

Introduzione
In questa serie di articoli parliamo di metriche che ci aiutano nel miglioramento continuo. Nello scorso numero abbiamo discusso del perché usare metriche, abbiamo fornito qualche consiglio pratico, e abbiamo introdotto il Cumulative Flow Diagram per osservare il flusso di lavoro.
In questo articolo proseguiamo il nostro percorso, introducendo metriche che ci aiutano ad analizzare e migliorare i nostri tempi di consegna e a fare previsioni.
L’obiettivo di questi articoli è sempre di essere di ispirazione: non tutto potrebbe essere applicabile al vostro contesto ma spero che troviate spunti di riflessione e magari scegliate qualche metrica da iniziare ad usare.
Come detto nella prima parte, non lasciatevi spaventare: bastano davvero pochi dati per partire. Pochi dati sono comunque meglio di niente! Usateli per iniziare, e poi diventerete sempre più precisi via via che raccoglierete ulteriori campioni.
Ricordo di tenere a mente che queste metriche hanno senso solo se applicate a singoli tipi di lavoro.
Lead Time & Cycle Time: quanto ha impiegato questa storia?
Probabilmente avete già sentito parlare di Lead Time e/o Cycle Time e sapete che indicano quanto tempo ha impiegato una storia dall’inizio alla fine. Tuttavia c’è molta confusione sulla differenza tra i due termini e diverse persone usano definizioni differenti.
Vi dò le definizioni “ufficiali” usate in Kanban; se preferite usare altri termini, comunque, fate pure: assicuratevi però di chiarire cosa intendete voi con Lead Time e Cycle Time.
Commitment Point e coda infinita
Per poter definire Lead Time e Cycle Time dobbiamo prima chiarire due concetti: Commitment Point e coda infinita.
Il Commitment Point [1] è il punto nel processo dove una storia passa da essere una semplice opzione — per esempio, si trova in un backlog o in un pool di idee — ad essere selezionata come prossima attività. Quando una storia supera il commitment point il team si sta impegnando per portarla a termine e, se è sufficientemente maturo, comunica una previsione agli stakeholder su quando la storia sarà pronta: “Stiamo iniziando la tua storia, siamo sicuri all’80% che sarà completata entro 10 giorni o meno”. Spesso il commitment point è la prima colonna con un WIP Limit.
La Coda Infinita è il punto nel processo dove il team non ha più influenza, dove i tempi non sono più dettati da noi. Un esempio potrebbe essere “Waiting for Release”: non possiamo decidere noi quando fare un rilascio ma dobbiamo aspettare un particolare momento, quindi le storie si accumulano in questa colonna fino ad allora. Solitamente le colonne senza WIP Limit sono code infinite: non possiamo limitarle perché non ne abbiamo il controllo.
Lead Time e Cycle Time
Detto questo, possiamo dare le seguenti definizioni “ufficiali”.
Il Lead Time è il tempo tra il commitment point e la prima coda infinita [2].
Cycle Time: è il tempo tra due punti del processo; pertanto andrebbe sempre specificato “Cycle Time tra punto A e punto B” [2].

Statistiche “for dummies”
È utile osservare alcune statistiche sul Lead Time per conoscere meglio i nostri tempi di consegna: vediamole a una a una di seguito.
Media e mediana
Queste statistiche danno indicazione sul tempo medio per completare una storia. Preferiamo sempre usare la mediana rispetto alla media perché è meno influenzata dai cosiddetti outlier (dati anomali). Per esempio, se capita una storia problematica con un Lead Time particolarmente alto che è fuori dal comune, la media cambia parecchio ma la mediana resta simile. Per capirci basta ricordare il detto: “Quando Bill Gates entra in un bar in media gli avventori diventano tutti milionari, ma in mediana non cambia niente…”.
Moda
Moda è il valore di Lead Time più comune, quello che accade più spesso. In quanto tale, a meno che non abbiano dati migliori e più circostanziati a disposizione, la moda è di solito il numero che le persone ricordano istintivamente quando viene loro chiesto “Quanto impiega solitamente una storia?”.
Percentili
Matematicamente parlando ci dicono che, su 100 campioni, n cadono entro un certo numero. Per esempio l’80esimo percentile ci dice che, su 100 valori, 80 cadono entro il valore 7, cioè sono minori o uguali a 7. Personalmente, trovo più utile ed immediato esprimerli in modo leggermente diverso: “L’80% delle storie impiega 7 giorni o meno”. I percentili sono utili per fare previsioni e decidere il Service Level Agreement (SLA), di cui parliamo meglio nel corso dell’articolo.
Min e max
Sono, intuitivamente, i valori minimo e massimo. “Quanto è il minimo che ha impiegato una storia? E il massimo?” Ci fanno capire il range di valori su cui lavoriamo.
Deviazione standard
Questa statistica ci dà una indicazione della variabilità nel nostro processo. Quando è alta significa che i valori sono distribuiti su un lungo intervallo. Per esempio, la deviazione standard sarà molto più alta quando i possibili valori sono compresi tra 1 e 20 (maggiore variabilità), e più bassa se i valori sono compresi tra 1 e 5 (minore variabilità).
Attenzione a come si usa la deviazione standard: tenete presente che la distribuzione del Lead Time non è una distribuzione normale; ne parliamo meglio tra poco.
Control Chart: come possiamo migliorare?
Il Control Chart è un grafico piuttosto famoso che forse avrete già visto in passato [3]. È utilissimo per trovare opportunità di miglioramento e rispondere alla domanda “Come possiamo migliorare?”.
Come funziona il Control Chart
Per ogni storia, il Control Chart mostra quanto tempo quella storia ha impiegato (Lead Time). Viene poi annotato con la mediana (linea verde) e due limiti in rosso. Questi limiti sono posti in modo tale che una certa percentuale di storie sia compresa tra quei valori. Per chiarire meglio, nella figura 3:
- il limite superiore ci dice che l’80% delle storie vengono completate in 7 giorni o meno;
- il limite inferiore ci dice che il 25% delle storie vengono completate in 1,5 giorni o meno.
Le storie che cadono fuori da questi limiti — sopra al limite superiore o sotto al limite inferiore — sono storie “insolite” che per qualche motivo hanno impiegato più del solito o meno del solito. Perché? Che cosa ha reso quella storia così lenta? Cosa possiamo cercare di evitare in futuro? E che cosa, invece ha reso quella storia così veloce? Cosa possiamo ripetere in futuro?
Uso del Control Chart
Ogni storia fuori dai limiti è una opportunità di miglioramento e va discussa per cercare di imparare qualcosa da essa: talvolta decidiamo che è stato semplicemente un caso isolato, ma altre volte scopriamo che c’è dietro un problema e discutiamo di come possiamo evitarlo in futuro.
Nel mio team troviamo utilissimo portare questo grafico nelle retrospettive per trovare argomenti di cui parlare e nuove idee per migliorare. Il Control Chart ci offre continui spunti di riflessione ed è fantastico per guidare il miglioramento continuo.
Quali limiti usare?
Solitamente per scegliere i valori dei due limiti superiore ed inferiore si usano alcuni percentili. Quali valori usare esattamente dipende dal contesto e non c’è una regola unica da seguire. Per aiutarvi a scegliere, ricordate che lo scopo del Control Chart è generare discussioni interessanti: ponete i limiti in modo tale da generare sufficienti discussioni e idee di miglioramento.
Come visto nella figura 3, nel mio team abbiamo scelto di usare l’80esimo e il 25esimo percentile perché per noi generano un buon numero di discussioni. Altri valori comuni che vengono scelti potrebbero essere 80/20 o 90/10.
Domande frequenti riguardo al control chart
“Vale la pena parlare di ogni storia fuori dai limiti?”.
Personalmente penso di sì perché potrebbe nascondere qualcosa da cui imparare e su cui possiamo migliorare. Attenzione però a non reagire troppo in fretta: se è la prima volta che incontriamo un particolare problema, forse vale la pena aspettare finché non accade di nuovo, prima di cambiare il nostro processo.
“Ma può essere accaduto che una storia fosse semplicemente una storia grossa e non ci fossero problemi particolari?”.
Certo! Ma in questo caso mi chiederei comunque: “Perché questa storia era più grossa del solito?”. C’era qualche segnale per cui avremmo potuto prevederlo? Come possiamo spezzarla meglio la prossima volta? Nel caso qualche lettore se lo stia chiedendo: sì, molto spesso è possibile spezzare la storia in storie più piccole, anche quando sembra impossibile. Ma è una competenza che va imparata.
Lead Time Trend: il tempo di consegna sta migliorando?
Per capire se stiamo migliorando è utile visualizzare il trend del Lead Time: il nostro Lead Time sta crescendo o diminuendo? Stiamo diventando più veloci o più lenti?
Come funziona
Ad intervalli di tempo regolari — per noi ogni due settimane — calcoliamo la mediana del Lead Time delle storie concluse in quel periodo. Pur usando Kanban, per semplicità chiamiamo ancora questi periodi “iterazioni”.
Per ottenere il trend, calcoliamo la stessa mediana sulle ultime 4 iterazioni: per ogni iterazione contiamo quella corrente, più le precedenti 3.
Per vedere se la variabilità nel Lead Time aumenta o diminuisce, troviamo utile visualizzare anche il trend di alcuni percentili, gli stessi che abbiamo usato nel Control Chart: se per quell’iterazione i due valori si avvicinano, significa che i Lead Time delle storie sono stati compresi in un intervallo più piccolo, cioè il Lead Time è stato meno variabile.
Uso del Lead Time Trend
Il principale uso del Lead Time Trend è per validare se stiamo migliorando o meno. È particolarmente utile quando introduciamo cambiamenti, per validarne l’efficacia: “Quale effetto ha questo cambiamento sul Lead Time?”.
Vale la pena ricordare che, come discusso nel primo articolo, è solo quando tutte le metriche migliorano che diciamo che stiamo migliorando. Se solo il Lead Time migliora, potrebbe anche essere che stiamo prendendo scorciatoie, compromettendo la qualità.
Lead Time Distribution: quanto impiegano le nostre storie?
Osservando la distribuzione del Lead Time possiamo conoscere la probabilità di ogni possibile durata e rispondere a domande come: “Quanto impiegano le nostre storie?”, “Quanto impiegherà la prossima storia?”. [4]
È particolarmente utile per fare previsioni e per creare aspettative realistiche negli stakeholder.
Se avete mai avuto problemi di prevedibilità e state cercando di migliorare, questa è probabilmente la metrica più importante che vorrete osservare.
Come funziona
Occorre contare la frequenza di ogni Lead Time nelle storie completate in passato. In pratica, per ogni possibile Lead Time che abbiamo avuto in passato, contiamo quante storie hanno avuto quel Lead Time.
Nell’esempio di figura 5 il conteggio è il seguente:
- 17 storie hanno impiegato tra 0 e 1 giorno;
- 18 storie hanno impiegato tra 1 e 2 giorni;
- 16 storie hanno impiegato tra 2 e 3 giorni;
- e così via.
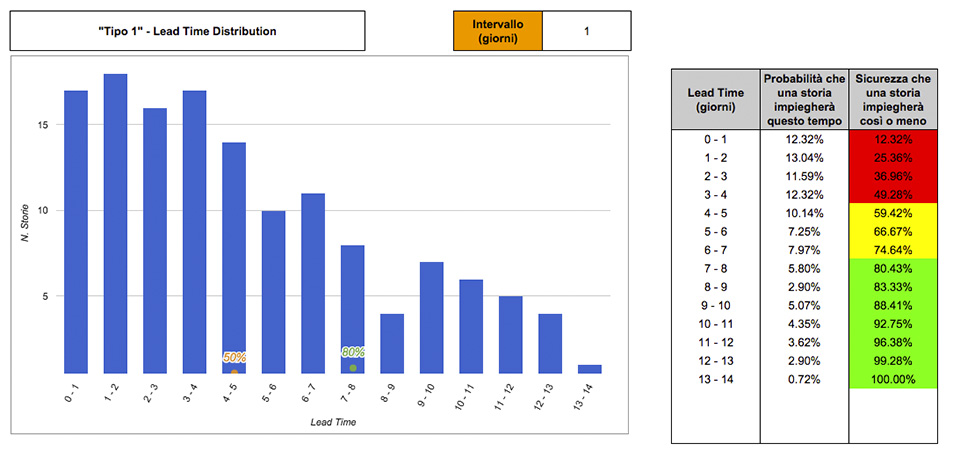
Inoltre, sulla destra mostriamo alcuni dati per rendere facilmente accessibili queste informazioni:
- la probabilità di ogni Lead Time, ovvero la probabilità che una storia impieghi esattamente quel tempo. Per esempio: il 12% delle storie impiega 0-1 giorno; il 13% impiega 1-2 giorni, e così via.
- la somma cumulativa delle singole probabilità per trovare la percentuale di storie che impiega quel tempo o meno. Per esempio: il 59% delle storie impiega 5 giorni o meno; l’80% di storie impiega 8 giorni o meno, e così via.
Uso del Lead Time Distribution: fare previsioni
Avere questi dati a disposizioni cambia il modo in cui prendiamo decisioni sul futuro: decidiamo il livello di rischio che vogliamo assumere, e in base a questo facciamo previsioni su quanto una storia potrebbe impiegare.
Immaginate questo caso: uno stakeholder (cliente, o project manager, etc.) viene da noi e ci dice “Abbiamo una scadenza e ci serve questa storia fatta per fine mese”. Quando dovremmo pianificare questa storia? È fattibile o è meglio dire no? Usando i dati a nostra disposizione sappiamo che per avere l’80% di certezza che la storia sarà completata in tempo, dovremmo iniziarla 8 giorni prima della scadenza. Se invece vogliamo assumere del rischio potremmo iniziarla solo 4 giorni prima della scadenza, ma in questo caso saremmo sicuri solo al 50%. Sta a noi decidere quanto valore diamo al rispettare quella scadenza e quindi a decidere quanto rischio vogliamo assumere.
Avere queste conversazioni cambia il modo in cui pianifichiamo e facciamo stime: invece di concentrarci sul costo di una attività e cercare di stimare e pianificare con precisione, vogliamo concentrarci sul valore della storia e sull’incertezza naturalmente associata al nostro lavoro. Tenendo conto del rischio ci costringiamo a pensare “So che c’è solo il 10% di possibilità che la storia impiegherà più di 10 giorni, ma se accadesse? Quale sarebbe l’impatto? Posso assumere questo rischio?” [5].
A proposito, i colori usati nell’immagine sopra servono proprio a rendere esplicito il livello di rischio: in rosso abbiamo meno del 50% di sicurezza, in giallo siamo tra il 50% e l’80%, e in verde siamo certi almeno all’80%.
Tra l’altro, avendo a disposizione i dati della distribuzione del Lead Time possiamo usare tecniche come Montecarlo Simulation [6] e Probabilistic Forecasting per effettuare simulazioni e prevedere il futuro. Ne parleremo in dettaglio in uno dei prossimi articoli.
Uso del Lead Time Distribution: definire il Service Level Agreement (SLA)
In modo simile possiamo usare questi dati per definire un SLA (Service Level Agreement): quanto rischio vogliamo di andare fuori SLA? Se vogliamo poco rischio, per esempio quando il SLA diventa vincolante da contratto, allora potremmo decidere di usare un alto livello di sicurezza come 90% o 95%, e quindi dichiarare 10-12 giorni. Altrimenti potremmo usare un numero più basso, per esempio quando il SLA è solo un’indicazione per creare aspettative, ma sappiamo che di tanto in tanto capiteranno storie che impiegheranno di più.
Uso: identificare “tipi di lavoro”
Un consiglio veloce: se nella nostra Lead Time Distribution notiamo picchi multipli probabilmente stiamo mischiando diversi tipi di lavoro. È un facile trucchetto per capire se abbiamo suddiviso abbastanza i tipi di lavoro nel nostro processo.
Ricordate che, come quasi tutte le altre metriche, la Lead Time Distribution ha senso solo se applicata a singoli tipi di lavoro. Tipi diversi tipi seguono diverse distribuzioni.
Sfatiamo un mito: le storie devono essere di dimensione simile? No!
Molto spesso sento dire “Ma le storie devono essere tutte di dimensione simile perché Kanban e le metriche funzionino”. Questo è un falso mito. Non importa che le storie abbiano dimensione diversa perché sappiamo che storie dello stesso tipo seguono la stessa distribuzione.
Fintanto che restiamo coerenti nel modo in cui spezziamo le storie e identifichiamo il loro tipo, la Lead Time Distribution ci dice che avremo molte storie veloci, alcune storie un po’ più lente, e di tanto in tanto qualche storia più grossa. Ma conosciamo esattamente la probabilità che questo accada.
Parentesi avanzata: un po’ di teoria con la Weibull Distribution
Notate come nel grafico le barre a sinistra sono molto alte e poi vanno via via calando? Questo è un classico esempio di distribuzione asimmetrica ed è tipico nel mondo dello sviluppo software: abbiamo molte storie che impiegano pochi giorni, e poi via via sempre meno storie che impiegano molto tempo: è un po’ il contrario classica distribuzione gaussiana “a campana” dove il picco è al centro e i valori sono ugualmente distribuiti su entrambi i lati).
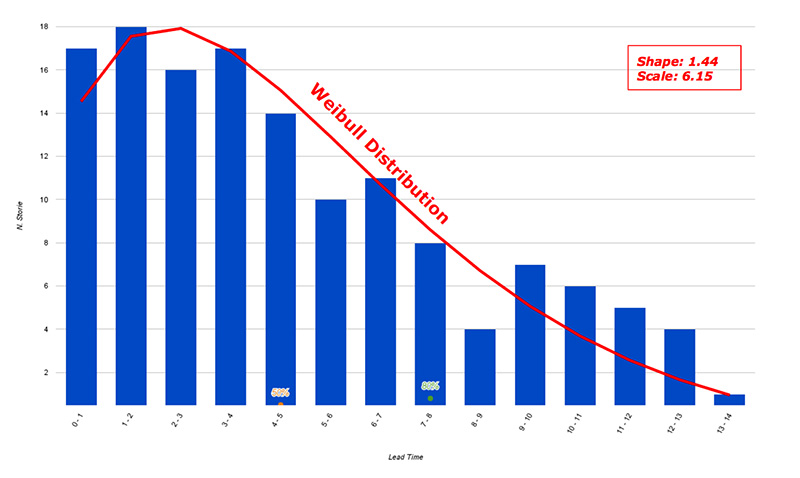
In particolare, se proviamo a interpolare i dati e trovare la curva migliore per modellarli troviamo un particolare tipo di distribuzione chiamata Weibull Distribution.
La Weibull Distribution è in realtà una famiglia di distribuzioni che può assumere diverse forme. La teoria ci dice che la maggior parte dei processi di sviluppo software è rappresentabile da una di queste forme e in base alla forma esatta possiamo trarre qualche conclusione sul nostro processo.
Tutto questo entra in territori di teoria piuttosto avanzata: lascio a voi approfondire se siete interessati [7], [8], [9]. Io ho preferito spiegarvi come nel mio team usiamo questi dati in pratica.
Story Health: su cosa dovrei lavorare oggi?
La Lead Time Distribution ci dà informazioni su quanto tempo le storie hanno impiegato in passato. Possiamo però usare gli stessi dati anche per capire lo stato di salute delle storie attualmente in corso e decidere a cosa dare priorità oggi…
Come funziona
Per le storie attualmente in corso osserviamo da quanto tempo sono state iniziate. Usiamo alcune percentuali, che possiamo ricavare dalla nostra Lead Time Distribution, per capire se il tempo che la storia sta impiegando è normale o se dovremmo preoccuparci.
- 0-50%. Finché la storia è in corso da 4 giorni o meno, la consideriamo verde: è tutto ok. La metà delle storie impiega tale tempi e quindi è normale.
- 50-80%. Tra i 5 e 6 giorni la storia diventa gialla perché sta iniziando a impiegare più del solito. Ci chiediamo: “Va tutto bene? Ci sono impedimenti? Vale la pena fare swarming e avere un ulteriore paio di persone sulla storia per aiutare?”.
- 80-90%. Tra i 7 e 10 giorni la storia è rossa: non è normale che impieghi così a lungo. Forse c’è qualche problema che necessita escalation? Forse lo scope era troppo grande e va spezzata? Diamo priorità a risolvere questi problemi e a completare la storia.
- 90-100%. Oltre i 10 giorni la storia è nera: la consideriamo un’emergenza che va risolta con massima priorità.

Uso dello Story Health: al Daily Standup Meeting per decidere su cosa lavorare
Conoscere lo stato di salute della storia è utilissimo durante lo Standup Meeting per decidere su cosa lavorare oggi. Se ci storie gialle, rosse o nere decidiamo di dar loro priorità e probabilmente assegniamo loro più persone. Se le storie in corso sono verdi, va tutto bene e potremmo anche permetterci di iniziare qualcos’altro.
Nel mio team, visualizziamo lo stato di salute sul nostro Build Monitor cosicché sia facile per chiunque prendere decisioni su cosa è meglio lavorare [
Conclusioni
In questo articolo abbiamo parlato di metriche per osservare, migliorare e prevedere i nostri tempi di consegna. Nel prossimo articolo proseguiremo con metriche che si concentrano sulla prevedibilità.
Riferimenti
[1] G. Puliti, Kanban, dall’idea alla pratica. In azione: tecniche e suggerimenti, MokaByte 213, gennaio 2016
http://www.mokabyte.it/2016/01/kanban-5/
[2] Alexei Zheglov, Lead Time: what we know about it, how we use it
[3] Carl Berardinelli, A Guide to Control Charts
[4] Alexei Zheglov, Analyzing the Lead Time Distribution Chart, Connected Knowledge
[5] Alexei Zheglov, Inside a Lead Time Distribution, Connected Knowledge
[6] Troy Magennis, The Economic Impact of Software Development Process Choice. Cycle-time Analysis and Monte Carlo Simulation Results
[7] Alexei Zheglov, Introducing Lead Time Forecasting Cards, Connected Knowledge
[8] Esempi di riferimento delle distrubuzioni Weibull
[9] Foglio di calcolo per definire la forma delle distribuzioni Weibull
[10] Versione pubblica del nostro spreadsheet
[11] Daniel S. Vacanti, Actionable Agile Metrics for Predictability: An Introduction, 2015
Mattia Battiston è un software developer con una grande passione per il miglioramento continuo. Attualmente lavora a Londra e utilizza Kanban, Lean e Agile per aiutare diversi team a migliorare.