

Capire i problemi e/o trovare le soluzioni
Tra le tante frasi attribuite in modo apocrifo ad Albert Einstein, c’è quella che dice: “Se avessi a disposizione un’ora per salvare il mondo, utilizzerei 55 minuti per definire il problema e solo 5 minuti per trovare le soluzioni”.
Volendo “tradurre” in poche parole questa affermazione, potremmo dire che il problem space è l’insieme di tutti i problemi che il nostro applicativo software dovrebbe risolvere, mentre il solution space è l’insieme di tutte le soluzioni che risolvono ogni dato problema.
Se il mio docente di informatica sosteneva che la scrittura del codice era l’ultima fase — e su questo non concordo pienamente nemmeno oggi — la mia docente di matematica sosteneva che, per risolvere un problema, bisogna prima comprenderlo a fondo: inutile studiare a memoria tutto. Era talmente avanti che ti permetteva di consultare il libro durante l’esame di analisi; ma, nonostante questo, passare il suo esame era un incubo!
Problem space
Come esseri umani abbiamo la tendenza a essere dei problem solver: così sostengono Allen Newell e Herbert Simon nel loro libro Human Problem Solving [1], e questo lo vediamo quotidianamente nel lavoro di team mentre sviluppiamo software. Abbiamo la tendenza a cercare, e a trovare, una soluzione il più velocemente possibile; tendiamo a uscire dal problem space nel minor tempo, come se ci trovassimo a disagio stando in quella zona. Il problem space è il luogo in cui risiedono le necessità dei nostri clienti, è la zona che ci permette di acquisire maggiori informazioni sui problemi che i nostri clienti ci chiedono di risolvere tramite il software che svilupperemo per loro. Essenzialmente, questo spazio costituisce le fondamenta sulle quali poggerà lo spazio delle soluzioni. Restando nell’ambito della matematica, il problem space è sempre un sottoinsieme del solution space: quindi, non dobbiamo avere fretta di abbandonare il primo per approdare, con una scarsa conoscenza del dominio, nel secondo. Non dobbiamo sorprenderci se, come sviluppatori, tendiamo a fornire una soluzione in fretta: è la nostra natura che ci porta ad agire in questo modo.
E allora non ci importa se non utilizziamo a sufficienza del tempo per capire a fondo il problema, per restare a lungo fuori dalla nostra zona di comfort, col risultato di produrre dei requisiti incompleti per la soluzione completa del problema. Quello che importa è che il risultato così ottenuto sarà sempre incompleto o, peggio ancora, sbagliato; ed è in questo spazio che iniziano i fallimenti dei nostri progetti software.
Restiamo nel Problem Space
Come mi piace spesso ripetere, realizzare software significa risolvere problemi di business e, trattandosi di problemi, questa volta concordo pienamente con la mia docente di matematica: bisogna comprenderli a fondo per poterli risolvere.
Non fornire una soluzione adeguata sin dall’inizio significa partire zoppi, e sappiamo tutti che le nostre applicazioni nascono piccole, ma sono destinate a crescere nel tempo, alcune anche molto in fretta: man mano che cresceranno le richieste del cliente, una piccola deviazione all’inizio del percorso ci porterà a una meta diversa da quella immaginata, perché sarà sempre più difficoltoso adeguare la nostra soluzione alla soluzione del problema stesso.
Come dice E. Evans, man mano che procediamo, come team, nello sviluppo dell’applicazione, ci avviciniamo sempre più ai Business Expert come conoscenza del dominio, alla comprensione del problema, e questo ci porterà a trovare soluzioni decisamente più adeguate; ma, se il punto di partenza diverge troppo dalla giusta direzione, sarà difficile, se non impossibile, fare coincidere le nuove soluzioni con quelle iniziali.
Come possiamo evitare tutto questo? Restando il più a lungo possibile nello spazio del problema. Proprio come nella citazione di A. Einstein. Anche lo stesso E. Evans, con termini più vicini al nostro mondo, sostiene che la prima versione del nostro modello di dominio sarà sicuramente sbagliata e che, se riteniamo di aver trovato la soluzione al primo giro, sicuramente abbiamo sbagliato qualcosa, non abbiamo considerato tutti i fattori del problema. Non a caso ci propone un modello esplorativo, fatto di iterazioni continue di analisi, proposte e feedback
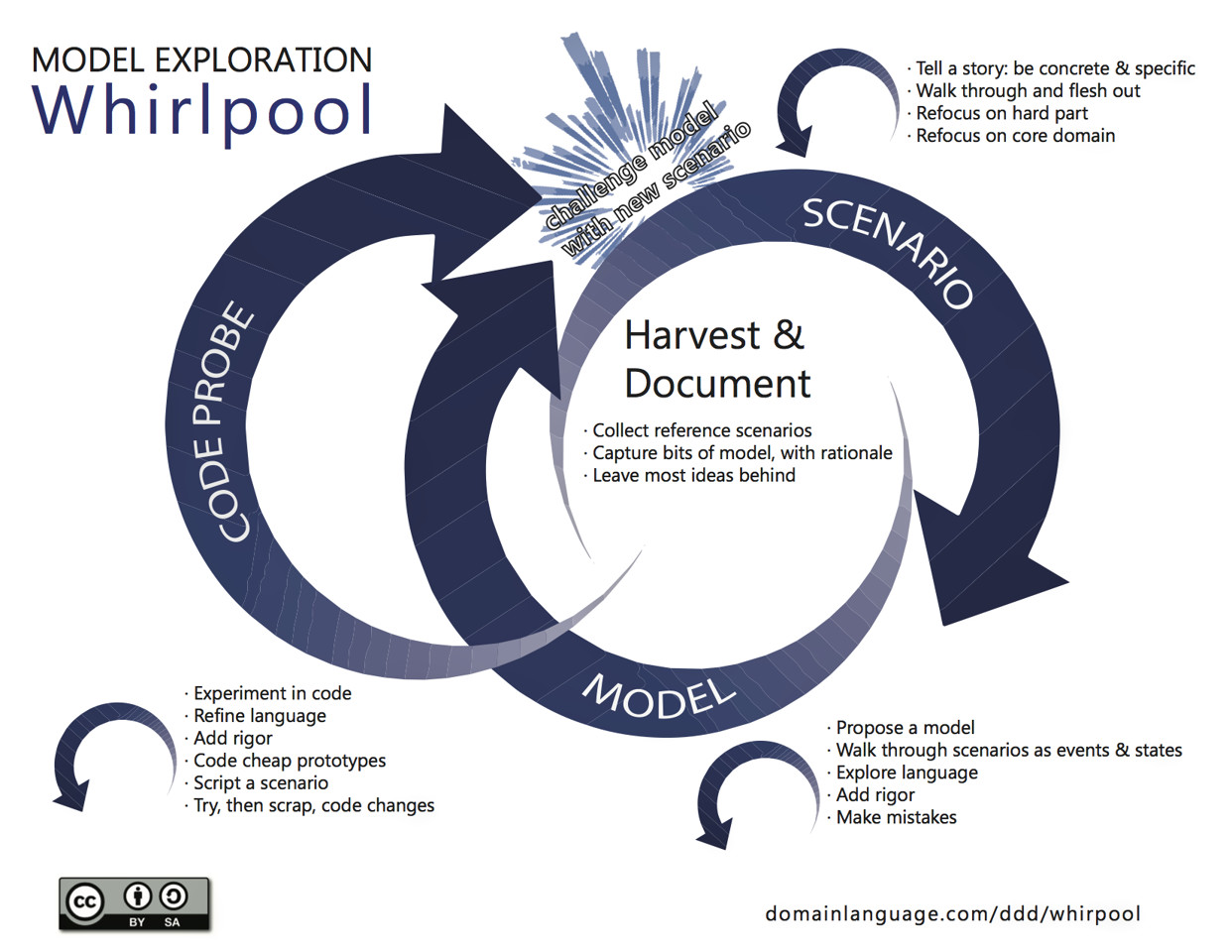
Il blocco delle soluzioni precoci
Lo stesso Evans definisce l’azione del trovare una soluzione sin dall’inizio all’intero problema come ciò che in gergo chiamiamo big front design: un blocco (“locking in our ignorance”). Il problema con questo tipo di approccio sta nel fatto che ci troviamo costretti a prendere un sacco di decisioni importanti riguardo la nostra soluzione proprio nel momento in cui abbiamo minore conoscenza del problema stesso.
Anche Dan North ci suggerisce massima cautela nel procedere verso una soluzione definitiva. Nel suo articolo Introducing Deliberate Discovery [2] suggerisce di mantenere un approccio di mancanza di consapevolezza nei confronti della conoscenza del dominio che stiamo affrontando. La mancanza di consapevolezza, per chi volesse approfondire, è il secondo livello di ignoranza secondo Philip Armour, che proprio a tal proposito, nel 2000, scrisse un articolo sui cinque ordini di ignoranza nell’ambito dello sviluppo software [3].
Qualche indicazione per non trovare soluzioni frettolose
Ma, se l’ignoranza è l’opposto della conoscenza, come possiamo rimanere nello spazio del problema per cercare di colmare la prima e accrescere la seconda? Come si controlla la nostra propensione a proporre una soluzione troppo rapidamente? Possiamo considerare alcuni consigli utili.
- Mantenere il controllo della discussione. Non significa che dovete parlare in continuazione, ma che dovete evitare che la discussione converga troppo rapidamente a una conclusione. Spesso un segnale a un vostro collega è sufficiente per far cambiare rotta ai membri del team. Il cliente, o chi per lui, dà per scontato un sacco di informazioni mentre ci racconta del suo problema, e tocca a noi farle emergere in maniera palese nella discussione.
- Acoltare le diverse soluzioni. Durante la discussione del problema, vinti i primi momenti di imbarazzo, normalmente emergono molte idee di soluzione, a volte contrastanti fra loro. È importante mantenere un ambiente sano e positivo inserendo i suggerimenti di tutti nello spazio delle soluzioni.
- Tenere nascoste le soluzioni principali. Come moderatori dell’esplorazione del problema, il vostro compito è mantenere il più a lungo possibile nascoste le soluzioni che man mano si dimostrano valide. Se, per esempio, utilizzate EventStorming come tool di esplorazione, lasciate che i partecipanti continuino ad attaccare Post-it sul muro, e magari guidateli verso una direzione, in modo che questa emerga in maniera autonoma dall’esplorazione stessa. Evidenziate le soluzioni che sembrano simili e fate convergere su di esse l’attenzione, per capire se sono modi diversi di esprimere la stessa soluzione, oppure se sono proprio due soluzioni diverse da esplorare.
Conoscere la situazione del cliente
Restare nello spazio del problema è sicuramente scomodo per entrambe le parti, cliente e fornitore. Il primo si sente un po’ sotto pressione per le innumerevoli domande che gli continuano ad arrivare, il secondo — vale a dire, spesso, noi — non vedel’ora di proporre una soluzione. Affrontare completamente il problema del cliente richiede tempo, e non sempre è conveniente insistere più del necessario al primo incontro. L’importante è individuare i confini del problema e iniziare a proporre una soluzione, sulla quale ci si potrà ritrovare per avere feedback e continuare, dopo aver eventualmente aggiustato il tiro. Il nostro dominio sarà sempre in continua evoluzione, se non altro per tutto ciò che appartiene al livello del unknow unknows, ossia le cose che ancora non sappiamo di non sapere, ma che scopriremo a mano a mano che diventeremo sempre più esperti del dominio su cui stiamo lavorando. A questo punto dobbiamo capire come si affronta, dal punto di vista architetturale, una soluzione simile.
Evolutionary Architecture
Anche l’architettura, così come il software che stiamo implementando, dovrà essere in grado di evolvere; è finito il tempo della metafora fra architettura di un edificio e architettura del software. Non possiamo permetterci di creare un’applicazione che poi andremo ad abbandonare perché imbrigliata in un’architettura rigida che non consente di adeguarsi alle esigenze del mercato, quali, per esempio, scalabilità, resilienza, elasticità.
Pro e contro dei microservizi e dei monoliti
Se partiamo con una soluzione a microservizi, quasi certamente troveremo facilmente risposta a questi problemi, ma dovremo pagare lo scotto di portarci in casa parecchia complessità accidentale all’inizio del progetto stesso. I microservizi portano con sé alcuni problemi:
- decomposizione del database
- workflow distribuiti
- transazioni distribuite
- automazione dei processi
- distribuzione tramite container e orchestratori
Quelle appena citate sono tutte questioni che comportano anche oneri economici non indifferenti, per un progetto che potrebbe continuare come anche interrompersi per svariate ragioni.
Una soluzione che contempli il buon vecchio monolite sembra più abbordabile; il monolite è infatti
- facile da implementare
- facile da testare
- facile da distribuire
- veloce da realizzare
Ovviamente, oltre a questi pregi, ha i suoi bei difetti, guarda caso, esattamente quelli che noi vorremmo evitare e che abbiamo citato sopra.
Architettura modulare
Negli ultimi anni, una nuova soluzione architetturale sta prendendo piede: è una via di mezzo tra microservizi e monolite, la Modular Architecture.
Lo scopo di questa architettura è quello di creare una soluzione production ready a tutti gli effetti, non un semplice PoC (Proof of Concept); l’idea di base è individuare i moduli all’interno della soluzione, e per fare questo abbiamo a disposizione gli Strategic Pattern del DDD, quali Bounded Context, Context Mapping e, ovviamente, Ubiquitous Language. Spesso questi pattern vengono associati ai microservizi, proprio perché ci aiutano a definire i confini delle singole responsabilità di ogni sotto dominio del nostro sistema.
Contrariamente ai microservizi però, in questo caso non si progettano soluzioni diverse per ogni Bounded Context indivuato, ma bensì un modulo all’interno di un monolite. Questo ci servirà nel caso il nostro confine iniziale non sia stato individuato proprio correttamente, e avrà bisogno di qualche aggiustamento; dover fare queste operazioni di sistemazione del codice all’interno di un monolite è sicuramente più semplice che non dover rimettere mano a diversi microservizi.
Conclusioni
Abbiamo visto in questo articolo che rimanere nello “spazio dei problemi”, per quanto scomodo e tendenzialmente innaturale, ci aiuta a entrare nello “spazio della soluzione” con una migliore conoscenza del dominio e una maggiore capacità di assumere le decisioni giuste.
Abbiamo anche parlato brevemente di vantaggi e svantaggi delle soluzioni architetturali a monolite e a microservizi, introducendo il concetto di architettura modulare.
Vedremo nel prossimo articolo cosa si intende esattamente per modulo, e quali vantaggi ci porta una soluzione architetturale simile.
Riferimenti
[1] A. Newell – H. Simon, Human Problem Solving. Echo Point Books & Media, 2019
[2] Dan North, Introducing Deliberate Discovery
https://dannorth.net/introducing-deliberate-discovery/
[3] Phillip G. Armour, Five Orders of Ignorance. Viewing software development as knowledge acquisition and ignorance reduction. “Communications of the ACM”, October 2000, vol. 43, n. 10, pp. 17–20
https://cacm.acm.org/magazines/2000/10/7556-the-five-orders-of-ignorance/abstract
Sono fondamentalmente un eterno curioso. Mi definisco da sempre uno sviluppatore backend, ma non disdegno curiosare anche dall'altro lato del codice. Mi piace pensare che "scrivere" software sia principalmente risolvere problemi di business e fornire valore al cliente, e in questo trovo che i pattern del DDD siano un grande aiuto. Lavoro come Software Engineer presso intré, un'azienda che sposa questa ideologia; da buon introverso trovo difficoltoso uscire allo scoperto, ma mi piace uscire dalla mia comfort-zone per condividere con gli altri le cose che ho imparato, per poter trovare ogni volta i giusti stimoli a continuare a migliorare.
Mi piace frequentare il mondo delle community, contribuendo, quando posso, con proposte attive. Sono co-founder della community DDD Open e Polenta e Deploy, e membro attivo di altre community come Blazor Developer Italiani.