

Introduzione
Negli articoli di questa serie abbiamo parlato di svariate metriche che ci aiutano a guidare il nostro processo di miglioramento continuo e ad avere maggiore consapevolezza riguardo a ciò che può essere previsto in prospettiva.
In questo e nell’articolo del mese prossimo — che chiuderà la serie — mettiamo insieme tutto quanto imparato fin qui per prevedere la durata di gruppi di storie o di interi progetti. Mostrerò come nel team usiamo i dati e le metriche a nostra disposizione per migliorare il nostro processo di stima, facendo riferimento a una tecnica chiamata Probabilistic Forecasting.
Consiglio a chi non avesse ben presenti i temi degli articoli precedenti di fare una rilettura di alcune parti particolarmente importanti a cui farò spesso riferimento: “Work Item Type” [1], “Lead Time Distribution” [2], “Throughput” e “Il problema di Story Point e Velocity” [3].
“Quanto ci vuole? Mi fai una stima?”
Abbiamo tutti uno o più stakeholder che consideriamo essere i nostri “clienti”: potrebbe essere un altro team nella nostra stessa azienda, un cliente della nostra società di consulenza, un Product Owner per il prodotto che vendiamo, il CEO della nostra startup, e così via.
Solitamente la prima domanda che il cliente ci rivolge non appena spiegato il problema — o spesso anche prima… — è: “Quanto tempo ci vorrà? Quanto costa? Mi fai una stima?”.
L’approccio agile comune al processo di stima
Per rispondere a queste domande, l’approccio comune di un team Agile più o meno è:
- analizza i requisiti con l’aiuto del cliente e/o del PO e li “spezza” in storie, creando un backlog;
- stima ogni storia nel backlog, usando tecniche come Story Point, T-shirt size, ore ideali, o ore effettive, quest’ultima soprattutto in quei team non ancora molto agili;
- usa la Velocity per convertire Story Point in giorni o sprint e per sapere quanto tempo ci vorrà per completare il lavoro; questa potrebbe essere una Velocity ideale se si tratta di un team nuovo, o la Velocity effettiva che si è misurata in passato se è un team già esistente;
- prima di consegnare la stima al cliente, un Project Manager (o chi per lui) aggiunge un “buffer”, un “cuscinetto temporale” ulteriore, necessario per gestire eventuali emergenze o nel caso la stima sia sbagliata; a volte viene semplicemente aggiunto del tempo extra, a volte invece la stima viene proprio raddoppiata o addirittur triplicata;
- dichiara la stima al cliente, in termini di costo e di data di consegna: un team agile idealmente consegna in modo incrementale, ma è ancora molto comune dichiarare la data in cui il progetto sarà “finito”;
- durante il corso del progetto usa la Velocity per controllare se si è in linea e quando il backlog sarà completato, usando tool come burn-down e burn-up chart.
Problemi tipici con le stime
L’approccio appena visto rappresenta senza dubbio un enorme miglioramento dai tempi del waterfall e sono sicuro che siamo tutti in buona fede quando lo seguiamo. Tuttavia non possiamo ignorare alcuni problemi che tipicamente emergono con questo tipo di stime: vediamoli di seguito.
Falso senso di certezza
Il risultato è espresso come un singolo numero o una data precisa, con l’effetto di nascondere l’incertezza intrinseca in una stima. Per esempio: “Ci vogliono 60 giorni”; oppure “Lo consegniamo il 01 febbraio”.
Spesso è il cliente a chiedere una data esatta perché questo lo fa sentire più sicuro e può usare quella data come “committment”. Questa data finisce in qualche piano e diventa una deadline che ci spinge verso quei comportamenti molto poco agili: blocchiamo i cambiamenti, riduciamo la collaborazione, cerchiamo scorciatoie, e così via.
Molto inaccurata
Come spiegato nel terzo articolo della serie [3], la correlazione tra Story Point e Lead Time è molto bassa. Inoltre la Velocity è una delle metriche più facili da imbrogliare, soprattutto quando siamo sotto pressione: senza rendercene conto, finiamo per raddoppiare i punti di ogni storia per sentirci più veloci o per rispettare le aspettative di qualche manager.
Il risultato è che la traduzione da stime a giorni/data diventa altamente inaccurata, pur sembrando precisa. È la ricetta per un disastro…
Stime inaffidabili quando siamo troppo occupati
La teoria delle code, da cui Kanban prende enorme ispirazione, ci insegna che più il livello di utilizzo del sistema va verso il 100% più il Lead Time schizza in alto. In breve: quando siamo troppo occupati, le attività impiegano molto tempo, come ben illustrato in un celebre libro di Don Reinertsen [4] o in un articolo del 2015 di Pawel Brodzinski [5].
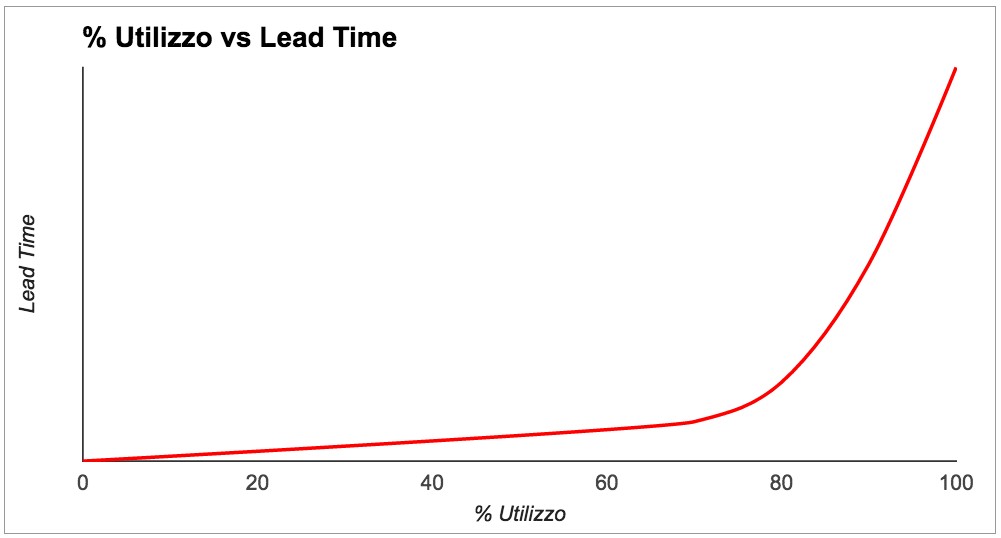
Un alto utilizzo è tipico in team che non hanno un limite al Work In Progress (WIP): quando una attività è bloccata, ne iniziano un’altra perché vogliono essere sempre occupati, e finiscono con avere 10 cose lasciate a metà e niente di completato.
In questi casi, stime basate sulla dimensione di una attività perdono senso perché anche qualcosa di molto semplice impiega moltissimo. L’analogia di Troy Magennis [6] descrive bene il problema: in una strada intasata, la bici, la Ferrari e il camion si muovono tutti alla stessa velocità, vale a dire molto lentamente.
Diamo il risultato che il cliente vuole sentirsi dire
Spesso abbiamo già un’idea di cosa il cliente vuole sentirsi dire. Finiamo così per influenzare le nostre decisioni per cercare di dare il risultato che crediamo sarà accettato dal cliente, a discapito di quello che derivava dalla nostra stima. Se il cliente non accetta, marchiamo le nostre stime come “sbagliate” e le rivediamo. Diventa un processo di negoziazione da cui una delle due parti uscirà perdente… e troppo spesso il perdente è proprio il team di sviluppo.
Questo è uno scenario particolarmente tipico per società di consulenza che devono vincere contratti.
Fixed-scope: ci fissiamo troppo presto su una particolare soluzione
Invece di presentargli un problema da risolvere, molto spesso viene chiesto al team di sviluppo di stimare una particolare soluzione.
Il team si concentra quindi a stimare quella soluzione, crea un backlog con tutte le storie da implementare, e il progetto non è considerato concluso finché tutte le storie non sono complete. Diventa un progetto con fixed-scope. Se il progetto va lungo abbiamo paura di fermarlo perché ci abbiamo già investito troppo: è la cosiddetta Sunk Cost Fallacy [7].
Non ci rendiamo conto che ogni problema ha infinite soluzioni e potremmo invece partire con la più economica per consegnare immediatamente del valore: magari è una soluzione che richiede qualche step manuale e qualche hack qua e là, ma per lo meno risolve il problema subito. Successivamente possiamo sempre iterare e implementare soluzioni più complesse, se il cliente lo ritiene necessario.
“Probabilistic forecasting”: quanto impiegheranno le prossime N storie?
Probabilistic forecasting [8] è una tecnica usata in diverse industrie per prevedere il verificarsi di eventi incerti. Il risultato della previsione è espresso come una lista di possibili risultati accompagnati dalla probabilità che quel particolare risultato divenga realtà.
Un classico esempio sono le previsioni meteo. Magari in gran parte dei notiziari TV si limitano a dire “domani piove”, ma quello che il meteorologo ha previsto è piuttosto una cosa del genere: “dopo aver utilizzato diversi modelli matematici per simulare la situazione meteorologica di domani, l’80% dei risultati dà esito di pioggia, il 15% dà nuvoloso senza pioggia, il 5% dà poco nuvoloso”.
Da qualche anno la comunità Kanban ha introdotto l’uso di questa tecnica nello sviluppo software.
Monte Carlo Simulation
Il meteo, come lo sviluppo software, è un sistema complesso [9] dove le relazioni di causa-effetto non sono prevedibili e sono visibili solo a posteriori. Non possiamo prevedere in modo deterministico cosa succederà. Quello che possiamo fare è usare i dati storici a nostra disposizione per simulare cosa potrebbe accadere in futuro.
Per fare Probabilistic Forecasting utilizziamo una tecnica presa dalla statistica chiamata Monte Carlo Method, anche se nella comunità Kanban tutti la chiamano Monte Carlo Simulation. È una tecnica particolarmente utile quando abbiamo a che fare con variabili incerte, o quando queste variabili sono generate a partire da una distribuzione. Consiste nell’estrarre valori random per queste variabili per ogni simulazione, ripetendo la simulazione per migliaia di volte così da generare sufficiente variazione nei valori e trovare statisticamente l’occorrenza di ogni possibile risultato.
Probabilistic Forecasting passo per passo
Vediamo passo passo con un esempio come usare Probabilistic Forecasting per rispondere alla fatidica domanda “quanto impiegheranno le prossime N storie?”. Come nota importante, stiamo dando per scontato che tutte le N storie siano dello stesso work item type.
Passo 1: suddividere in storie
Se non lo abbiamo già fatto, analizziamo i requisiti e li spezziamo in storie, usando i nostri soliti criteri. Per ogni storia identifichiamo il suo work item type. Il risultato sono storie con cui ci sentiremmo a nostro agio a lavorare.
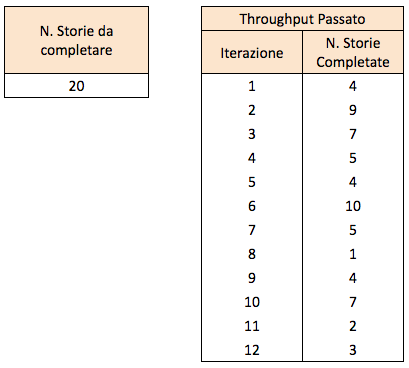
Passo 2: dati di input
Abbiamo bisogno di due dati in input: il numero di storie da completare, e il throughput che il team ha avuto in passato. Per esempio, vogliamo completare 20 storie e abbiamo avuto il throughput rappresentato in figura 3.
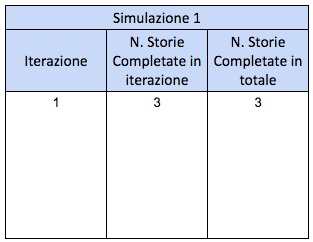
Passo 3: prima simulazione
Iniziamo la prima simulazione. Estraiamo a random un campione dal throughput che abbiamo avuto in passato, per far finta che nella prima iterazione completeremo quel numero di storie. Nell’esempio ho estratto 3: stiamo quindi simulando che nella prima iterazione completeremo 3 storie.
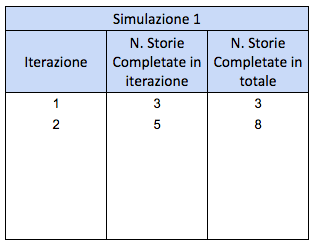
Passo 4: seconda iterazione della prima simulazione
Ripetiamo per eseguire la seconda iterazione della prima simulazione: quante storie completeremo nella seconda iterazione? Estraiamo un nuove campione a random. Nell’esempio ho estratto 5. Dopo due iterazioni, avremo completato 8 storie in totale
Passo 5: completiamo la prima simulazione
Ripetiamo finché il numero di storie completate in totale arriva o supera 20. Nell’esempio ci sono volute 5 iterazioni prima di completare 20 storie. La prima simulazione è completata.
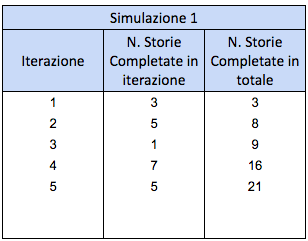
Passo 6: ripetere la simulazione per migliaia di volte
Ripetiamo la simulazione per qualche migliaio di volte, ovviamente in modo automatico, con uno spreadsheet [11] o uno script. Ogni volta continuiamo a estrarre numeri a random dal nostro throughput passato. Ripetendo la simulazione così tante volte, stiamo generando ogni possibile variazione nel risultato, così da osservare statisticamente quante volte avviene quel particolare risultato.
Ci saranno simulazioni particolarmente fortunate dove magari impieghiamo solo un paio di iterazioni, e altre particolarmente sfortunate dove impieghiamo 7-8 iterazioni. Ma con così tante ripetizioni questi casi anomali diventano una minoranza rispetto ai casi più probabili.
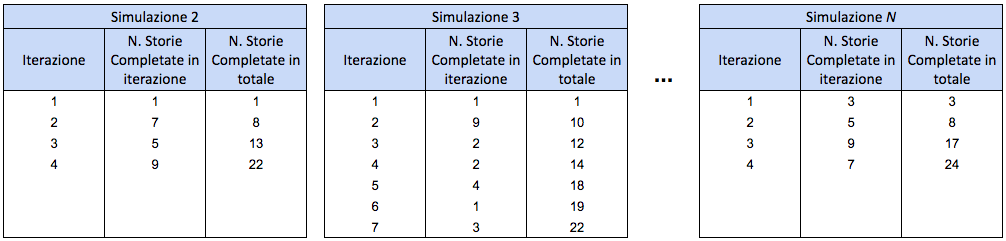
Passo 7: individuare la probabilità dei risultati
Contiamo la frequenza di ogni risultato per trovarne la probabilità.
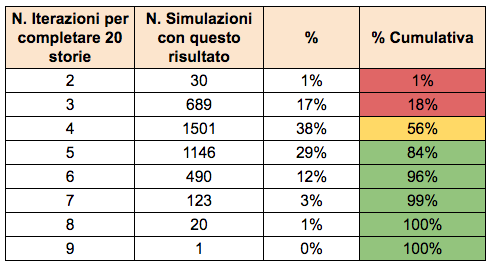
L’esempio di figura 8 mostra che abbiamo il 17% di probabilità di impiegare 3 iterazioni, il 38% di probabilità di impiegare 4 iterazioni, e così via. La colonna più a destra è la somma cumulativa delle singole probabilità: ci dice che abbiamo il 56% di sicurezza che completeremo le 20 storie entro al massimo 4 iterazioni, e l’84% di sicurezza che le completeremo entro al massimo 5 iterazioni.
Passo 8: comunicare il risultato al cliente
Idealmente esprimiamo il risultato al cliente in questo modo: “Abbiamo circa il 50% di possibilità di completare il lavoro in 4 iterazioni, ma potrebbero volercene 5. È improbabile che ne servano più di 5, ma nel peggiore dei casi potremmo arrivare a 6”.
Questo stile ci aiuta a concentrarci sulla gestione del rischio: se dovesse verificarsi il peggiore dei casi e dovessimo impiegare 6 iterazioni, quale sarebbe l’impatto? Cosa possiamo fare per diminuire quel rischio?
Se invece il cliente insiste per un singolo numero o una data precisa, sta a noi decidere quanto livello di rischio vogliamo assumerci. Se vogliamo essere sicuri dovremmo dichiarare 5 iterazioni. Altrimenti potremmo anche rischiare e dire 4 iterazioni; ma in questo secondo caso abbiamo quasi il 50% di probabilità di sbagliarci e sforare le stime.
Passo 9: tener traccia dell’avanzamento
Una volta che iniziamo a lavorare sulle 20 storie, usiamo esattamente la stessa tecnica per tenere traccia dell’avanzamento del lavoro. Al termine di ogni iterazione torniamo al passo 1 e aggiorniamo i dati in input: aggiungiamo un valore al throughput, e il numero di storie da completare viene diminuito. Ripetiamo quindi gli altri step per prevedere quando completeremo il resto delle storie.
Ribadiamo la nota: la dimensione delle storie non conta… ma il loro tipo sì!
Lo abbiamo già spiegato negli articoli precedenti [2] ma preferisco ripeterlo: la dimensione delle storie non conta, a patto che siano storie dello stesso tipo (Work Item Type). Storie dello stesso tipo seguono la stessa distribuzione di Lead Time, e quindi avremo molte storie veloci, alcune storie un po’ più lente e, di tanto in tanto, qualche storia più grossa.
Ma per le storie di tipo diverso? Vediamo di seguito quello che si può fare.
Previsioni per storie di tipo diverso
Gli step descritti qui sopra fanno riferimento al throughput per una tipologia singola di Work Item Type. Supponiamo invece di dover fare previsioni per storie di diverso tipo, per esempio: 20 storie di tipo 1 e 8 storie di tipo 2. Seguiamo lo stesso processo ma lo ripetiamo per i due tipi:
- Iniziamo con il tipo 1: diamo in input “20 storie” e il throughput che abbiamo avuto in passato per il tipo 1. Il risultato è 4-5 iterazioni.
- Ripetiamo per il tipo 2: diamo in input “8 storie” e il throughput che abbiamo avuto in passato per il tipo 2. Il risultato è 2-3 iterazioni.
- Il risultato è quindi 4-5 iterazioni: le storie di tipo 2 saranno complete dopo 3 iterazioni, ma ci vorranno un altro paio di iterazioni prima di finire anche le storie di tipo 1.
Altri fattori da considerare
Ci sono un paio di fattori importanti da considerare quando diamo in input il numero di storie:
- Quanti bug abbiamo di solito? Dovremmo tenerne conto e aumentare il numero di storie di conseguenza. Per esempio: come abbiamo spiegato nell’articolo precedente, se abbiamo 1 bug ogni 6 storie, invece di 20 storie dovremmo dare in input 23 o 24 per tenere conto dei bug che troveremo.
- Ci sarà scope creep? Vale a dire, scoprirò altre storie a cui non avevo pensato? È molto comune che questo accada; quindi, in base a quanto ci sentiamo sicuri, potremmo voler aggiungere altre storie per tenerne conto. Idealmente, è bene guardare agli scorsi progetti: quante storie erano nel backlog all’inizio, e quante storie si sono avute alla fine?
“Effort” vs “Elapsed”
È importante notare che il risultato della nostra previsione è quello che un project manager chiamerebbe Effort. Risponde alla domanda: “Quanto impiegheremo? Quanto costa?”.
Se invece vogliamo sapere “Quando il lavoro sarà concluso o consegnato?”, ossia i giorni di calendario, allora dobbiamo pensare alla misura di tipo Elapsed e dobbiamo stare attenti: dipende da come lavoreremo sulle storie. Se il team è libero di concentrarsi e lavorare a tempo pieno sulle storie, allora Effort ed Elapsed coincidono. Se invece il lavoro è mischiato con altro, dobbiamo allora tenere conto di quanto tempo trascorreremo su questo progetto per ogni iterazione.
Conclusione
In questo articolo abbiamo cominciato a vedere come utilizzare i dati a nostra disposizione per prevedere la durata di interi progetti e migliorare il nostro processo di stima, grazie al Probabilistic Forecasting e alla tecnica statistica Monte Carlo Simulation. Nel prossimo articolo concluderemo il discorso con una serie di considerazioni su stime e previsioni.
Mi farebbe molto piacere sentire la vostra opinione e rispondere ad eventuali domande! Potete trovarmi per email, o su Twitter e Linkedin.
Riferimenti
[1] Mattia Battiston, Metriche Kanban per il miglioramento continuo – I parte: Uno sguardo alle metriche per il flow, MokaByte 214, febbraio 2016
http://www.mokabyte.it/2016/02/kanbanmetrics-1/
[2] Mattia Battiston, Metriche Kanban per il miglioramento continuo – II parte: Metriche per il Delivery Time, MokaByte 215, marzo 2016
http://www.mokabyte.it/2016/03/kanbanmetrics-2/
[3] Mattia Battiston, Metriche Kanban per il miglioramento continuo – III parte: Metriche per la prevedibilità, MokaByte 216, aprile 2016
http://www.mokabyte.it/2016/04/kanbanmetrics-3/
[4] Donald G. Reinertsen, The Principles of Product Development Flow: Second Generation Lean Product Development, Celeritas Publishing, 2009
[5] Pawel Brodzinski, Economic Value of Slack Time
http://brodzinski.com/2015/01/slack-time-value.html
[6] Troy Magennis, Agile 2015 – Risk – The Final Agile Enterprise Frontier
[7] David McRaney, The Sunk Cost Fallacy
[8] La voce “Probabilistic forecasting” su Wikipedia
https://en.wikipedia.org/wiki/Probabilistic_forecasting
[9] Il modello Cynefin
https://lizkeogh.com/cynefin-for-developers/
[10] La voce “Monte Carlo method” su Wikipedia
https://en.wikipedia.org/wiki/Monte_Carlo_method
[11] Un foglio di calcolo per realizzare la simulazione Monte Carlo
Mattia Battiston è un software developer con una grande passione per il miglioramento continuo. Attualmente lavora a Londra e utilizza Kanban, Lean e Agile per aiutare diversi team a migliorare.