

Architettura evolutiva
Che cos’è un’architettura evolutiva? Troppo spesso l’architettura del nostro applicativo software viene paragonata all’architettura di un edificio. Come a dire, se non hai le giuste e solide fondamenta, non puoi costruirci sopra quello che vuoi; devi decidere prima di partire con i lavori se intendi costruire una casa su di un solo piano, oppure un condominio, oppure ancora un capannone. Non puoi partire con una casetta e finire con un edificio a 5 piani!
Allo stesso modo ci sentiamo ripetere questo discorso all’inizio di un progetto. Il mio applicativo dovrà essere in grado di gestire migliaia di connessioni contemporaneamente, ma non mi dovrà costare un patrimonio in risorse nei giorni in cui nessuno lo usa. Insomma, dovremmo progettare una casetta, ma all’occorrenza trasformarla in un grattacielo, e poi, nuovamente in una casetta se tutti escono. È possibile?
La risposta ovviamente è sì, altrimenti di cosa staremmo parlando? Una Evolutionary Architecture è un tipo di architettura che supporta il cambiamento guidato, incrementale e soprattutto su più dimensioni.
Detto così vuol dire tutto e niente, ma proviamo ad analizzare le proprietà che abbiamo appena elencato e vediamo che soluzioni potremmo mettere sul tavolo.
Per proporre una evoluzione guidata abbiamo bisogno necessariamente dei test, che ci garantiscano che, ad ogni evoluzione, il tutto continui a funzionare, e non c’è dubbio che fare test in un monolite è nettamente più semplice che testare un sistema distribuito a microservizi.
Già, ma così facendo, poi come posso garantire la scalabilità e la crescita su più dimensioni? Allora partiamo con i microservizi. In questo caso però ci portiamo in casa, sin dall’inizio, parecchia complessità accidentale, come direbbe il buon Fred Brooks [1] e non vogliamo partire con un carico aggiuntivo sin dall’inizio. Mai come in questo momento la frase di Warren Buffet
Risk comes from not knowing what you are doing
ci piove addosso come un macigno, e se pensate che investire tempo per cercare una buona architettura sia costoso, provate a iniziare con una pessima architettura…
Ma procediamo con ordine.
Cambiamento guidato
Come abbiamo detto, se vogliamo essere certi di poter continuamente apportare modifiche alla nostra soluzione, per adattarla alle nuove esigenze e/o specifiche, allora dobbiamo prima attrezzarci con una seria batteria di test che ci possa garantire che, ad ogni cambiamento, non introduciamo errori.
Ma che tipo di test può essere quello in grado di garantire che a livello architetturale, i miei cambiamenti non saranno distruttivi? Non posso certo fare affidamento solo agli unit test: quelli mi servono per le funzionalità di business, e vanno benissimo per quelle, ma non per il resto.
Posso forse affidarmi al Behavior-Driven Development (BDD)? No! Con questo tipo di test posso testare il comportamento verso l’esterno, garantire che il mio sistema si comporti esattamente come previsto a livello di funzionalità; ma, per quanto riguarda la dimensione architetturale, non mi garantiscono alcun tipo di copertura. Esiste un altro tipo di test, nato prima in ambito sistemistico, rivolto agli operatori DevOps più cha noi sviluppatori, per testare che le prestazioni del sistema restino garantite al crescere del suo utilizzo, per monitorare lo stato di salute tramite log centralizzati e alert su eventuali malfunzionamenti, e cose simili. Questo tipo di test ricorre sotto il nome di Fitness Functions.
Fitness Functions
Dal punto di vista di uno sviluppatore, una fitness function verifica quanto la nostra soluzione sia vicina a quanto desiderato, quanto “fitta” le specifiche che un solution architect ha previsto. Ma perché abbiamo bisogno di un test per questo? Sarà compito del solution architect monitorare questi aspetti ed eventualmente richiamare il Team se qualcosa non viene rispettato. No! Se vogliamo garantire la massima flessibilità nell’evoluzione di un sistema, l’unico modo è automatizzare il più possibile tutte le fasi che precedono il suo rilascio in produzione.
Nessuno vuol fare il guardiano del faro. Gli sviluppatori devono sentirsi liberi di apportare le modifiche necessarie al sistema, senza che nessuno stia tutto il giorno ad osservare il loro lavoro; saranno i test nelle pipeline di compilazione e rilascio che diranno loro se hanno svolto un buon lavoro, oppure se devono rivedere qualche parte perché ha violato le specifiche architetturali previste.
Ricordiamoci che in architettura è più importante il perché di una scelta, e non il come la si implementa. Chi si occupa dell’architettura deve porre l’attenzione, ed essere in grado di giustificare, perché ha fatto certe scelte; come queste verranno implementate sarà una scelta del Team di sviluppo, a patto che questo si possa muovere in un terreno protetto da test.
Scendendo nel concreto, a livello di codice abbiamo a disposizione due librerie di test che ci possono aiutare. A chi utilizza il framework .NET, Ben Norris mette a disposizione NetArchTest [2]; un pacchetto che ci permette di scrivere test sfruttando delle fluent API. Un esempio di come applicare questi test alla soluzione a moduli vista in precedenza lo potete trovare su GitHub [3],
Questa libreria è inspirata a ArchUnit [4], che è invece pensata per coloro che sviluppano in Java.
Un esempio
Di seguito un esempio, molto semplice ma altrettanto efficace, di implementazione di un test di questo tipo. Vogliamo garantire che il progetto Sales.Facade, punto di ingresso al nostro modulo Sales non abbia dipendenze dirette con gli altri moduli del sistema. Perché abbiamo bisogno di questo test? Perché vogliamo essere certi che, se un domani il nostro modulo Sales evolverà in un microservizio autonomo, non avremo problemi ad estrarlo da questa soluzione, proprio perché non avrà nessuna dipendenza diretta con il resto dei progetti presenti nella soluzione.
[Fact]
public void Should_SalesArchitecture_BeCompliant()
{
var types = Types.InAssembly(typeof(ISalesFacade).Assembly);
var forbiddenAssemblies = new List<string>
{
"BrewUp.Sagas",
"BrewUp.Purchases.Facade",
"BrewUp.Purchases.Domain",
"BrewUp.Purchases.Messages",
"BrewUp.Purchases.ReadModel",
"BrewUp.Purchases.SharedKernel",
"BrewUp.Warehouses.Facade",
"BrewUp.Warehouses.Domain",
"BrewUp.Warehouses.Messages",
"BrewUp.Warehouses.Infrastructures",
"BrewUp.Warehouses.ReadModel",
"BrewUp.Warehouses.SharedKernel",
"BrewUp.Production.Facade",
"BrewUp.Production.Domain",
"BrewUp.Production.Messages",
"BrewUp.Production.Infrastructures",
"BrewUp.Production.ReadModel",
"BrewUp.Production.SharedKernel",
"BrewUp.Purchases.Facade",
"BrewUp.Purchases.Domain",
"BrewUp.Purchases.Messages",
"BrewUp.Purchases.Infrastructures",
"BrewUp.Purchases.ReadModel",
"BrewUp.Purchases.SharedKernel"
};
var result = types
.ShouldNot()
.HaveDependencyOnAny(forbiddenAssemblies.ToArray())
.GetResult()
.IsSuccessful;
Assert.True(result);
}
Incremental
Ora che abbiamo risolto il nodo della crescita guidata, vediamo di capire come risolvere la questione della crescita incrementale. Ad essere onesti non abbiamo molto da dire, in quanto il tema è ben sviluppato parlando di architetture modulari.
Intanto bisogna precisare che le architetture modulari, di cui tanto si parla ultimamente, non sono affatto una novità. Nel lontano 1971, infatti, David Lorge Parmas [5] della Carnegie Mellon University descriveva dettagliatamente i vantaggi di un’architettura a moduli, riassumendo in tre principali aree: quella manageriale, quella della flessibilità del prodotto e quella della comprensibilità.
- Manageriale: i tempi di sviluppo dell’intero sistema potrebbero essere ridotti perché team separati potrebbero lavorare a moduli diversi con poca necessità di comunicare.
- Flessibilità del prodotto: è molto più semplice, e soprattutto meno invasivo, apportare modifiche a un singolo modulo, indipendente dagli altri, che non all’intero sistema. Su questo punto vale la pena ricordare cosa si intende per sistema legacy. Non si tratta di un sistema scritto con framework e/o linguaggi vecchi, ma di un sistema che è ancora molto utilizzato in azienda, (ossia “rende soldi”), ed è però complicato da evolvere o modificare perché il codice al suo interno è fortemente accoppiato e non testato.
- Comprensibilità: poter affrontare il sistema un modulo alla volta aiuta a comprenderlo meglio, quindi a proporre una soluzione migliore.
Tutto questo ben prima di Domain–Driven Design e di tutti gli approcci “moderni” ora conosciuti.
Coesione vs. accoppiamento
In un’architettura a moduli ogni modulo deve essere assolutamente indipendente dagli altri, il che significa che non ci deve essere nessun tipo di accoppiamento statico fra i moduli stessi. Se devo far dialogare fra loro due moduli, lo farò tramite messaggi. All’interno di ogni modulo invece gli oggetti possono anche essere dipendenti gli uni dagli altri; in questo caso parleremo di coesione più che di accoppiamento, questo perché tutti i componenti del modulo si suppone servano alla soluzione di quella parte di problema del sistema.
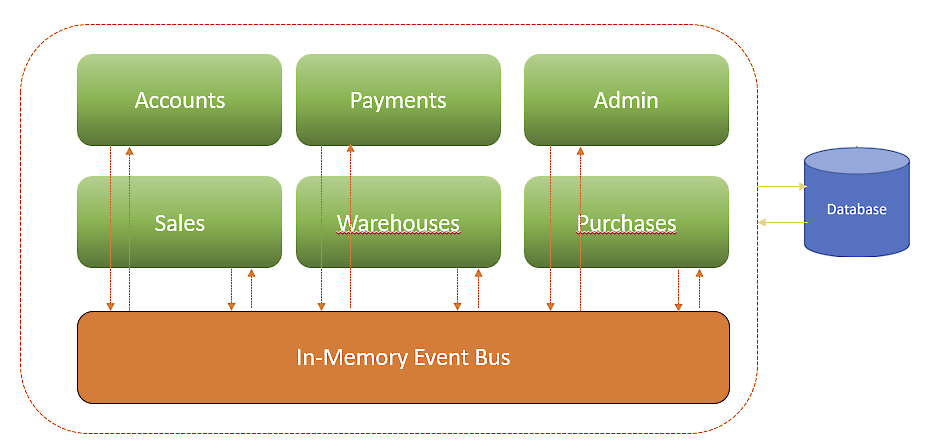
Le caratteristiche dell’architettura modulare
Osservando l’immagine possiamo capire alcuni vantaggi che un’architettura simile ci offre rispetto a una soluzione a microservizi. Intanto il Service Bus per la comunicazione fra i moduli può essere in memoria. Questo ci toglie la necessità di dover subito affrontare l’inserimento di un Broker esterno per lo scambio delle informazioni, ma allo stesso tempo predispone il sistema a utilizzare questo pattern per mantenere il corretto isolamento. Non dobbiamo nemmeno pensare a diverse istanze di database; possiamo utilizzare un solo motore per il database, ma all’interno di esso avere uno schema per ogni modulo. Ancora una volta, meno complessità accidentale, in favore di una soluzione pragmatica alla complessità essenziale.
Non sto dicendo che passare da questa soluzione a quella a microservizi non comporti nessun lavoro; sto dicendo che sarà innanzitutto possibile, perché appunto ogni modulo è separato logicamente dagli altri, sia per quanto riguarda la comunicazione, che la persistenza dei dati. Certo, ci dovremo attrezzare con unBroker per i messaggi, perché la soluzione in memoria non sarà più possibile; ma in fase iniziale saremo molto più veloci a fornire al cliente una soluzione funzionante.
Non dimentichiamo che testare un monolite è decisamente più facile che non testare un sistema distribuito e, se dobbiamo modificare il contenuto dei moduli, spostando oggetti da un modulo a un altro a seguito di una nuova scoperta sul dominio complessivo, lo potremo fare con un po’ più di serenità in un monolite rispetto a un sistema distribuito.
Come realizziamo una soluzione a moduli nella pratica? Un esempio scritto in C# lo trovate su GitHub [6]
Multiple Dimensions
Vediamo di analizzare anche l’ultima delle proprietà di un’architettura evolutiva, ossia la crescita in più direzioni. Perché ogni sviluppatore serio ha paura dei sistemi distribuiti?
La risposta semplice è: perché, se cercate, su un motore di ricerca oppure su ChatGPT, risposte riguardanti un’architettura software che faccia al caso vostro, non troverete risposte, se non una serie di pattern applicabili. Già, ma quali applico nel mio caso? E soprattutto come li applico?
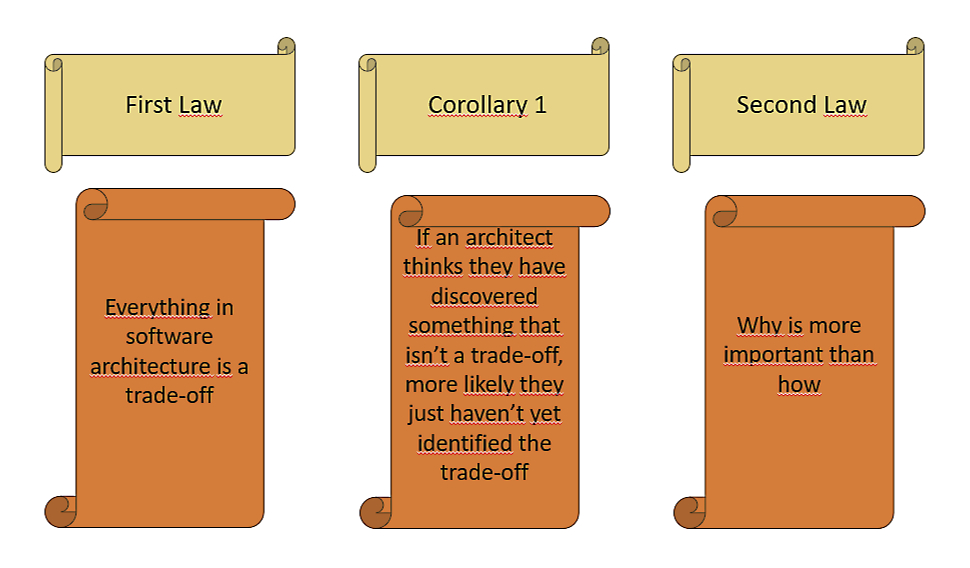
Ricordate la seconda legge delle architetture software? Il “Perché” è molto più importante di “come”. Ebbene, se c’è una seconda legge, significa che ci deve essere anche una prima legge. E infatti esiste e recita che, quando si tratta di architettura software, tutto è un compromesso, e se qualcuno pensa di aver trovato una soluzione che non ha compromessi… semplicemente non ha ancora trovato il compromesso.
Scalare: come e in che direzione?
Garantire la crescita su più dimensioni comporta non solo dover affrontare il tema di una codebase scalabile e facilmente mantenibile. Per questo sappiamo di avere a disposizione i test, a tutti i livelli, dagli Unit Test sino ai test End–to–End.
Ma un sistema distribuito degno di questo nome deve poter scalare se le circostanze lo richiedono, e quando diciamo scalare intendiamo che deve essere quanto meno elastico, ossia deve scalare verso l’alto, ma anche verso il basso quando non è sotto stress. Trattandosi poi di sistema distribuito avremo bisogno di monitorare tutti i servizi, per garantire che siano in salute e che non compromettano il funzionamento dell’intero sistema.
E qui scoperchiamo un’altra pentola. Cosa succede se il rilascio di un microservizio danneggia l’intero sistema? Non dico nel caso di un monolite distribuito, ossia la peggior soluzione che possiamo adottare. Supponiamo pure che ogni microservizio sia indipendente, implementi soltanto una parte dell’intera logica di business, abbia il proprio database per la persistenza e comunichi solo scambiando messaggi. Se uno di questi microservizi cadesse, gli utenti potrebbero continuare a utilizzare la nostra applicazione? Oppure il tutto crollerebbe?
Gli impatti delle modifiche
Se ripensiamo ora all’articolo di Fred Brooks [1], forse cominceremmo a pensare che la complessità accidentale non è proprio destinata a diminuire. Potrà commutare, ma sicuramente occuperà sempre una parte importante nel nostro sistema.
Per essere certi che la parte di business su cui stiamo lavorando come Team sia effettivamente autonoma dovremmo essere certi che anche l’impatto a livello applicativo lo sia. Ma allora, se ci pensate bene, il solo Bounded Context non è più sufficiente, abbiamo bisogno di espandere il concetto di isolamento. Come recitano gli autori di Software Architecture: The Hard Parts [7]:
Bounded Context is not Enough!
Nelle applicazioni distribuite, la garanzia che il rilascio di un microservizio non sia d’ostacolo al resto del sistema è fondamentale. Provate a pensare all’applicazione di Netflix. Può capitare che all’avvio non ci appaia la riga delle serie che stavamo guardano, oppure dei film consigliati in base alla nostra esperienza, ma non che l’applicazione non funzioni. Magari certi servizi si caricano in ritardo e appaiono in un secondo momento, ma non si blocca l’intera applicazione.
Questo risultato è il frutto di anni di applicazione di fitness functions come Chaos Engineering al ciclo di sviluppo. In questo modo siamo in grado di rispettare la crescita del nostro sistema in termini di funzionalità, ma anche in termini di scalabilità multidimensionale, appunto. In questi termini il Bounded Context da solo non è sufficiente a garantire l’indipendenza di un microservizio, perché ci sono aspetti che esulano dai pattern del Domain–Driven Design, ma che non possiamo trascurare quando ci occupiamo di sistemi distribuiti.
Architecture Quantum
Di Architecture Quantum ho sentito parlare per la prima volta leggendo il libro Building Evolutionary Architecture [8] . “Quantum” si riferisce a un “manufatto” distribuibile in modo indipendente, con un’alta coesione funzionale, un alto accoppiamento statico e un accoppiamento dinamico sincrono. In poche parole, un microservizio ben strutturato, dalla persistenza alla UI, all’interno di un flusso di lavoro.
L’idea alla base è proprio quella di poter distribuire un artifact che sia completamente indipendente dagli altri e, nel caso appunto di malfunzionamento, non impedisca all’intero sistema di continuare a funzionare. Magari non avremo accesso ad alcune funzionalità, ma di certo non saremo completamente bloccati.
Un architecture quantum misura diversi aspetti della topologia e del comportamento dell’architettura software, proprio come richiesto da un’architettura evolutiva, relativi al modo in cui le parti in gioco si collegano e comunicano fra loro.
Static Coupling
Rappresenta il modo in cui le dipendenze statiche si risolvono all’interno dell’architettura tramite contratti. Queste dipendenze includono il sistema operativo, i framework e/o le librerie utilizzate per lo sviluppo del sistema, e qualsiasi altro requisito operativo necessario al funzionamento del quantum.
Dynamic Coupling
Rappresentano il modo in cui i quanta comunicano a runtime, in modalità sia sincrona che asincrona. Per questo tipo di accoppiamento si applicano fitness function di monitoring delle prestazioni e dello stato di salute.
Princìpi
Ci sono dei principi da rispettare che ci supportino nello sviluppo delle evolutionary architectures? Ovviamente ci sono, e proviamo a riassumerli di seguito.
Last Responsible Moment
Per quanto procrastinare sia un’operazione difficile in certi casi, in questo caso non solo è consigliabile, ma è anche salutare. Dobbiamo rimandare la decisione sull’architettura, ma in genere su qualsiasi punto critico del nostro sistema, all’ultimo momento utile. Dobbiamo cercare di raccogliere quante più informazioni possiamo, dobbiamo ridurre al minimo l’ignoranza verso il sottodominio che stiamo affrontando, prima di decidere perché prendere quella decisione.
Architect and develop for evolvability
Se il principio è progettare prima, e sviluppare dopo, con un occhio di riguardo alle possibilità evolutive del nostro sistema, allora prima lo dobbiamo capire. Non possiamo cambiare un sistema che non si capisce. Quindi torniamo al punto “Problem Space vs Solution Space”: non dobbiamo aver fretta di abbandonare il Problema Space!
Postel’s Law
Il “principio di robustezza”, o legge di Postel, afferma “Sii conservatore in ciò che invii, sii liberale in ciò che accetti”. In pratica ci dice di essere molto cauti nel cambiare il formato della struttura dei dati che inviamo verso l’esterno, per non dover obbligare il mondo a seguire le nostre evoluzioni, e al contempo ad essere un po’ più flessibili in ciò che invece ci viene inviato.
Conway’s Law
Forse una delle leggi più conosciute. “Le organizzazioni che progettano sistemi sono costrette a produrre progetti che sono copie delle strutture di comunicazione delle organizzazioni stesse”.
Conclusioni
Le Evolutionary Architecture sono un argomento molto vasto, di cui abbiamo solo scalfito la superficie, giusto per capire come strutturare il refactoring di un’applicazione esistente, o l’inizio di un nuovo progetto. I libri che ho citato sono una fonte inesauribile di pattern e dettagli sull’argomento, e rappresentano, a mio avviso, un must-to-read per chiunque voglia approfondire il discorso.
Una domanda, a questo punto, sorge spontanea. Un monolite può essere considerato come Architecture Quantum? Per alcuni aspetti sì, siamo in presenza di un forte accoppiamento statico, caratteristica richiesta, ma meno di una alta coesione funzionale. Difficilmente, all’interno di un monolite, troviamo la divisione delle responsabilità attorno ai problemi di business; quasi sempre la parte di business logic è condivisa da tutti i sottodomini.
Un monolite modulare si avvicina molto a un “quantum”, ma attenzione alla dipendenza verso il database: se è unico allora non lo è; se ogni modulo ha il proprio schema avremo più possibilità di essere autonomi nelle scelte progettuali, ma attenzione alle dipendenze verso la UI. In breve, un sistema distribuito si presta meglio a essere organizzato a “quanta” rispetto a un monolite.
Riferimenti
[1] Frederick P. Brooks Jr., No Silver Bullet. Essence and Accident in Software Engineering. 1986
https://worrydream.com/refs/Brooks_1986_-_No_Silver_Bullet.pdf
[2] NetArchTest
https://github.com/BenMorris/NetArchTest
[3] I test applicati, su GitHub
https://github.com/BrewUp/BrewUp.ModularArchitecture/tree/Day1-StrategicPatterns-WithTests
[4] ArchUnit
https://www.archunit.org/
[5] David Lorge Parnas, On the criteria to be used in decomposing systems into modules. CMU-CS-71-101, 1971
https://prl.khoury.northeastern.edu/img/p-tr-1971.pdf
[6] Modular Architecture su GitHub
https://github.com/BrewUp/BrewUp.ModularArchitecture
[7] N. Ford – M. Richards – P. Sadalage – Z. Dehghani, Software Architecture: The Hard Parts. O’Reilly Media, 2021
https://bit.ly/3T6ptJP
[8] N.Ford – R. Parsons – P. Kua – P. Sadalage, Building Evolutionary Architectures, 2nd edition. O’Reilly Media, 2022
https://www.oreilly.com/library/view/building-evolutionary-architectures/9781492097532/