

Introduzione
Nello scorso articolo avevamo cominciato l’analisi delle funzionalità di simulazione presenti in Bizagi Modeler. Come detto, la simulazione ha lo scopo di valutare le prestazioni del modello di un processo al variare delle configurazioni. Lo scopo è chiaramente quello di aumentare le probabilità di soddisfare le specifiche, eliminare i colli di bottiglia, eliminare sotto- o sovrautilizzazioni di risorse — di personale, attrezzature, sistemi software — e di ottimizzare le prestazioni.
Level 3. Resources Analysis
Questo livello consente di analizzare il potenziale effetto delle risorse (persone, sistema software, attrezzature) sulle prestazioni del processo.
Questo tipo di simulazione considera quindi una situazione più realistica rispetto al precedente livello di analisi che assumeva una capacità infinita di risorse per la elaborazione di una quantità infinita di token nello stesso tempo. Nella realtà ci sono sempre dei vincoli di disponibilità di risorse.
Il primo effetto che risulterà dall’introduzione di un constraint sulla disponibilità di risorse è che alcuni token, in un dato momento, dovranno aspettare per essere elaborati con conseguenze quindi sulla creazione di colli di bottiglia (bottleneck) e con l’aumento del cycle time medio, il tempo medio per completare/portare a chiusura un processo dall’inizio alla fine.
L’elemento economico è un’altra risorsa che direttamente o indirettamente è coinvolta in un processo quando vengono assegnate più o meno risorse, di conseguenza questo livello permette di analizzare il processi anche in termini di costo.
In definitiva questo livello di analisi consente di valutare le seguenti misure di performance del processo:
- la sovra- o sottoutilizzazione delle risorse;
- il costo totale delle risorse;
- il costo totale delle attività;
- il ritardo, tempo che una attività attende per una risorsa;
- una stima del cycle time atteso.
Dati in input
Per questo livello vanno fornite diverse informazioni.
La prima è Resources, vale a dire le risorse totali disponibili per il processo. Per inserire questo dato bisogna selezionare il bottone Resources sul ribbon, quindi si seleziona ancora Resources nella popup window che appare e che che porta al popup dove si inseriscono le risorse (figura 1).
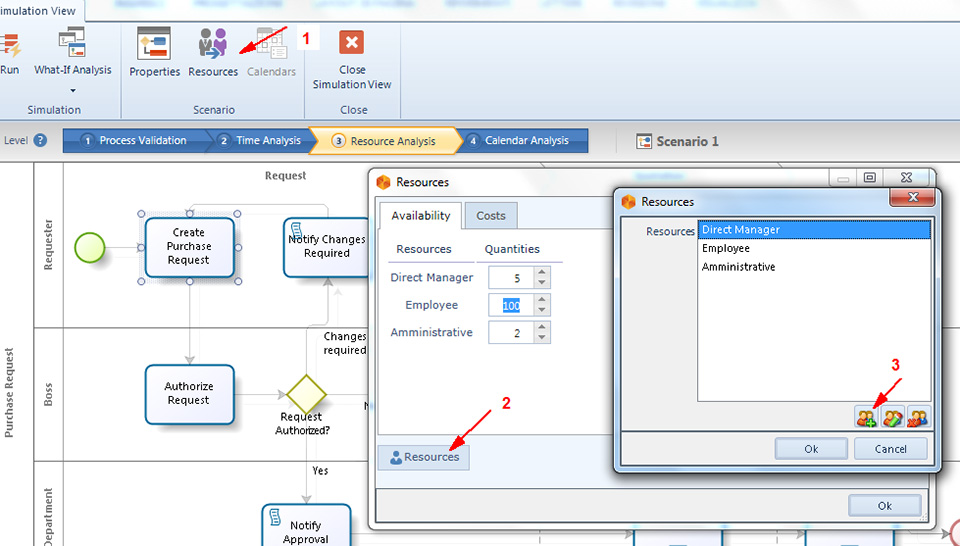
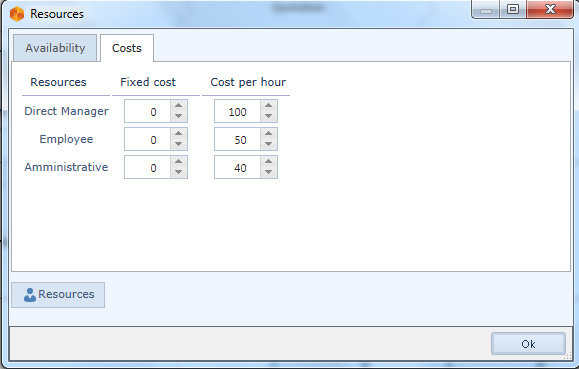
La seconda informazione da fornire rappresentata da Availability e costs of resource, che indicano rispettivamente quante risorse di un dato tipo sono disponibili e il relativo costo. Per indicare la disponibilità bisogna inserire i dati nei campi che sono presenti nel tab Availability della finestrella mostrata in figura 1. Per indicare il costo, fisso o per ora, bisogna inserire i dati nei campi che sono presenti nel tab Costs della stessa finestrella (figura 2).
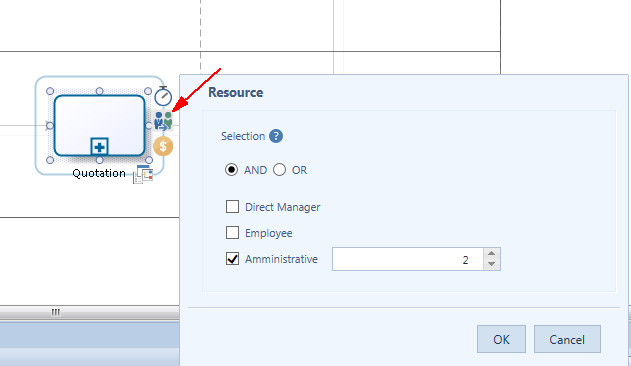
Resource Requirements reppresentano un’altra informazione da fornire: sono le risorse richieste da ciascuna attività. Per definire questo dato si seleziona l’attività, si clicca sulla icona Resource quindi nei campi della finestrella che appare si inserisce il dato richiesto e, mediante l’AND/OR, si definisce se servono tutte le risorse allo stesso tempo o una sola per volta (figura 3).
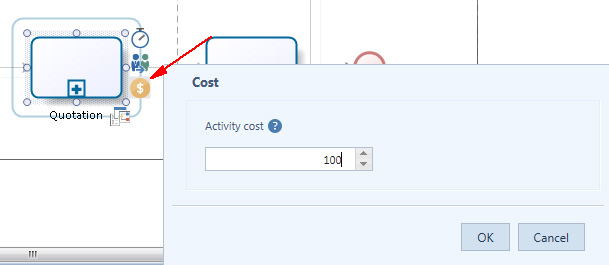
L’ultima informazione necessaria è Activity Cost, che definisce quanto costa un’attività ogni volta che viene eseguita. Per definire il costo dell’attività, si seleziona l’attività stessa, si clicca sulla icona Cost, quindi nel campo del popup window che appare si inserisce il dato (figura 4).
Esecuzione della simulazione
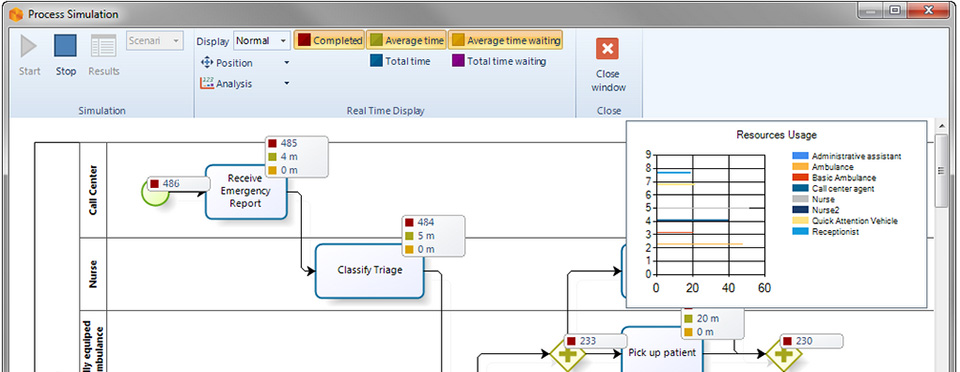
Inserite le informazioni necessarie a questo livello si seleziona il bottone di Run per eseguire la simulazione. Durante l’esecuzione vengono visualizzati i seguenti dati di analisi:
- il grado di impegno della risorsa;
- Il numero dei token completati;
- Il processig time medio per ciascuna attività;
- Il processing time totale per ciascuna attività;
- Il tempo medio di attesa per ciascuna attività.
Risultati
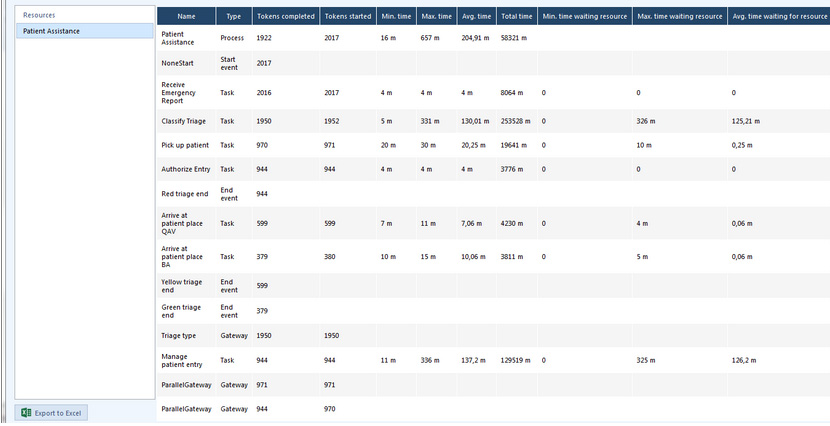
Quando la simulazione è terminata, per quanto riguarda il processo e le attività si possono vedere le seguenti informazioni:
- Name:identifica lo specifico elemento del diagramma per il quale viene mostrato il risultato.
- Type:identifica il tipo dell’elemento.
- Token completed: indica quanti token hanno attraversato quell’elemento, cioè quante volte quell’elemento è stato interessato da un’istanza di processo durante l’esecuzione della simulazione.
- Tokens started:indica quanti token sono arrivati a quell’elemento.
- Minimum time:indica il processing time minimo per quell’elemento.
- Maximum time:indica il processing time massimo per quell’elemento.
- Average time:indica il processing time medio per quell’elemento.
- Total time:indica il processing time totale per quell’elemento.
- Minimum time waiting resource:indica il tempo minimo che l’attività ha dovuto aspettare per una risorsa.
- Maximum time waiting resource:indica il tempo massimo che l’attività ha dovuto aspettare per una risorsa.
- Average time waiting resource:indica il tempo medio che l’attività ha dovuto attendere per una risorsa.
- Standard deviation:indica la deviazione standard dal tempo medio di attesa.
- Total fixed cost:indica il costo totale di esecuzione di una attività durante l’esecuzione della simulazione.
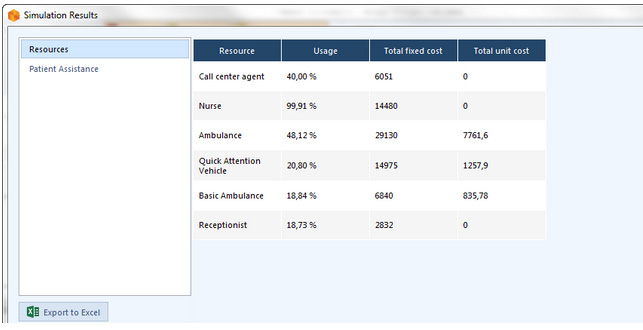
Per quanto riguarda le risorse, si possono vedere invece le seguenti informazioni:
- Usage: indica la percentuale di tempo in cui la risorsa è stata impegnata
- Total fixed cost:indica la componente fissa del costo nell’uso della risorsa
- Total unit cost:indica la componente variabile del costo nell’uso della risorsa
Dall’analisi dei risultati dell’esempio mostrati nella figura 7 risulta evidente come il cycle time del processo è impattato dal constraint sulle risorse. Per motivi di sintesi non abbiamo specificato il dettaglio della disponibilità delle risorse assegnate a ciascuna attività: il minimo tempo è rimasto 16 minuti ma il tempo medio è aumentato a 204,91 minuti.
Inoltre è evidente come il processing time per ciascuna attività è cambiato, in particolare il valore del tempo medio di attesa delle attività Classify triage e Manage patient mostra che queste due attività hanno dei problemi, probabilmente le risorse loro assegnate non sono sufficienti.
Dall’analisi dei risultati in figura 7 risulta inoltre che ci sono alcune sottoutilizzazioni e sovrautilizzazioni delle risorse, in particolare si nota che l’infermiere/a che esegue le attività Classify triage and Manage patient reception è impegnato al 99,91%. Questo significa che i token che arrivano devono aspettare per essere elaborati dalle risorsa assegnata a quelle attività.
In conclusione, una prima analisi dei risultati di questo esempio evidenzia che va seriamente considerato di aumentare il numero di risorse disponibili per le due attività citate al fine di ridurre il service e il waiting time e quindi di conseguenza il cycle time dell’intero processo.
Una nuova esecuzione della simulazione, avendo assegnato più risorse alle attività dette, può consentire di valutare gli impatti sui tempi e sui costi.
Level 4. Calendar Analysis
In questo livello, in aggiunta ai constraints sulle risorse del livello precedente, viene considerata anche la disponibilità delle risorse su un determinato periodo temporale. Come si può comprendere, considerare anche questo tipo di vincolo permette delle analisi di scenari sempre più realistici in quanto nella realtà i processi sono sempre soggetti a condizioni di cambiamento dovuti a periodi di vacanze, weekend, turni, pause.
Al termine di questo livello di analisi si possono ottenere più accurate informazioni su:
- sovra- o sottoutilizzazione delle risorse;
- costo totale delle risorse;
- costo totale delle attività;
- ritardi, tempo che una attività attende per una risorsa;
- stime più accurate del cycle time atteso.
Dati in input
Le informazioni aggiuntive, rispetto al livello precedente che devono essere fornite, sono quelle sui Calendari delle risorse. Un calendario definisce la disponibilità di una risorsa su base temporale, permettendo di definire orari, turni, vacanze. Per creare un calendario bisogna selezionare il bottone Calendars, cliccare su Add che apre una popup window dove si inseriscono le informazioni sul calendario.
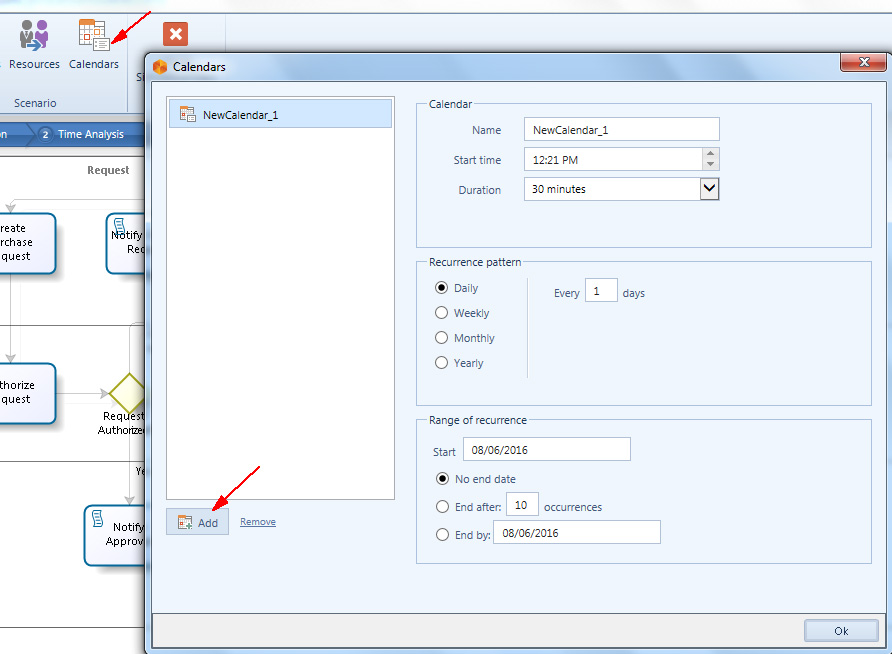
Il significato dei campi è il seguente:
- Name:definisce il nome del calendario. Dovrebbe essere corto e deve permette di identificare chiaramente il periodo di tempo che rappresenta. Ad esempio: ferie, turno notturno, pausa pranzo, turno diurno estivo, turno diurno, etc.
- Start Time:definisce la data iniziale del calendario.
- Duration:definisce la durata del calendario.
- Recurrence Pattern:definisce la frequenza con cui il calendario sarà ripetuto. Può essere su base giornaliera, settimanale, mensile, annuale.
- Range of recurrence:definisce il periodo di tempo per il quale si applica il calendario.
- Start of recurrence:definisce la data di inizio del periodo di tempo per il quale di applica il calendario.
- End of recurrence:definisce la data di fine del periodo di tempo per il quale si applica il calendario. Può essere espresso anche in termini di numero di ricorrenze.
La seconda informazione è rappresentata dall’assegnazione dei calendari con cui si definisce la disponibilità delle risorse per ciascun calendario definito. Per inserire questa informazione si deve selezionare il bottone Resources; quindi i dati si inseriscono nei campi che sono visualizzati e che si riferiscono a ciascun calendario definito:
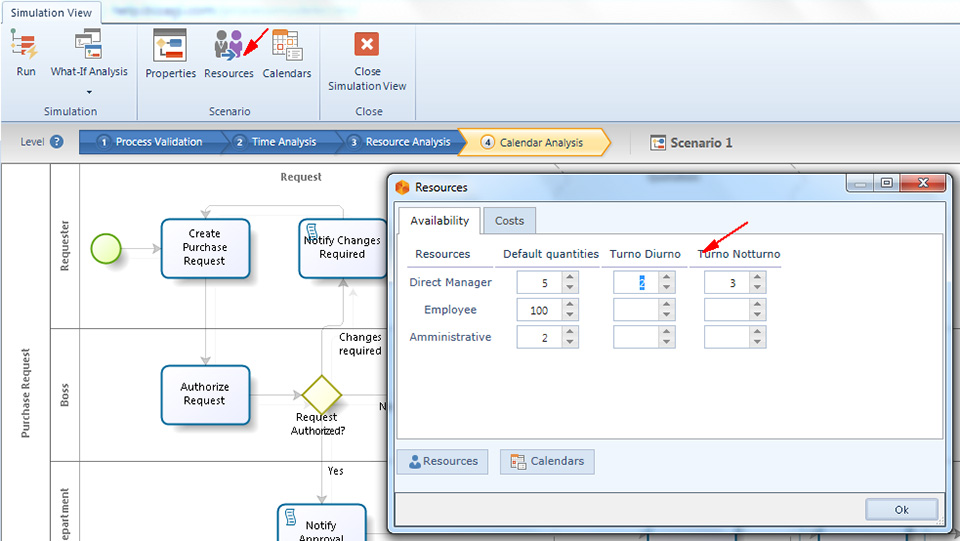
Per definire l’assegnazione dei calendari si parte dal numero di risorse disponibili definite nel livello di simulazione precedente, Level 3. Resources Analysis.
Esecuzione della simulazione
Inserite le informazioni necessarie a questo livello si seleziona il bottone di Run per eseguire la simulazione. Durante l’esecuzione vengono visualizzati i seguenti dati:
- il grado di impegno della risorsa;
- il numero dei token completati;
- il processig time medio per ciascuna attività;
- il processing time totale per ciascuna attività;
- il tempo medio di attesa per ciascuna attività;
Risultati
Quando la simulazione è terminata, per quanto riguarda il processo, le attività e le risorse si possono vedere le stesse informazioni viste per il livello Level 3. Resources Analysis ma in questo caso, tenendo conto dei vincoli fissati nei calendari definiti, i risultati risultano più realistici e quindi affidabili.
Configurazione dello scenario
La simulazione di un modello di processo costruito in Bizagi viene eseguito in uno scenario standard i cui parametri di definizione possono essere cambiati con l’obiettivo di configurare uno scenario quanto più realistico possibile.
La configurazione dello scenario si realizza nella finestrella che si raggiunge selezionando il bottone Properties quando si è in Simulation View (figura 10).
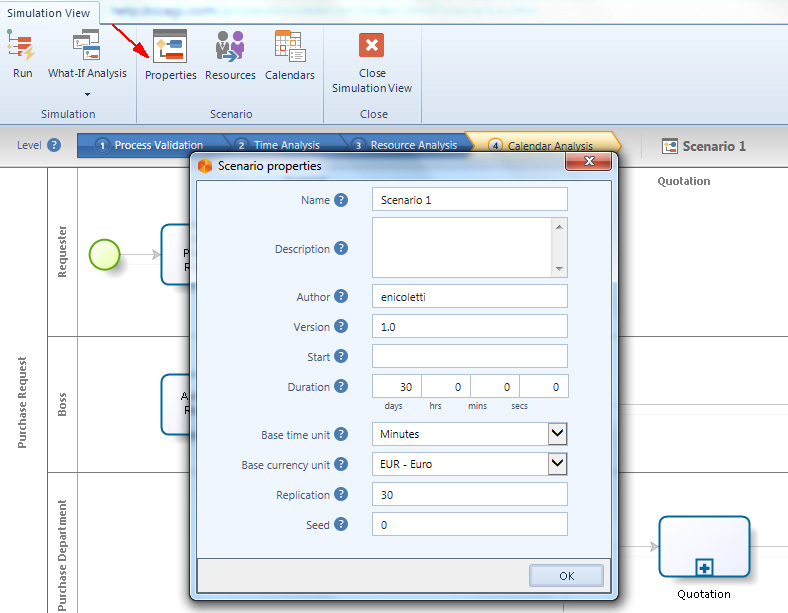
Le informazioni che si possono definire per lo scenario sono:
- Name: è il nome dello scenario. Dovrebbe essere chiaro e descrittivo e richiamare le condizioni che caratterizzano la simulazione.
- Description:è una dettagliata descrizione delle assunzioni e condizioni che caratterizzano la simulazione del modello del processo.
- Author:è l’autore che ha creato lo scenario.
- Version:è la versione dello scenario.
- Start:è la data di inizio della simulazione.
- Duration:è il periodo di tempo durante il quale il processo sarà simulato.
- Base Time units:è l’unità di misura in cui saranno espresso le misure relative al tempo e dei risultati.
- Base currency unit:è l’unità di misura in cui saranno espresso le misure relative al costo.
- Replication:è il numero di volte volte la simulazione dello scenario deve essere ripetuto.
- Bizagi raccomanda di usare almento 30 ripetizioni per essere sicuri che la simulazione raggiunga risultati stabili.
- Seed:è il valore del seed usato per generare numeri causali.
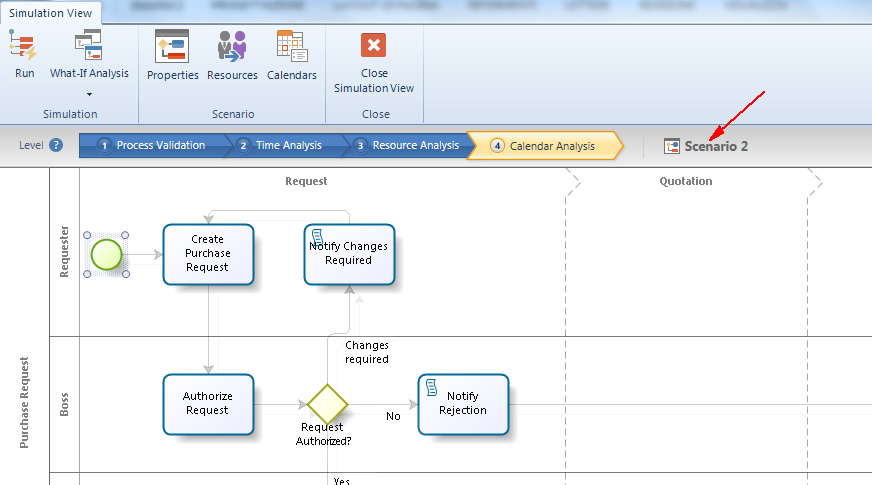
Scenari multipli
Bizagi consente di creare scenari multipli per un modello di processo con lo scopo di analizzare come variano i risultati della simulazione al variare dei dati di input. Gli scenari creati sono completamente indipendenti uno dall’altro, sia per quanto riguarda i parametri di definizione dello scenario stesso che per quanto riguarda i valori dei parametri che definiscono gli elementi del processo.
Quando si è in modalità Simulation View lo scenario in simulazione è visualizzato in alto a destra (figura 11).
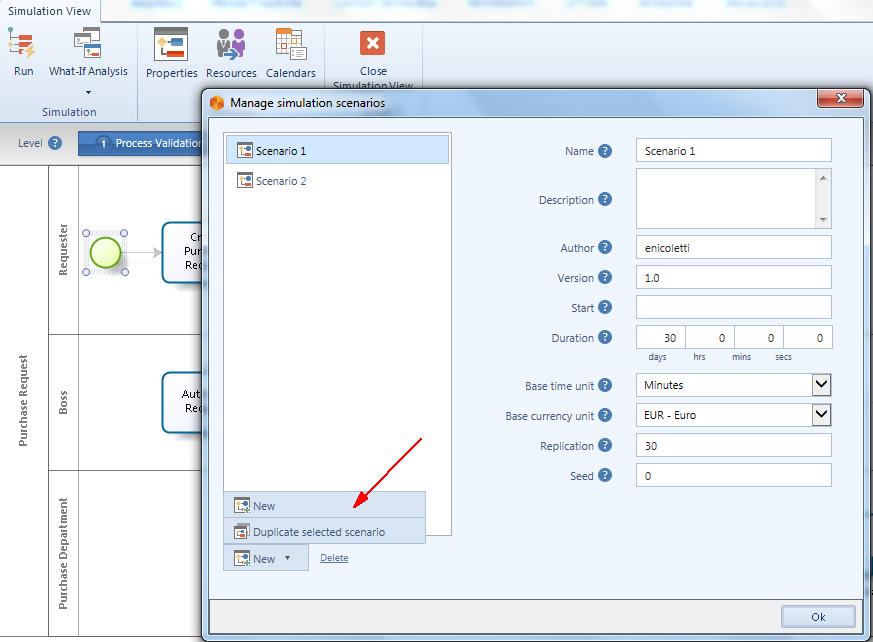
Creazione di uno scenario
Per creare un nuovo scenario si deve selezionare la voce di menù Manage scenarios che si raggiunge dal bottone What-If-Scenerio sul ribbon (figura 12).
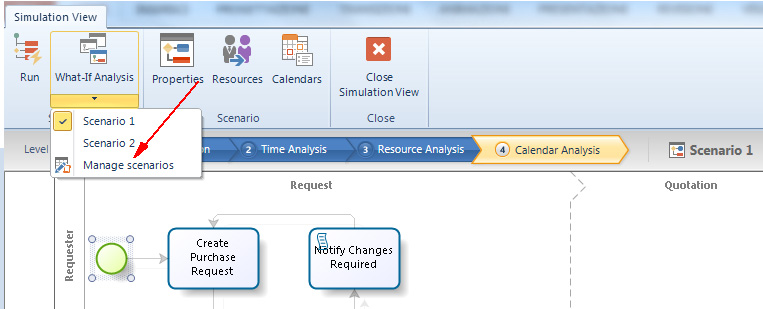
Quindi nella finestrella che si apre bisogna scegliere una delle due voci:
- Duplicate selected scenario: per creare una copia dello scenario selezionato con gli stessi valori per i parametri di definizione dello scenario e degli elementi del processo.
- New: per creare uno scenario completamente nuovo con tutti i parametri non valorizzati.
What-If Analysis
Siamo arrivati dove i lettori più attenti, avevano intuito: alla What-If Analysis. La What-If Analysis consente la comparazione di differenti scenari al fine di valutare come dei cambiamenti ai dati di input — che possono riferirsi a cambiamenti strategici, tattici o operativi — possono influire sulle prestazioni del processo e quindi quali impatti possono avere sul business.
Bizagi permette di effettuare una what-if analysis in maniera molto semplice e di rispondere quindi a domande del tipo:
- Come viene impattato il processing time di una attività se le risorse assegnate vengono raddoppiate?
- Quale sarebbe il rapporto costo/benefici riducendo il processing time di una specificata attività?
- Come sarebbe impattato il costo e il livello di servizio modificando i turni di lavoro?
What-If Analysis in uso
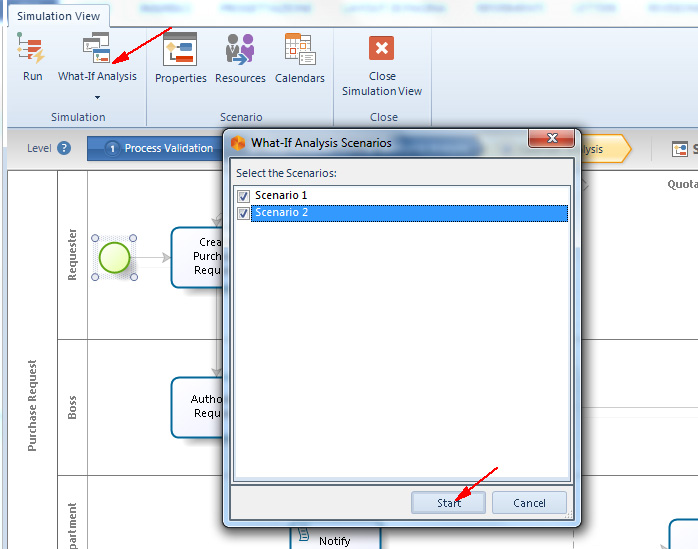
Per realizzare una what-if analysis in Bizagi, prima bisogna aver creato gli scenari che si intende valutare; quindi si seleziona il bottone What-If Analysis sul ribbon, si selezionano gli scenari da confrontare e infine si clicca sul bottone Start sul pop-up window che viene visualizzato (figura 14).
Quando l’analisi è completata, i risultati sono visualizzato in una tabella dove, per facilitare l’analisi, le differenze vengono evidenziate mediante l’uso del colore rosso (figura 15).
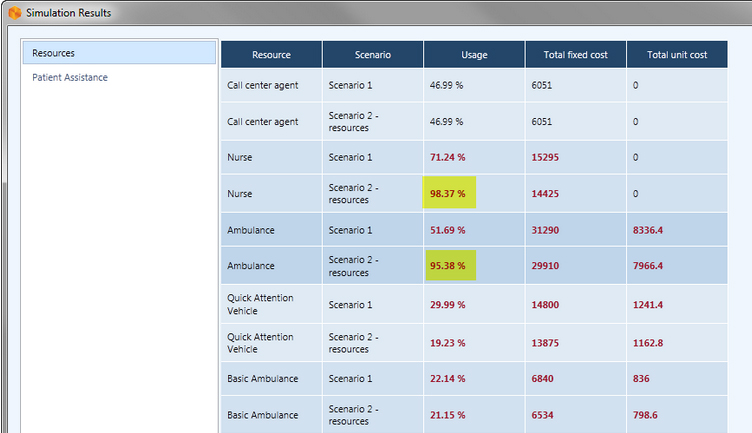
Dai risultati dell’esempio mostrati nella figura 15 risulta evidente che i parametri di definizione dello scenario 2 hanno aumentato la percentuale di uso delle risorse, soprattutto per Nurse e Ambulance che ora lavorano a piena capacità. Questo fa pensare che ci saranno dei ritardi e i pazienti dovranno aspettare; a contraltare di questi svantaggi, il risultato positivo è che i costi sono ridotti.
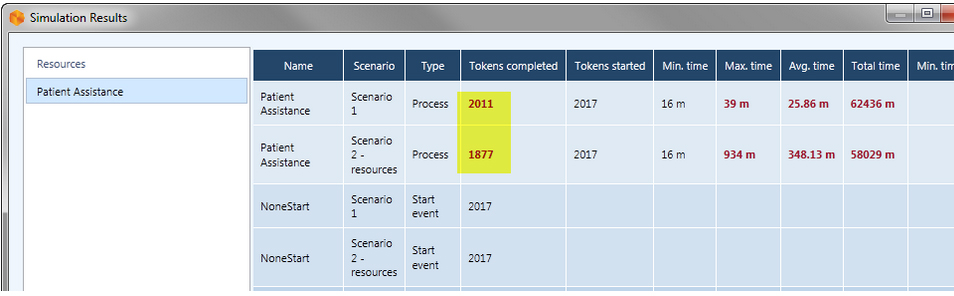
I risultati mostrati nella figura 16 indicano invece che i token completati nello scenario 2 si sono ridotti. Questo fa pensare che, con la configurazione di risorse impostata in questo secondo scenario, il numero di pazienti di cui ci si riesce a prendere cura è minore.
Già dall’analisi di questi primi risultati risulta evidente che forse la configurazione dello scenario 2 non è poi così vantaggiosa e che qualcosa dovrà essere rivisto.
Conclusioni
In questo e nel precedente articolo abbiamo approfondito la simulazione di un modello di processo. Abbiamo detto che è la tecnica più diffusa di analisi quantitativa di un modello di processo, che è utile sia per le analisi as-is che per definire i processi to-be in quanto permette delle what-if analysis di diverse configurazioni del modello.
Abbiamo visto quindi la feature di Simulazione in Bizagi Modeler. In particolare abbiamo visto i diversi, graduali livelli di analisi che consentono di configurare degli scenari man mano sempre più ricchi di informazioni per essere quanto più realistici possibili. Infine abbiamo visto come in Bizagi è possibile costruire e definire degli scenari differenti per realizzare delle what-if analysis.
Prima di concludere, vogliamo riportare una considerazione piuttosto esplicativa [1]: ”La tecnica della simulazione si basa su un modello e su delle assunzioni iniziali. L’affidabilità dei risultati prodotti da questa tecnica è largamente dipendente dall’accuratezza delle informazioni date in input. Inoltre, la simulazione assume che le risorse assegnate alle attività lavorino durante il tempo, costantemente con lo stesso impegno. Nella realtà, le persone non sono dei robot: vengono interrotte e le loro performance dipendono da numerosi fattori. È buona pratica quindi ottenere i dati di input della simulazione dalle osservazioni riscontrate sul campo, cioè dai dati storici delle esecuzioni dei processi. Ora, se questo potrebbe essere possibile per i processi as-is, non è invece fattibile per le simulazioni dei processi to-be. In questi casi è buona pratica incrociare i risultati ottenuti dalla simulazione con il parere di esperti del processi. Questo può essere fatto presentando i risultati della simulazione agli stakeholder del processo inclusi i partecipanti allo stesso. Questi possono dare un feedback critico e rilevare supposizioni non precise e quindi dare dei suggerimenti su configurazioni dei parametri più vicini al reale comportamento nella realtà. In altre parole, il processo di simulazione è una tecnica di analisi iterativa con potenzialmente diversi loop di validazione.”
Nel prossimo articolo inizieremo a vedere Bizagi Studio che è l’ambiente della suite di Bizagi dove il modello del processo viene trasformato in una vera e propria applicazione di processo eseguibile, dove vengono definiti il modello dei dati, la user interface e le integrazioni con gli altri IT asset.
Sono sposato, ho due figlie e, per non soffrire troppo la situazione di minoranza, ho imposto la presenza in famiglia di Balu‘: un derivato setter inglese maschio. Sono laureato in Informatica e certificato PMP-PMI. Nella mia carriera professionale ho ricoperto i ruoli di responsabile di prodotto, responsabile di unità di business, tecnico-pre sales, progettista, delivery manager, business process analyst, software architect e project manager. I principali ambiti applicativi in cui ho maturato esperienze sono automazione dei reparti di neonatologia, human capital management, gestione dei processi della qualità, per aziende e organizzazioni piccole, medie e di dimensione internazionale. Attualmente lavoro come Business Process Analyst e Project Manager presso una azienda di Reggio Emilia esperta nello sviluppo di Sistemi Informativi per la Qualità.