

Introduzione
Nel precedente articolo, il terzo della serie dedicato alla suite di BPM di Bizagi, oltre ad avere visto le principali funzioni di modellazione e documentazione dei processi di business disponibili in Bizagi Modeler, abbiamo accennato alle funzioni di simulazione presente in questo ambiente.
Le funzioni di simulazione consentono, stabilito un periodo di osservazione sufficientemente lungo, di valutare le prestazioni del modello di un processo al variare delle configurazioni, con lo scopo di aumentare le probabilità di soddisfare le specifiche, eliminare i colli di bottiglia, eliminare sotto- o sovrautilizzazioni di risorse — di personale, attrezzature, sistemi software — e di ottimizzare le prestazioni.
In questo articolo vedremo cosi si intende per simulazione, e poi passeremo ad approfondire come in Bizagi Modeler è permessa la simulazione di un modello di processo, almeno per quanto riguarda i primi livelli. Nel prossimo articolo, completeremo la discussione sulla simulazione
Cosa si intende per simulazione
La simulazione è sicuramente la più popolare tecnica di analisi quantitativa di un modello di processo. In termini essenziali, l’idea alla base è semplice: in un periodo di tempo definito, abbastanza ampio, vengono generate un largo numero di ipotetiche istanze di processo e, per ciascuna di queste esecuzioni, vengono raccolti i risultati sulle prestazioni in termini di utilizzo medio delle risorse, tempo medio di attesa di ciascuna attività, end-to-end process time ed altri dati.
La tecnica è molto versatile in quanto si può applicare per eseguire due tipi di analisi: sia la as-is analysis che la what-if analysis [1].
Analisi as-is
La as-is analysis è relativa al modello di un processo attualmente in esecuzione nell’organizzazione, riguardo al quale disponiamo di alcuni dati, relativi ad esempio a quali prestazioni sta effettivamente avendo nella realtà.
Analisi what-if
La what-if analisys può essere usata per esempio per un processo to-be che deve essere automatizzato. In questo caso, si confrontano i risultati di diverse configurazioni al fine di identificare quella che meglio soddisfa i requisiti.
La simulazione in Bizagi
In Bizagi ci sono quattro livelli di simulazione:
- Level 1: Process Validation
- Level 2: Time Analysis
- Level 3: Resources Analysis
- Level 4: Calendars Analysis
Ciascun livello richiede che il diagramma del processo sia arricchito di informazioni che aggiungono via via maggiore complessità, ma che al contempo consentono un’analisi completa e coerente del processo. I livelli non sono interdipendenti, quindi, volendo, si può partire da qualsiasi livello senza necessariamente partite dal primo. Va comunque detto che è una best practice iniziare la simulazione dal primo livello e progredire a mano a mano di un livello per volta andando nei successivi.
Per ciascun livello di simulazione si eseguono i seguenti passaggi:
- si raccolgono le informazioni di processo per la simulazione;
- si crea il modello di simulazione aggiungendo le informazioni raccolte;
- si esegue la simulazione;
- si analizzano i dati risultanti dalla simulazione.
Il concetto di Token
Per parlare di simulazione dobbiamo però introdurre prima il concetto di token. Il token è un concetto teorico che è usato come aiuto per definire il comportamento di un processo quando viene eseguito. Deve essere inteso come un marker mobile che, quando una istanza di processo è stata generata, viene usato per identificare il progredire (lo stato) del processo. I token sono creati nello start event, si muovono attraverso i vari elementi — non in un message flow— che compongono il modello del processo finché vengono distrutti nell’end event.
Creare ed eseguire i modelli di simulazione
Per creare ed eseguire un modello di simulazione in Bizagi si eseguono i passi che vediamo di seguito, illustrati dalle immagini.
Si seleziona il bottone Simulation View e, se il diagramma non presenta errori, questo sarà aperto in modalità read only – simulation mode.
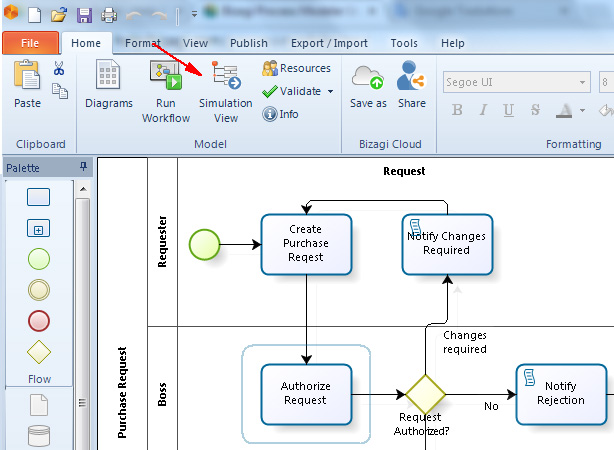
A seconda del livello di simulazione, vengono evidenziati gli elementi che richiedono le informazioni aggiuntive.
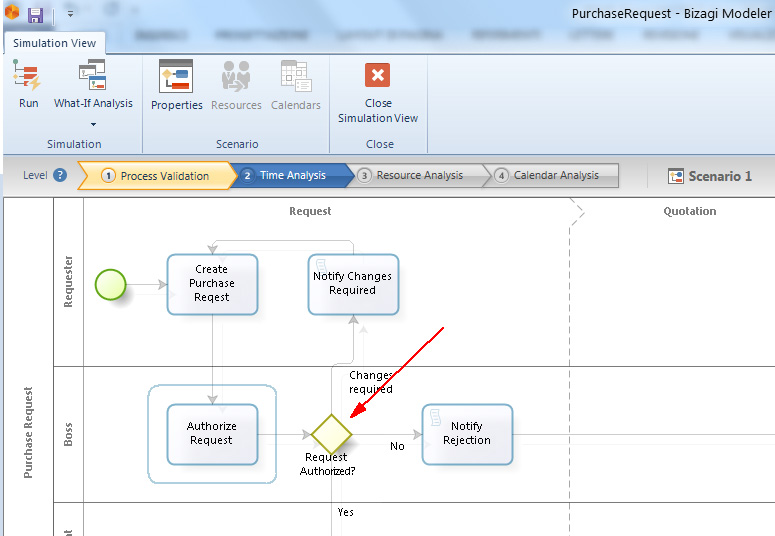
Si seleziona ciascun elemento e si inseriscono le informazioni richieste.
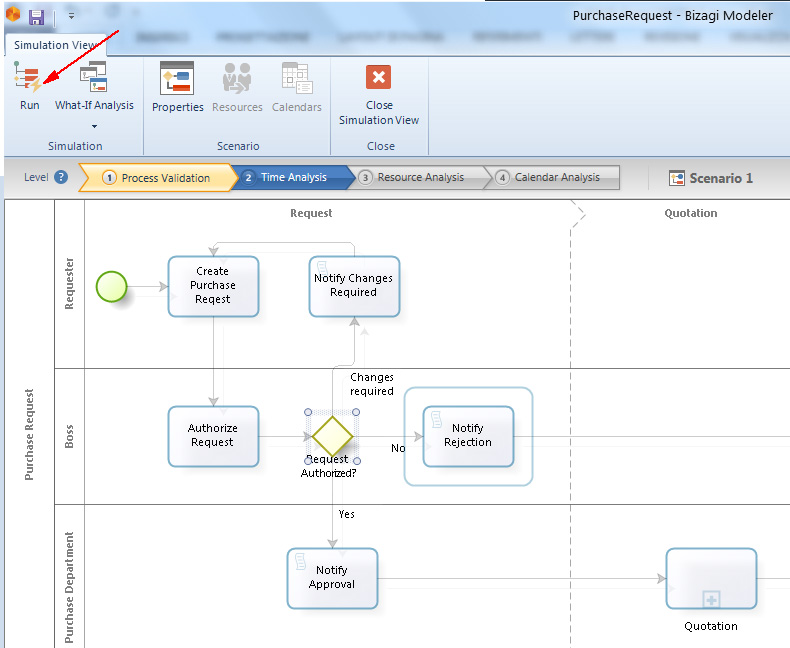
Una volta che tutte le informazioni aggiuntive richieste sono state inserite, si clicca su Run per lanciare la finestra Process Simulation.
Si clicca su Start per eseguire la simulazione. Durante la simulazione verrà mostrata un’animazione del processo e il flusso dei tokens tra le attività.
Quindi si clicca sul bottone Stop per terminare la simulazione.
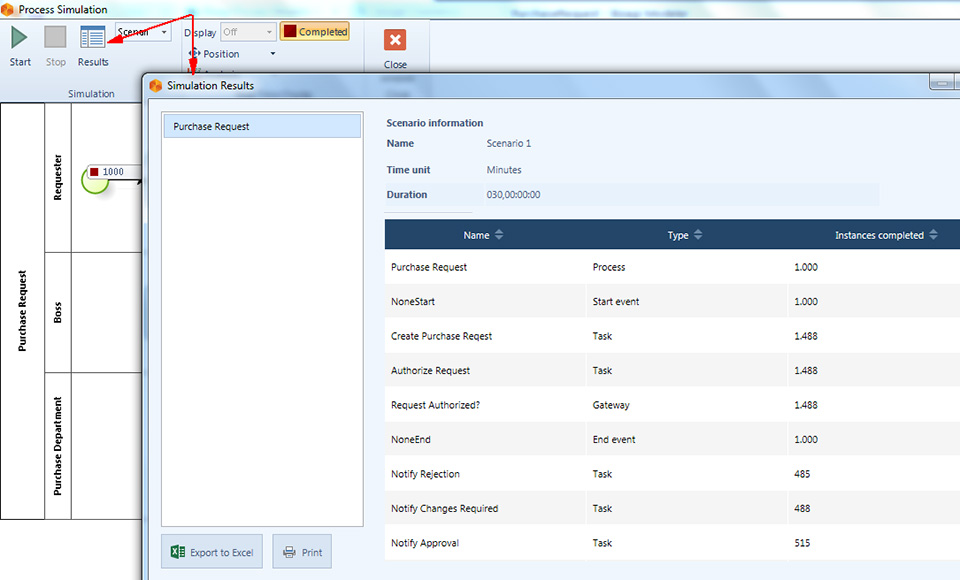
Conclusa la simulazione si clicca su Results per visualizzare i risultati.
Dopo aver analizzato i risultati, si eseguono i successivi livelli di simulazione ripetendo i passi dal secondo al sesto.
Level 1. Process Validation
Questo primo livello di simulazione permette di validare il modello del processo andando a verificare che siano attraversati tutti i percorsi — sequence flows— e che tutte le istanze di processo create arrivino tutte a conclusione.
Dati in input
Per questo livello vanno fornite alcune informazioni, anzitutto Max.arrival count che definisce il numero di token — istanze di processo— che verranno create. È consigliato definirne un numero alto, per ottenere dei risultati finali affidabili.
Per inserire questo dato bisogna selezionare lo Start Event e cliccare sull’icona Gear, quindi si inserisce il dato nel campo Max.arrival count nella finestra a comparsa che appare:
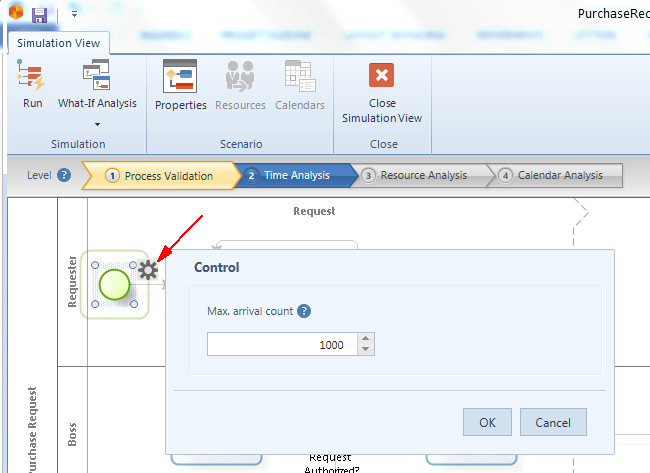
In realtà la simulazione finirà quando si verifica una delle due seguenti opzioni: la durata dello scenario è raggiunta o il numero massimo di istanze create è stato raggiunto.
La durata dello scenario è definita nella configurazione dello scenario che vedremo in seguito.
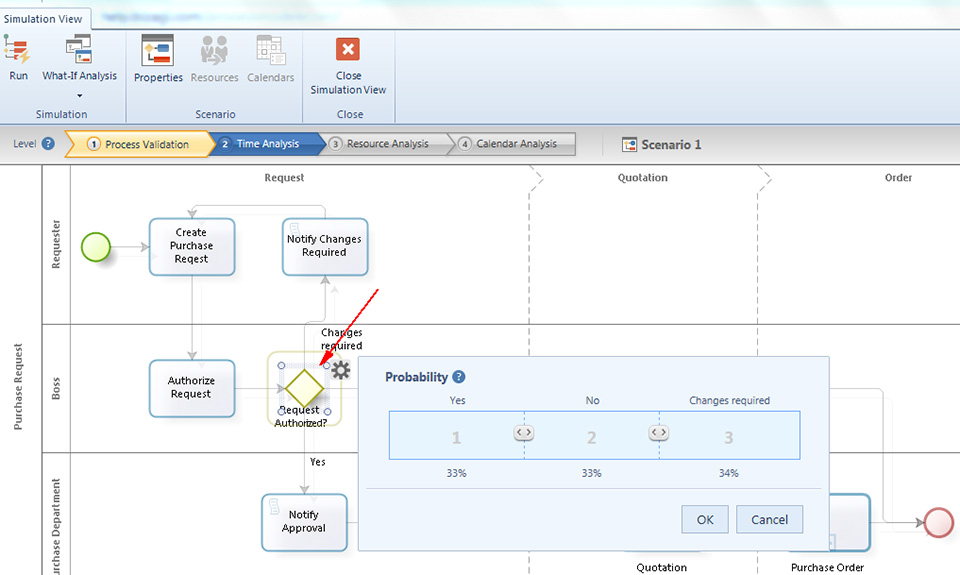
L’altro dato da fornire è Gateways routing: definisce la probabilità di attraversamento di ciascun alternative sequence flow o ramo di uscita di un inclusive and exclusive gateway. Le probabilità variano da 0 a 100%. Per inserire questo dato si seleziona e si sposta a destra o sinistra l’icona < > :
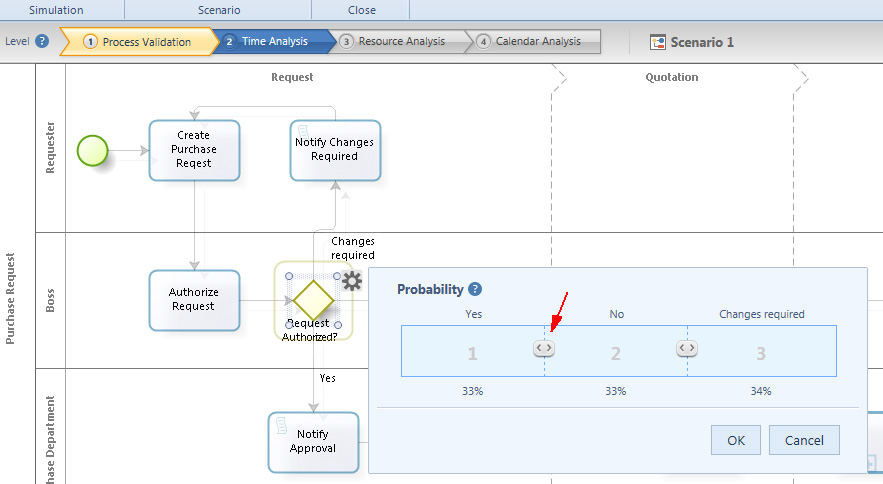
Se non viene definita nessuna probabilità questa viene distribuita equamente.
Esecuzione della simulazione
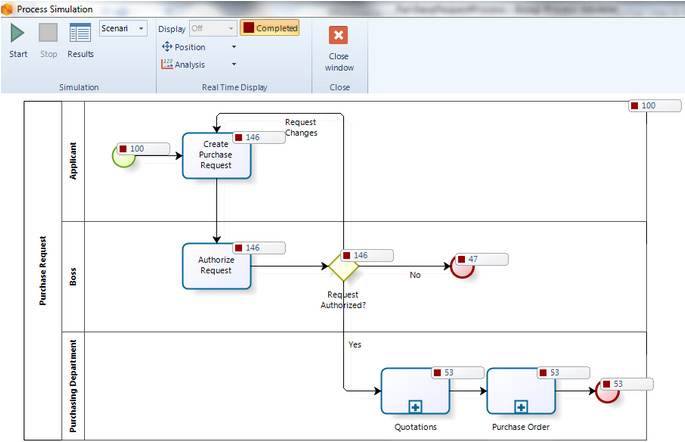
Inserite le informazioni necessarie, a questo livello si seleziona il bottone di Run — come visto in un paragrafo precedente — per eseguire la simulazione. Durante l’esecuzione vengono visualizzati i seguenti dati:
- il numero di token che hanno raggiunto l’End Event;
- il numero di token che sono creati nello Start Event;
- il numero di token che hanno attraversato ciascun elemento del processo;
- il numero di istanze di processo che si sono concluse.
Risultati
Quando la simulazione è terminata, si seleziona il bottone Results per vedere i risultati.
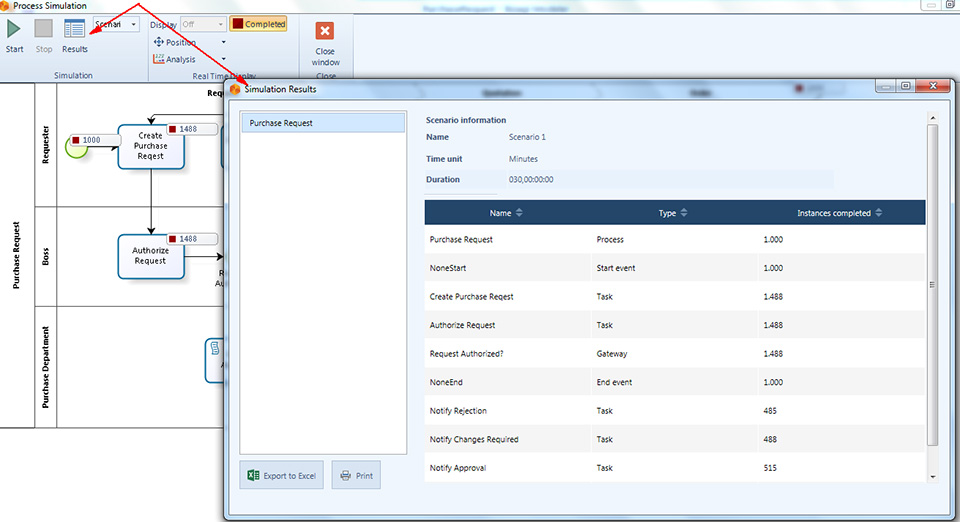
Questo primo livello di simulazione presenta le seguenti informazioni:
- Name: identifica lo specifico elemento del diagramma per il quale viene mostrato il dato;
- Type:identifica il tipo di elemento;
- Instance completed: indica quanti token hanno attraversato quell’elemento, cioè quante volte quell’elemento è stato interessato da un’istanza di processo durante l’esecuzione della simulazione.
Nell’analizzare i risultati, una prima verifica da fare è quella di controllare se il numero dei token creati nello start event è uguale alla somma dei token che hanno raggiunto gli end event. Se questo non dovesse risultare vuol dire che il diagramma del processo è errato ed è necessario rivederlo.
Level 2. Time Analysis
Questo secondo livello di simulazione è utile per misurare l’end-to-end process time oltre che il processing time di ciascuna attività.
Per end-to-end process time (cycle time o throughput time) si intende il tempo necessario per elaborare un token dall’inizio sino alla fine del processo. A sua volta, il processing time (service time) definisce il tempo necessario ad una attività per elaborare un token dal momento in cui questo arriva all’attività stessa. Questo tempo è legato alla disponibilità delle risorse assegnate alla esecuzione dell’attività.
Un’altra utile misura per valutare le performance di un processo, che vedremo nel successivo livello di simulazione, ma che per completezza definiamo in questo paragrafo, è il waiting time ossia, il tempo di attesa prima che un token venga preso in considerazione da una risorsa per essere elaborata. Il waiting time include il tempo di coda, dovuto al fatto che nessuna risorsa è disponibile per elaborare il token, e altri tempi di attesa, per esempio quello dovuto ad una sincronizzazione che deve avvenire con un altro processo o quello dovuto all’attesa di un input da un cliente o un altro attore esterno.
In questo livello di simulazione viene considerato il best case scenario, cioè che siano disponibili un numero infinito di risorse, il che evita ritardi e tempi di attesa. Ovviamente, nella realtà, non è mai così e questi vincoli verranno presi in considerazione nel successivo livello di simulazione.
Dati in input
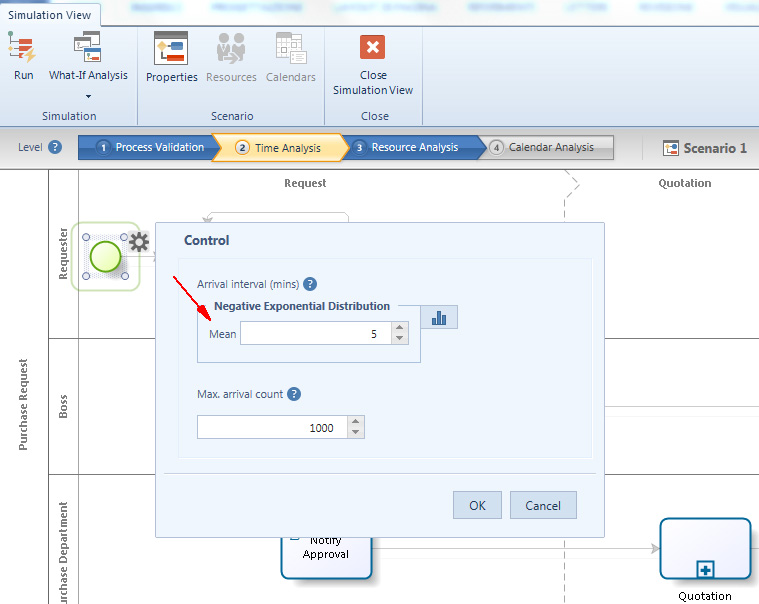
Anche per questo livello vanno fornite diverse informazioni. Si comincia con lo arrival interval time, vale a dire l’intervallo di tempo che trascorre tra la generazione di due istanze di processo. Le istanze saranno create sino a che non sarà raggiunto un numero massimo di istanze create.
Per inserire questo dato bisogna selezionare lo Start Event e cliccare sull’icona Gear; quindi i dati si inseriscono nei campi Arrival Interval (min) e Max Interval count nella finestra che appare.
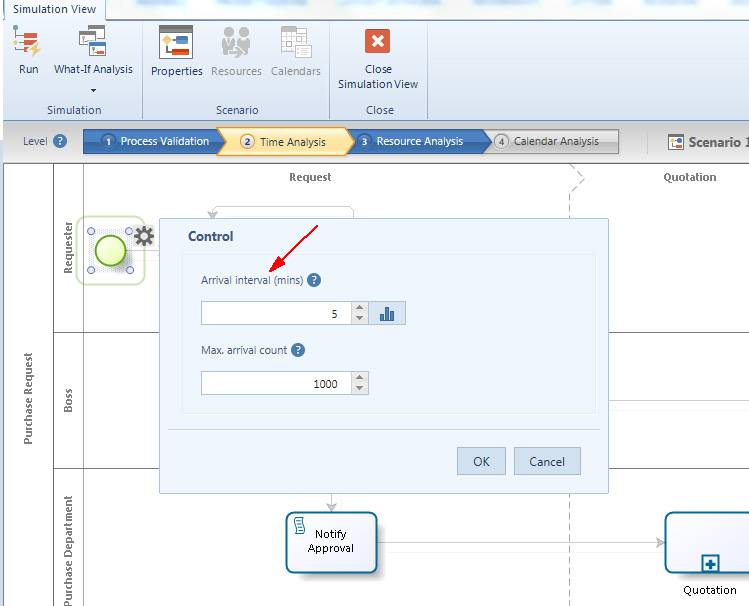
Nell’esempio mostrato nella figura sopra è stato inserito un valore numerico costante per l’Arrival Interval (min) ma cliccando l’icona accanto al campo si apre una finestra dove si può selezionare una distribuzione statistica.
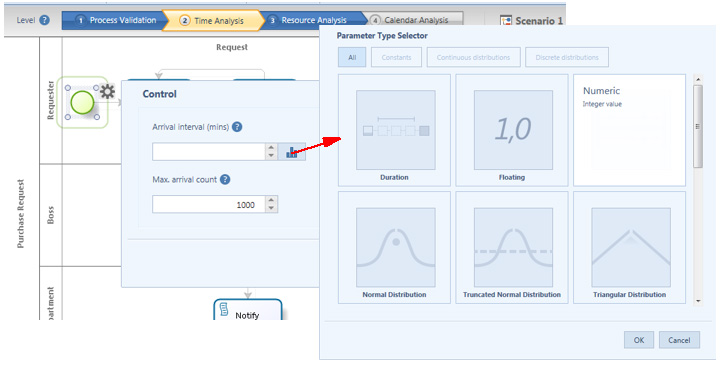
Una volta selezionata la distribuzione si dovrà inserire il parametro di definizione relativo. Per esempio, se le istanze sono create in maniera esponenziale, allora si dovrà definire la media.
Si fornisce poi il dato di processing time vale a dire il tempo che trascorre dal momento in cui un token arriva a una attività sino a quando questo è elaborato e passato al successivo elemento del processo.
Per inserire questa informazione, si seleziona l’attività, si clicca sull’icona Clock, quindi si inserisce il valore nel campo Processing time.
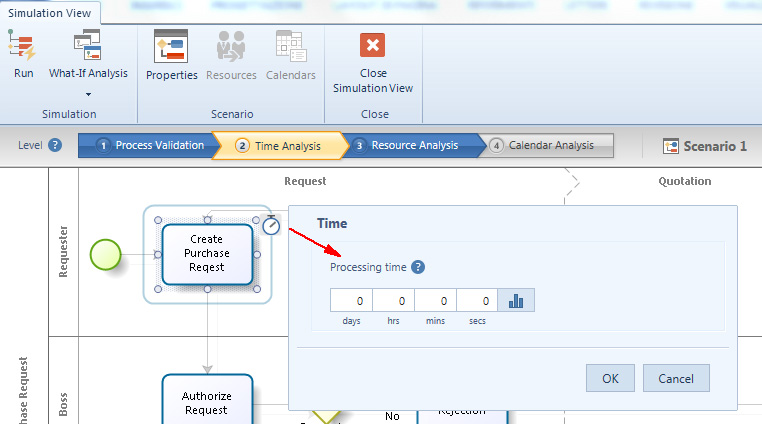
Anche per questa informazione si può selezionare una distribuzione statistica nella finestra che appare cliccando sull’icona accanto al campo.
Esecuzione della simulazione
Inserite le informazioni necessarie a questo secondo livello, si seleziona il bottone di Run per eseguire la simulazione. Durante l’esecuzione, vengono visualizzati i seguenti dati:
- Il numero dei token completati;
- Il processig time medio per ciascuna attività;
- Il processing time totale per le attività.
Risultati
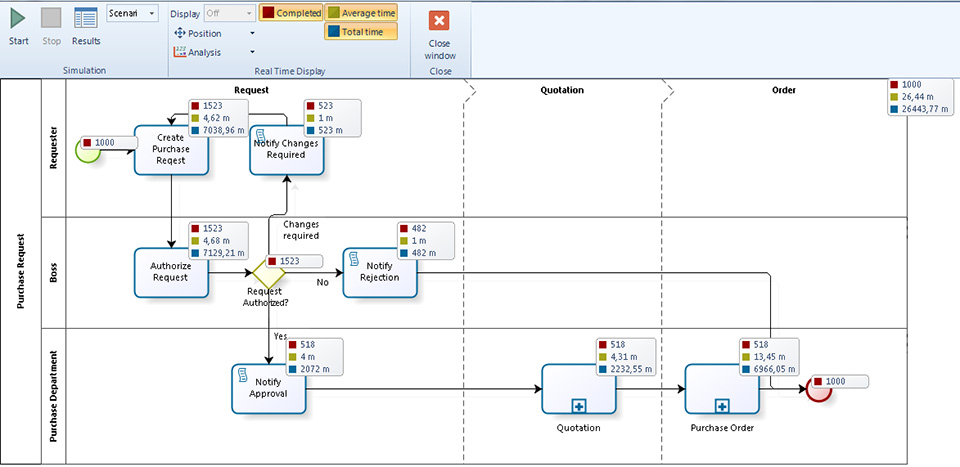
Quando la simulazione è terminata si possono vedere le seguenti informazioni:
- Name:identifica lo specifico elemento del diagramma per il quale viene mostrato il dato;
- Type:identifica il tipo dell’elemento;
- Token completed: indica quanti token hanno attraversato quell’elemento, cioè quante volte quell’elemento è stato interessato da un’istanza di processo durante l’esecuzione della simulazione;
- Token started: indica quanti token sono arrivati a quell’elemento;
- Minimum time: indica il processing time minimo per quell’elemento;
- Maximum time: indica il processing time massimo per quell’elemento;
- Average time: indica il processing time medio per quell’elemento;
- Total time: indica il processing time totale per quell’elemento.
Chiaramente il Minimum, il Maximum e l’Average time differiscono quando per il Processing time è stata selezionata una distribuzione statistica.
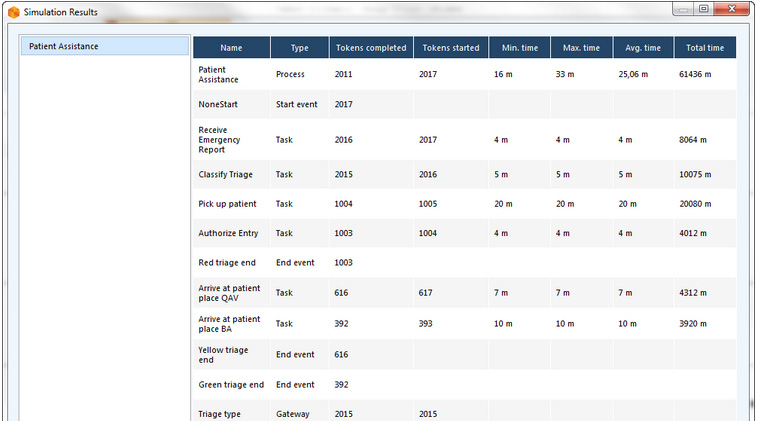
Nell’esempio mostrato nella figura 17 si legge come per esempio l’attività Classify Triage è durata minimo 4 minuti, al massimo 4 minuti, in media 4 minuti.
Inoltre viene indicato che il processing time del processo complessivo Patient Assistance è durato minimo 16 minuti, al massimo 33 minuti, in media 25 minuti e spiccioli.
I risultati sono tanto più affidabili quanto più tempo dura la simulazione.
Conclusioni
In questo articolo abbiamo iniziato ad approfondire la simulazione di un modello di un processo. Abbiamo detto che è la tecnica più diffusa di analisi quantitativa di un modello di processo, che è utile sia per le analisi As-is che per definire i processi To-be in quanto permette anche delle analisi di tipo What-if di diverse configurazioni del modello.
Abbiamo visto i primi due livelli di analisi, Process Validation e Time Analysis, e nel prossimo articolo continueremo affrontando il terzo e quarto livello, Resources Analysis e Calendars Analysis.