

Togliere di mezzo la Continuous Integration
Stavolta ho scelto di comportarmi nel modo in cui agiscono alcuni giornali: il titolo che avete appena letto sembra dire una cosa, ma la lettura dell’articolo ci rivela che le cose non stanno esattamente come scritto nel titolo. Lo dico subito, a scanso di equivoci, così i lettori sono avvertiti…
In realtà, in questo articolo, ci riallacciamo a quanto raccontato nelle parti precedenti della serie [1] e guardiamo ad alcune strategie che la Continuous Integration la fanno fuori per davvero. Il fatto è che tali strategie di gestione del processo di sviluppo sono molto più comuni di quanto si pensi e che, soprattutto, vengono impiegate in ambiti in cui, in buona fede, si ritiene di fare Continuous Integration, Continuous Delivery e Continuous Deployment.
La Continuous Integration non è solo un aspetto tecnico
Di fatto, come abbiamo avuto modo di notare negli altri articoli, la Continuous Integration (CI) non consiste solo nell’adozione di una particolare infrastruttura tecnica: non basta inseire nel proprio processo Cruise Control [2], Bamboo [3] o Jenkins [4] per garantirsi di fare CI.
La CI è anzitutto un approccio al processo che implica delle precise pratiche “quotidiane” nello sviluppo del software: posso avere i tool giusti, ma se non li inserisco in questo processo nel modo corretto e se non adatto il mio modo di lavorare non sto facendo effettivamente Continuous Integration.
Questi aspetti erano ben chiari a Martin Fowler quando, ormai dieci anni fa, scrisse un lungo articolo [5] introducendo la pratica (così la definisce) della Continuous Integration. Nelle sue parole è chiaro che l’integrazione deve essere effettuata su base almeno quotidiana, puntando comunque a più integrazioni durante una giornata. Ed è chiaro che CI è anzitutto un approccio condiviso nel gruppo di lavoro, un modo di lavorare in cui tutti gli sviluppatori effettuano un commit al trunk almeno una volta al giorno.
Il passo successivo è il cosiddetto Continuous Delivery, vale a dire un approccio integrato e globale di tecnologie, metedologie e pratiche che porta le aziende a ridurre drasticamente i tempi di rilascio delle nuove features di un prodotto. Non occorre essere fini pensatori per capire che il Continuous Delivery non esiste senza una base di codice sempre “rilasciabile”. E una base di codice che si presti a essere rilasciato è quella in cui i test e l’integrazione vengono effettuati almeno quotidianamente, meglio se ancora più spesso. In definitva: “No Continuous Integration? No Continuous Delivery!”, anche se magari l’azienda se ne fa vanto nelle presentazioni commerciali…
Strategie per il controllo delle versioni
Come spesso succede, uno sguardo in ottica “storica” ci consente di capire meglio quello che stiamo facendo e le ragioni di certe tecnologie e di certi approcci. Ormai lo sviluppo software “moderno”, anche lasciando fuori tante cose che ci sono state prima, è una disciplina con almeno una trentina di anni di storia, in cui tendenze e soluzioni, pratiche e tecnologie si sono avvicendate. La costante di questa evoluzione è che ogni soluzione portava con sé grandi novità e positivi avanzamenti, ma poneva a sua volta dei limiti e dei problemi che dovevano essere ulteriormente affrontati.
Questo vale certo per i linguaggi di programmazione, ma anche per i metodi e i tool di version control [6] che si sono presto affermati come ottimi strumenti metodologici per affrontare il problema della qualità del software [7].
Vediamo allora le diverse strategie per il version control e quale è la loro “compatibilità” con l’approccio Continuous Integration / Continuous Delivery. Analizzandone alcune caratteristiche, capiremo anche perché alcuni approcci finiscono per determinare una vera e propria “eliminazione” della possibilità di fare CI.
Gli anni Novanta e il Release Feature Branching
Gli anni Novanta vedono lo sviluppo e l’affermazione del modello di controllo del versionamento del software detto Release Feature Branching. In esso, dal tronco principale del codice (trunk) si staccavano subito dei rami secondari (branch) relativi a specifiche feature.
Su questi branch condivisi, i programmatori lavoravano per settimane, se non per mesi: intere “epiche”, per parlare in termini di storie utente, venivano sviluppate e testate indipendentemente sui diversi branch prima di poter essere rilasciate per la produzione.
Seguiva poi il merge con cui i rami separati venivano reinnestati sul tronco principale: inutile dire che questo era il momento critico, in cui l’integrazione richiedeva operazioni faticose, lunghe, molti test di regressione e, in definitiva, finiva per allungare ulteriormente i tempi di completamento.
Ciò nonostante, questo è stato il modo di lavorare più diffuso che ha comunque portato alla realizzazione anche di ottimi prodotti per quanto con una certa fatica. A sostegno di tale approccio si sono utilizzati tool come MKS, ClearCase, Perforce che impementavano appunto tale modalità di procedere.
Il “revival” della metà degli anni Zero
Sebbene a partire grosso modo dal 2000 abbia iniziato a diffondersi un diverso modo per sviluppare, che vedremo subito dopo, alla metà degli anni Zero c’è stata una sorta di “revival” dell’approccio appena visto, dovuto anzitutto alla disponibilità di tool di versionamento molto conosciuti e performanti, i cosiddetti DVCS (Distributed Version Control Systems).
In pratica si è affermato un approccio di tipo Release Feature Branching “alleggerito”, grazie all’emergere di strategie per così dire “imposte” dalla constatazione di tutti i problemi inerenti all’approccio “classico”.
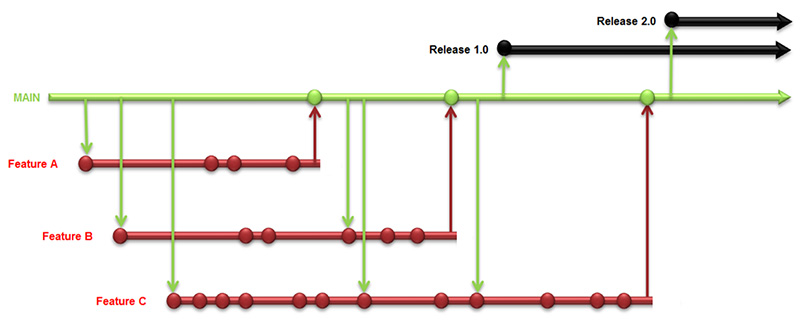
In effetti, grazie a strumenti DVCS come Git e Mercurial si è ottenuto un “costo” minore nello sviluppare svariate branch di feature e poi integrarle nel tronco principale: il concetto è rimasto lo stesso, ma le modalità e i tempi con cui tale concetto viene applicato sono molto differenti. Si parla in questo caso di Integration Feature Branching poiché qui l’integrazione assume un valore importante.
Con questo approccio, si continua a lavorare su una singola feature, ma lo si fa per tempi brevi, idealmente solo una giornata, prima di effettuare il merge su un ramo di integrazione che è vivo da tempi più lunghi e sul quale si fanno i test. A questo punto, se tutto è OK, il branch di integrazione sarà riunito tramite merge al tronco principale. Un esempio di questo approccio è riportato in un dettagliato articolo [8] dal quale abbiamo estratto anche la figura 2 che sintetizza tale Integration Feature Branching.
Incompatibilità con Continuous Integration
Per quanto l’Integration Feature Branching risolva molti dei problemi del classico Release Feature Branching, si tratta comunque in entrambi i casi di approcci che non si prestano a un reale processo di Continuous Integration: se il metodo più vecchio è in sé la negazione della CI, che nasce proprio come risposta ai problemi insiti in tale approccio, anche la versione riveduta e corretta dell’Integration Feature Branching — pur giustamente inserendo tempi abbastanza brevi per i test e l’integrazione — continua a presentare un esagerato numero di rami secondari prima dell’effettiva integrazione nel tronco principale.
Gli anni Zero e il Trunk Based Development
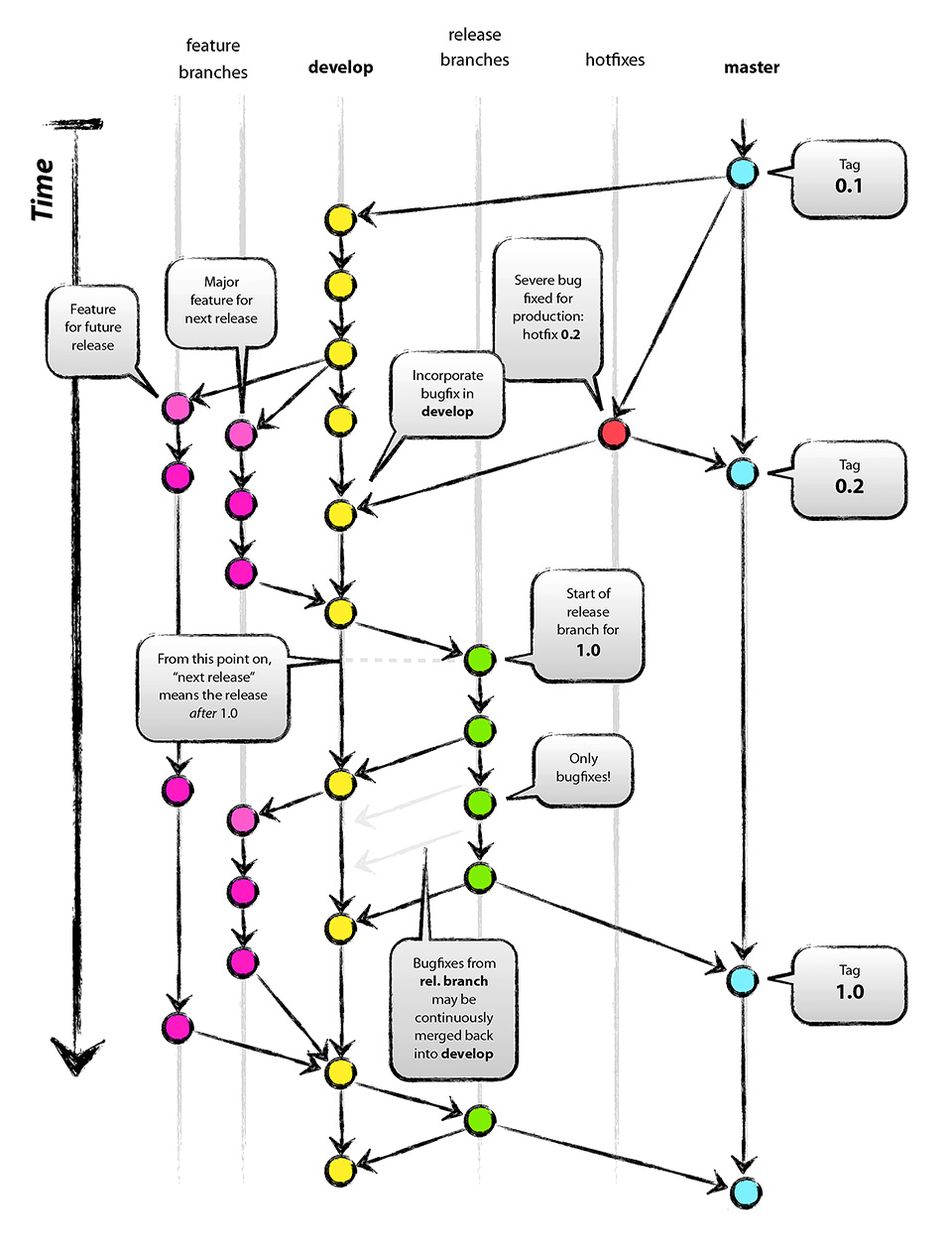
A partire dai primissimi anni Zero del presente secolo, si è affermato un approccio definito Trunk Based Development che già dal nome mette in risalto l’importanza data al tronco principale. In questa affermazione non va sottovalutata il ruolo di strumenti quali Perforce [9] e poi Subversion [10], sebbene, a onor del vero, vada detto che concettualmente anche gli strumenti di DVCS di cui si è parlato sopra possono adattarsi a questo paradigma.
In modo schematico, in cosa consiste? Gli sviluppatori lavorano su un trunk principale effettuando numerosi commit al giorno, in una sequenza di piccoli passi incrementali. I test si fanno direttamente sul tronco principale, dal quale partono anche le release per la produzione, sebbene si usino per queste anche dei branch appositi per le release, che vengono tenuti in vita per brevi periodi di tempo [11].
Non è esclusa la possibilità di sviluppare feature parallelamente, e a tale scopo sono state messe a punto tecniche apposite quali la FeatureToggle [12] e la Branch By Abstraction [13].
Il Trunk Based Development può essere utilizzato con tool quali il già citato Subversion, ma anche con Git e Mercurial [14].
Compatibilità con Continuous Integration
Siamo in presenza di una strategia di version control che si concentra su svariati commit al giorno, effettuati sul trunk principale (detto anche master), e che prevede poche branch secondarie, oltretutto in genere di breve durata.
È chiaro che si tratta proprio di una implementazione pratica dei concetti alla base della Continuous Integration: è questa la ragione per cui, più che di compatibilità con la CI, sarebbe il caso di parlare di perfetta “sovrapponibilità” tra questa pratica e i dettami della CI. Ogni componente del team effettua ogni giorno svariati commit sul tronco principale, e questo costringe oltretutto a scomporre la codebase in elementi piccoli e modulari, il che è un passo importante verso una necessaria semplificazione.
Un caso di esempio
Per chi fosse interessato ad approfondire, esiste anche un libro [15] che racconta quello che è successo con l’introduzione di questo approccio all’interno dell’azienda HP, mettendo in luce come l’abbandono del vecchio paradigma e il passaggio al Trunk Based Development abbiano non solo migliorato le performance nella realizzazione di codice, ma anche liberato una serie di energie creative da parte degli ingegneri che si sono potuti concentrare maggiormente sulla ricerca e sullo sviluppo, piuttosto che sulla risoluzione dei problemi derivanti da un’integrazione tardiva.
Gli anni Dieci e il Build Feature Branching
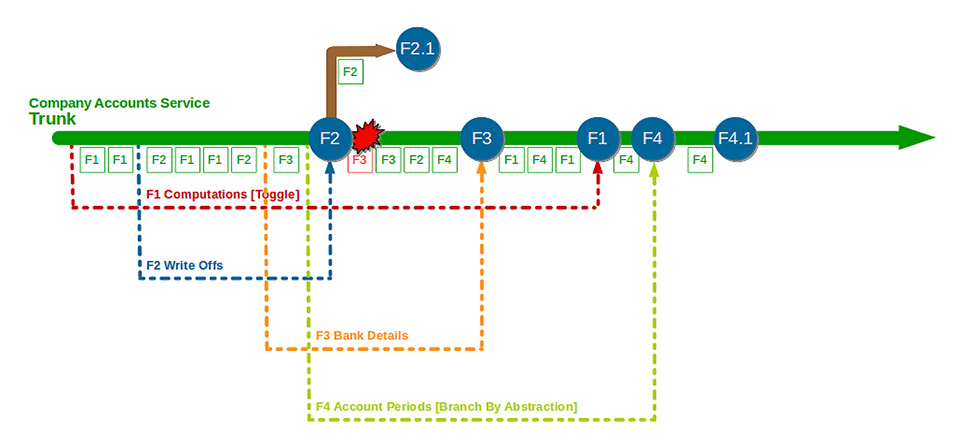
Il decennio attuale ha visto l’affermazione di un ulteriore paradigma per il version control, che è stato definito Build Feature Branching []: a dire il vero, esso è nato alla fine del decennio precedente, ma per schematicità di esposizione lo confiniamo un po’ forzatamente negli anni Dieci…
Si tratta di una ulteriore evoluzione degli approcci Feature Branching visti prima, che però trae vantaggio dallo sviluppo dei nuovi tool. In pratica gli sviluppatori lavorano su feature branches secondarie, idealmente su una base giornaliera. Le varie features poi vengono ricollegate al trunk per i test e il rilascio in produzione. Rispetto a quanto visto con lo Integration Feature Branching, qui diminuiscono drasticamente sia il numero dei rami secondari, sia la loro durata in vita.
Il ruolo cruciale dei tool
Nell’affermazione di questa pratica, ha pesato molto la diffusione e il miglioramento di strumenti quali Mercurial ma in particolare GitHub. In un breve ma significativo tutorial [17], il cosiddetto
GitHub Flow, ossia il flusso di lavoro ideale in GitHub (figura 4), viene illustrato con un testo molto chiaro e una serie di figure animate, che meritano sicuramente un’attenta lettura.
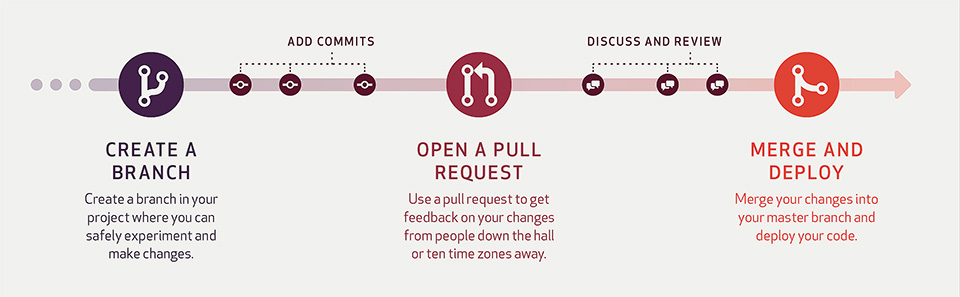
Questo approccio di Build Feature Branching è probabilmente il più diffuso attualmente, perché Git e GitHub sono degli strumenti di ottima qualità, estremamente diffusi e alla portata di tutti, oltre a godere di un’ampia community che fornisce idee e spunti. I dati forniti da StackOverflow [18] relativamente all’uso di strumenti per il version control ci dicono che GitHub è usato in quasi il 70% dei casi: parliamo, stando a dati forniti da GitHub stessa, di circa dieci milioni di utilizzatori con circa venticinque milioni di repository!
È pertanto ovvio che lo strumento finisca per influenzare il flusso di lavoro. Laddove lo strumento è pensato per creare innanzitutto dei branch, lo sviluppatore creerà delle ramificazioni, spesso senza interrogarsi a proposito di tale comportamento.
Compatibilità con Continuous Integration: sì, ma…
Il Build Feature Branching è un approccio che, almeno dal punto di vista ideale e teorico, risulterebbe compatibile con i principi della Continuous Integration. Ci sono però una serie di constatazioni che potrebbero non renderlo tale.
Se infatti è perfettamente compatibile con la CI l’idea di singole feature branches che vengono rivedute e corrette e poi reinnestate nel trunk, in realtà il più delle volte le cose stanno diversamente. I problemi stanno nella durata effettiva delle singole ramificazioni, nella lunghezza delle revisioni e nel meccanismo di build. In breve, il processo ideale è quello riportato in figura 4, ma ciò che accade nella realtà lavorativa di molti team di sviluppo è ciò che si vede [16] in figura 5.
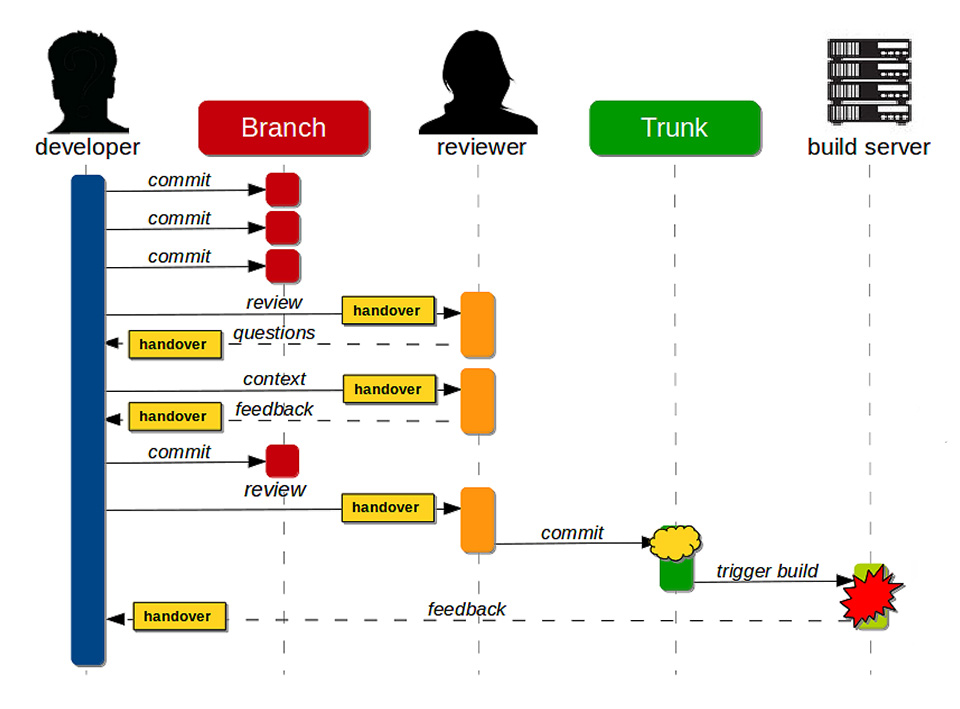
In particolare, succede che i singoli commit si protraggano ben oltre la canonica giornata perché
- gli sviluppatori spesso apportano un grosso numero di cambiamenti in blocco al codice prima della revisione;
- la revisione spesso tarda ad arrivare perché è fatta da altri sviluppatori che comunque devono fare altre cose e magari non sono disponibili al momento adatto;
- le build sono più corpose e prendono più tempo oltre ad avere un tasso maggiore di fallimenti che finisce per “scoraggiare” il gruppo di lavoro.
Attenzione, non è detto che debba essere per forza così. Possono aiutare ad esempio degli step più brevi nelle aggiunte al codice, e il pair-programming che di fatto accorcia nettamente i tempi di revisione, anche se questo miglioramento nella review accade anche perché se ne fa meno “sulla fiducia” e non solo per la reale e indiscussa efficacia del processo di programmazione a coppie così impostato. Una analisi dei tempi di build, della durata della review e degli intervalli che intercorrono tra l’inizio dell’aggiunta al codice e il commit possono fornire indicazioni dei punti del workflow in cui andare a intervenire.
Però, se si vuole aderire precisamente a un processo di Continuous Integration, questi sono aspetti da tenere in considerazione, valutando con franchezza se non sia meglio adottare un modello come il Trunk Based Development.
Conclusioni
In questo articolo abbiamo voluto guardare come la Continuous Integration intesa come approccio sia implementabile attraverso le diverse pratiche di scrittura, branching, revisione e integrazione del base di codice.
Attraverso una panoramica sui diversi tipi di gestione della codebase affermatisi nel passato ventennio, abbiamo voluto mettere in luce come spesso l’adozione di certi tool finisca per influenzare il metodo con cui si pensa e si scrive il software.
La continuous integration è troppo importante per il continuous delivery, e questa considerazione dovrebbe spingerci a valurare sempre se l’adozione di un tool, per quanto facile e potente, non possa in qualche modo andare a intaccare la possibilità reale di avere sempre una base di codice pronta, testata, integrata e rilasciabile.
Luigi Mandarino ha cominciato ad appassionarsi ai computer con il glorioso ZX Spectrum 48k: una bomba, per l‘epoca 🙂 Dopo gli studi di ingegneria, si è dedicato per diversi anni allo sviluppo di applicazioni Java, specie per la piattaforma Enterprise. Successivamente, ha svolto il ruolo di architetto dei sistemi interessandosi particolarmente alle architetture di integrazione. Attualmente, svolge consulenze a svariate aziende in particolare nel settore bancario, assicurativo e finanziario, principalmente su temi inerenti le architetture Java EE e le dinamiche di processo secondo un approccio Lean/Agile.