

Integrazione sì… ma come?
L’integrazione fra i vai microservices della nostra struttura è uno degli aspetti cruciali della loro implementazione. Se integriamo nel modo corretto, allora ogni microservice conserva la propria autonomia, lo possiamo rilasciare in maniera completamente asincrona rispetto agli altri, e tutto il nostro sistema ne trarrà beneficio. Viceversa, se lo facciamo nel modo sbagliato… allora avremo lavorato per nulla.
Vediamo di capire, nel complicato, o meglio, variegato, mondo dell’integrazione, qual è la soluzione da adottare, ammesso che ne esista solo una. Come vedremo, la risposta all’interrogativo principale sul come integrare è… “Dipende!”.
Obiettivi nell’integrazione
La cosa più importante su cui focalizzarci è mantenere l’indipendenza di ogni microservice rispetto agli altri. In soldoni, se abbiamo la necessità di aggiungere proprietà alla risposta di un microservice, dobbiamo avere la libertà di poterlo fare senza che questo influenzi in alcun modo il comportamento di un eventuale consumer del servizio stesso.
Allo stesso modo ci dobbiamo rendere indipendenti dalle tecnologie adottate. Nel nostro settore queste si susseguono alla velocità della luce, e noi dobbiamo essere liberi di poter implementare un servizio con una tecnologia più efficace senza per questo dover riscrivere l’intera applicazione.
Fatte queste premesse, vediamo come integrare fra loro i nostri microservices.
Database condiviso
È inutile nasconderci dietro ad un dito: il database condiviso è la forma più classica di integrazione e i motivi sono sicuramente più d’uno. È facile e soprattutto veloce da implementare, ma tutti questi vantaggi hanno un costo, e anche piuttosto elevato.
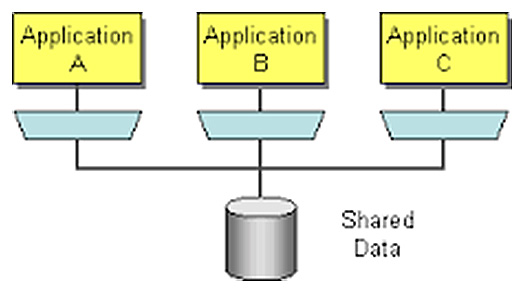
I “costi” della condivisione del database
Primo pegno da pagare: tutti i nostri servizi sono a conoscenza dell’implementazione del database che a questo punto appare come un’enorme API condivisa. Pensiamo alla classica tabella dei Nominativi, condivisa fra vari servizi. Se devo modificarla per implementare nuove funzionalità necessarie a un servizio, dovrò prestare molta attenzione affinché questa modifica non vada ad interrompere un altro servizio che utilizza la stessa tabella. Tutto questo comporta, nei casi migliori, grande investimento di tempo in test di regressione.
Secondo pegno: tutti i nostri servizi sono accoppiati alla stessa tecnologia di storage, quindi difficilmente potremmo sposare una tecnologia diversa, magari più adatta a un particolare servizio, rispetto ad un’altra. È risaputo che un database documentale è più adatto, rispetto ad un database relazionale, a servire un’applicazione web, mentre un database relazionale è più adatto ad un servizio di reportistica o di business Intelligence.
Ricordando i principi che dovrebbero guidarci nella realizzazione dei nostri microservices, strong cohesion e loose coupling, possiamo affermare, senza grosse difficoltà, che in questo modo… li perdiamo entrambi.
Direttore d’orchestra o coreografo?
Nel momento stesso in cui iniziamo a modellare un dominio complesso, ci scontriamo con il problema della gestione dei flussi che governano le relazioni fra i nostri servizi. Esistono due tipi di architetture che si possono implementare: orchestrazione e coreografia.
Orchestrazione
Proprio come nel caso di un direttore d’orchestra, nella Orchestration la guida del processo è affidata ad un processo, che è l’unico responsabile della gestione dei flussi.
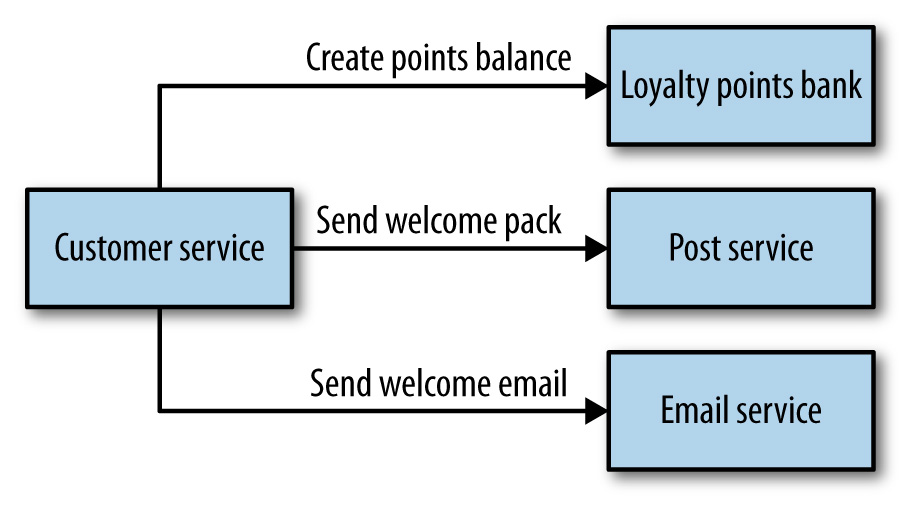
Coreografia
Nella Choreography, il compito del coreografo è invece quello di comunicare ad ogni elemento la propria parte, e poi lasciare che ognuno la interpreti a modo proprio, ovviamente nei limiti consentiti dalla coreografia stessa.
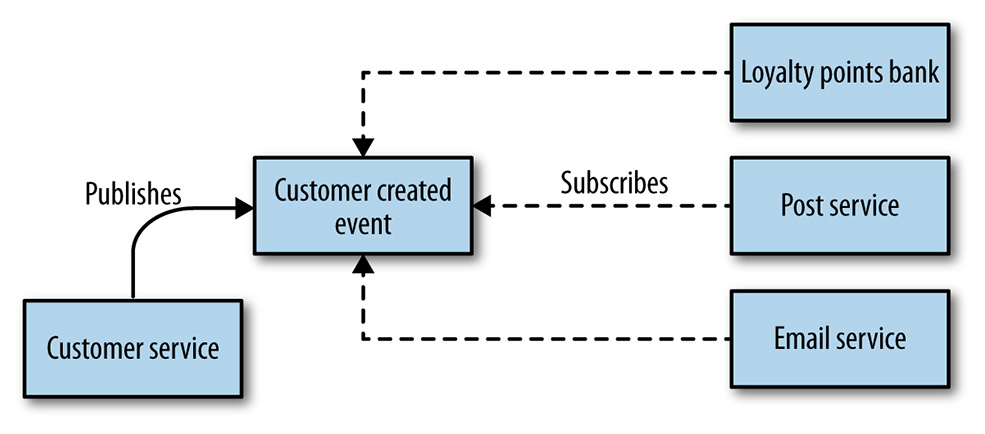
Sincrono o asincrono?
Questa è un’altra importante decisione da prendere, che inevitabilmente condizionerà le nostre scelte di implementazione.
Per quei pochissimi lettori che ancora non conoscessero la differenza, con una comunicazione sincrona ogni chiamata a un servizio blocca l’operazione, e resta in attesa della risposta.
Viceversa, nel caso di comunicazione asincrona, chi chiama non resta in attesa della risposta dal server, né tanto meno si preoccupa che questa arrivi.
Ovviamente anche la loro implementazione è completamente diversa; nel primo caso è semplice gestire il processo, in quanto sappiamo benissimo quando l’operazione è completata, proprio perché ogni chiamata è bloccante. Viceversa, una gestione asincrona è utile nel caso di processi molto lunghi, per evitare di mantenere aperta una connessione client/server per lungo tempo, in attesa di una risposta. È inutile sottolineare che, per come vengono consumate le nostre applicazioni oggi, la comunicazione asincrona risulta vincente come scelta.
La scelta dell’uno o dell’altro modello ci indirizza su due diversi stili di collaborazione fra client e server: request/response ed event–based.
request/response
Un client invia una richiesta e resta in attesa della risposta da parte del server; è quanto succede se adottiamo uno stile di comunicazione sincrona. Con una piccola modifica possiamo adottare questo stile anche in caso di comunicazione asincrona, nel caso in cui il client, nel momento in cui invia la richiesta, registra una callback che verrà utilizzata dal server per comunicare al client stesso quando avrà terminato il suo compito. Due possibili soluzioni per implementare il modello request/response, sono RPC (Remote Procedure Call) e REST (REpresentational State Transfer) che vedremo tra pochissimo.
event-based
Con questo stile di collaborazione invertiamo le cose. È il server che, una volta svolto il suo compito, solleva un evento per avvisare chiunque lo abbia sottoscritto che il lavoro è stato svolto, e aspetta che altri gli dicano cosa fare in seguito. Questo stile è tipico del modello asincrono. Il modello event-based è da preferire per mantenere il più possibile disaccoppiati i microservices fra loro. Chi emette un evento non sa, e non è tenuto a sapere, chi lo raccoglierà, questo ci permette di aggiungere, o togliere, eventuali subscribers senza che il client lo debba venire a sapere.
Remote Procedure Call
La prima possibile soluzione per implementare il modello request/response è rappresentata dalla Remote Procedure Call. Nel modello RPC viene eseguita una chiamata a una funzione in locale, che verrà eseguita su un servizio remoto, di cui non necessariamente, conosciamo la posizione.
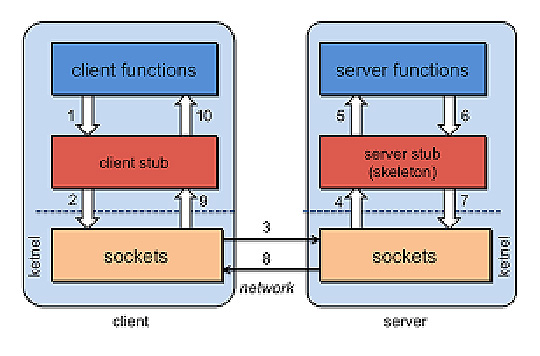
Esistono diversi tipi di tecnologie basate su RPC: alcune di esse espongono un’interfaccia separata (SOAP, Thrift, protocol buffers) che rende più facile realizzare proxy di comunicazione fra client e server anche se questi sono realizzati con tecnologie diverse. Ad esempio un server .NET espone la sua interfaccia tramite il modello WSDL (Web Service Definition Language), che potrà essere utilizzato da un client Java.
Il principale vantaggio riconosciuto a questa tecnologia è la sua semplicità; è possibile implementare e pubblicare una serie di funzionalità che potranno essere richiamante con la stessa semplicità e sintassi con cui si invocano funzioni locali, grazie appunto a un proxy client realizzabile tramite il modello WSDL.
Il limite di RPC: forte accoppiamento
Ovviamente, come ogni medaglia che si rispetti, anche questa ha il suo rovescio, ossia il forte accoppiamento fra client e server, dovuto proprio al modello WSDL. Ogni modifica al server comporta la nuova generazione del modello WSDL, e quindi una nuova lettura dello stesso da parte del client per poter utilizzare le nuove implementazioni.
Non solo, se è vero che la complessità di una chiamata a un servizio remoto è completamente nascosta al suo utilizzatore, non dobbiamo dimenticarci del costo che questa comporta in termini di apertura e chiusura del canale di comunicazione, oltre al fatto che inviare e ricevere dati attraverso la rete ha un suo peso, che potremmo pagare piuttosto caro in termini di performance.
REpresentational State Transfer
REST è uno stile architetturale inspirato dal web, che sfrutta quello che il web stesso già espone.
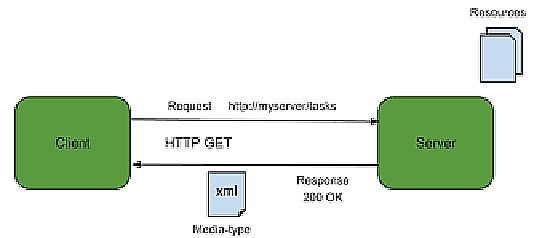
La principale differenza, rispetto a RPC, è il concetto di risorsa. Con RPC vengono esposti servizi, con REST ciò che viene esposto è la risorsa. Nel caso specifico del nostro argomento, la risorsa è qualcosa che il microservice conosce bene, come ad esempio il Cliente, o l’Articolo.
Il server crea differenti rappresentazioni della risorsa; come poi questa risorsa sia espressa esternamente è completamente separato dal modo in cui è memorizzata all’interno. Il protocollo che maggiormente viene utilizzato per implementare REST è HTTP, ma non è necessariamente l’unico supportato. In ogni caso i verbi esposti dal protocollo HTTP si sposano perfettamente con lo stile REST come illustrato di seguito:
- GET è utilizzato per leggere lo stato di una risorsa;
- POST è utilizzato per creare una risorsa;
- PUT è utilizzato per modificare una risorsa;
- DELETE è utilizzato per eliminare una risorsa.
HATEOAS
Un altro principio introdotto da REST, di grande aiuto nello sviluppo di servizi totalmente disaccoppiati, è HATEOAS (Hypermedia As The Engine Of Application State). Tale principio afferma che in un’applicazione REST il client ha bisogno di conoscere molto poco della stessa per poterla utilizzare; idealmente, l’unica cosa che deve conoscere è l’URI (Uniform Resource Identifier) di ingresso. Tutti gli altri URI dovrebbero essere forniti dalla posizione del server, utilizzando intestazioni, o altri meccanismi, per informare il client su dove risiedono le altre risorse. In questo modo Client e Server non sono accoppiati, e il server potrebbe cambiare posizione della risorsa senza interrompere il suo servizio.
Così facendo, il servizio può essere esteso ad ogni richiesta di nuova funzionalità, senza la necessità di interrompere o compromettere quanto già da esso esposto. L’importante è documentare in modo esaustivo quanto esposto dai nostri servizi, ma per questo esistono diversi tools, fra i quali va sicuramente citato Swagger [2].
Servizi RESTful
Detto questo dobbiamo assicurarci che i nostri servizi siano effettivamente RESTful, e per farlo possiamo innanzitutto verificare che essi non portino con loro alcuni difetti.
Per prima cosa, cerchiamo di capire la situazione dell’utilizzo di Application/Json come Media Type. È uno degli attributi che viene utilizzato più spesso, insieme ad Application/Xml. Con Jersey (JAX-RS) potremmo trovare qualcosa di simile:
@GET
@Produces(MediaType.APPLICATION_JSON)
public List<Product> GetProducts()
{
...
}
REST, per definizione, richiede che i messaggi siano auto-descrittivi, quindi la semantica dei dati deve viaggiare con i dati stessi. Per fare un esempio concreto la differenza sta nello scrivere:
Object GetProducts();
oppure
List<Product> GetProducts();
Nel primo caso affermiamo che viene restituito un tipo generico, nel qual caso chi utilizza il servizio deve sapere che tipo di cast potrà applicare per utilizzarlo. Nel secondo caso invece viene esplicitato il tipo. Utilizzare tipi generici è di fatto un modo per accoppiare il client al server, perché lo obblighiamo a conoscere come interpretare il JSON che gli restituiamo. È sempre meglio definire il tipo che viene restituito per contrastare questa fragilità del servizio.
Il secondo aspetto da verificare è l’utilizzo dell’ID nei dati restituiti. Spesso i dati restituiti dai nostri servizi contengono un riferimento esplicito all’identificatore del dato stesso, qualcosa di simile a
{ "products": [
{ "id": 12,
"type": 103,
"name": "ACME Router D12"
},
{ "id": 13,
"type": 145,
"name": "5m UTP Cable"
},
...
]}
Utilizzare ID numerici non è RESTful per due motivi. Innanzitutto richiede che il client sappia come e dove utilizzare questi identificatori per ottenere informazioni aggiuntive sul prodotto. E ancora, questo non fa altro che aumentare l’accoppiamento fra client e server, esattamente ciò che noi vorremmo evitare. Per restare all’esempio riportato sopra, potremmo trovare qualcosa di simile:
{ "products": [
{ "id": "/product/12",
"type": "/type/103",
"name": "ACME Router D12"
},
{ "id": "/product/13",
"type": "/product/145",
"name": "5m UTP Cable"
},
...
]}
Dal punto di vista della sintassi non abbiamo apportato un gran cambiamento, ma ora il nostro client sa come ottenere informazioni sul prodotto in modo implicito.
Terzo aspetto imporante è quello relativo alla documentazione: Senza disperderci troppo su questo punto, come già scritto in precedenza ci sono validissimi strumenti che ci permettono di documentare i nostri servizi come Swagger [2] o WADL (Web Application Description Language) [3].
Ultimo punto da verificare per garantire che i nostri servizi siano pienamente RESTful è rappresentato dagli URI Templates. Si tratta degli URI con appositi placeholders, ossia “segnaposto”, ma suona male… Vengono utilizzati nella documentazione per descrivere dove risiede la risorsa:
/product/{id}
/products?page={pageNumber}
/products?startIndex={startIndex}&endIndex={endIndex}
Anche in questo caso stiamo accoppiando Client e Server. Un modo meno esplicito per esporre un servizio di ricerca potrebbe essere simile a questo
{
"search": "/search?q={query}"
}
Il modello event-based
I due modelli di comunicazione visti sopra ci aiutano a implementare il pattern request/response, vediamo ora come implementare un modello basato sugli eventi.
Negli ultimi anni, un’altra architettura è emersa prepotentemente: si tratta di un modello chiamato Event Driven Architecture (EDA). L’obiettivo di EDA è permettere ai servizi di reagire dinamicamente agli stimoli esterni, che possono essere generati da processi di business, tanto per non dimenticare la relazione fra DDD e microservices. Gartner fornisce una definizione precisa [4] di “evento”:
- Evento ordinario: gli eventi ordinari sono semplicemente qualche cosa che è già accaduto.
- Evento software: un evento software è la registrazione automatica di quanto accaduto. Un evento software è un oggetto, codificato in forma di messaggio, che rappresenta un evento ordinario.
In questa architettura gli end–point sono fortemente slegati, guarda caso proprio quello che stiamo cercando, e le notifiche sono gestite con modello PUSH. In EDA il routing riveste un aspetto fondamentale.
In particolare, il routing definito a design-time è di tipo
- Client <-> server
- Flow based (Biztalk, batch, …)
Il routing definito a run-time è di tipo
- content-based
- a eventi
Da un punto di vista pratico EDA è un componente “core” che descrive un particolare message routing tra i serivizi. Rispetto a SOA, trasforma il concetto di loosely coupled in decoupled. In SOA il producer e il consumer condividono il service contract, mentre in EDA non c’è nessun tipo di condivisione. Ma la vera differenza fra SOA ed EDA è che quest’ultima presuppone la presenza di un message bus, in grado di trasportare i messaggi, che altro non sono che classi con proprietà immutabili [5].
Anche in questo caso, non c’è bisogno di reinventare la ruota: strumenti come RabbitMQ [6] risolvono il problema su entrambi i fronti. Il microservizio in questione utilizza una API per pubblicare un evento (publish), in pratica lo invia al broker (RabbitMQ appunto); il broker gestisce i sottoscrittori permettendo loro di essere avvisati quando viene sollevato un evento.
Strumenti come questi sono sicuramente progettati per essere scalabili e resilienti, altro termine molto cool nel mondo dell’IT di oggi ma, ovviamente, questi vantaggi hanno un costo. Tutto ha un prezzo e, in questo caso, trattandosi di strumenti esterni ai nostri microservizi, essi possono aggiungere complessità allo sviluppo, come necessità di competenze aggiuntive, o strutture aggiuntive da manutenere. Però, una volta pagato il debito tecnico, forniscono uno strumento formidabile per costruire architetture debolmente accoppiate.
Trattare le molteplici implementazioni di questa architettura richiede certamente più di qualche riga di un articolo, ma possiamo almeno dare qualche indicazione; cercare di utilizzare HTTP come protocollo di propagazione eventi. ATOM è una specifica REST-compliant che definisce, fra l’altro, la semantica per pubblicare feed delle nostre risorse. Ma anche in questo caso c’è il rovescio della medaglia, sappiamo che HTTP scala molto bene, ma non eccelle in quanto a bassa latenza, dove, viceversa, alcuni brokers se la cavano benissimo.
Conclusioni
Provando a dare un senso a tutta questa disquisizione sull’integrazione dei nostri microservices, sia che si scelga di diventare esperti di REST, sia che si rimanga fedeli al buon vecchio SOAP con RPC, il concetto chiave del servizio come state machine è fondamentale. Abbiamo già scritto del fatto che il raggio d’azione dei nostri microservices è esplicitato dal concetto di Bounded Context, quindi il nostro microservizio è l’unico responsabile della logica associata ai comportamenti di questo contesto.
Quando un utente del nostro microservizio desidera cambiare una proprietà della risorsa, ad esempio i dati di un articolo, invia una richiesta appropriata. Il microservice, in base alla logica implementata, deve decidere se accettare tale richiesta, oppure rifiutarla, sollevando un’eccezione. Per fare questo il nostro microservizio passa in rassegna tutti gli eventi associati al ciclo di vita dell’articolo stesso. Il nostro obiettivo, se ricordate, è quello di evitare servizi anemici, che non sono altro che implementazioni di operazioni CRUD. Lasciare a un’entità esterna la decisione su cosa sia consentito modificare della nostra risorsa, e soprattutto sul come farlo, significherebbe perdere la tanta agognata coesione, uno dei due aspetti principali dei nostri microservizi.
Modellare esplicitamente questi concetti di dominio all’interno del nostro microservizio lo rende molto potente. Significa avere un solo punto per gestire le collisioni di stato, come ad esempio la gestione della modifica di un articolo rimosso, da parte di un utente, ma anche avere un solo punto in cui implementare i comportamenti necessari a gestire i cambiamenti di stato della risorsa stessa.
Qualsiasi tecnologia si decida di scegliere, quindi, questo è il concetto chiave da memorizzare.
Sono fondamentalmente un eterno curioso. Mi definisco da sempre uno sviluppatore backend, ma non disdegno curiosare anche dall'altro lato del codice. Mi piace pensare che "scrivere" software sia principalmente risolvere problemi di business e fornire valore al cliente, e in questo trovo che i pattern del DDD siano un grande aiuto. Lavoro come Software Engineer presso intré, un'azienda che sposa questa ideologia; da buon introverso trovo difficoltoso uscire allo scoperto, ma mi piace uscire dalla mia comfort-zone per condividere con gli altri le cose che ho imparato, per poter trovare ogni volta i giusti stimoli a continuare a migliorare.
Mi piace frequentare il mondo delle community, contribuendo, quando posso, con proposte attive. Sono co-founder della community DDD Open e Polenta e Deploy, e membro attivo di altre community come Blazor Developer Italiani.