTO che contiene le proprietà che sono cambiate all’interno del nostro aggregato, e una sua implementazione in C# potrebbe essere questa (figura 2)
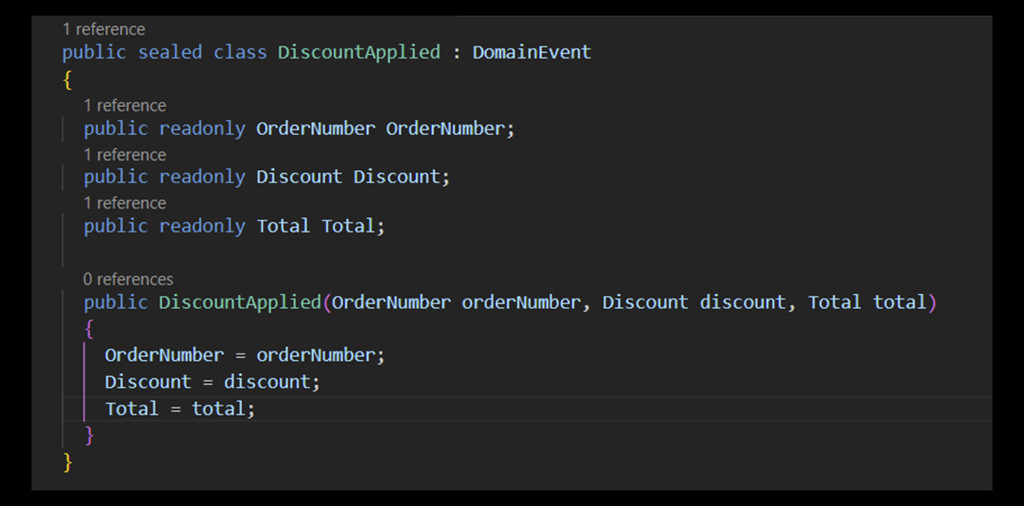
Proviamo a analizzare questo codice. Innanzitutto, è una classe sealed, il che significa che nessuno la può ereditare, e quindi espandere, all’interno del codice. Tutte le sue proprietà sono readonly. Il motivo è molto semplice. Per essere inviato alle parti interessate, il nostro Domain Event verrà serializzato, in fase di invio, e poi deserializzato, in fase di ricezione. Durante queste fasi, nessuno può intervenire a modificarne il suo contenuto. Dobbiamo essere certi che ciò che esce dal nostro dominio arrivi integro a destinazione. I più attenti si saranno accorti di un’altra importante caratteristica: la semantica utilizzata all’interno del Domain Event. È possibile notare che, per esprimere le grandezze delle proprietà, non vengono utilizzati tipi primitivi, ma tipi customizzati che rispecchiano il linguaggio del business in questione, ossia l’Ubiquitous Language. Se definisco il numero di ordine con un tipo string, o UUID, solo i tecnici saranno in grado di capirlo, e quindi di validare, o meno, il mio Domain Event. Se invece utilizzo il tipo custom Order Number, tutti i membri del team capiranno di cosa stiamo parlando, abbattendo tutte le barriere di comunicazione fra persone di business e persone tecniche, riducendo la possibilità di fraintendimento, e quindi di produzione di codice non esattamente conforme alle specifiche, al minimo.
Modellare l’Aggregato in relazione alla realtà
Quando modelliamo il nostro Aggregato, ossia il modello di business che ci accingiamo a risolvere, vogliamo restare il più conformi possibile alla realtà, e avere un linguaggio comune, lo abbiamo già detto e ripetuto, è fondamentale. Ovviamente dovremo semplificare dei concetti, perché è impossibile replicare un modello reale all’interno del nostro codice. Per non rischiare di divergere troppo è fondamentale creare aggregati il più piccoli possibile, per rimanere il più vicino possibile alla realtà. Un po’ come considerare l’intero processo di business una figura geometrica complessa, di cui non siamo in grado di calcolarne la superficie, se non suddividendola in infinite parti che integreremo al fine di ottenere un risultato finale non proprio esatto (non riusciremo mai a replicare la realtà), ma sicuramente molto, molto simile. Sufficientemente simile per schematizzare e risolvere il problema stesso.
Infine, ma non meno importante, ogni Domain Event contiene l’ID dell’aggregato a cui appartiene, e l’eventuale ID delle operazioni a esso correlate; essendo queste proprietà ripetute per ogni Domain Event è bene raggrupparle in una classe DomainEvent che ci aiuta sia a semplificare la scrittura di tutti i domain event, sia a capire, solo guardando il codice, se l’oggetto che stiamo osservando è un Domain Event!
Chi può sottoscrivere un Domain Event?
A questo punto dobbiamo chiederci quali sono le parti interessate a sottoscrivere un Domain Event, chi ne è legittimato. Trattandosi di un elemento del Dominio stesso, non può, e non deve, uscire dal nostro Bounded Context! Nell’immagine relativa al pattern CQRS/ES, abbiamo visto che il Domain Event serve per aggiornare il nostro Read Model, ossia la parte di dati che poi gli utenti della nostra applicazione andranno a interrogare per prendere decisioni. In un sistema distribuito, queste informazioni possono essere ridondate e replicate in diversi Read Model, ognuno in Bounded Context differenti, e potenzialmente, in microservizi differenti, ossia, database differenti. Quale strumento utilizziamo per aggiornare tutti questi Read Model che non appartengono al nostro Bounded Context? La risposta del programmatore pigro è: “Il Domain Event”, ed è qui che il nostro sistema, in un batter d’occhio, si trasforma da Distribuito, a Big Ball of Mud.
![Figura 3 – Schema del Domain Event (da Vernon [1])](https://www.mokabyte.it/wp-content/uploads/2024/03/architettureevolutive-5_fig03.jpg)
Condividere un Domain Event con altri Bounded Context comporta un errore dal punto di vista semantico, ossia sto condividendo informazioni espresse in un linguaggio tipico di un Bounded Context con un altro che non è detto condivida lo stesso linguaggio, fermo restando che nel Domain Event ci potrebbero essere informazioni che non devono uscire proprio da questo contesto per essere condivise.
Ma c’è un errore anche dal punto di vista più implementativo e, rifacendoci a quanto detto nella parte 4 di questa serie a proposito delle Evolutionary Architecture, nel momento in cui due parti di codice condividono qualcosa, ci troviamo di fronte a un accoppiamento, e quindi possiamo dire addio alla facoltà di evolvere in maniera indipendente a ognuno di esse. Gli aggregati, come già detto, sono una rappresentazione della realtà, uno schema semplificato del problema di business da risolvere.
I problemi di business, essendo problemi legati agli esseri umani, sono per loro natura mutevoli, e in quanto tali, prima o poi, evolveranno in modo tale da non poter più essere rappresentati dal nostro aggregato, che dovremo far evolvere per soddisfare il nuovo modello. Non si tratta di un errore di modellazione iniziale, o di una prematura ottimizzazione! Semplicemente dobbiamo accettare che le cose cambiano! Lo so che molti di voi stanno cercando riferimenti all’interno del concetto di antifragilità dei sistemi di Taleb, e in effetti è proprio così.
Ne abbiamo parlato quando abbiamo introdotto appunto le Architetture Evolutive; la sfida non è costruire un sistema perfetto, ma un sistema in grado di evolvere, di adeguarsi ai cambiamenti continui, di modificare anche una sua piccola parte per adeguarsi alle nuove necessità. Forse risulta molto più evidente perché condividere il nostro Domain Event va esattamente nella direzione opposta a questa.
Prima di essere considerato un errore semantico, va analizzato come un errore architetturale. Se il contratto con cui scambio informazioni con gli altri modelli è lo stesso che utilizzo al mio interno per mantenere la coerenza fra Domain Model e Read Model, allora non mi potrò permettere il lusso di poter modificare il mio aggregato a piacimento, perché così facendo andrei a modificare il contratto di comunicazioni con gli altri Bounded Context, che sarei costretto ad avvisare, e che dovranno essere aggiornati e pubblicati, in caso di architettura a microservizi, in concomitanza con il Bounded Context modificato, pena l’incapacità di comunicare a causa proprio della variazione del Domain Event condiviso. E di colpo ci siamo portati in casa la complessità dei sistemi distribuiti, con i limiti del monolite accoppiato, in sintesi, abbiamo creato la perfetta Big Ball of Mud.
Integration Event
Ma allora come avviso il “resto del mondo” che lo stato del mio Bounded Context è stato modificato? Utilizzando appunto un Integration Event, ossia un evento che dal punto di vista tecnico è assolutamente identico al Domain Event, ma che conterrà informazioni che possono essere condivise, espresse in un linguaggio comune a tutti i Bounded Context del mio sistema.
Ma se i dati del Domain Event e dell’Integration Event sono esattamente gli stessi? Non importa, pubblico ugualmente un Integration Event, perché sicuramente, prima o poi, il Domain Event cambierà, e noi potremo permetterci di farlo perché saremo certi che viene consumato solamente all’interno del nostro Bounded Context, e potremo continuare a emettere lo stesso Integration Event all’esterno, senza interrompere la condivisione di informazioni con il resto del sistema.
In questo modo avremo garantito l’indipendenza delle parti del nostro sistema, che potranno evolvere liberamente, senza attendere il benestare delle altre.
Versioning
Cosa succede se, a causa appunto di una nuova richiesta, il nostro Domain Event deve cambiare? Se, ad esempio, dobbiamo aggiungere, o togliere, una delle proprietà?
Innanzitutto, dobbiamo capire se si tratta veramente di una variazione, e quindi è sufficiente aggiungere delle proprietà, ma il significato espresso del nostro Domain Event resterà invariato; in questo caso saremo veramente di fronte a una modifica dello stesso, a una nuova versione. Se invece le modifiche saranno talmente invasive, da modificare il significato semantico del nostro Domain Event, allora saremo di fronte a un nuovo Domain Event, probabilmente con un nome diverso, in grado di comunicare il nuovo intento del business.
Fatte le dovute premesse, va comunque detto che un Domain Event non deve mai essere modificato! Nuovamente, le ragioni sono sia semantiche che tecniche. Dal punto di vista semantico, il Domain Event, ormai lo abbiamo imparato, esprime un concetto di business, e noi vogliamo che questo concetto resti invariato nel nostro EventStore e nel nostro Domain Model. Dal punto di vista tecnico, abbiamo detto che il Domain Event viene prima serializzato, e poi deserializzato; quindi, se modifichiamo la sua struttura dopo averlo salvato rischiamo di non essere più in grado di recuperare gli eventi dall’EventStore, quindi di ricostruire lo stato del nostro Aggregato, quando dovremo deserializzare gli eventi salvati.
Come si risolve questa situazione? Versionando gli eventi. Avremo quindi la versione V1, V2, … Vn. del Domain Event che è cambiato nel tempo. Attenzione, ricordiamoci, a patto che il suo significato, dal punto di vista del business, resti invariato, altrimenti dovremo proprio rinominarlo. Nel caso in cui avremo più versioni dello stesso evento, dovremo prevedere nel nostro codice tutti gli handler per tutte le versioni, oppure un handler in grado di catturarli tutti, valorizzando, laddove necessario, le proprietà mancanti con valori standard. La gestione del versioning è una questione complessa, un ottimo libro [2] al riguardo lo sta scrivendo, da anni, proprio Greg Young, e vale certamente la pena di essere letto.
Conclusioni
Da programmatore pigro, se devo condividere informazioni fra Bounded Context diversi, appartenenti a microservizi diversi, sono molto tentato di farlo tramite un qualcosa che nel mio codice esiste già, in questo caso un Domain Event. Non devo fare altro che aggiungere un altro eventhandler allo stesso topic e il gioco è fatto.
Purtroppo, non sto commettendo solamente un errore semantico, ossia sto condividendo informazioni scritte in un linguaggio tipico di un Bounded Context, con altro Bounded Context che non necessariamente conosce questo linguaggio … altrimenti non parleremmo di Ubiquitous Language! Senza trascurare il fatto che in un Domain Event, essendo un oggetto che appartiene al Domain Model, ci possono essere informazioni riservate, che non devono uscire dal confine del Bounded Context stesso. Perché non si tratta solamente di un errore semantico? Perché nel momento stesso in cui due funzioni condividono un oggetto, un qualsiasi oggetto, queste ultime risultano essere accoppiate fra loro, e nel momento in cui dovrò modificarne una, sarò costretto a modificare anche l’altra, con buona pace all’indipendenza dei microservizi che le ospitano. Provate voi, ora, a pubblicare il vostro microservizio, in seguito all’implementazione di una nuova feature che ha modificato il Domain Event, senza avvisare tutti i relativi sottoscrittori allo stesso!
Anche se le informazioni da scambiare, in un primo momento, sono esattamente le stesse contenute nel Domain Event, create un Integration Event e condividete quello. Con un piccolo sforzo avrete guadagnato la libertà di intervenire sul vostro Domain Model come vorrete, senza dover renderne conto a nessuno, e si sa, la libertà non ha prezzo!
Riferimenti
[1] Vaughn Vernon, Implementing Domain-Driven Design. Addison-Wesley Professional, 2013
[2] Greg Young, Versioning in an Event Sourced System
https://leanpub.com/esversioning/read