

Introduzione
In questa serie di articoli parliamo di metriche che ci aiutano nel miglioramento continuo. Nello scorso numero abbiamo discusso di come migliorare la nostra prevedibilità. In questo articolo ci concentriamo su metriche per osservare la qualità del nostro lavoro e per il miglioramento continuo del nostro processo.
Bug per storia: quanti bug abbiamo di solito?
Per osservare la qualità del nostro lavoro utilizziamo una metrica semplicissima: contiamo il numero di bug rispetto al numero di storie.
Notate che quando dico “bug” includo qualsiasi cosa che venga riportata al nostro team come bug: potrebbe essere una funzionalità con comportamenti inaspettati, un requisito mancante, un problema di installazione, performance inadeguate, etc. Considero ognuno di questi casi un problema di qualità nel nostro processo e pertanto voglio contarli e segnalarli. Il termine tecnico più appropriato per questi eventi sarebbe failure demand [1], ma “bug” è più diffuso, oltre che più facile da capire.
Nel vostro contesto la definizione di bug potrebbe essere differente: sta a voi decidere cosa rappresenta una mancanza di qualità.
Come funziona
Molto semplicemente, nel nostro set di dati contiamo il numero di storie e il numero di bug per trovare la percentuale di bug rispetto alle storie.
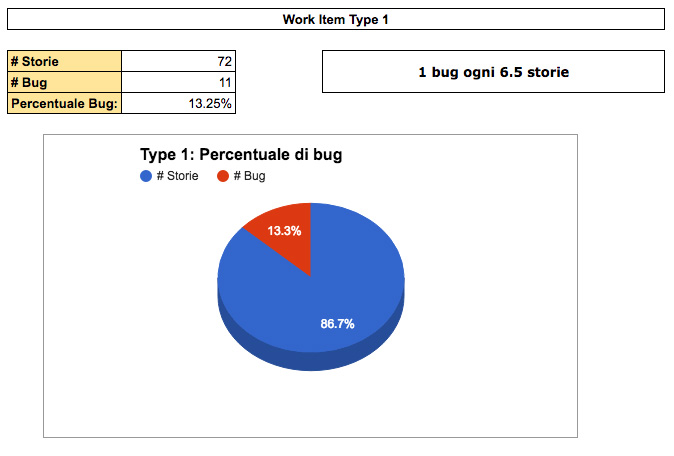
Trovo utile esprimere questa informazione nel formato “1 bug ogni N storie” per renderla più immediata da utilizzare.
Uso: pianificare sufficiente tempo per i bug
Questa informazione è utilissima quando pianifichiamo le storie successive per aiutarci a tenere conto dei bug che troveremo.
Immaginiamo di stare pianificando le prossime 10 storie, e che, come nella figura 1, sappiamo che normalmente troviamo 1 bug ogni 6-7 storie: significa che in realtà dobbiamo pianificare 11 o 12 storie invece di 10, per tenere conto di 1 o 2 bug. Questo ci aiuta molto perché, nel computo delle storie che pianifichiamo, c’è già anche il “di più” determinato dai bug.
Uso: stiamo migliorando?
Monitoriamo il numero di bug che troviamo in ogni iterazione per riscontrare eventuali trend: stiamo trovando più o meno bug del solito? La nostra qualità sta crescendo o diminuendo?
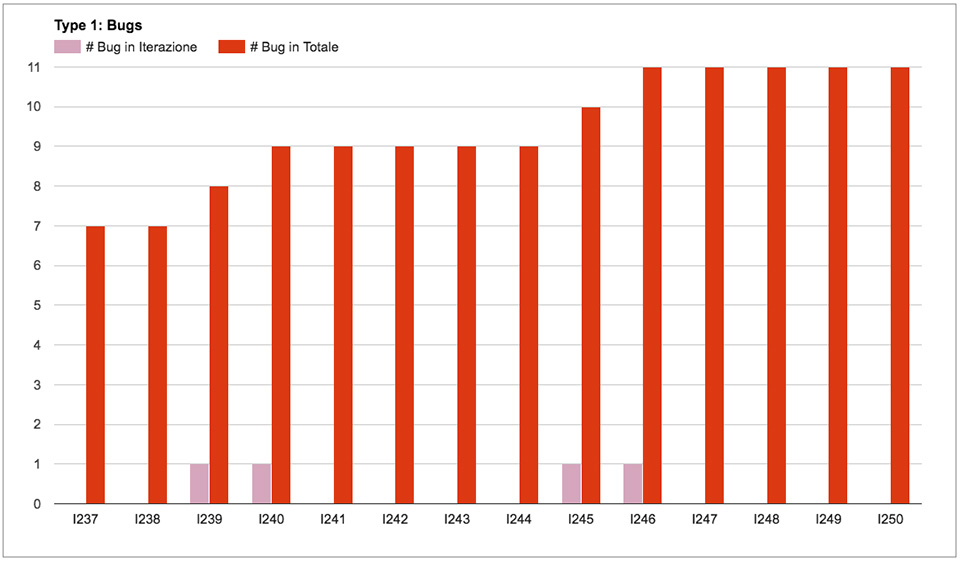
Nel nostro processo, siccome il numero di bug è così basso, possiamo permetterci di fermarci a riflettere ogni volta che ne troviamo uno, per cercare di evitare che si ripeta in futuro.
Uso: dove investire in qualità?
Per ogni bug analizziamo dove è stato trovato, la causa e l’impatto. Con questa analisi possiamo capire in quali fasi del processo abbiamo bisogno di migliorare.
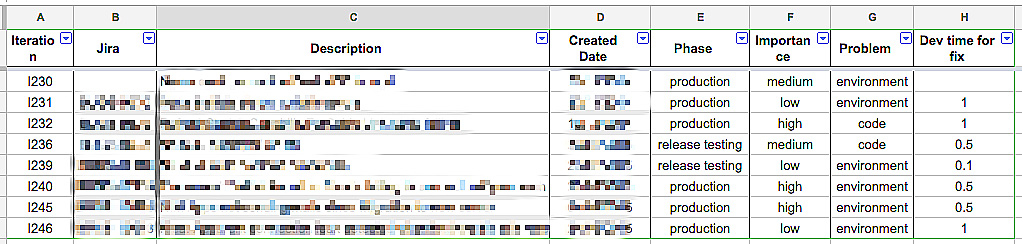
Nel mio team, per esempio, ci siamo resi conto che gli unici bug trovati prima di produzione erano banali problemi di configurazione degli ambienti di test. I bug interessanti invece venivano da produzione. Era quindi meglio concentrarci sul migliorare il monitoraggio delle applicazioni live e ridurre il lead time, così da sistemare i bug in produzione il più in fretta possibile non appena trovati, piuttosto che investire in lunghe e costose fasi di release testing [2] per cercare invano di prevenirli.
Altre metriche per la qualità?
Nel mio team non abbiamo mai avuto la necessità di raffinare troppo queste metriche sulla qualità: contare i bug per noi è abbastanza. Questo un po’ perché, come vedete negli esempi, abbiamo pochi bug, e un po’ perché queste informazioni sono sufficienti a investigare quei pochi che troviamo.
Ma, in altri contesti, magari è il caso di tener traccia di qualsiasi cosa indichi “mancanza di qualità”: per esempio numero di telefonate dal cliente, numero di email che esprimono rabbia e disappunto, quante volte una storia torna indietro e va rifatta, e così via. Si possono poi prendere in considerazione anche aspetti più tecnici come copertura del codice, analisi statica, e così via.
È sempre importante, però, che quando si sceglie una metrica si tenga a mente quanto discusso nel primo articolo della serie [3] riguardo a cosa le rende “buone”. In particolare, bisogna essere sicuri che quello di cui si tiene traccia serva effettivamente a migliorare il sistema, non a puntare il dito verso singoli individui o a farci semplicemente sentire “fighi”.
Flow Efficiency: quanto spreco abbiamo nel nostro processo?
In ogni processo solitamente si hanno alcuni stati che consideriamo come “stati che aggiungono valore” e altri stati che invece consideriamo come “code” o “in attesa”.
Nel processo del mio team, per esempio, consideriamo come stati che aggiungono valore quelli dove qualcuno sta direttamente lavorando sulla storia, come development e functional testing. Gli altri stati invece sono semplicemente code tra uno stato e l’altro, dove la storia è in attesa che avvenga qualcosa: per esempio next è l’attesa che uno sviluppatore sia libero per tirare la storia in development; wait for test o dev done è l’attesa che un tester sia libero per testare la storia, e così via.
Chiamiamo Flow Efficiency [4] la percentuale di tempo che una storia passa in stati che aggiungono valore. L’efficienza del flusso di lavoro, in tal senso è opposta agli sprechi. In Lean le code sono considerate come uno dei 7 tipi di spreco [5]. Tuttavia io preferisco usare il termine “potenziale di miglioramento” invece di “spreco” per promuovere una mentalità dove i problemi non sono visti come tali ma bensì come opportunità per migliorare.

Un ottimo esercizio per identificare quali stati aggiungono valore e quali no è il value stream mapping [6], una pratica in cui il team analizza e descrive gli step di processo necessari per concludere una attività, realizzando un “modello” del flusso per capire dove si crea valore.
Come funziona
Ogni barra nel grafico rappresenta una storia e mostra la percentuale di tempo che la storia ha passato in coda. Sotto al grafico riportiamo la media di quanto tempo in percentuale le storie passano in stati che aggiungono valore o in code. (figura 5).
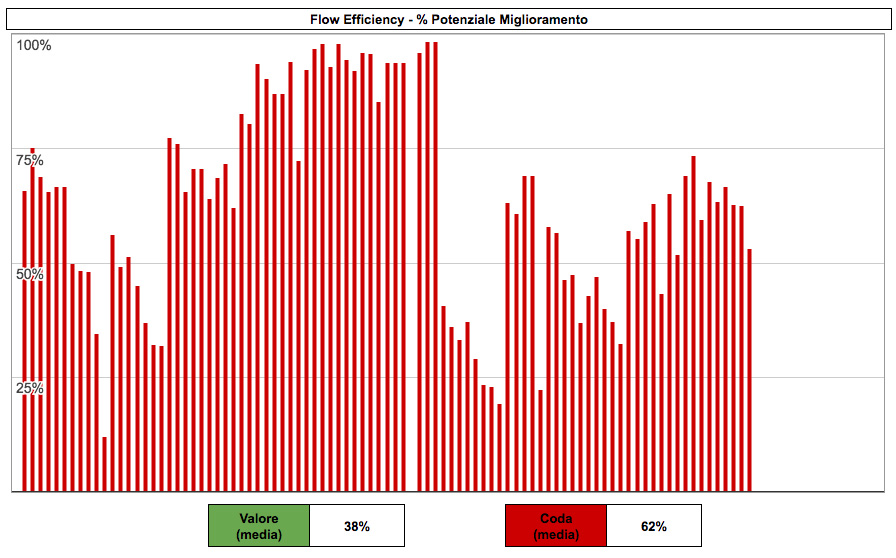
Uso: ridurre le code
È scioccante osservare quanto bassa sia la Flow Efficiency in molti processi. La figura 5 fa riferimento al mio team, che considero avere un processo ragionevolmente maturo: ciò nonostante, per la maggior parte delle storie la percentuale di spreco supera il 50%, e spesso va anche fino a 80%-90%! In media, 62% del tempo di una storia è speso in coda senza che nessuno ci stia lavorando, risultando in una Flow Efficiency del 38%.
Questa informazione è la prova che, se vogliamo veramente migliorare, non serve a niente puntare il dito verso le persone e dire “lavora più sodo!”; quello su cui dobbiamo concentrarci è ridurre le code.
Ridurre le code non è facile. Lean e Kanban offrono diverse strategie che vediamo nei punti seguenti.
- Ridurre il WIP: più i singoli individui sono occupati, più la storia dovrà aspettare in coda perché qualcuno sia libero. Abbassando il Work In Progress le storie attualmente in corso sono concluse più velocemente, riducendo di conseguenza il tempo di attesa per le altre. Ridurre il WIP rappresenta una vera e propria “rivoluzione” nell’approccio: ci si concentra a migliorare l’efficienza dell’intero flusso invece che a tenere le persone occupate il più possibile. È un cambiamento di paradigma dalla efficienza delle risorse all’efficienza del flusso [7].
- Ridurre il batch size: per evitare che le storie in coda si accumulino, eseguiamo le nostre azioni più spesso ma in blocchi più piccoli. Esempio: rilasci più frequenti ma di poche funzionalità alla volta; testare una o due storie alla volta e così via. Insomma, come si sente dire per le diete, no alle “abbuffate”, sì a piccoli pasti frequenti e bilanciati.
- Creare un team di persone con competenze cross-funzionali: molte delle code sono causate da passaggi di consegne interni al team. Per esempio, quando la storia passa da uno sviluppatore a un tester, occorre aspettare che un tester sia libero; e lo stesso accade quando a storia passa da analisi in sviluppo. Persone veramente cross–funzionali potrebbero invece lavorare sulla storia dall’inizio alla fine, riducendo i tempi di attesa tra diversi “specialisti”.
Attenzione però: migliorare l’efficienza del flusso non significa eliminare totalmente questi stati di coda dal nostro processo; anche le code sono necessarie per creare buffer tra diversi step e rendere il processo più fluido. Quello che ci interessa è invece che le storie restino nello stato di coda il meno possibile.
Tempo di rilascio: quanto tempo serve a rilasciare?
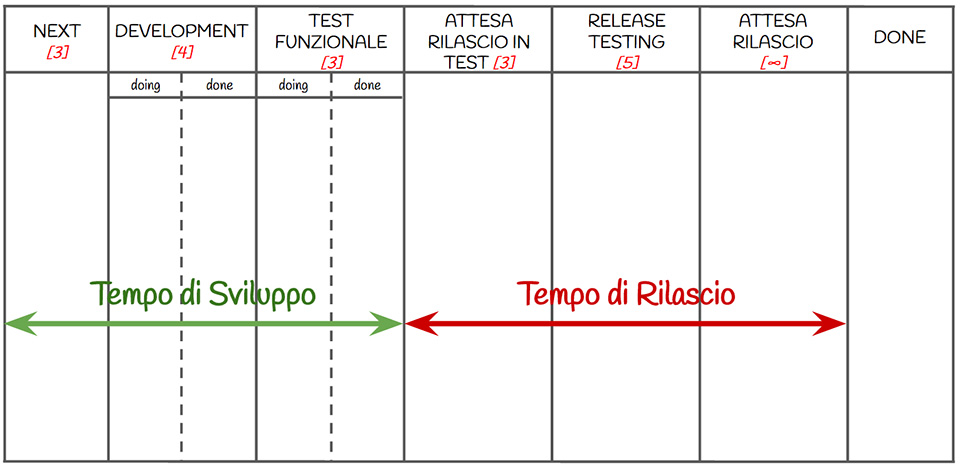
Una metrica particolarmente interessante per chi vorrebbe fare Continuous Delivery è il Tempo di rilascio: dal momento in cui è dichiarata come “sviluppo completato”, quanto tempo impiega una storia ad essere rilasciata in produzione?
Come funziona
Anzitutto, dividiamo il nostro processo in due parti:
- tempo di sviluppo cheinclude quegli stati necessari per l’implementazione della storia (p.e.: analisi, sviluppo e testing);
- tempo di rilascio che include quegli stati necessari perché la storia sia effettivamente rilasciata in produzione (p.e.: attesa di fine iterazione, creare un nuovo artifact, essere installata in altri ambienti).
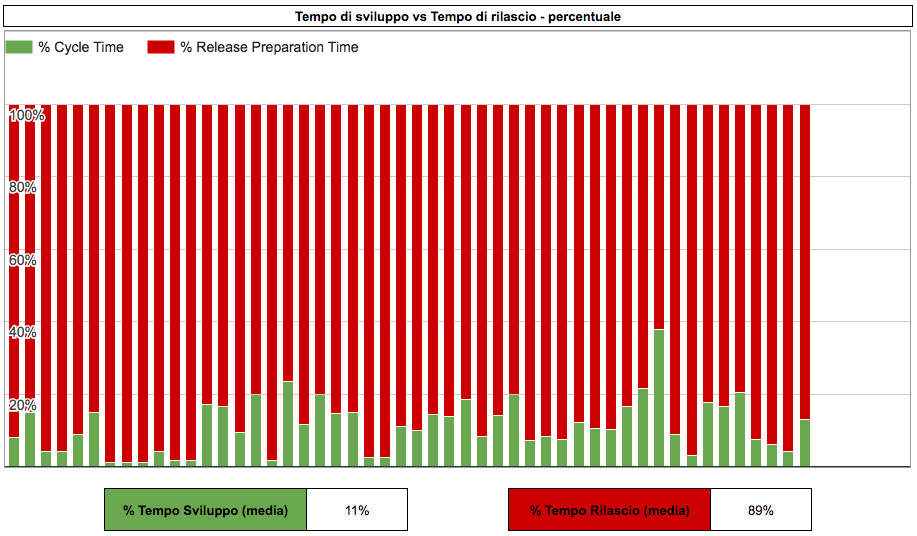
Per ogni storia, calcoliamo la percentuale di tempo di rilascio rispetto al tempo di sviluppo. Sotto al grafico riportiamo anche la media di quanto tempo in percentuale le storie passano nei due stadi.
Uso: iterazioni più veloci
Chi di noi lavora in processi iterativi (p.e.: Scrum) probabilmente scoprirà che un’alta percentuale di tempo è spesa in Tempo di rilascio: questo accade perché le storie devono attendere la fine dello sprint per essere poi rilasciate.
Un tempo di rilascio elevato è il risultato di rilasci in batch troppo grossi: cadiamo nella trappola di aspettare di avere un certo numero di storie prima di effettuare un rilascio [8]. È sintomo che il nostro processo di rilascio è troppo costoso, per problemi tecnici o “politici”. Dobbiamo risolvere questi problemi per ridurre il costo e rendere conveniente rilasciare più spesso.
Quando rilasciare costa poco, possiamo accorciare le nostre iterazioni fino a lavorare in un flusso continuo e rilasciare ogni storia non appena è pronta: è il cosiddetto Continuous Delivery [8], il rilascio continuo.
Uso: migliorare le discussioni con l’uso di dati
Metriche come questa sono un esempio di come possiamo usare i dati a nostra disposizioni per avere discussioni migliori: invece di dibattere su opinioni personali si parla di fatti e dati reali.
Molto probabilmente quando iniziate a proporre di fare Continuous Delivery, trovate qualcuno contrario all’idea: vi diranno che non ne vale la pena, che è troppo rischioso, che avete sempre seguito questo processo e che funziona bene, e via così. Con questi dati potete lasciare fuori dalla discussione pareri soggettivi e dimostrare l’enorme valore che ricavereste dal rilasciare più spesso e in “infornate” più piccole.
Tempo per stato: dove dobbiamo migliorare?
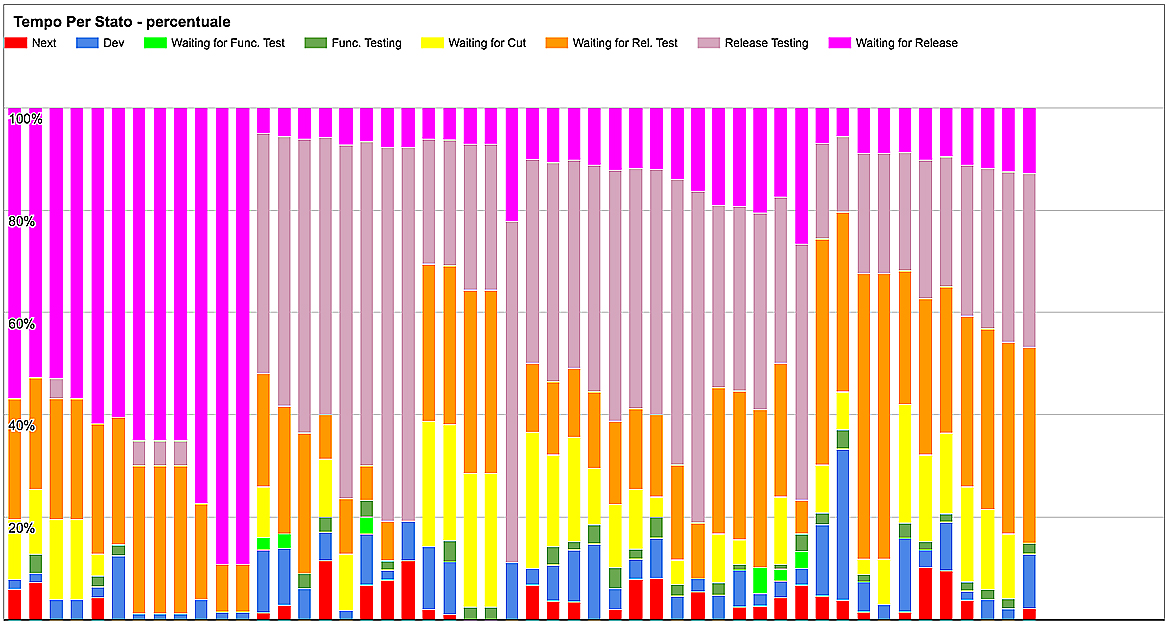
Per ogni storia, osserviamo quanto tempo in percentuale trascorre in ogni stato. Ci aiuta a capire quali stati sono più lenti e a rispondere alla domanda “dove dobbiamo migliorare?”.
Uso: NON aggiungere sviluppatori al team (per ora)!
Avete presente quando state lavorando su un progetto problematico e il “capo”, credendo di aiutarvi, aggiunge sviluppatori al team per andare più veloci? Bene, questo grafico dimostra che è una perdita di tempo!
Nel grafico in esempio il tempo di sviluppo è rappresentato dalla parte in blu: vedete quanto poco impatto ha lo sviluppo sul tempo totale? Nel vostro processo potrebbe andare meglio — magari per la vostra situazione la differenza non è così drastica — ma mi aspetterei che comunque lo sviluppo sia solo una piccola parte rispetto al tempo dell’intero processo.
Se vogliamo veramente migliorare dobbiamo concentrarci sul migliorare le altre parti del processo, non lo sviluppo. Se anche riuscissimo a migliorare lo sviluppo, avremmo un impatto solo su una piccola parte.
È purtroppo molto comune puntare il dito verso gli sviluppatori quando qualcosa va storto e ordinar loro di lavorare di più, fare straordinari, lasciar stare i test che “tanto poi facciamo i test manuali”… Sappiamo bene che queste cose hanno l’effetto contrario [10]; ma, se per assurdo, comunque funzionassero e riuscissimo a ridurre la percentuale di barra blu, avremmo risolto poco. È solo migliorando il resto del processo che possiamo avere un reale impatto su di esso!
Conclusione
In questo articolo abbiamo discusso di metriche per osservare la qualità e per il miglioramento continuo. Questo numero conclude l’analisi sulle varie metriche che possiamo usare per migliorare il nostro processo.
Nel prossimo e ultimo articolo parleremo di “probabilistic forecasting” e di come utilizzare i dati a nostra disposizione per “stimare” gruppi di storie o interi progetti.
Riferimenti
[1] Failure Demand
https://leanandkanban.wordpress.com/2009/05/24/failure-demand/
[2] Release Testing Is Risk Management Theatre
[3] Mattia Battiston, Metriche Kanban per il miglioramento continuo – I parte: Uno sguardo alle metriche per il flow, MokaByte 214, febbraio 2016
http://www.mokabyte.it/2016/02/kanbanmetrics-1/
[4] Flow Efficiency
http://scrumandkanban.co.uk/flow-efficiency/
[5] Come gestire i 7 tipi di spreco nello sviluppo agile
[6] Value Stream Mapping
http://www.slideshare.net/AgileOnTheBeach/value-stream-mapping-9358435
[7] Resource efficiency vs. Flow Efficiency
[8] Reduce batch size – an effective way to improve efficiency
[9] Continuous Delivery
http://martinfowler.com/bliki/ContinuousDelivery.html
[10] Fred Brooks, The Mythical Man-Month, Addison-Wesley, 1995
Mattia Battiston è un software developer con una grande passione per il miglioramento continuo. Attualmente lavora a Londra e utilizza Kanban, Lean e Agile per aiutare diversi team a migliorare.