

Introduzione
“Quanto tempo ci vorrà? Cosa possiamo consegnare per la prossima scadenza? Questa feature sarà pronta in tempo?”. La maggior parte dei team si trova frequentemente a dover rispondere a domande come queste, spesso poste dal cliente, dal Product Owner, dal manager, o dal team stesso. Tuttavia, i comuni approcci alle stime raramente ci danno la prevedibilità che cerchiamo, e tendono invece a introdurre effetti collaterali negativi come scadenze inflessibili, oltre a nascondere incertezza.
In una serie di articoli pubblicata qualche anno fa su MokaByte, abbiamo parlato di come usare metriche per aiutare il team nel miglioramento continuo [1]. In questa nuova serie, ci concentriamo su come possiamo usare metriche per rispondere a domande di business, e spieghiamo il modo in cui avere dati a nostra disposizione migliori le conversazioni con cui prendiamo queste decisioni. Gli esempi mostrati sono presi da dati reali raccolti nei team con cui ho lavorato negli ultimi anni, e ogni storia o conversazione è basata su eventi realmente accaduti.
Nel primo articolo discutiamo i motivi per cui in moltissimi team fatichiamo a usare le nostre stime per raggiungere la prevedibilità desiderata, e quali alternative abbiamo. Cominciamo, quindi, raccontando una storia: L’Aquila, 14 dicembre 2008…
Il terremoto dell’Aquila
L’Aquila, 14 dicembre 2008. È una tranquilla domenica mattina, fredda ma asciutta. Un tiepido sole fa timidamente capolino da dietro le nuvole, lascito della pioggia del giorno prima. Sono le 09:16 quando una leggera scossa di terremoto scuote la città. È di sola magnitudo 1.8 ma è sufficiente per essere avvertita e per spaventare la popolazione.
Nessuno poteva sapere che si trattava solo della prima di una lunga serie di scosse che, nei mesi successivi, culminerà nel terribile terremoto del 6 aprile 2009 quando, alle 03:32, nel pieno della notte, una scossa di magnitudo 6.1 colpisce la zona. Il bilancio è tragico: 309 morti, oltre 1600 feriti, e danni stimati per oltre 10 miliardi di euro [3].
Possiamo prevedere i terremoti?
In seguito a tragedie come queste, la domanda sorge spontanea: si sarebbe potuto prevedere? Possiamo prevedere i terremoti? La risposta delle scienze geologiche è chiara: no, se con “prevedere” si intende conoscere in anticipo intensità, luogo, o data del terremoto. Ad oggi, la sismologia non ha trovato alcun metodo efficace per questo tipo di previsioni deterministiche – nulla che vada al di là della sporadica “botta di fortuna”.
Tuttavia, è relativamente facile prevedere terremoti in modo probabilistico. I terremoti seguono sequenze statistiche piuttosto stabili. Per esempio, dati storici mostrano come nella zona dell’Aquila accade un terremoto di magnitudo superiore a 6 ogni trecento anni circa: 6.5 nel 1461, 6.8 nel 1703, e 6.1 nel 2009.
La precisione di queste previsioni si misura in anni, rendendo impossibile utilizzarle per scopi come evacuazioni: sarebbe assurdo evacuare la popolazione per 30 anni. È molto facile però usarle per dire “C’è un’alta probabilità che un terremoto di magnitudo superiore al 6 accada nei prossimi 30-50 anni”, che dovrebbe guidare iniziative volte alla resilienza — per prime, costruzioni antisismiche — e al disaster recovery, ad esempio regolari prove di evacuazione.
Due (tristemente) interessanti tentativi di previsione
Ma nel caso del terremoto dell’Aquila, ci furono però due tentativi di prevedere quanto sarebbe successo: due approcci radicalmente opposti, che rendono questa triste storia interessante ai fini di questo articolo.
Il primo: nei giorni immediatamente successivi al sisma, il tecnico Giampaolo Giuliani sale agli onori della cronaca rivendicando di aver predetto l’evento. Previsione che però non ha potuto opportunamente divulgare perché le autorità gli avevano proibito di lanciare l’allarme [4].
Viene eletto ad eroe dai media e dall’opinione pubblica, nonostante lo stesso signore avesse provocato un falso allarme solo una settimana prima, e il suo metodo sia definito chiaramente inaffidabile dalla comunità scientifica: le poche volte che ci azzecca sono dovute, appunto, a sporadiche “botte di fortuna” e giustificate dal trovare un falso segnale in una serie di dati con molto rumore.
Secondo: nelle settimane precedenti al sisma, la Protezione Civile, allertata dal protrarsi dello sciame sismico, crea una speciale task force di esperti e scienziati per valutare il rischio di un evento catastrofico. Il gruppo comunica alla popolazione che la possibilità esiste, ma di non farsi prendere dal panico in quanto sciami del genere sono considerati normali per la zona. In seguito al terremoto, gli scienziati vengono addirittura messi sotto processo con l’accusa di aver “fallito” nel prevedere la tragedia, suscitando clamore e rabbia nella comunità scientifica.
Una analisi dettagliata dei due approcci è trattata al capitolo 5 de libro The signal and the noise. [5]
Due importanti lezioni
Se torniamo a volgere lo sguardo alle attività di sviluppo software, questa storia evidenzia due importanti lezioni che ho imparato negli ultimi anni lavorando con team che usano dati e metriche per fare previsioni.
Abbandonare modelli deterministici
La prima lezione da imparare è che, per prevedere eventi con alta incertezza, come terremoti o progetti software, è meglio abbandonare modelli deterministici — le classiche stime, o in inglese estimates — e utilizzare invece modelli probabilistici, vale a dire fare delle previsioni, in inglese forecasts.
Dobbiamo accettare che la certezza promessa da falsi esperti, come quel tecnico che riteneva di poter prevedere esattamente il momento del terremoto, non esiste. Dobbiamo invece ascoltare i veri esperti quando ci spiegano che c’è sempre il rischio che avvenga un terremoto nel nostro progetto, invece di metterli sotto processo.
Quando accettiamo questo cambio di mentalità, cambia anche il modo in cui pianifichiamo il nostro lavoro: restiamo sempre agili e flessibili, in modo da poter reagire e cambiare rotta in qualunque momento, nel caso che avvenga un evento catastrofico.
Adottare approcci probabilistici
Per abbracciare modelli probabilistici e raggiungere quanto appena descritto, occorre ottima comunicazione.
Come esseri umani abbiamo una naturale predisposizione negativa contro l’incertezza: la troviamo scomoda e frustrante. Per questo, inconsciamente, preferiamo ascoltare falsi esperti che promettono certezza: questo fenomeno psicologico prende il nome di doubt avoidance tendency, ossia “tendenza ad evitare il dubbio” [6].
Fare forecasting significa comunicare rischi e opzioni e, per farlo in modo efficace, dobbiamo migliorare il modo in cui approcciamo molte conversazioni. In questa serie di articoli vedremo molti esempi pratici di tali conversazioni, e di come usare dati e metriche per guidarle.
I tipici problemi delle stime tradizionali
Nello sviluppo software, il tradizionale modo deterministico di fare stime (estimates) presenta una serie di problemi, legati in definitiva alla complessità dell’attività stessa. Vediamo di seguito una serie di problemi tiipici e cerchiamo di individuarne i motivi.
Problema: scarsa correlazione tra stime e lead time
Prendiamo ad esempio il metodo di stima più comune tra i team agili: story points. Il team usa Planning Poker per stimare le storie in punti e poi usa la velocity per fare previsioni e rispondere a domande quali “Quante storie dovrei includere nel prossimo sprint?” o “Quando completeremo questo gruppo di storie, o questo progetto?”.
L’uso di queste pratiche è così diffuso che è ormai considerato la normalità. Tuttavia, negli ultimi anni, è diventato sempre più chiaro che questo approccio, sebbene rappresenti un enorme passo avanti rispetto ai vecchi giorni di waterfall, ha un problema importante.
Molti team osservano che c’è scarsa correlazione tra la dimensione stimata di una storia (story point) e quanto tempo la storia impiega effettivamente per essere completata (lead time). Per esempio, in un team dove ho lavorato, storie stimate con lo stesso numero di punti potevano impiegare da alcuni giorni ad alcune settimane per essere completate.
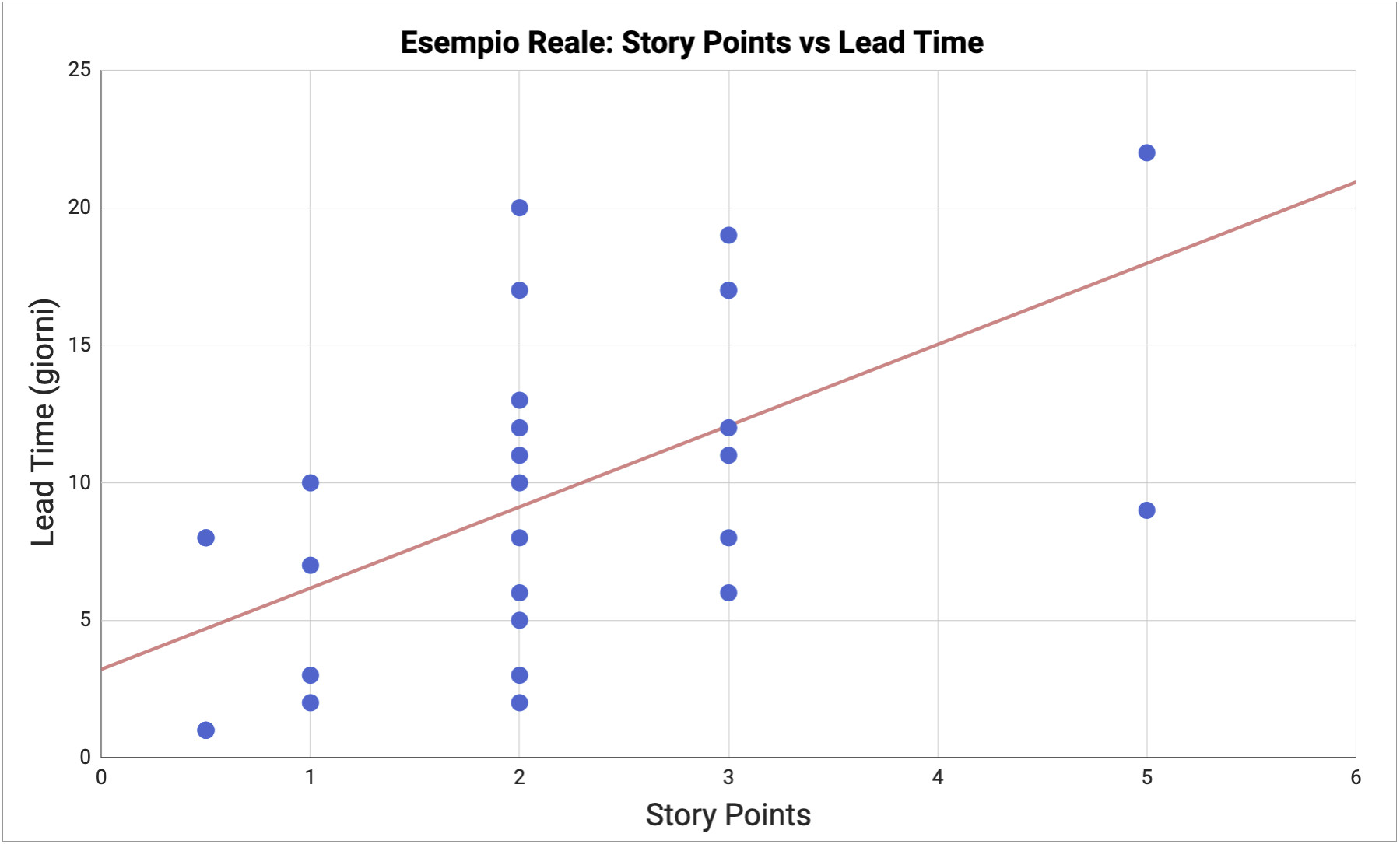
Storie di 1 punto impiegavano da 2 a 10 giorni; storie di 2 punti impiegavano da 2 a 20 giorni; storie di 3 punti impiegavano da 2 a 18 giorni. C’era pochissima correlazione tra i punti stimati e l’effettivo lead time. Con così poca correlazione le nostre stime erano praticamente inutili: non avevamo modo di sapere quanto una storia avrebbe impiegato basandosi sui punti stimati. Di conseguenza anche la nostra velocity non aveva senso ed era altamente imprevedibile.
Se siete curiosi di vedere se questo è il caso anche nel vostro team, al riferimento [7] trovate una serie di fogli di calcolo in grado di aiutare a capirlo. In particolare, ce ne è uno per misurare se le nostre stime sono prevedibili.
Lo stesso problema si presenta con metodi di stima come t-shirt size, ore ideali, giornate ideali, e qualunque metodo dove si chiede alle persone di “indovinare” il futuro: la dimensione di una storia ha poco a che fare con quanto tempo impiegherà, per tre importanti motivi, che vediamo qui di seguito.
Motivo #1: Troppo “Work in Progress”
Quando abbiamo troppo “Work in Progress” (WIP), stiamo lavorando su troppe cose allo stesso tempo, invece di concentrarci sul completare le attività già iniziate. Perdiamo tempo nel passare da un contesto a un altro (context switching) e la qualità del lavoro soffre: e anche storie all’apparenza semplici finiscono per impiegare piú tempo di quanto ci aspettassimo.
È il caso tipico di team che non hanno un limite al Work In Progress: quando un’attività è bloccata ne iniziano un’altra perché vogliono essere sempre occupati, e finiscono con avere dieci cose lasciate a metà e niente di completato.

In questi casi stime basate sulla dimensione di una attività perdono senso perché anche qualcosa di molto semplice impiega moltissimo. L’analogia di Troy Magennis [8] descrive bene il problema: in una strada intasata, la bici, la Ferrari e il camion si muovono tuttie alla stessa velocità, molto lentamente.
Motivo #2: Code nel processo
Molto spesso nei nostri processi ci sono tempi di attesa tra una attività e l’altra. Per esempio: attesa che qualcuno sia libero per iniziare una storia, attesa che qualcuno sia libero per testare la storia, attesa del prossimo rilascio, etc.

Consideriamo questi stati come “code” o “in attesa”, quando nessuno sta lavorando sulla storia, mentre gli altri stati sono considerati come “stati che aggiungono valore”. Chiamiamo Flow Efficiency la percentuale di tempo che una storia passa in stati che aggiungono valore.
Moltissimi team non si rendono conto che la loro flow efficiency è estremamente bassa, comunemente tra il 5% ed il 15%. La stragrande maggioranza del tempo è perso in code.
Queste code sono spesso “invisibili”, non rappresentate sulla lavagna, ed è comune ignorarle quando stimiamo. Quando ci viene chiesta una stima, automaticamente pensiamo “Quanto tempo dovrò lavorare su questa storia?”, ma così facendo stiamo stimando solo il tempo di lavoro attivo, che è solo una piccola percentuale rispetto all’effettivo lead time di una storia.
Motivo #3: Eventi incerti
Molto spesso nel nostro lavoro dobbiamo fronteggiare eventi inaspettati: blockers, problemi urgenti, bug, etc. Diventa molto difficile prevedere quanto una storia durerà, non sapendo se e quanto sarà impattata da uno di questi eventi.
Per esempio, la figura 4 mostra una foto presa verso la fine di un progetto recente su cui ho lavorato: ogni Post–it arancione rappresenta qualcosa da chiarire, e i Post–it verdi sono le rispettive risposte.

Ognuna di queste domande (arancione) è sorta a inizio progetto, ma solo durante il corso del lavoro siamo riusciti a trovare le risposte (verde). Cercare di stimare la durata di certe attività a inizio progetto sarebbe stato impossibile, in quanto ognuna di queste domande aveva la possibilità di cambiare considerevolmente la soluzione da implementare.
L’unica dimensione che conta: abbastanza piccola
L’unica dimensione che conta nelle nostre storie è che siano abbastanza piccole. Fintanto che il team si sforza di suddividerle per renderle più piccole possibili usando dei criteri uniformi nel tempo, possiamo semplicemente usare il numero di storie invece della loro dimensione per applicare le tecniche di forecasting descritte in questi articoli. Per idee su come migliorare il nostro story slicing, il “classico” di Gojko Adzic e David Evans [9] resta un libro davvero raccomandato.
Il team investe comunque del tempo a parlare del lavoro e decidere come spezzarlo in storie, così da creare l’importante “shared understanding”, ma non importa più associare un numero di punti a ogni storia.
Un mito importante da sfatare: non occorre che ogni storia abbia la stessa dimensione. Si tratta, appunto, di un falso mito. Se il team resta uniforme e costante nei criteri con cui suddivide il lavoro, ci sarà una naturale variazione nella dimensione delle storie, ma questa variazione viene automaticamente rappresentata e tenuta in considerazione dal fatto che, come vedremo, quando facciamo forecasting utilizziamo dati storici del team per fare previsioni [10].
Alternativa: Probabilistic Forecasting
Spinte da discussioni come #noestimates e dalla voglia di migliorare, negli ultimi anni sono state esplorate diverse alternative a questi processi di stime tradizionali. Una tecnica in particolare sta cominciando a prendere piede: inizialmente esplorata e promossa nella comunità Kanban da esperti come Troy Magennis e Dan Vacanti, Probabilistic Forecasting sta guadagnando popolarità nel mondo Agile, essendosi dimostrata estremamente utile e efficace quando abbiamo a che fare con eventi incerti come lo sviluppo software.
Forecasting: definizione e principi
Probabilistic Forecasting [11], o più semplicemente Forecasting, è una tecnica usata in diversi campi industriali per prevedere il verificarsi di eventi incerti. Segue due principi:
- utilizza dati storici del team per simulare cosa succederà in futuro;
- esprime la previsione come una lista di possibili risultati accompagnati dalla probabilità che quel particolare risultato divenga realtà.
Un classico esempio sono le previsioni meteo (che non a caso si chiamano in inglese weather forecasts): magari chi le illustra in TV si limita a dire “domani pioverà”. Ma il ragionamento che sintetizzano è: “Dopo aver utilizzato diversi modelli matematici per simulare la situazione meteorologica di domani, e dopo aver preso in considerazione quanto avvenuto in condizioni analoghe negli anni precedenti, l’80% dei risultati dà esito di pioggia, il 15% dà nuvoloso senza pioggia, 5% dà neve”.
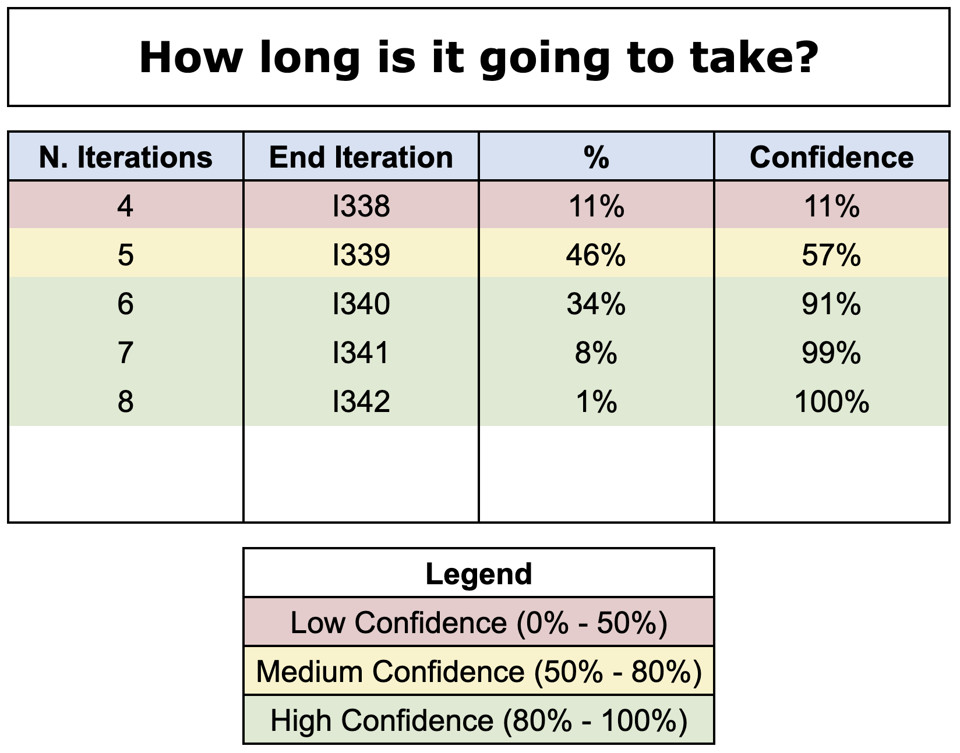
Troy Magennis, uno dei maggiori esperti di forecasting e metriche agili, mi ha insegnato quello che considero essere il vero potere del forecasting: “Quando fai forecasting sei nel campo della comunicazione”. Ruota tutto intorno a come comunichiamo le nostre previsioni.
Quando esprimiamo i risultati in questo modo, cambiamo il nostro approccio da deterministico — “possiamo prevedere il futuro” — a probabilistico, vale a dire “questi sono i possibili esiti, alcuni sono più probabili di altri”.
Questo incoraggia conversazioni di valore come “Cosa succederebbe se il progetto impiegasse così a lungo? Quale sarebbe l’impatto? Cosa possiamo fare per ridurre questo rischio?”.
Conclusioni
In questo articolo abbiamo discusso del perché i comuni approcci alle stime spesso falliscono nel garantirci una buona prevedibilità. Abbiamo introdotto l’idea di Probabilistic Forecasting, che espanderemo nei prossimi articoli con molti esempi pratici, concentrandoci in particolare sul modo in cui migliorare le nostre conversazioni.
Mattia Battiston è un software developer con una grande passione per il miglioramento continuo. Attualmente lavora a Londra e utilizza Kanban, Lean e Agile per aiutare diversi team a migliorare.