

La dashboard di visualizzazione
La dashboard di visualizzazione, basata su tecnologia WebSocket, viene implementata sotto forma di microservizio SpringBoot che espone un WebServer, il quale pubblica una pagina HTML di presentation e le classi di backend Java necessarie alla definizione del microservizio e di accesso ai dati di Cassandra.
WebSocket è una specifica che permette la comunicazione bidirezionale sincrona tra un client e un server, nel nostro caso il browser web e il microservizio SpringBoot. WebSocket è un protocollo basato su una connessione HTTP attraverso cui possono essere scambiati frame a lunghezza variabile tra i due endpoint. Si tratta quindi di un protocollo generalmente utilizzato per la comunicazione sincrona tra il browser dell’utente e un’applicazione di backend esposta da un web server.
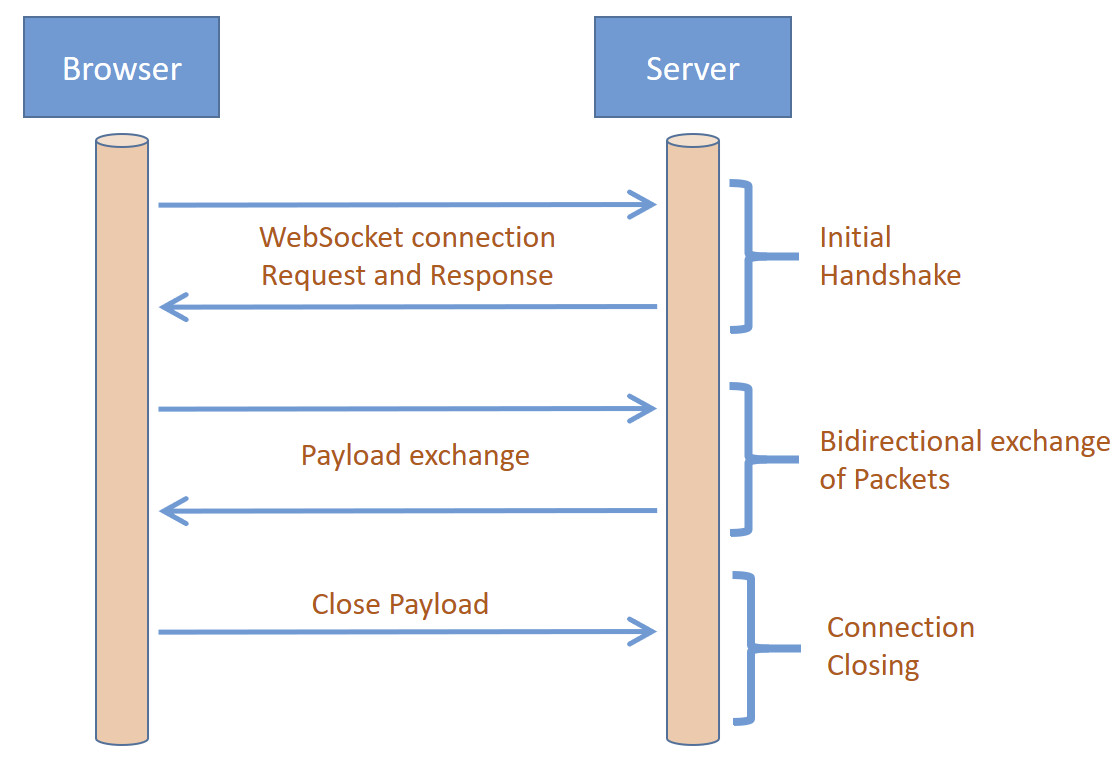
Un WebSocket è un canale di comunicazione che utilizza TCP come protocollo sottostante. Viene avviato dal client che invia una richiesta HTTP al server richiedendo un aggiornamento della connessione a WebSocket. Se il server supporta questo protocollo, la richiesta del client viene concessa e viene stabilita una connessione di questo tipo tra le due parti. Da questo momento tutte le comunicazioni avvengono tramite WebSocket e il protocollo HTTP non viene più utilizzato. WebSocket realizza un protocollo di comunicazione senza richiedere uno specifico formato di messaggistica. Spetta alle applicazioni concordare il formato dei messaggi scambiati. WebSocket API fa parte della specifica HTML5 ed è supportata dai più diffusi browser Internet.
Per la dashboard di visualizzazione la comunicazione WebSocket viene realizzata attraverso il framework Spring, utilizzando STOMP (Streaming Text Oriented Message Protocol) come protocollo di messaggistica. STOMP definisce un formato di comunicazione dove un client STOMP può comunicate con un message broker STOMP per realizzare un’interoperabilità di messaggistica di semplice implementazione piuttosto diffusa tra linguaggi di programmazione e piattaforme diverse.
L’implementazione della dashboard di visualizzazione viene completata dall’utilizzo delle librerie JavaScript JQuery e Chart. JQuery viene utilizzata nelle pagine per semplificare la selezione, la manipolazione, la gestione degli eventi e l’animazione di elementi (Document Object Model). JQuery semplifica anche l’uso di funzionalità AJAX, la gestione degli eventi e la manipolazione dei CSS. Attraverso la libreria Chart.js verranno creati gli elementi grafici in linguaggio JavaScript.
Backend
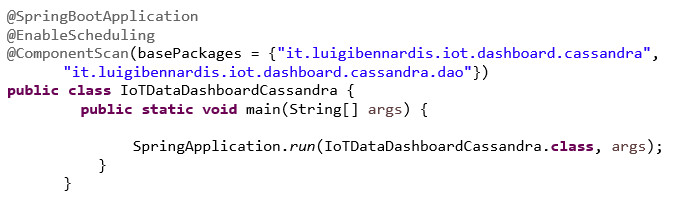
Descriviamo in questo paragrafo le classi che definiscono il layer applicativo di backend. Di seguito l’implementazione della classe di avvio Spring Boot dove si evince la direttiva che abilita lo scheduling che sarà impostato poi nella classe service.
La funzionalità WebSocket viene abilitata attraverso l’annotazione @EnableWebSocketMessageBroker. Viene quindi codificata la registrazione dell’endpoint STOMP alla URL scelta (/stomp) attraverso SockJS, abilitato un message broker e configurata la URL corrispondente (/topic). Di seguito il fragment di implementazione della classe di configurazione.

Di seguito la classe che serializza le informazioni che saranno ottenute da Cassandra attraverso la classe di tipo data service.

Di seguito la classe DataService con la codifica di accesso schedulato ai record di Cassandra e invio degli stessi sotto forma di messaggio (WebSocket/STOMP) alla dashboard di visualizzazione.

Di rilevo nella codifica viene segnalata la variabile responseMessage che rappresenta un’istanza di org.messaging.simp.SimpMessagingTemplate, implementazione dell’interfaccia SimpleMessageSendingOperations, classe che a sua volta specializza MessageSendingOperations. MessageSendingOperations implementa i metodi necessari al supporto del framework di Spring per protocolli di Simple Messaging come STOMP. Il metodo convertAndSend invia il contenuto serializzato della classe httpDatiResponse alla URL di pubblicazione della dashboard.
Presentation
Viene riportata di seguito la codifica della pagina HTML/JavaScript che implementa le funzionalità di visualizzazione. Il primo fragment evidenzia l’importazione delle librerie client dei framework JavaScript utilizzati:

La codifica continua definendo le variabili di persistenza delle tabelle accedute attraverso JQuery e la creazione di una istanza SockJS e di un client STOMP.

Viene quindi codificato il client STOMP che sottoscrive il messaggio al path specificato. Nel body del messaggio saranno presenti i dati contenuti nelle tabelle Cassandra letti dal microservizio SpringBoot.
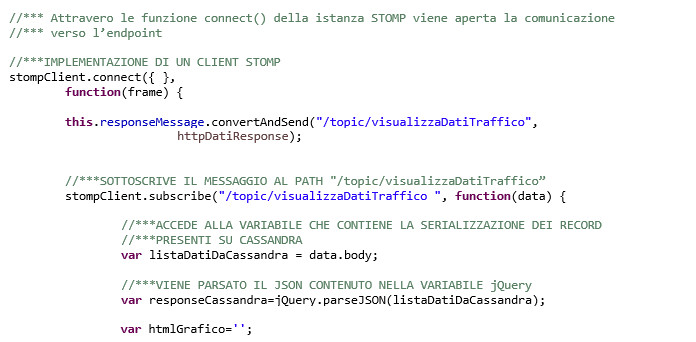
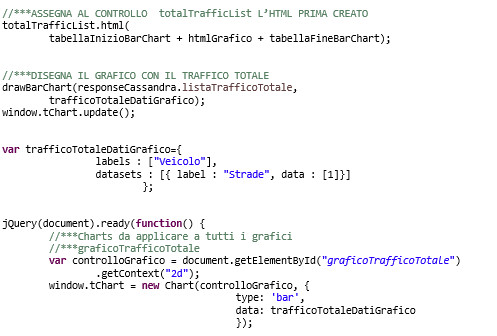
I dati di ciascuna tabella Cassandra (nell’esempio listaTrafficoTotale) vengono concatenati in una stringa con gli elementi HTML di visualizzazione.

La visualizzazione delle informazioni sui controlli Chart.js conclude l’implementazione della codifica JavaScript.
Grafici di monitoraggio
Di seguito i grafici di monitoraggio che rappresentano i veicoli al POI con il dettaglio della distanza, la distribuzione del traffico per tipo veicolo rilevata in nodo stradale specifico e il traffico totale per le direttrici stradali considerate.
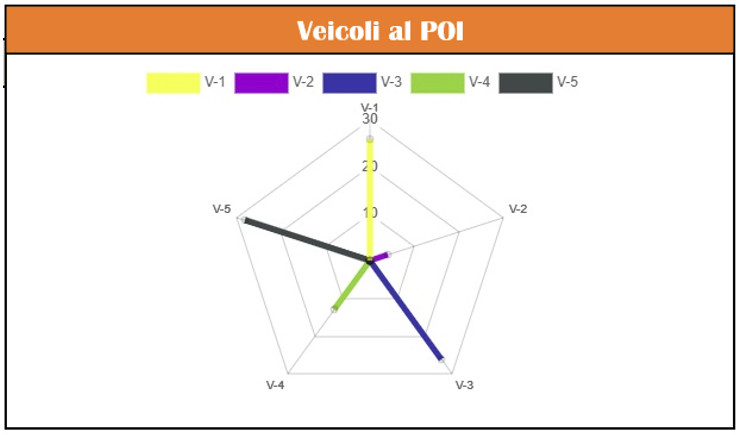
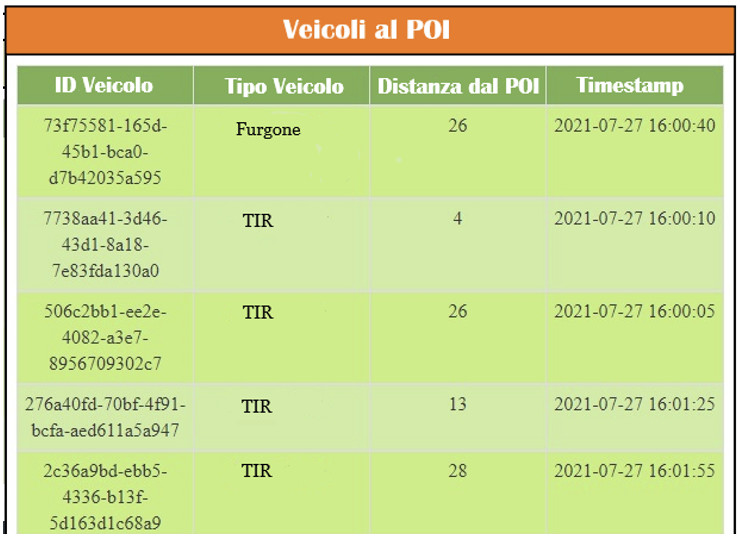
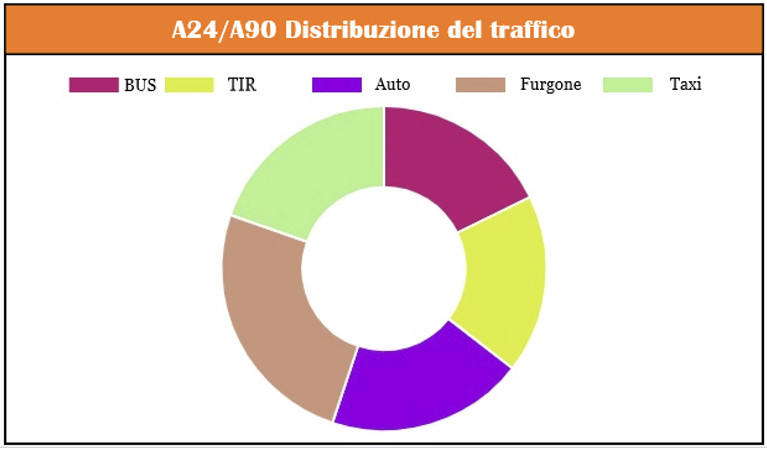
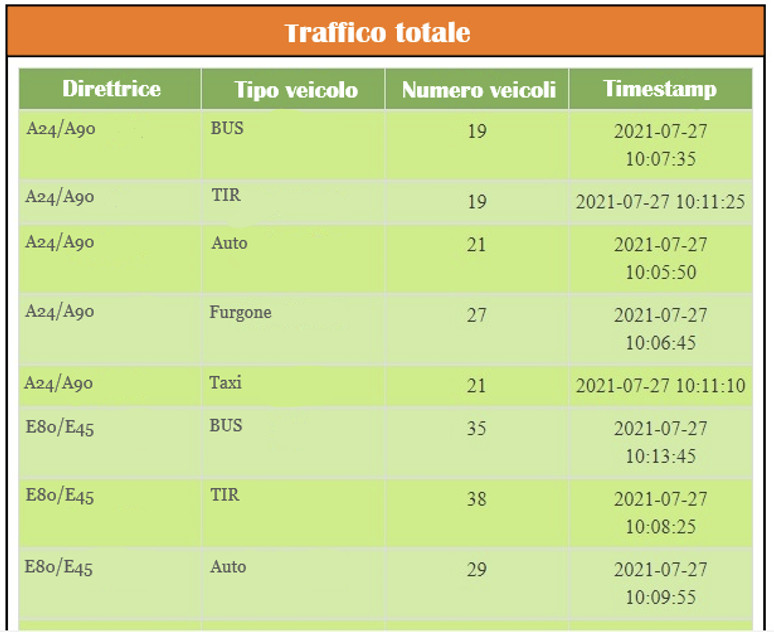
Dashboard Spark
Spark pubblica alla URL: <nome_host>:4040/jobs la dashboard di controllo. La dashboard elenca i job completati e la loro corrispondenza sulla timeline di esecuzione. Nella figura 15 c’è il dettaglio di un job di esempio con i riferimenti alla corrispondente linea di codice Java, il timestamp del momento dell’invio, la durata, gli stage e il dettaglio dei task. Nella timeline, i job sono rappresentati con colori diversi per quelli in esecuzione, quelli eseguiti con successo e quelli falliti.
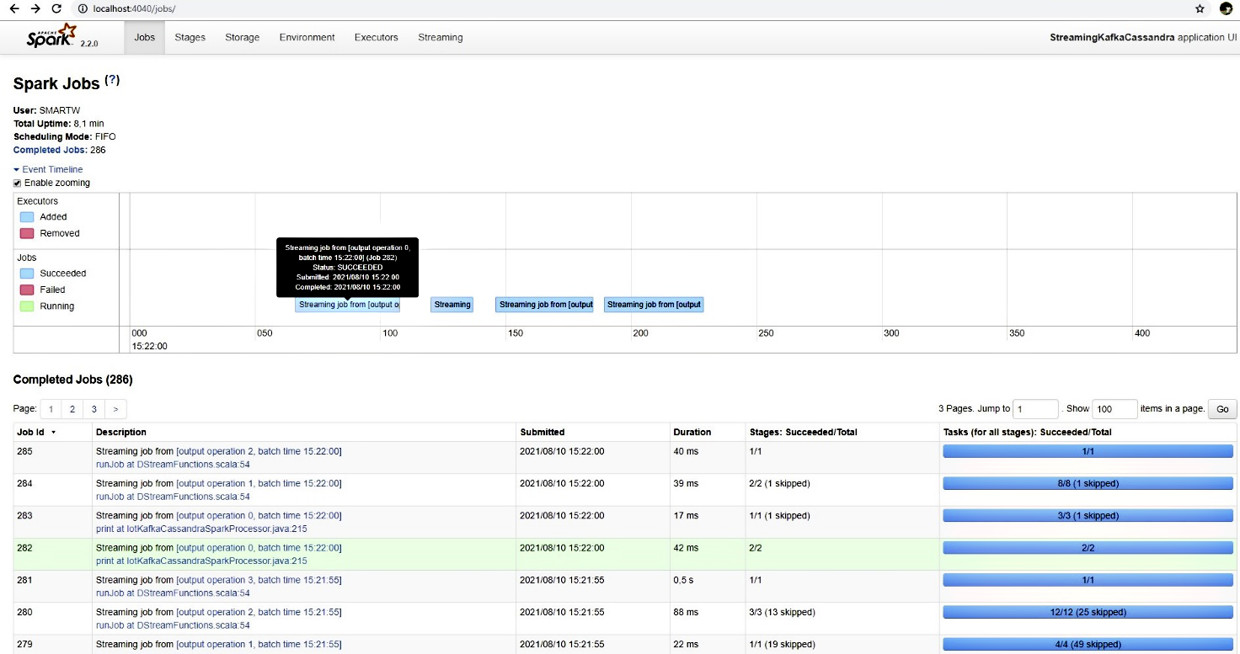
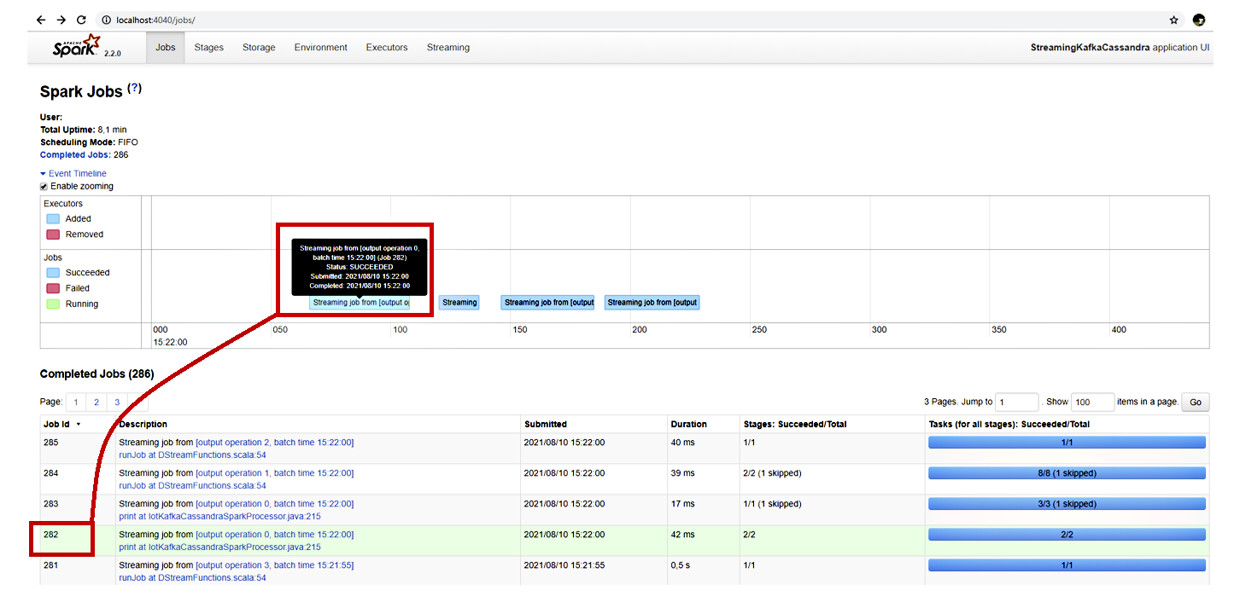
Di seguito la visualizzazione in formato DAG (Directed Acyclic Graph) di un job di esempio, con il dettaglio degli stage che esegue. Nella lista degli stage completati possiamo notare la corrispondenza di ciascuno alla linea di codice Java di implementazione. Anche in questo caso, la lista riporta le informazioni con il timestamp di invio, la durata, il numero di task terminati con successo, la quantità di dati di input e di output e il numero di letture/scritture.
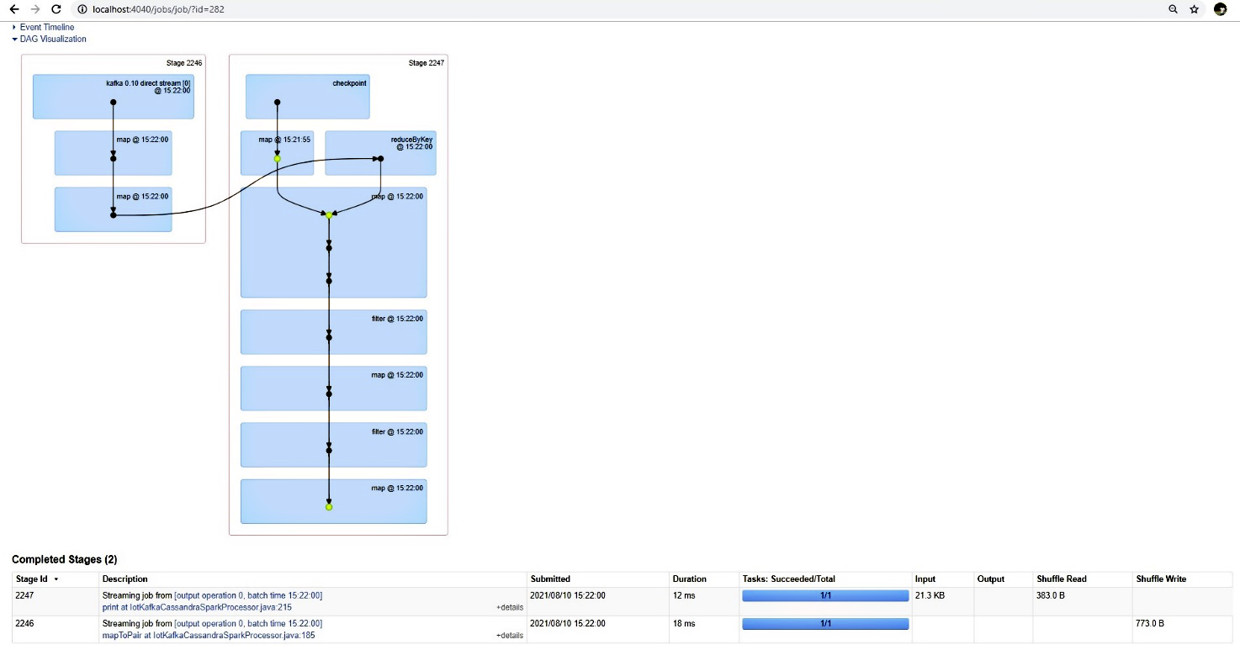
Nelle figure di seguito, sono riportate la visualizzazione di dettaglio di ogni stage con le evidenze delle metriche di esecuzione.
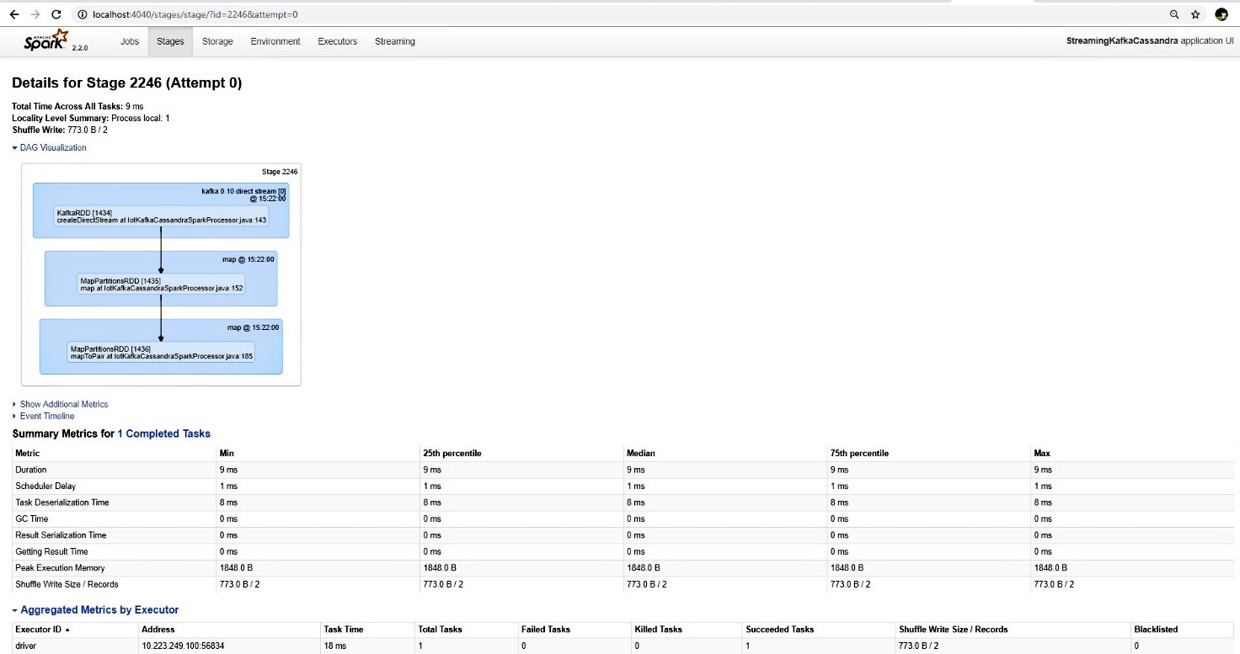

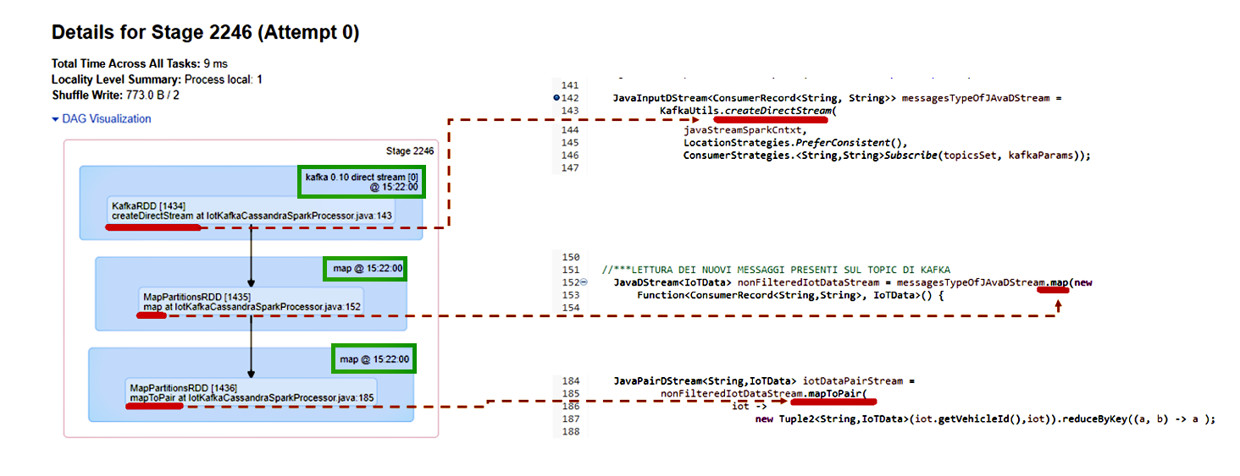
Nel dettaglio di visualizzazione DAG di ciascuno stage vengono visualizzati i task che lo compongono: nel riquadro verde l’operazione eseguita da ciascun task (direct stream, map).
Nella parte evidenziata in rosso la corrispondenza al codice Java eseguito: nell’esempio, la creazione dello stream di lettura da Kafka utilizzando il runtime kafka 0.10 direct stream e le due operazioni di map che ottengono in sequenza i nuovi RDD richiesti dall’elaborazione.
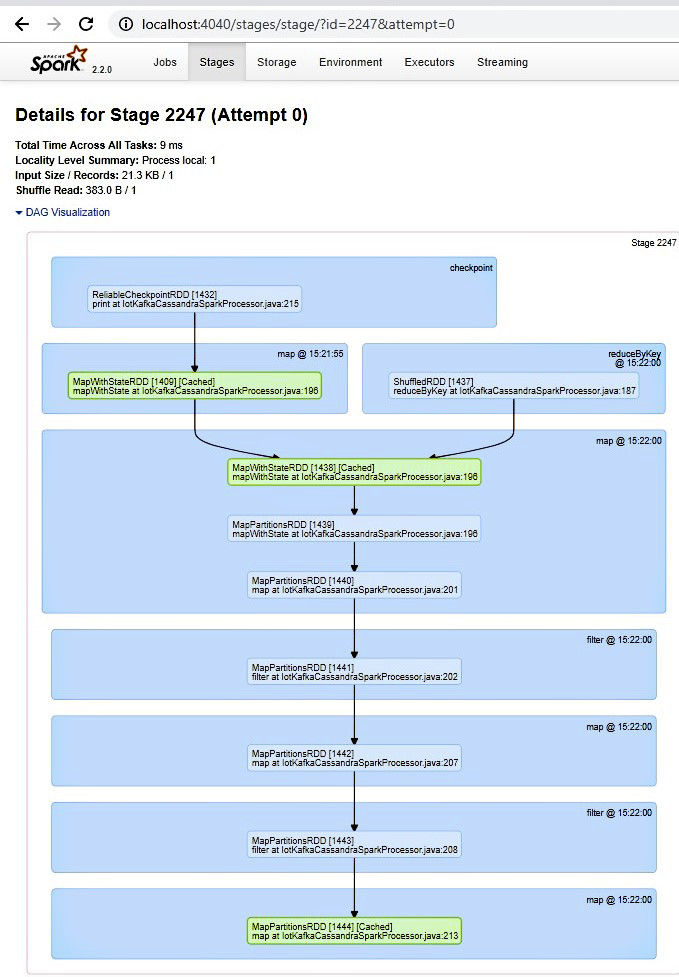
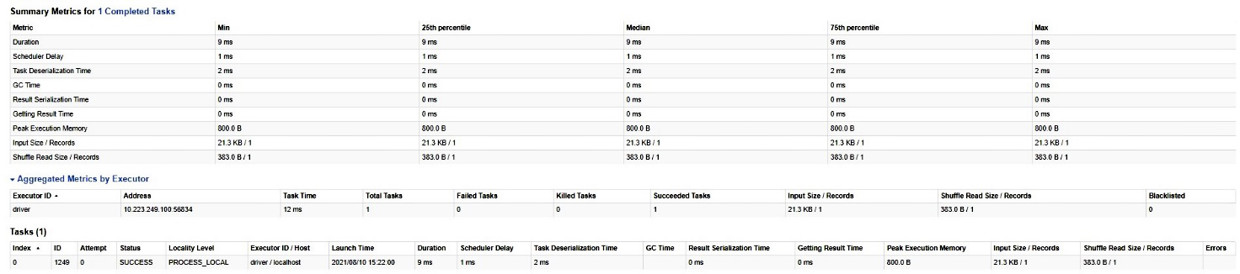
Analogamente a quanto già descritto per lo stage precedente, con una serie di immagini, di seguito viene riportato il dettaglio del secondo stage, sempre riferito al job preso in esame.

Conclusioni
Questa serie di articoli descrive una possibile implementazione di una piattaforma digitale di monitoraggio in tempo reale di dati posizionali inviati dai veicoli in transito su alcune direttrici stradali. Sono stati presentati i moduli applicativi, i dettagli tecnologici di integrazione e le caratteristiche di funzionamento di Kafka, Spark e Cassandra.
L’esempio proposto è facilmente estendibile a molti altri casi d’uso. Per esempio, al monitoraggio delle informazioni che rilevano eventuali criticità sui dispositivi in dotazione dei veicoli che trasportano merci pericolose. La possibilità di attuare un monitoraggio in tempo reale di queste informazioni potrebbe attivare una più efficace gestione della sicurezza, anche con l’integrazione delle informazioni inviate dai dispositivi IOT installati su infrastrutture stradali critiche, anche utilizzabili per eseguire algoritmi di intelligenza artificiale orientati alla prevenzione degli incidenti e/o a rendere più efficiente la fluidità del traffico.
Tra le caratteristiche di Spark Streaming c’è la possibilità di integrare batch di dati storicizzati con dati live streaming. Questa caratteristica rappresenta un elemento significativo in tema di gestione e programmazione del fabbisogno e della domanda di nuovi servizi di mobilità e più in generale per l’attuazione dei modelli di smart city.
Anche in ambito industriale il monitoraggio dei dati provenienti dai dispositivi IOT installati sulle macchine può rappresentare uno strumento di analisi e miglioramento dei processi oltre che di valutazione degli impatti di una modifica dei processi stessi.
Più in generale è verosimile che le analisi basate sul monitoraggio in tempo reale dei dati provenienti dai dispositivi IOT integrati dai batch di dati storicizzati, e con l’applicazione su questi dati di algoritmi di intelligenza artificiale, rappresentano uno strumento efficace per analizzare e migliorare l’efficienza dei processi osservati.